 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections
Sep 01, 2016
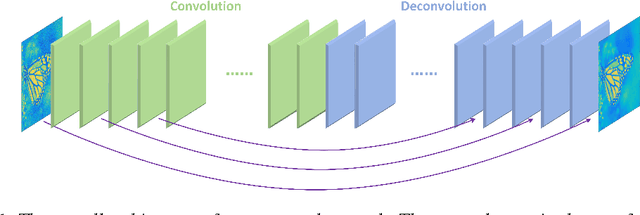
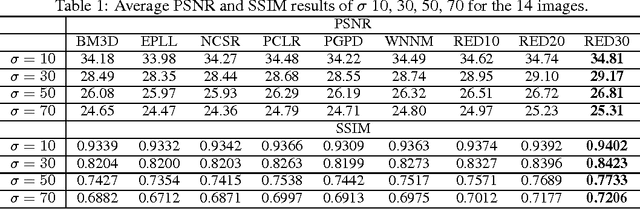
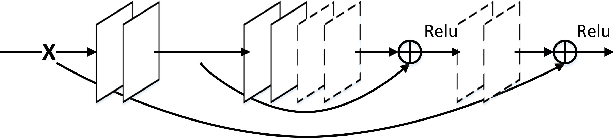
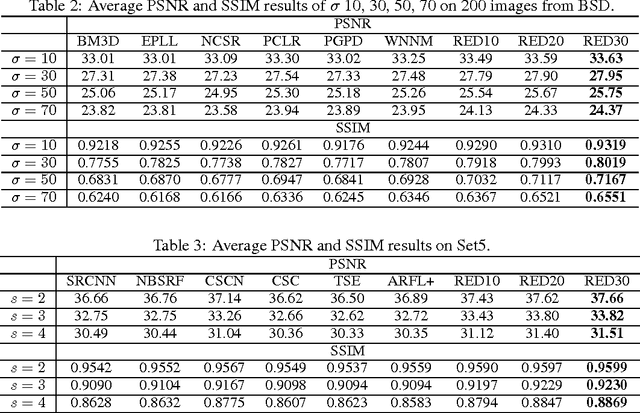
In this paper, we propose a very deep fully convolutional encoding-decoding framework for image restoration such as denoising and super-resolution. The network is composed of multiple layers of convolution and de-convolution operators, learning end-to-end mappings from corrupted images to the original ones. The convolutional layers act as the feature extractor, which capture the abstraction of image contents while eliminating noises/corruptions. De-convolutional layers are then used to recover the image details. We propose to symmetrically link convolutional and de-convolutional layers with skip-layer connections, with which the training converges much faster and attains a higher-quality local optimum. First, The skip connections allow the signal to be back-propagated to bottom layers directly, and thus tackles the problem of gradient vanishing, making training deep networks easier and achieving restoration performance gains consequently. Second, these skip connections pass image details from convolutional layers to de-convolutional layers, which is beneficial in recovering the original image. Significantly, with the large capacity, we can handle different levels of noises using a single model. Experimental results show that our network achieves better performance than all previously reported state-of-the-art methods.
