 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sparse Coding Driven Deep Decision Tree Ensembles for Nuclear Segmentation in Digital Pathology Images
Aug 13, 2020
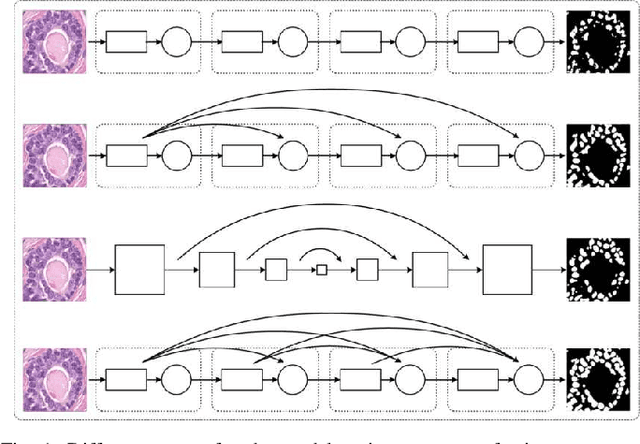
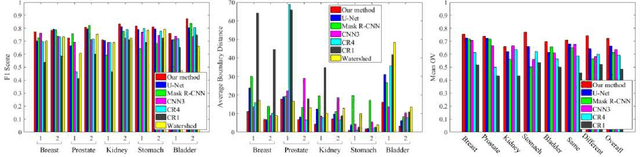
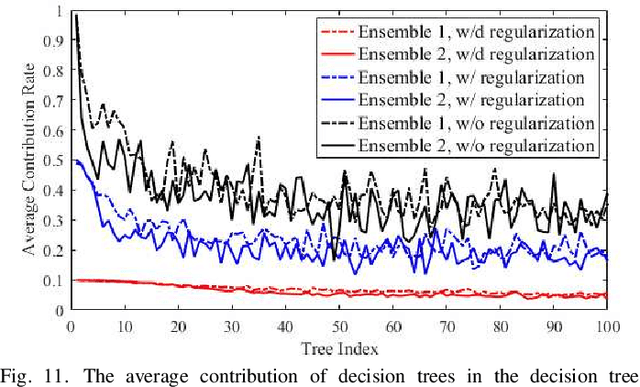
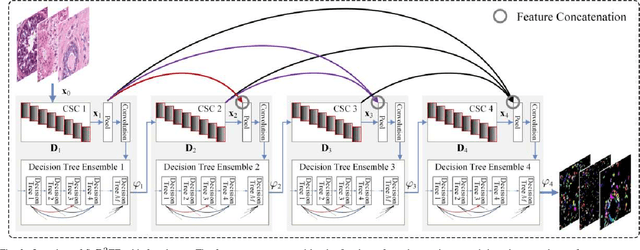
In this paper, we propose an easily trained yet powerful representation learning approach with performance highly competitive to deep neural networks in a digital pathology image segmentation task. The method, called sparse coding driven deep decision tree ensembles that we abbreviate as ScD2TE, provides a new perspective on representation learning. We explore the possibility of stacking several layers based on non-differentiable pairwise modules and generate a densely concatenated architecture holding the characteristics of feature map reuse and end-to-end dense learning. Under this architecture, fast convolutional sparse coding is used to extract multi-level features from the output of each layer. In this way, rich image appearance models together with more contextual information are integrated by learning a series of decision tree ensembles. The appearance and the high-level context features of all the previous layers are seamlessly combined by concatenating them to feed-forward as input, which in turn makes the outputs of subsequent layers more accurate and the whole model efficient to train. Compared with deep neural networks, our proposed ScD2TE does not require back-propagation computation and depends on less hyper-parameters. ScD2TE is able to achieve a fast end-to-end pixel-wise training in a layer-wise manner. We demonstrated the superiority of our segmentation technique by evaluating it on the multi-disease state and multi-organ dataset where consistently higher performances were obtained for comparison against several state-of-the-art deep learning methods such as convolutional neural networks (CNN), fully convolutional networks (FCN), etc.
