 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Intrinsic Scale Assessment: Bridging the Gap Between Quality and Resolution
Feb 10, 2025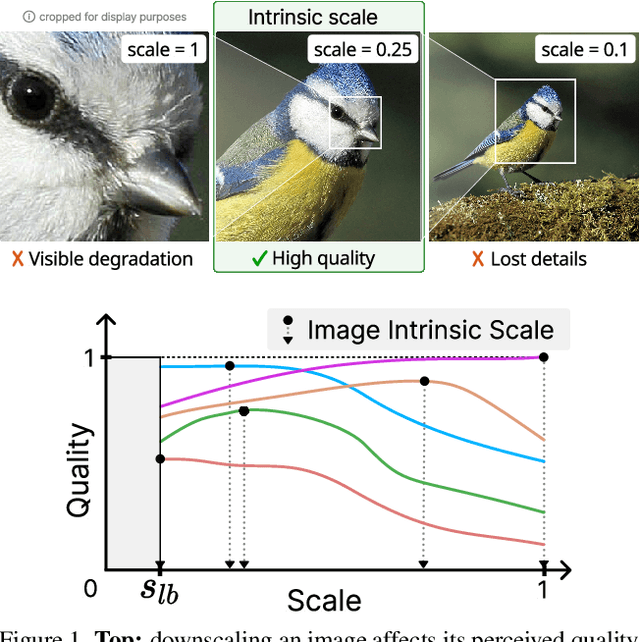
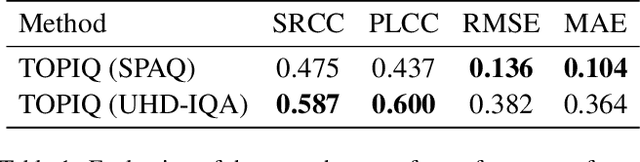
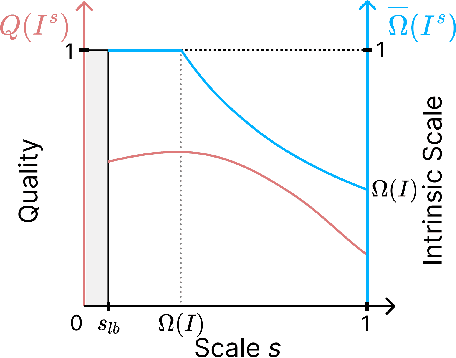

Image Quality Assessment (IQA) measures and predicts perceived image quality by human observers. Although recent studies have highlighted the critical influence that variations in the scale of an image have on its perceived quality, this relationship has not been systematically quantified. To bridge this gap, we introduce the Image Intrinsic Scale (IIS), defined as the largest scale where an image exhibits its highest perceived quality. We also present the Image Intrinsic Scale Assessment (IISA) task, which involves subjectively measuring and predicting the IIS based on human judgments. We develop a subjective annotation methodology and create the IISA-DB dataset, comprising 785 image-IIS pairs annotated by experts in a rigorously controlled crowdsourcing study. Furthermore, we propose WIISA (Weak-labeling for Image Intrinsic Scale Assessment), a strategy that leverages how the IIS of an image varies with downscaling to generate weak labels. Experiments show that applying WIISA during the training of several IQA methods adapted for IISA consistently improves the performance compared to using only ground-truth labels. We will release the code, dataset, and pre-trained models upon acceptance.
AIM 2024 Challenge on UHD Blind Photo Quality Assessment
Sep 24, 2024



We introduce the AIM 2024 UHD-IQA Challenge, a competition to advance the No-Reference Image Quality Assessment (NR-IQA) task for modern, high-resolution photos. The challenge is based on the recently released UHD-IQA Benchmark Database, which comprises 6,073 UHD-1 (4K) images annotated with perceptual quality ratings from expert raters. Unlike previous NR-IQA datasets, UHD-IQA focuses on highly aesthetic photos of superior technical quality, reflecting the ever-increasing standards of digital photography. This challenge aims to develop efficient and effective NR-IQA models. Participants are tasked with creating novel architectures and training strategies to achieve high predictive performance on UHD-1 images within a computational budget of 50G MACs. This enables model deployment on edge devices and scalable processing of extensive image collections. Winners are determined based on a combination of performance metrics, including correlation measures (SRCC, PLCC, KRCC), absolute error metrics (MAE, RMSE), and computational efficiency (G MACs). To excel in this challenge, participants leverage techniques like knowledge distillation, low-precision inference, and multi-scale training. By pushing the boundaries of NR-IQA for high-resolution photos, the UHD-IQA Challenge aims to stimulate the development of practical models that can keep pace with the rapidly evolving landscape of digital photography. The innovative solutions emerging from this competition will have implications for various applications, from photo curation and enhancement to image compression.