Associating Multi-Scale Receptive Fields for Fine-grained Recognition
May 19, 2020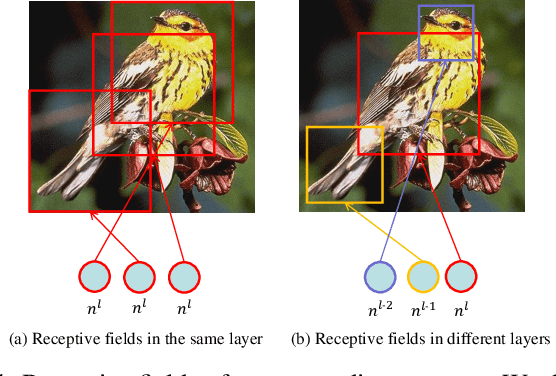
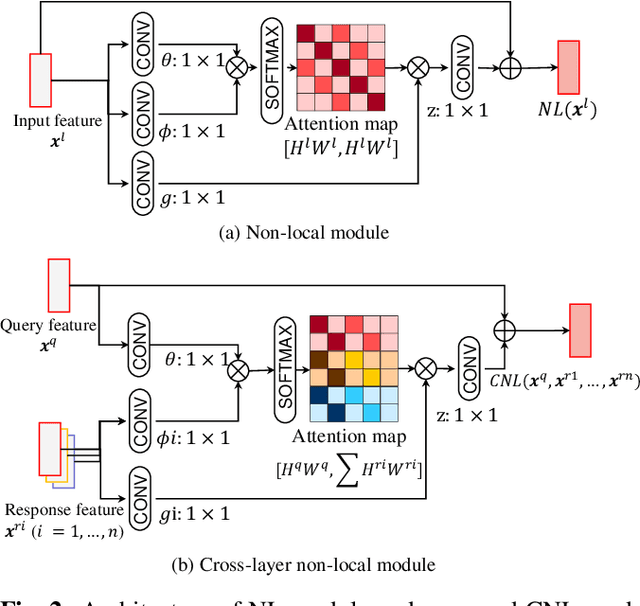
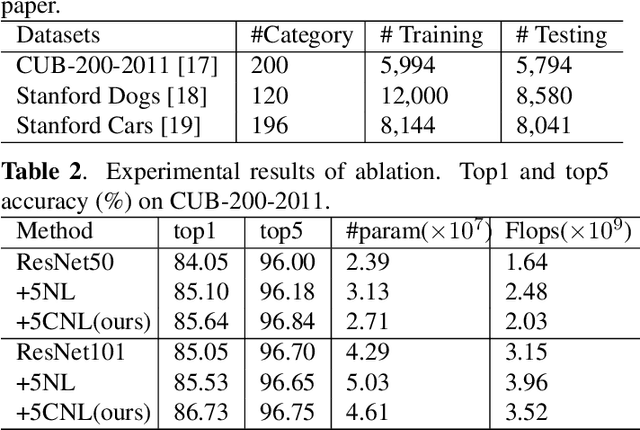

Extracting and fusing part features have become the key of fined-grained image recognition. Recently, Non-local (NL) module has shown excellent improvement in image recognition. However, it lacks the mechanism to model the interactions between multi-scale part features, which is vital for fine-grained recognition. In this paper, we propose a novel cross-layer non-local (CNL) module to associate multi-scale receptive fields by two operations. First, CNL computes correlations between features of a query layer and all response layers. Second, all response features are weighted according to the correlations and are added to the query features. Due to the interactions of cross-layer features, our model builds spatial dependencies among multi-level layers and learns more discriminative features. In addition, we can reduce the aggregation cost if we set low-dimensional deep layer as query layer. Experiments are conducted to show our model achieves or surpasses state-of-the-art results on three benchmark datasets of fine-grained classification. Our codes can be found at github.com/FouriYe/CNL-ICIP2020.