Generative Adversarial Data Programming
Apr 30, 2020
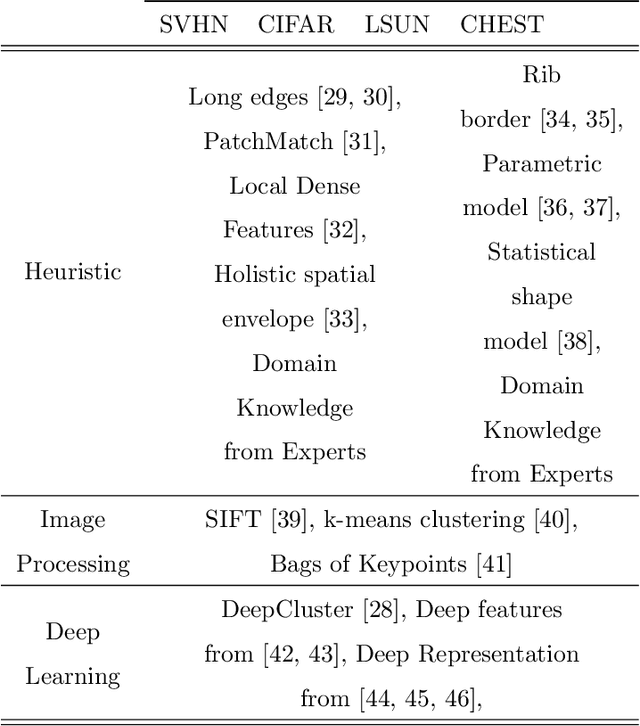
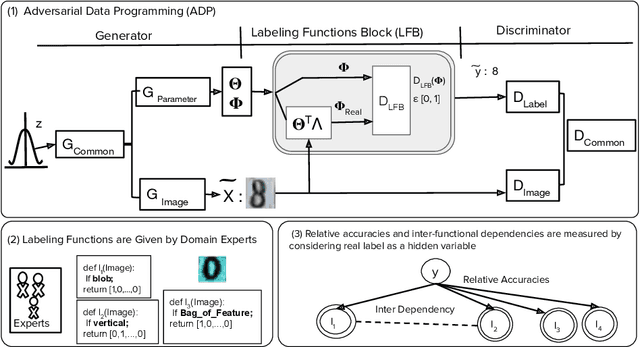
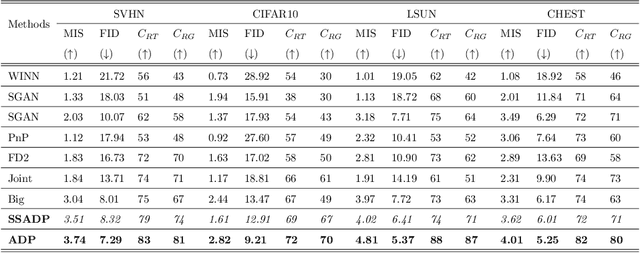
The paucity of large curated hand-labeled training data forms a major bottleneck in the deployment of machine learning models in computer vision and other fields. Recent work (Data Programming) has shown how distant supervision signals in the form of labeling functions can be used to obtain labels for given data in near-constant time. In this work, we present Adversarial Data Programming (ADP), which presents an adversarial methodology to generate data as well as a curated aggregated label, given a set of weak labeling functions. More interestingly, such labeling functions are often easily generalizable, thus allowing our framework to be extended to different setups, including self-supervised labeled image generation, zero-shot text to labeled image generation, transfer learning, and multi-task learning.