UHD-IQA Benchmark Database: Pushing the Boundaries of Blind Photo Quality Assessment
Jun 25, 2024We introduce a novel Image Quality Assessment (IQA) dataset comprising 6073 UHD-1 (4K) images, annotated at a fixed width of 3840 pixels. Contrary to existing No-Reference (NR) IQA datasets, ours focuses on highly aesthetic photos of high technical quality, filling a gap in the literature. The images, carefully curated to exclude synthetic content, are sufficiently diverse to train general NR-IQA models. The dataset is annotated with perceptual quality ratings obtained through a crowdsourcing study. Ten expert raters, comprising photographers and graphics artists, assessed each image at least twice in multiple sessions spanning several days, resulting in highly reliable labels. Annotators were rigorously selected based on several metrics, including self-consistency, to ensure their reliability. The dataset includes rich metadata with user and machine-generated tags from over 5,000 categories and popularity indicators such as favorites, likes, downloads, and views. With its unique characteristics, such as its focus on high-quality images, reliable crowdsourced annotations, and high annotation resolution, our dataset opens up new opportunities for advancing perceptual image quality assessment research and developing practical NR-IQA models that apply to modern photos. Our dataset is available at https://database.mmsp-kn.de/uhd-iqa-benchmark-database.html
KonX: Cross-Resolution Image Quality Assessment
Dec 12, 2022Scale-invariance is an open problem in many computer vision subfields. For example, object labels should remain constant across scales, yet model predictions diverge in many cases. This problem gets harder for tasks where the ground-truth labels change with the presentation scale. In image quality assessment (IQA), downsampling attenuates impairments, e.g., blurs or compression artifacts, which can positively affect the impression evoked in subjective studies. To accurately predict perceptual image quality, cross-resolution IQA methods must therefore account for resolution-dependent errors induced by model inadequacies as well as for the perceptual label shifts in the ground truth. We present the first study of its kind that disentangles and examines the two issues separately via KonX, a novel, carefully crafted cross-resolution IQA database. This paper contributes the following: 1. Through KonX, we provide empirical evidence of label shifts caused by changes in the presentation resolution. 2. We show that objective IQA methods have a scale bias, which reduces their predictive performance. 3. We propose a multi-scale and multi-column DNN architecture that improves performance over previous state-of-the-art IQA models for this task, including recent transformers. We thus both raise and address a novel research problem in image quality assessment.
Fairness in generative modeling
Oct 06, 2022
We design general-purpose algorithms for addressing fairness issues and mode collapse in generative modeling. More precisely, to design fair algorithms for as many sensitive variables as possible, including variables we might not be aware of, we assume no prior knowledge of sensitive variables: our algorithms use unsupervised fairness only, meaning no information related to the sensitive variables is used for our fairness-improving methods. All images of faces (even generated ones) have been removed to mitigate legal risks.
Going the Extra Mile in Face Image Quality Assessment: A Novel Database and Model
Jul 11, 2022
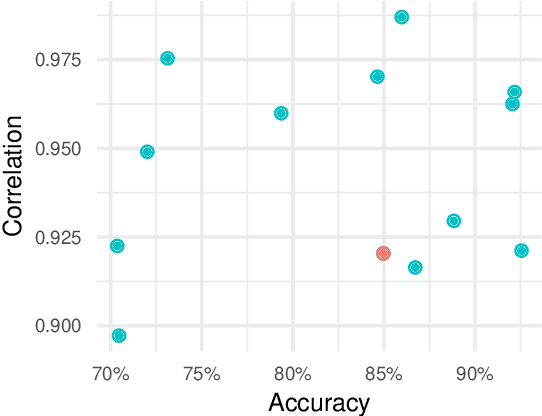

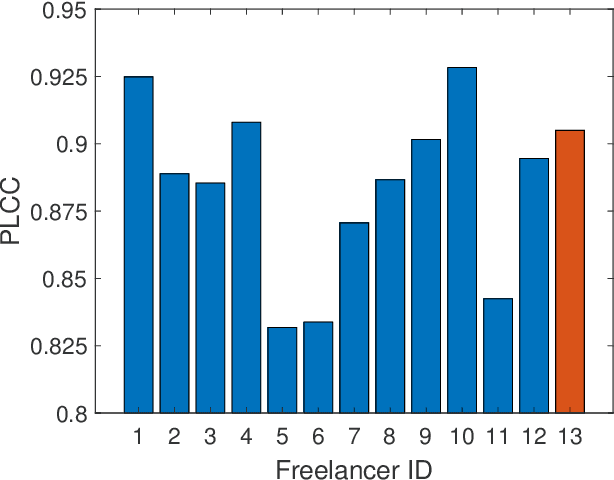
Computer vision models for image quality assessment (IQA) predict the subjective effect of generic image degradation, such as artefacts, blurs, bad exposure, or colors. The scarcity of face images in existing IQA datasets (below 10\%) is limiting the precision of IQA required for accurately filtering low-quality face images or guiding CV models for face image processing, such as super-resolution, image enhancement, and generation. In this paper, we first introduce the largest annotated IQA database to date that contains 20,000 human faces (an order of magnitude larger than all existing rated datasets of faces), of diverse individuals, in highly varied circumstances, quality levels, and distortion types. Based on the database, we further propose a novel deep learning model, which re-purposes generative prior features for predicting subjective face quality. By exploiting rich statistics encoded in well-trained generative models, we obtain generative prior information of the images and serve them as latent references to facilitate the blind IQA task. Experimental results demonstrate the superior prediction accuracy of the proposed model on the face IQA task.