RGBT Salient Object Detection: A Large-scale Dataset and Benchmark
Jul 08, 2020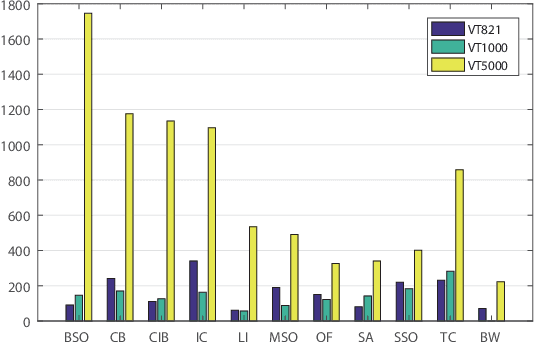

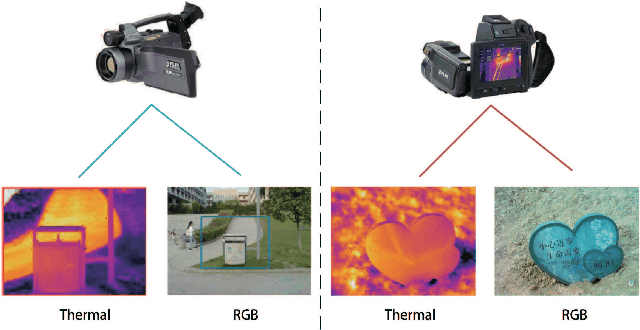
Salient object detection in complex scenes and environments is a challenging research topic. Most works focus on RGB-based salient object detection, which limits its performance of real-life applications when confronted with adverse conditions such as dark environments and complex backgrounds. Taking advantage of RGB and thermal infrared images becomes a new research direction for detecting salient object in complex scenes recently, as thermal infrared spectrum imaging provides the complementary information and has been applied to many computer vision tasks. However, current research for RGBT salient object detection is limited by the lack of a large-scale dataset and comprehensive benchmark. This work contributes such a RGBT image dataset named VT5000, including 5000 spatially aligned RGBT image pairs with ground truth annotations. VT5000 has 11 challenges collected in different scenes and environments for exploring the robustness of algorithms. With this dataset, we propose a powerful baseline approach, which extracts multi-level features within each modality and aggregates these features of all modalities with the attention mechanism, for accurate RGBT salient object detection. Extensive experiments show that the proposed baseline approach outperforms the state-of-the-art methods on VT5000 dataset and other two public datasets. In addition, we carry out a comprehensive analysis of different algorithms of RGBT salient object detection on VT5000 dataset, and then make several valuable conclusions and provide some potential research directions for RGBT salient object detection.
MaterialGAN: Reflectance Capture using a Generative SVBRDF Model
Sep 30, 2020
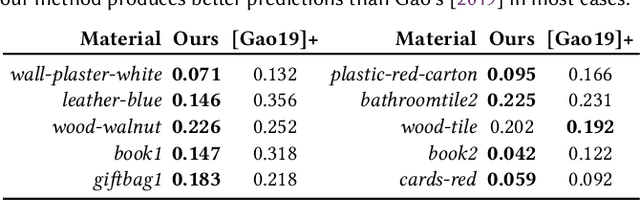


We address the problem of reconstructing spatially-varying BRDFs from a small set of image measurements. This is a fundamentally under-constrained problem, and previous work has relied on using various regularization priors or on capturing many images to produce plausible results. In this work, we present MaterialGAN, a deep generative convolutional network based on StyleGAN2, trained to synthesize realistic SVBRDF parameter maps. We show that MaterialGAN can be used as a powerful material prior in an inverse rendering framework: we optimize in its latent representation to generate material maps that match the appearance of the captured images when rendered. We demonstrate this framework on the task of reconstructing SVBRDFs from images captured under flash illumination using a hand-held mobile phone. Our method succeeds in producing plausible material maps that accurately reproduce the target images, and outperforms previous state-of-the-art material capture methods in evaluations on both synthetic and real data. Furthermore, our GAN-based latent space allows for high-level semantic material editing operations such as generating material variations and material morphing.