A Convex Similarity Index for Sparse Recovery of Missing Image Samples
Oct 17, 2017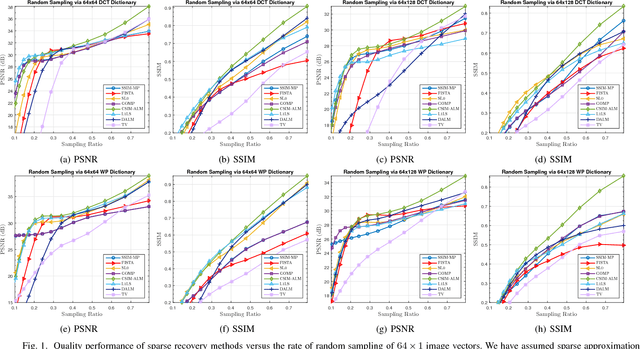
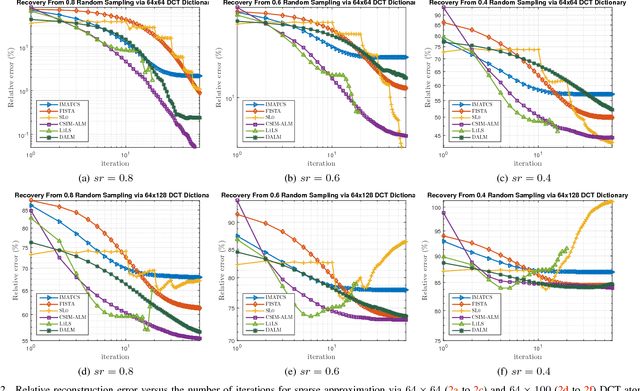
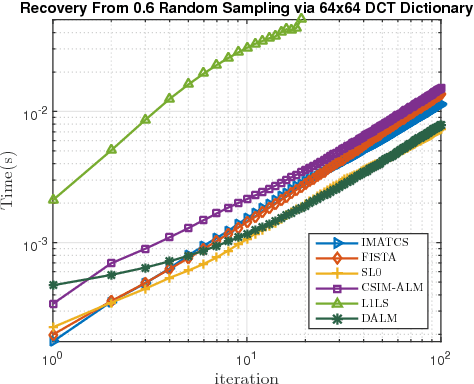
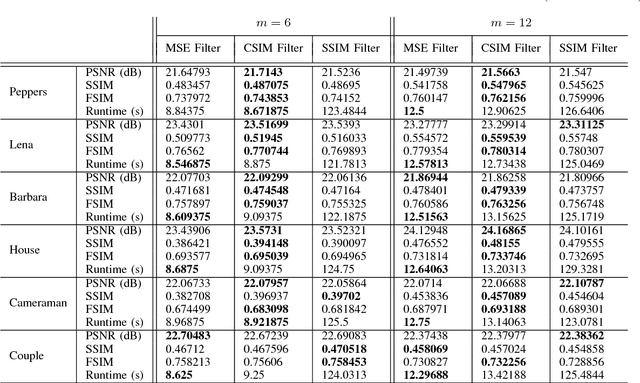
This paper investigates the problem of recovering missing samples using methods based on sparse representation adapted especially for image signals. Instead of $l_2$-norm or Mean Square Error (MSE), a new perceptual quality measure is used as the similarity criterion between the original and the reconstructed images. The proposed criterion called Convex SIMilarity (CSIM) index is a modified version of the Structural SIMilarity (SSIM) index, which despite its predecessor, is convex and uni-modal. We derive mathematical properties for the proposed index and show how to optimally choose the parameters of the proposed criterion, investigating the Restricted Isometry (RIP) and error-sensitivity properties. We also propose an iterative sparse recovery method based on a constrained $l_1$-norm minimization problem, incorporating CSIM as the fidelity criterion. The resulting convex optimization problem is solved via an algorithm based on Alternating Direction Method of Multipliers (ADMM). Taking advantage of the convexity of the CSIM index, we also prove the convergence of the algorithm to the globally optimal solution of the proposed optimization problem, starting from any arbitrary point. Simulation results confirm the performance of the new similarity index as well as the proposed algorithm for missing sample recovery of image patch signals.
