 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RAPiD: Rotation-Aware People Detection in Overhead Fisheye Images
May 23, 2020


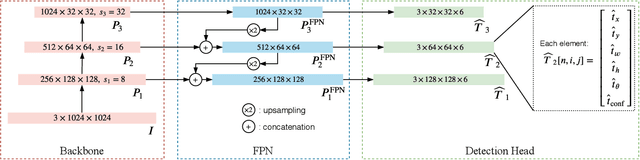
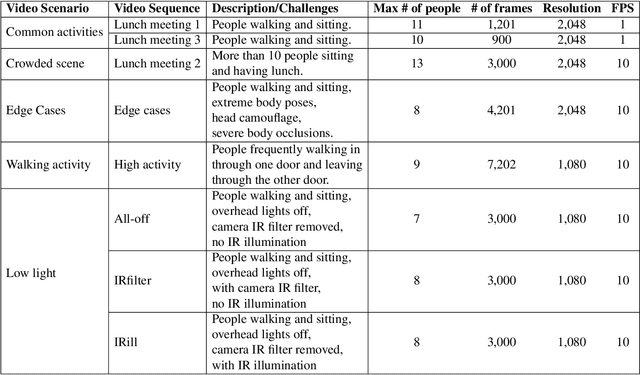
Recent methods for people detection in overhead, fisheye images either use radially-aligned bounding boxes to represent people, assuming people always appear along image radius or require significant pre-/post-processing which radically increases computational complexity. In this work, we develop an end-to-end rotation-aware people detection method, named RAPiD, that detects people using arbitrarily-oriented bounding boxes. Our fully-convolutional neural network directly regresses the angle of each bounding box using a periodic loss function, which accounts for angle periodicities. We have also created a new dataset with spatio-temporal annotations of rotated bounding boxes, for people detection as well as other vision tasks in overhead fisheye videos. We show that our simple, yet effective method outperforms state-of-the-art results on three fisheye-image datasets. Code and dataset are available at http://vip.bu.edu/rapid .
CryoNuSeg: A Dataset for Nuclei Instance Segmentation of Cryosectioned H&E-Stained Histological Images
Jan 02, 2021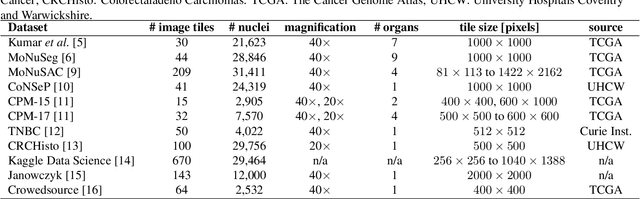
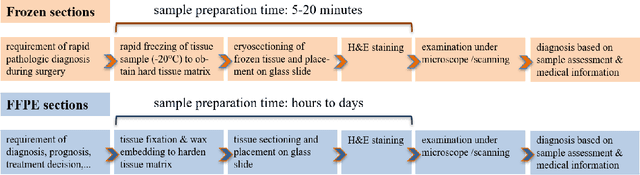
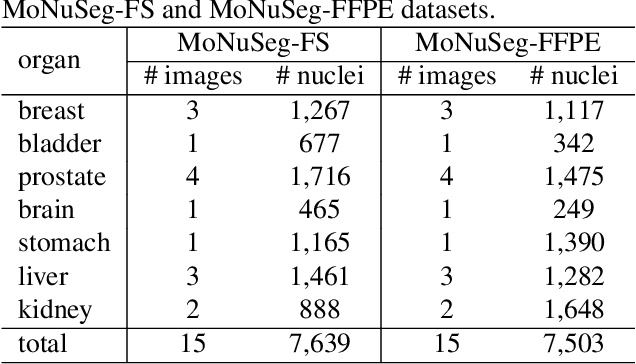
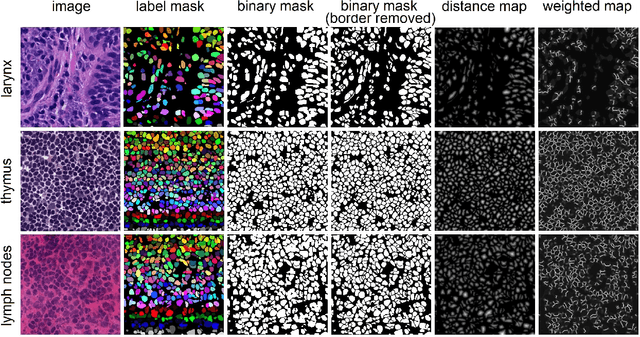
Nuclei instance segmentation plays an important role in the analysis of Hematoxylin and Eosin (H&E)-stained images. While supervised deep learning (DL)-based approaches represent the state-of-the-art in automatic nuclei instance segmentation, annotated datasets are required to train these models. There are two main types of tissue processing protocols, namely formalin-fixed paraffin-embedded samples (FFPE) and frozen tissue samples (FS). Although FFPE-derived H&E stained tissue sections are the most widely used samples, H&E staining on frozen sections derived from FS samples is a relevant method in intra-operative surgical sessions as it can be performed fast. Due to differences in the protocols of these two types of samples, the derived images and in particular the nuclei appearance may be different in the acquired whole slide images. Analysis of FS-derived H&E stained images can be more challenging as rapid preparation, staining, and scanning of FS sections may lead to deterioration in image quality. In this paper, we introduce CryoNuSeg, the first fully annotated FS-derived cryosectioned and H&E-stained nuclei instance segmentation dataset. The dataset contains images from 10 human organs that were not exploited in other publicly available datasets, and is provided with three manual mark-ups to allow measuring intra-observer and inter-observer variability. Moreover, we investigate the effects of tissue fixation/embedding protocol (i.e., FS or FFPE) on the automatic nuclei instance segmentation performance of one of the state-of-the-art DL approaches. We also create a baseline segmentation benchmark for the dataset that can be used in future research. A step-by-step guide to generate the dataset as well as the full dataset and other detailed information are made available to fellow researchers at https://github.com/masih4/CryoNuSeg.
A Gated Peripheral-Foveal Convolutional Neural Network for Unified Image Aesthetic Prediction
Dec 19, 2018
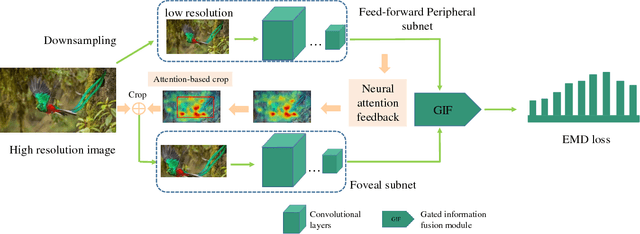
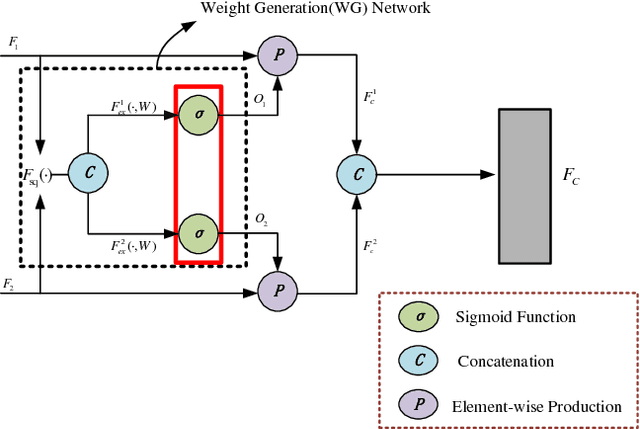