Prune Responsibly
Sep 10, 2020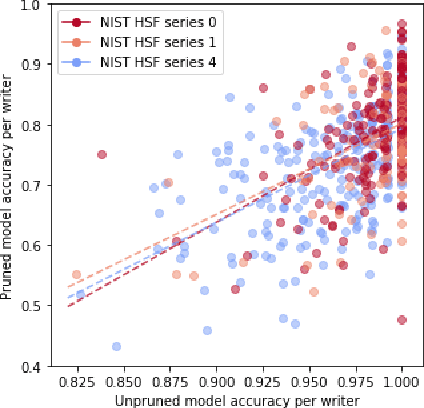
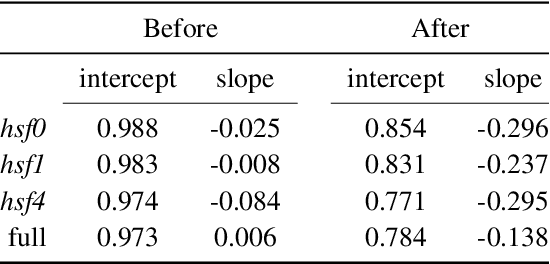
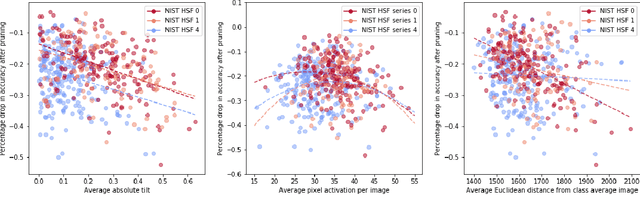
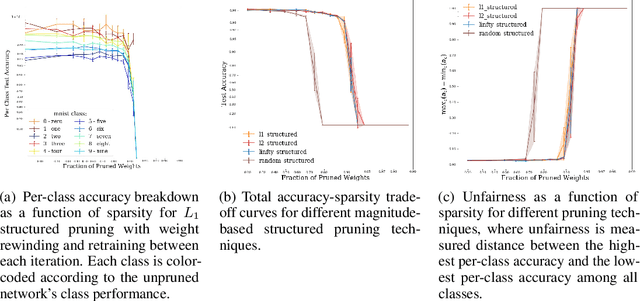
Irrespective of the specific definition of fairness in a machine learning application, pruning the underlying model affects it. We investigate and document the emergence and exacerbation of undesirable per-class performance imbalances, across tasks and architectures, for almost one million categories considered across over 100K image classification models that undergo a pruning process.We demonstrate the need for transparent reporting, inclusive of bias, fairness, and inclusion metrics, in real-life engineering decision-making around neural network pruning. In response to the calls for quantitative evaluation of AI models to be population-aware, we present neural network pruning as a tangible application domain where the ways in which accuracy-efficiency trade-offs disproportionately affect underrepresented or outlier groups have historically been overlooked. We provide a simple, Pareto-based framework to insert fairness considerations into value-based operating point selection processes, and to re-evaluate pruning technique choices.
Block-wise Minimization-Majorization algorithm for Huber's criterion: sparse learning and applications
Aug 25, 2020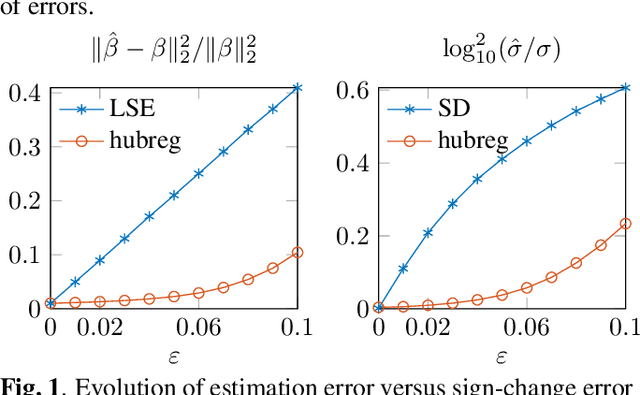

Huber's criterion can be used for robust joint estimation of regression and scale parameters in the linear model. Huber's (Huber, 1981) motivation for introducing the criterion stemmed from non-convexity of the joint maximum likelihood objective function as well as non-robustness (unbounded influence function) of the associated ML-estimate of scale. In this paper, we illustrate how the original algorithm proposed by Huber can be set within the block-wise minimization majorization framework. In addition, we propose novel data-adaptive step sizes for both the location and scale, which are further improving the convergence. We then illustrate how Huber's criterion can be used for sparse learning of underdetermined linear model using the iterative hard thresholding approach. We illustrate the usefulness of the algorithms in an image denoising application and simulation studies.