AutoGAN-Distiller: Searching to Compress Generative Adversarial Networks
Jun 15, 2020
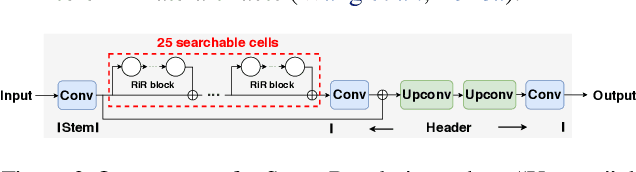
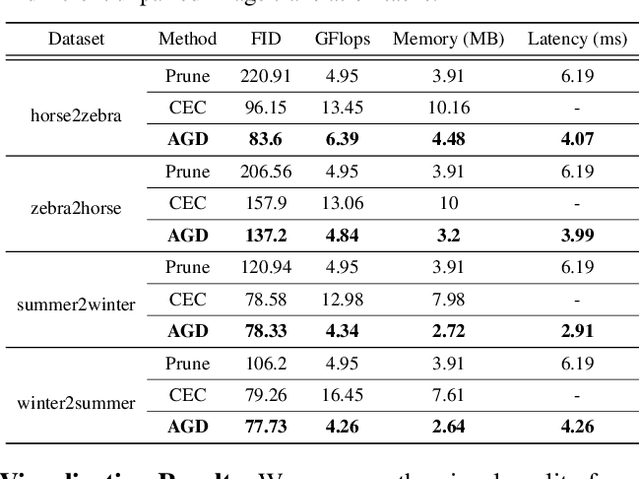

The compression of Generative Adversarial Networks (GANs) has lately drawn attention, due to the increasing demand for deploying GANs into mobile devices for numerous applications such as image translation, enhancement and editing. However, compared to the substantial efforts to compressing other deep models, the research on compressing GANs (usually the generators) remains at its infancy stage. Existing GAN compression algorithms are limited to handling specific GAN architectures and losses. Inspired by the recent success of AutoML in deep compression, we introduce AutoML to GAN compression and develop an AutoGAN-Distiller (AGD) framework. Starting with a specifically designed efficient search space, AGD performs an end-to-end discovery for new efficient generators, given the target computational resource constraints. The search is guided by the original GAN model via knowledge distillation, therefore fulfilling the compression. AGD is fully automatic, standalone (i.e., needing no trained discriminators), and generically applicable to various GAN models. We evaluate AGD in two representative GAN tasks: image translation and super resolution. Without bells and whistles, AGD yields remarkably lightweight yet more competitive compressed models, that largely outperform existing alternatives.
Shadow Removal by a Lightness-Guided Network with Training on Unpaired Data
Jun 28, 2020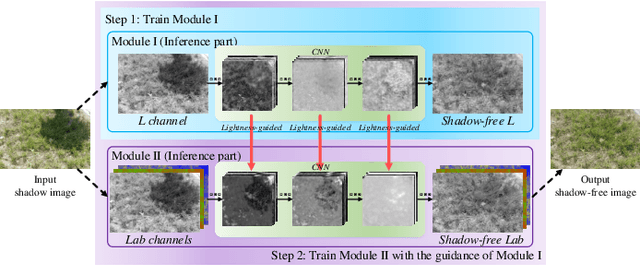
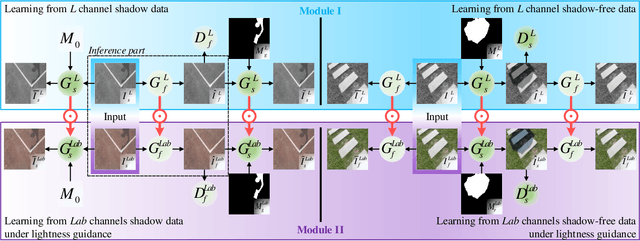
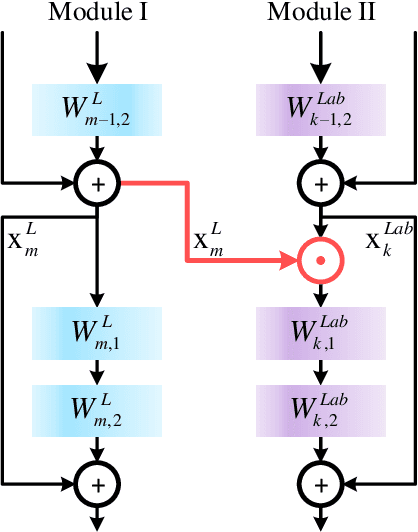
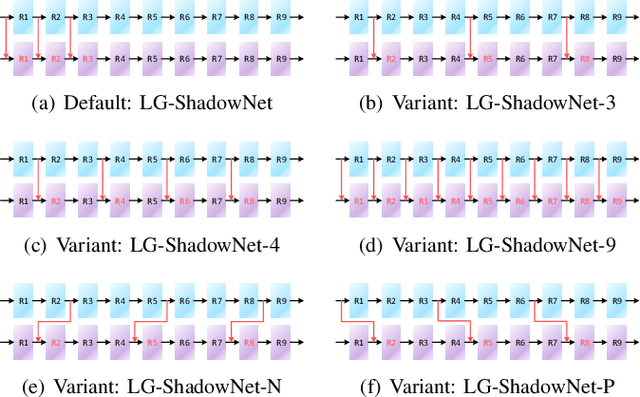
Shadow removal can significantly improve the image visual quality and has many applications in computer vision. Deep learning methods based on CNNs have become the most effective approach for shadow removal by training on either paired data, where both the shadow and underlying shadow-free versions of an image are known, or unpaired data, where shadow and shadow-free training images are totally different with no correspondence. In practice, CNN training on unpaired data is more preferred given the easiness of training data collection. In this paper, we present a new Lightness-Guided Shadow Removal Network (LG-ShadowNet) for shadow removal by training on unpaired data. In this method, we first train a CNN module to compensate for the lightness and then train a second CNN module with the guidance of lightness information from the first CNN module for final shadow removal. We also introduce a loss function to further utilise the colour prior of existing data. Extensive experiments on widely used ISTD, adjusted ISTD and USR datasets demonstrate that the proposed method outperforms the state-of-the-art methods with training on unpaired data.