EvolGAN: Evolutionary Generative Adversarial Networks
Sep 28, 2020

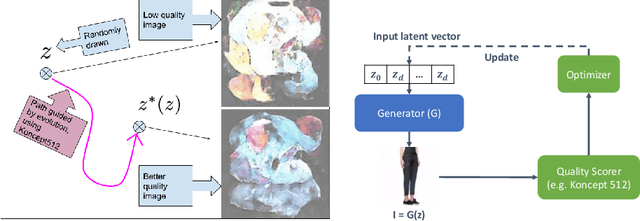
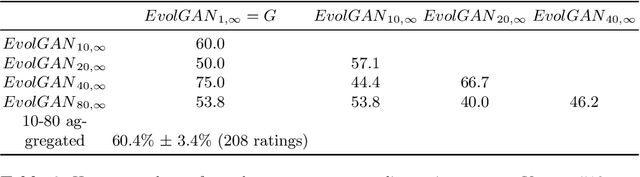
We propose to use a quality estimator and evolutionary methods to search the latent space of generative adversarial networks trained on small, difficult datasets, or both. The new method leads to the generation of significantly higher quality images while preserving the original generator's diversity. Human raters preferred an image from the new version with frequency 83.7pc for Cats, 74pc for FashionGen, 70.4pc for Horses, and 69.2pc for Artworks, and minor improvements for the already excellent GANs for faces. This approach applies to any quality scorer and GAN generator.
Tarsier: Evolving Noise Injection in Super-Resolution GANs
Sep 25, 2020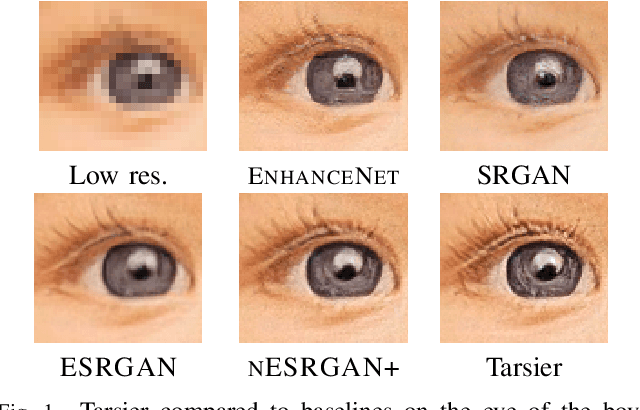

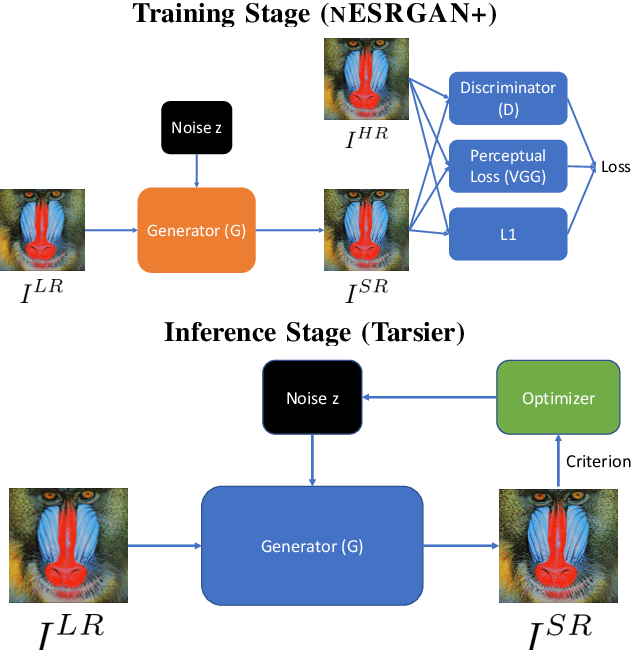
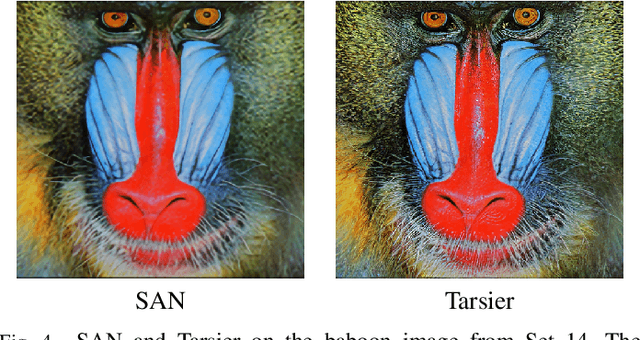
Super-resolution aims at increasing the resolution and level of detail within an image. The current state of the art in general single-image super-resolution is held by NESRGAN+, which injects a Gaussian noise after each residual layer at training time. In this paper, we harness evolutionary methods to improve NESRGAN+ by optimizing