Object Detection using Image Processing
Nov 23, 2016



An Unmanned Ariel vehicle (UAV) has greater importance in the army for border security. The main objective of this article is to develop an OpenCV-Python code using Haar Cascade algorithm for object and face detection. Currently, UAVs are used for detecting and attacking the infiltrated ground targets. The main drawback for this type of UAVs is that sometimes the object are not properly detected, which thereby causes the object to hit the UAV. This project aims to avoid such unwanted collisions and damages of UAV. UAV is also used for surveillance that uses Voila-jones algorithm to detect and track humans. This algorithm uses cascade object detector function and vision. train function to train the algorithm. The main advantage of this code is the reduced processing time. The Python code was tested with the help of available database of video and image, the output was verified.
A Novel and Reliable Deep Learning Web-Based Tool to Detect COVID-19 Infection from Chest CT-Scan
Jun 26, 2020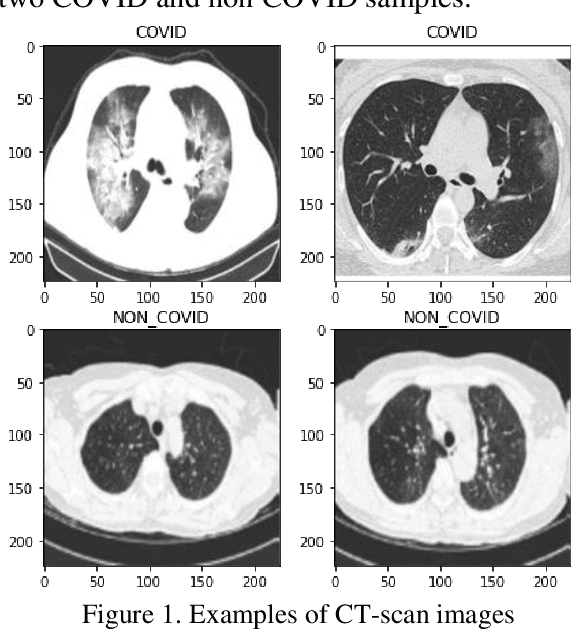
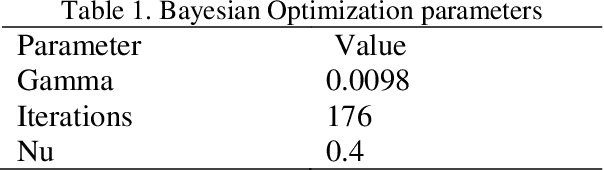
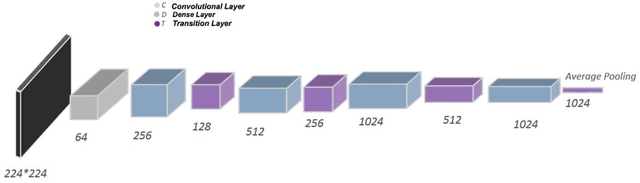
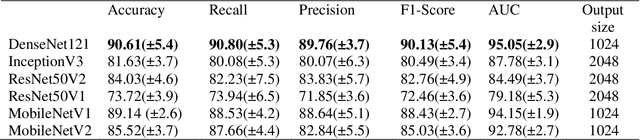
The corona virus is already spread around the world in many countries, and it has taken many lives. Furthermore, the world health organization (WHO) has announced that COVID-19 has reached the global epidemic stage. Early and reliable diagnosis using chest CT-scan can assist medical specialists in vital circumstances. In this work, we introduce a computer aided diagnosis (CAD) web service to detect COVID- 19 online. One of the largest public chest CT-scan databases, containing 746 participants was used in this experiment. A number of well-known deep neural network architectures consisting of ResNet, Inception and MobileNet were inspected to find the most efficient model for the hybrid system. A combination of the Densely connected convolutional network (DenseNet) in order to reduce image dimensions and Nu-SVM as an anti-overfitting bottleneck was chosen to distinguish between COVID-19 and healthy controls. The proposed methodology achieved 90.80% recall, 89.76% precision and 90.61% accuracy. The method also yields an AUC of 95.05%. Ultimately a flask web service is made public through ngrok using the trained models to provide a RESTful COVID-19 detector, which takes only 39 milliseconds to process one image. The source code is also available at https://github.com/KiLJ4EdeN/COVID_WEB. Based on the findings, it can be inferred that it is feasible to use the proposed technique as an automated tool for diagnosis of COVID-19.