Encryption Inspired Adversarial Defense for Visual Classification
May 16, 2020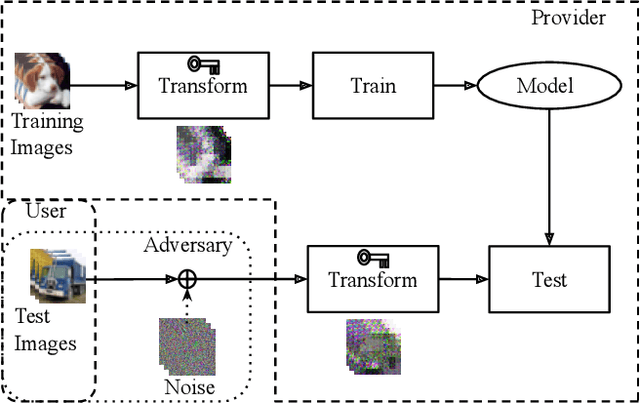
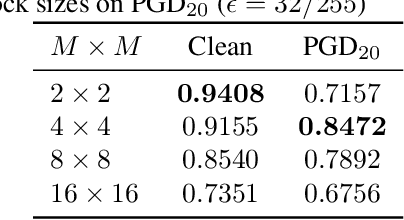
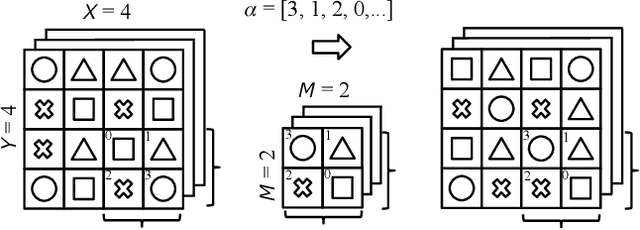

Conventional adversarial defenses reduce classification accuracy whether or not a model is under attacks. Moreover, most of image processing based defenses are defeated due to the problem of obfuscated gradients. In this paper, we propose a new adversarial defense which is a defensive transform for both training and test images inspired by perceptual image encryption methods. The proposed method utilizes a block-wise pixel shuffling method with a secret key. The experiments are carried out on both adaptive and non-adaptive maximum-norm bounded white-box attacks while considering obfuscated gradients. The results show that the proposed defense achieves high accuracy (91.55 %) on clean images and (89.66 %) on adversarial examples with noise distance of 8/255 on CIFAR-10 dataset. Thus, the proposed defense outperforms state-of-the-art adversarial defenses including latent adversarial training, adversarial training and thermometer encoding.
