 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGBT Salient Object Detection: A Large-scale Dataset and Benchmark
Jul 08, 2020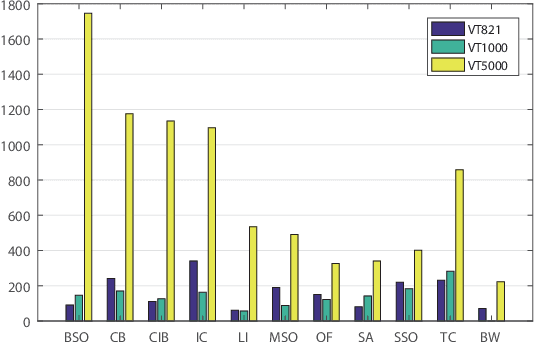

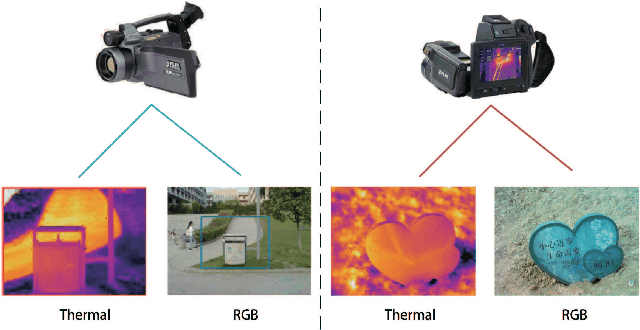
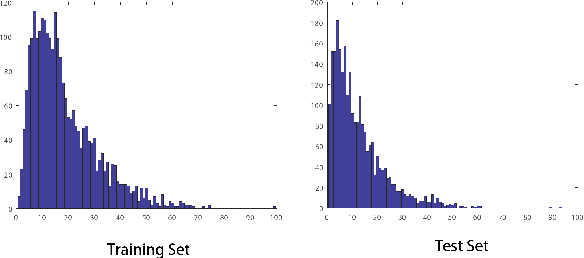
Salient object detection in complex scenes and environments is a challenging research topic. Most works focus on RGB-based salient object detection, which limits its performance of real-life applications when confronted with adverse conditions such as dark environments and complex backgrounds. Taking advantage of RGB and thermal infrared images becomes a new research direction for detecting salient object in complex scenes recently, as thermal infrared spectrum imaging provides the complementary information and has been applied to many computer vision tasks. However, current research for RGBT salient object detection is limited by the lack of a large-scale dataset and comprehensive benchmark. This work contributes such a RGBT image dataset named VT5000, including 5000 spatially aligned RGBT image pairs with ground truth annotations. VT5000 has 11 challenges collected in different scenes and environments for exploring the robustness of algorithms. With this dataset, we propose a powerful baseline approach, which extracts multi-level features within each modality and aggregates these features of all modalities with the attention mechanism, for accurate RGBT salient object detection. Extensive experiments show that the proposed baseline approach outperforms the state-of-the-art methods on VT5000 dataset and other two public datasets. In addition, we carry out a comprehensive analysis of different algorithms of RGBT salient object detection on VT5000 dataset, and then make several valuable conclusions and provide some potential research directions for RGBT salient object detection.
Multi-interactive Encoder-decoder Network for RGBT Salient Object Detection
May 05, 2020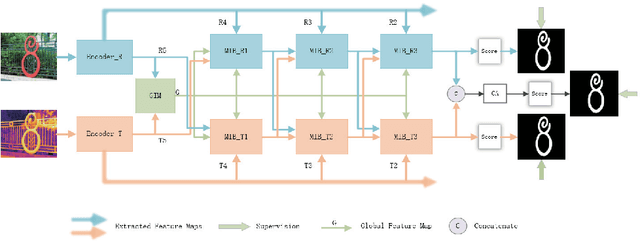
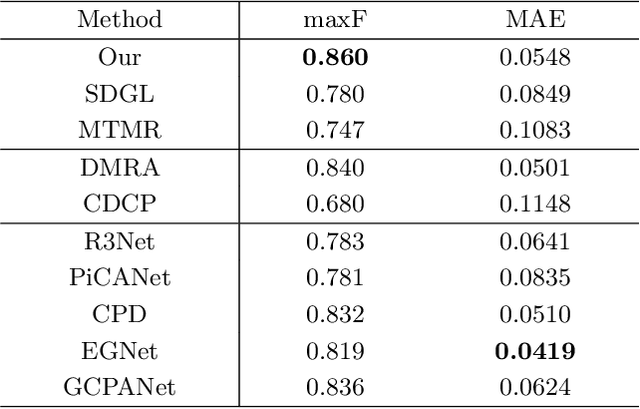
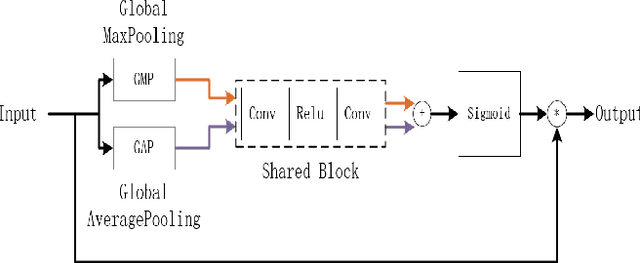
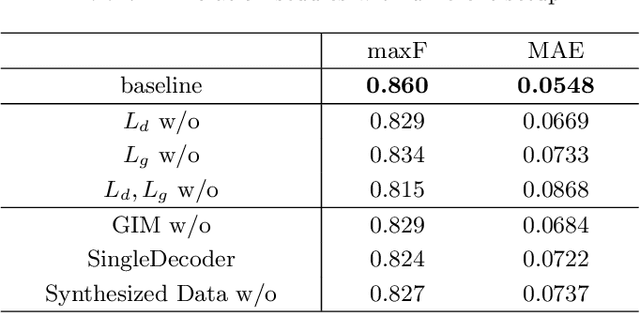
RGBT salient object detection (SOD) aims to segment the common prominent regions by exploring and exploiting the complementary information of visible and thermal infrared images. However, existing methods simply integrate features of these two modalities, and thus could not explore the potentials of their complementarity. In this paper, we propose a novel multi-interactive encoder-decoder network to achieve an elaborative fusion for RGBT SOD. Our network relies on an encoder-decoder for the feature extraction and fusion, and we design a multi-interaction block (MIB) to model the interactions of different modalities, different layers and local-global information. In particular, we interact and integrate the multi-level features of different modalities in a two-stream decoder, which could fuse modal information sufficiently while maintaining their own specific feature representations for more robust detection performance. Moreover, each MIB block accepts both information from previous MIB and global context to restore more spatial details and object semantics respectively. Extensive experiments on the existing RGBT SOD datasets show that the proposed method achieves outstanding performance against the state-of-the-art algorithms.