Scale-, shift- and rotation-invariant diffractive optical networks
Oct 24, 2020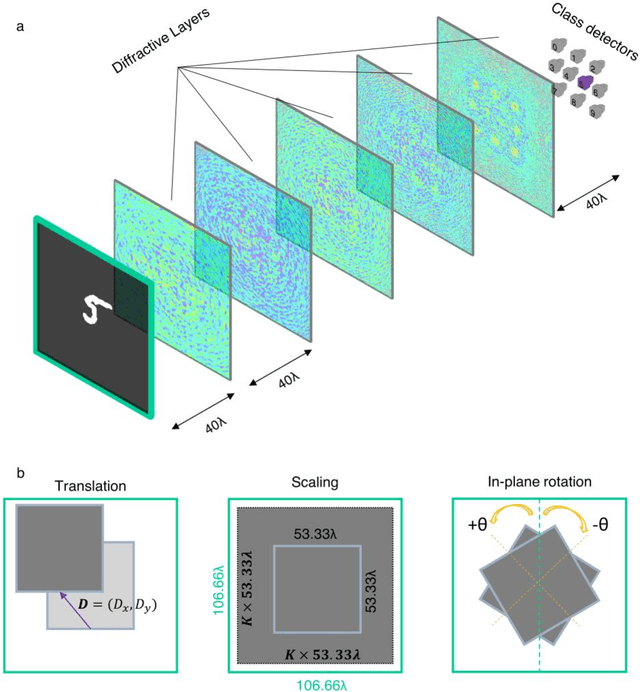
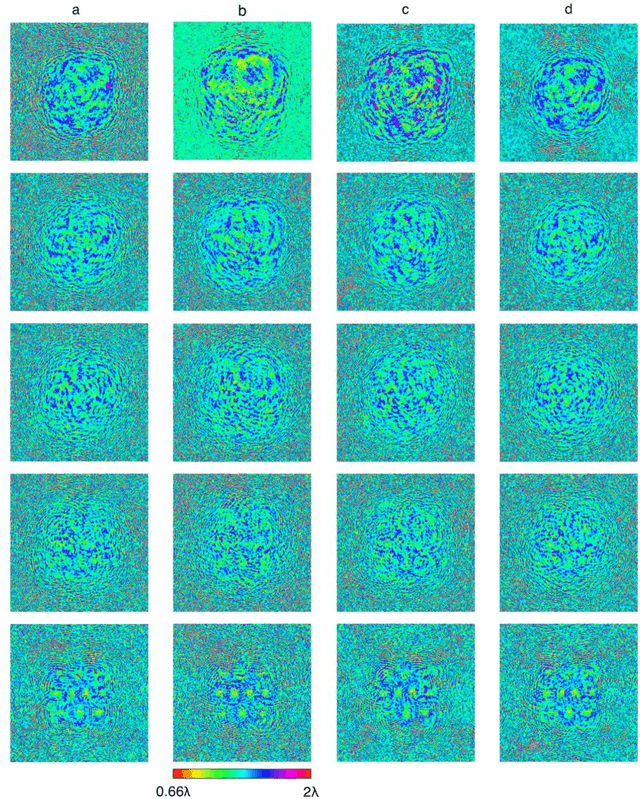
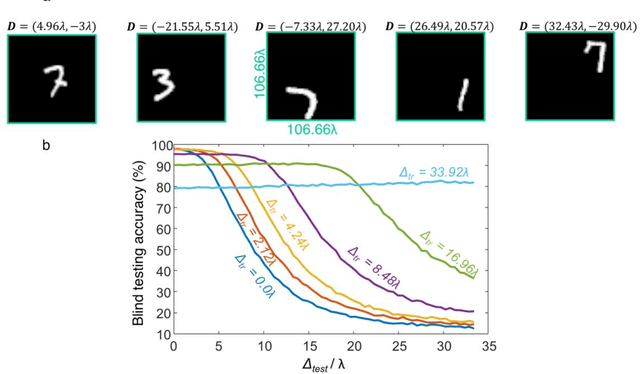
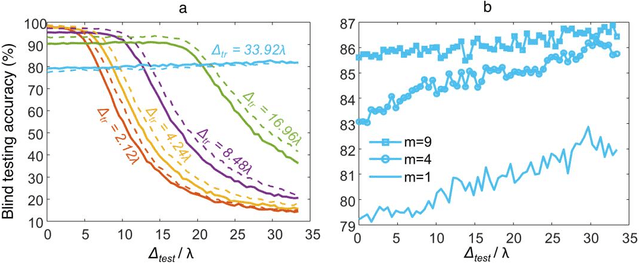
Recent research efforts in optical computing have gravitated towards developing optical neural networks that aim to benefit from the processing speed and parallelism of optics/photonics in machine learning applications. Among these endeavors, Diffractive Deep Neural Networks (D2NNs) harness light-matter interaction over a series of trainable surfaces, designed using deep learning, to compute a desired statistical inference task as the light waves propagate from the input plane to the output field-of-view. Although, earlier studies have demonstrated the generalization capability of diffractive optical networks to unseen data, achieving e.g., >98% image classification accuracy for handwritten digits, these previous designs are in general sensitive to the spatial scaling, translation and rotation of the input objects. Here, we demonstrate a new training strategy for diffractive networks that introduces input object translation, rotation and/or scaling during the training phase as uniformly distributed random variables to build resilience in their blind inference performance against such object transformations. This training strategy successfully guides the