the noise injection at inference time. More precisely, we use Diagonal CMA to optimize the injected noise according to a novel criterion combining quality assessment and realism. Our results are validated by the PIRM perceptual score and a human study. Our method outperforms NESRGAN+ on several standard super-resolution datasets. More generally, our approach can be used to optimize any method based on noise injection.
Critical analysis on the reproducibility of visual quality assessment using deep features
Sep 10, 2020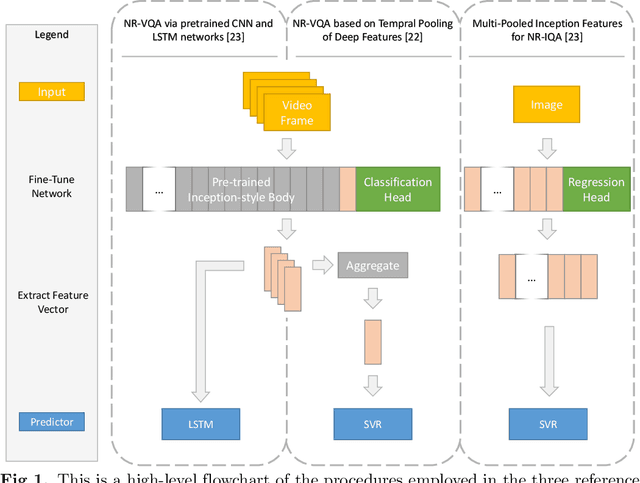
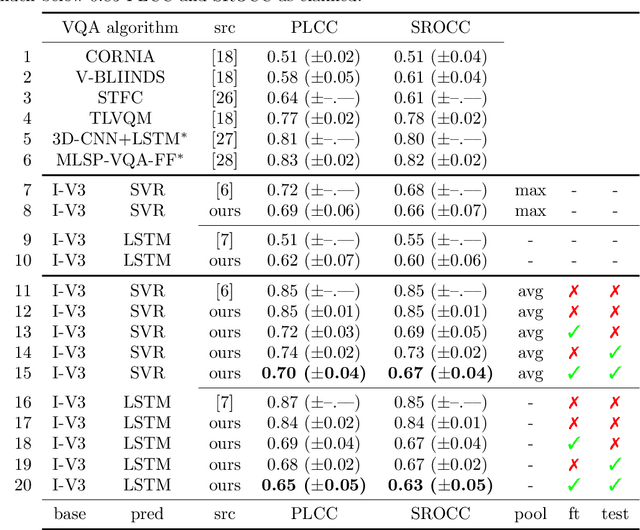
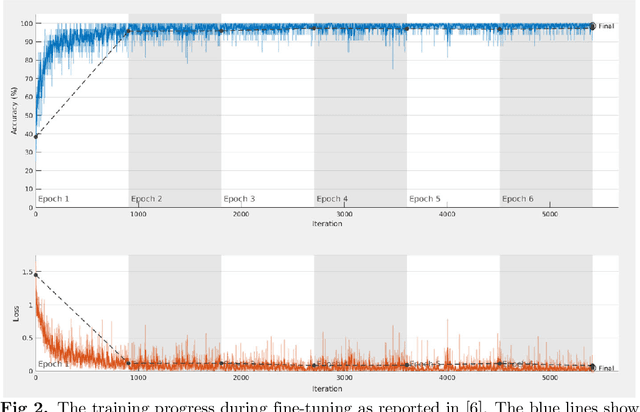
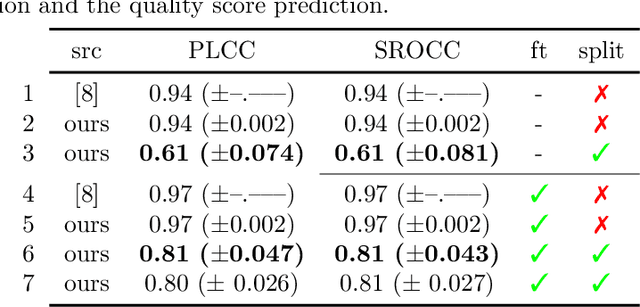
Data used to train supervised machine learning models are commonly split into independent training, validation, and test sets. In this paper we illustrate that intricate cases of data leakage have occurred in the no-reference video and image quality assessment literature. We show that the performance results of several recently published journal papers that are well above the best performances in related works, cannot be reached. Our analysis shows that information from the test set was inappropriately used in the training process in different ways. When correcting