Critical analysis on the reproducibility of visual quality assessment using deep features
Sep 10, 2020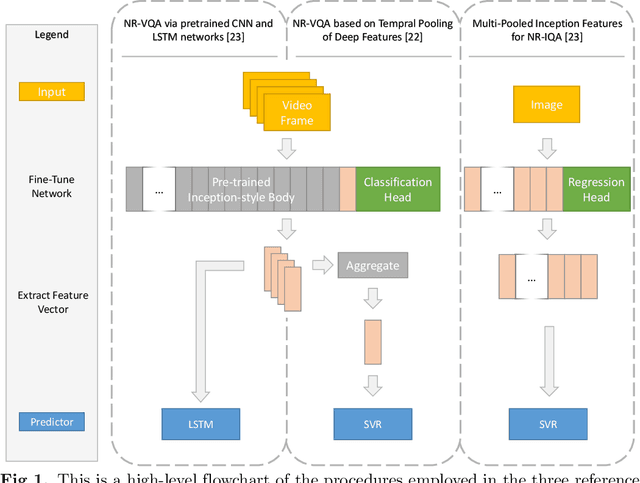
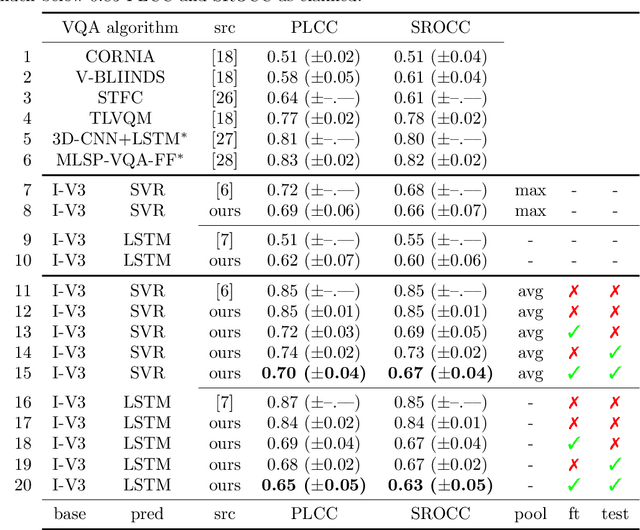
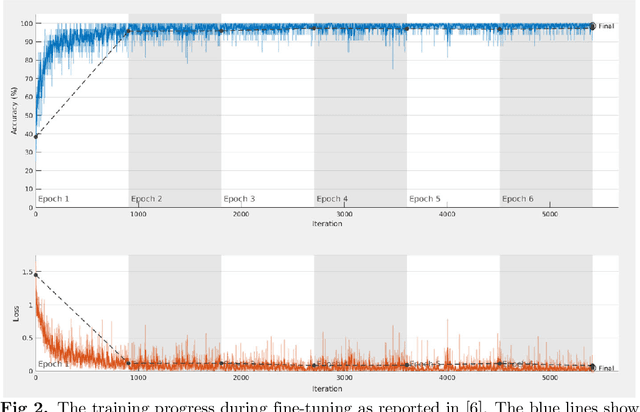
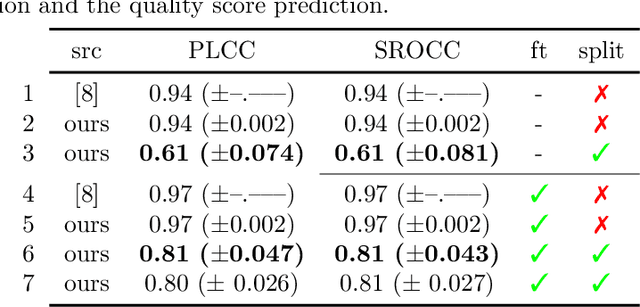
Data used to train supervised machine learning models are commonly split into independent training, validation, and test sets. In this paper we illustrate that intricate cases of data leakage have occurred in the no-reference video and image quality assessment literature. We show that the performance results of several recently published journal papers that are well above the best performances in related works, cannot be reached. Our analysis shows that information from the test set was inappropriately used in the training process in different ways. When correcting for the data leakage, the performances of the approaches drop below the state-of-the-art by a large margin. Additionally, we investigate end-to-end variations to the discussed approaches, which do not improve upon the original.