evolution of the diffractive optical network design towards a solution that is scale-, shift- and rotation-invariant, which is especially important and useful for dynamic machine vision applications in e.g., autonomous cars, in-vivo imaging of biomedical specimen, among others.
Lossy Image Compression with Compressive Autoencoders
Mar 01, 2017
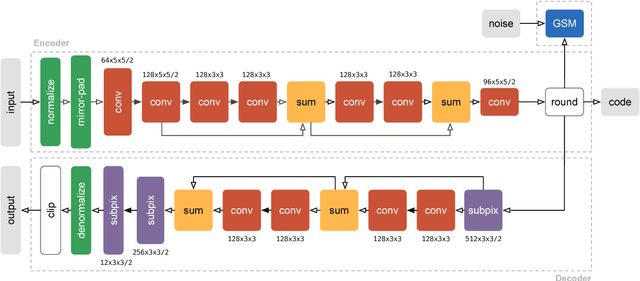
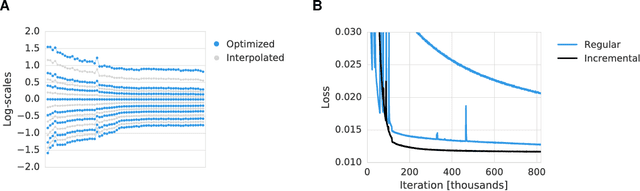
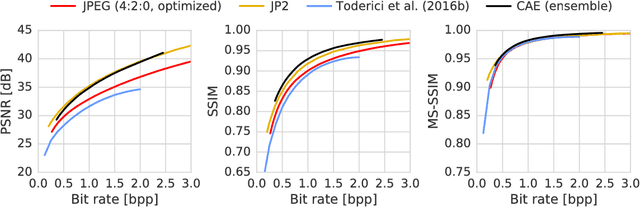
We propose a new approach to the problem of optimizing autoencoders for lossy image compression. New media formats, changing hardware technology, as well as diverse requirements and content types create a need for compression algorithms which are more flexible than existing codecs. Autoencoders have the potential to address this need, but are difficult to optimize directly due to the inherent non-differentiabilty of the compression loss. We here show that minimal changes to the loss are sufficient to train deep autoencoders competitive with JPEG 2000 and outperforming recently proposed approaches based on RNNs. Our network is furthermore computationally efficient thanks to a sub-pixel architecture, which makes it suitable for high-resolution images. This is in contrast to previous work on autoencoders for compression using coarser approximations, shallower architectures, computationally expensive methods, or focusing on small images.