for the data leakage, the performances of the approaches drop below the state-of-the-art by a large margin. Additionally, we investigate end-to-end variations to the discussed approaches, which do not improve upon the original.
Comment on "No-Reference Video Quality Assessment Based on the Temporal Pooling of Deep Features"
May 09, 2020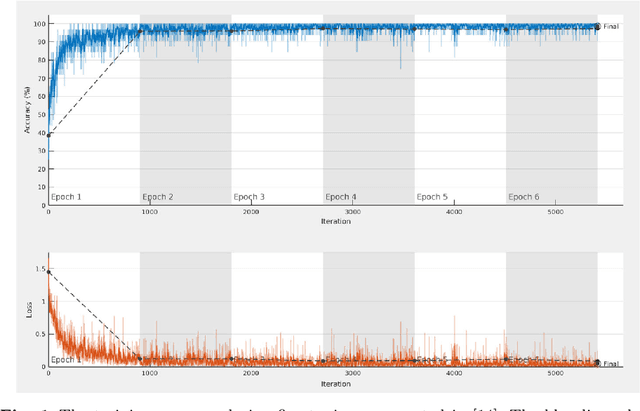
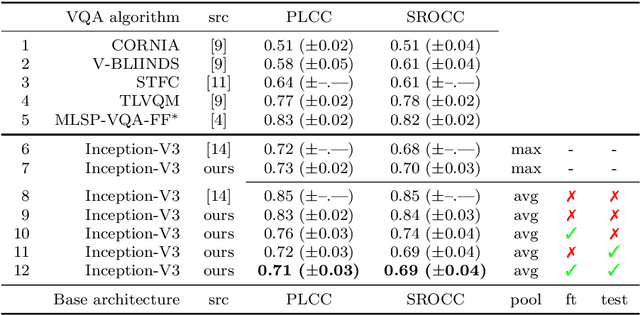

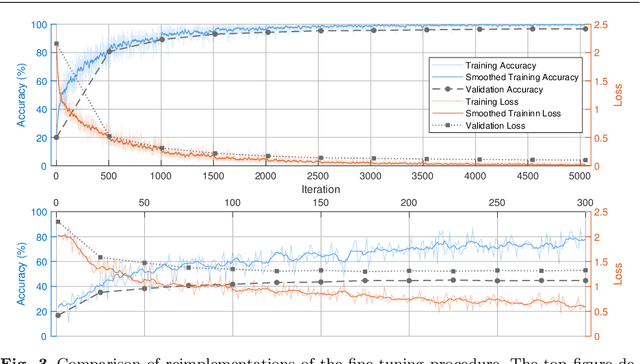
In Neural Processing Letters 50,3 (2019) a machine learning approach to blind video quality assessment was proposed. It is based on temporal pooling of features of video frames, taken from the last pooling layer of deep convolutional neural networks. The method was validated on two established benchmark datasets and gave results far better than the previous state-of-the-art. In this letter we report the results from our careful reimplementations. The performance results, claimed in the paper, cannot be reached, and are even below the state-of-the-art by a large margin. We show that the originally reported wrong performance results are a consequence of two cases of data leakage. Information from outside the training dataset was used in the fine-tuning stage and in the model evaluation.