Signs in time: Encoding human motion as a temporal image
Aug 06, 2016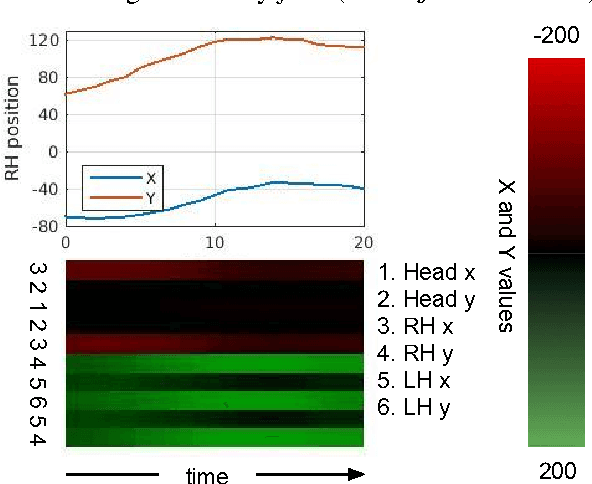
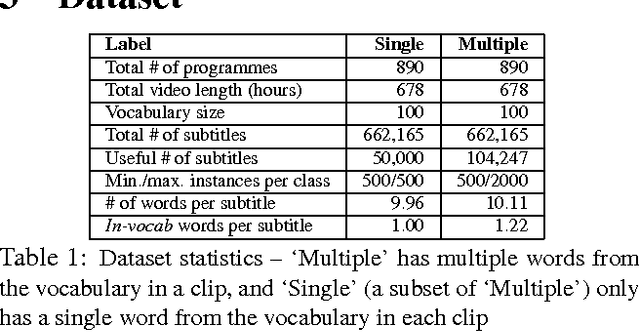

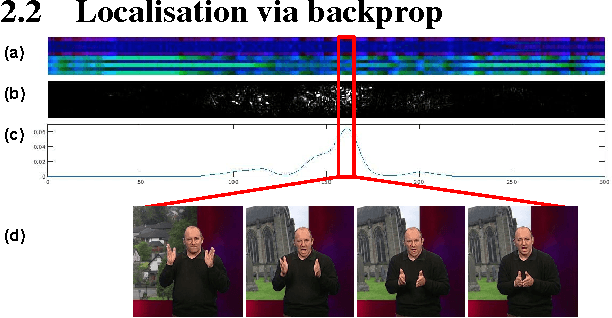
The goal of this work is to recognise and localise short temporal signals in image time series, where strong supervision is not available for training. To this end we propose an image encoding that concisely represents human motion in a video sequence in a form that is suitable for learning with a ConvNet. The encoding reduces the pose information from an image to a single column, dramatically diminishing the input requirements for the network, but retaining the essential information for recognition. The encoding is applied to the task of recognizing and localizing signed gestures in British Sign Language (BSL) videos. We demonstrate that using the proposed encoding, signs as short as 10 frames duration can be learnt from clips lasting hundreds of frames using only weak (clip level) supervision and with considerable label noise.
Memory-based Jitter: Improving Visual Recognition on Long-tailed Data with Diversity In Memory
Aug 22, 2020
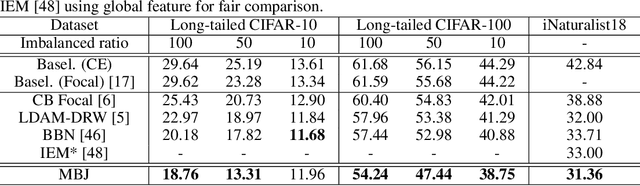
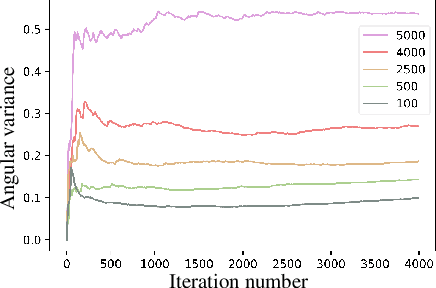
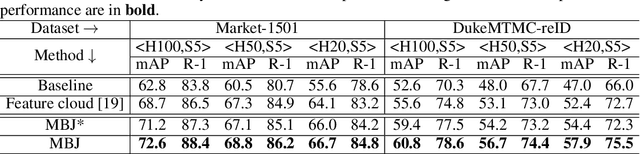
This paper considers deep visual recognition on long-tailed data, with the majority categories only occupying relatively few samples. The tail categories are prone to lack of within-class diversity, which compromises the representative ability of the learned visual concepts. A radical solution is to augment the tail categories with higher diversity. To this end, we introduce a simple and reliable method named Memory-based Jitter (MBJ) to gain extra diversity for the tail data. We observe that the deep model keeps on jittering from one historical edition to another, even when it already approaches convergence. The ``jitter'' means the small variations between historical models. We argue that such jitter largely originates from the within-class diversity of the overall data and thus encodes the within-class distribution pattern. To utilize such jitter for tail data augmentation, we store the jitter among historical models into a memory bank and get the so-called Memory-based Jitter. With slight modifications, MBJ is applicable for two fundamental visual recognition tasks, \emph{i.e.}, image classification and deep metric learning (on long-tailed data). On image classification, MBJ collects the historical embeddings to learn an accurate classifier. In contrast, on deep metric learning, it collects the historical prototypes of each class to learn a robust deep embedding. Under both scenarios, MBJ enforces higher concentration on tail classes, so as to compensate for their lack of diversity. Extensive experiments on three long-tailed classification benchmarks and two deep metric learning benchmarks (person re-identification, in particular) demonstrate the significant improvement. Moreover, the achieved performance are on par with the state-of-the-art on both tasks.
Color Image Retrieval Using Fuzzy Measure Hamming and S-Tree
Jun 03, 2015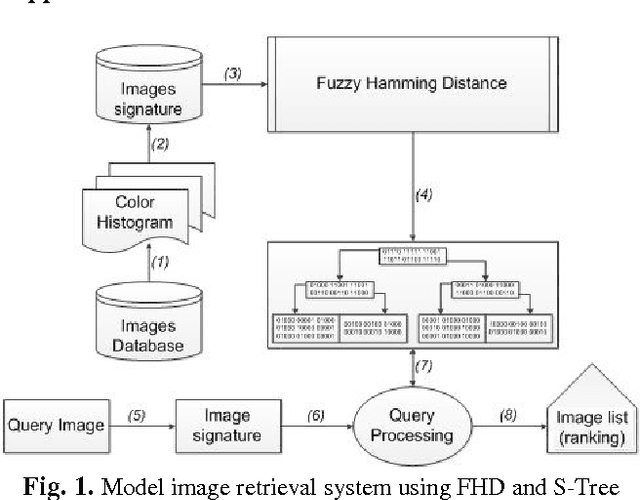
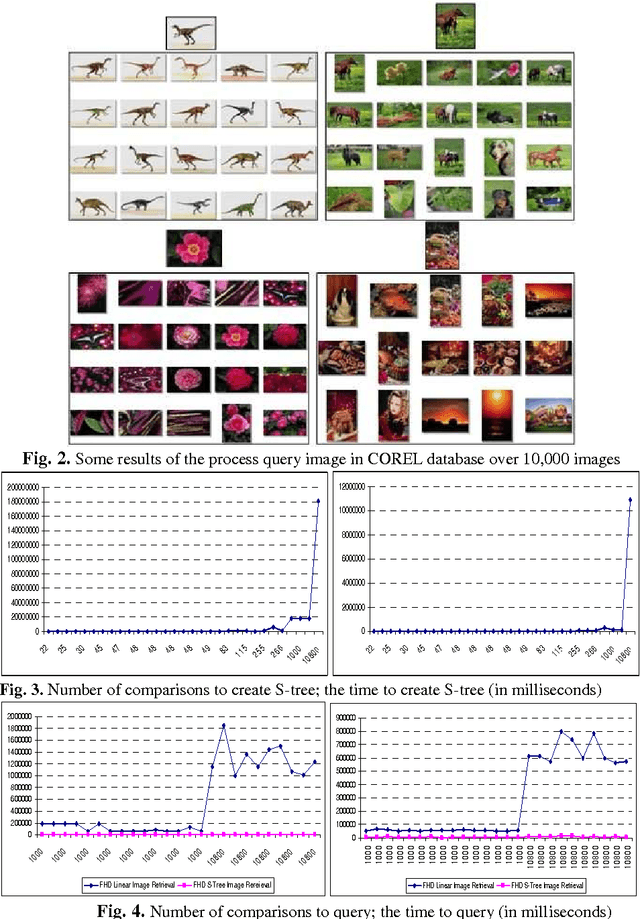
This chapter approaches the image retrieval system on the base of the colors of image. It creates fuzzy signature to describe the color of image on color space HSV and builds fuzzy Hamming distance (FHD) to evaluate the similarity between the images. In order to reduce the storage space and speed up the search of similar images, it aims to create S-tree to store fuzzy signature relies on FHD and builds image retrieval algorithm on S-tree. Then, it provides the content-based image retrieval (CBIR) and an image retrieval method on FHD and S-tree. Last but not least, based on this theory, it also presents an application and experimental assessment of the process of querying similar image on the database system over 10,000 images.