Learning fine-grained details is a key issue in image aesthetic assessment. Most of the previous methods extract the fine-grained details via random cropping strategy, which may undermine the integrity of semantic information. Extensive studies show that humans perceive fine-grained details with a mixture of foveal vision and peripheral vision. Fovea has the highest possible visual acuity and is responsible for seeing the details. The peripheral vision is used for perceiving the broad spatial scene and selecting the attended regions for the fovea. Inspired by these observations, we propose a Gated Peripheral-Foveal Convolutional Neural Network (GPF-CNN). It is a dedicated double-subnet neural network, i.e. a peripheral subnet and a foveal subnet. The former aims to mimic the functions of peripheral vision to encode the holistic information and provide the attended regions. The latter aims to extract fine-grained features on these key regions. Considering that the peripheral vision and foveal vision play different roles in processing different visual stimuli, we further employ a gated information fusion (GIF) network to weight their contributions. The weights are determined through the fully connected layers followed by a sigmoid function. We conduct comprehensive experiments on the standard AVA and Photo.net datasets for unified aesthetic prediction tasks: (i) aesthetic quality classification; (ii) aesthetic score regression; and (iii) aesthetic score distribution prediction. The experimental results demonstrate the effectiveness of the proposed method.
PaXNet: Dental Caries Detection in Panoramic X-ray using Ensemble Transfer Learning and Capsule Classifier
Dec 26, 2020

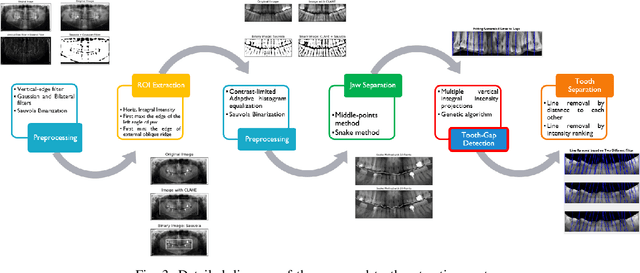
Dental caries is one of the most chronic diseases involving the majority of the population during their lifetime. Caries lesions are typically diagnosed by radiologists relying only on their visual inspection to detect via dental x-rays. In many cases, dental caries is hard to identify using x-rays and can be misinterpreted as shadows due to different reasons such as low image quality. Hence, developing a decision support system for caries detection has been a topic of interest in recent years. Here, we propose an automatic diagnosis system to detect dental caries in Panoramic images for the first time, to the best of authors' knowledge. The proposed model benefits from various pretrained deep learning models through transfer learning to extract relevant features from x-rays and uses a capsule network to draw prediction results. On a dataset of 470 Panoramic images used for features extraction, including 240 labeled images for classification, our model achieved an accuracy score of 86.05\% on the test set. The obtained score demonstrates acceptable detection performance and an increase in caries detection speed, as long as the challenges of using Panoramic x-rays of real patients are taken into account. Among images with caries lesions in the test set, our model acquired recall scores of 69.44\% and 90.52\% for mild and severe ones, confirming the fact that severe caries spots are more straightforward to detect and efficient mild caries detection needs a more robust and larger dataset. Considering the novelty of current research study as using Panoramic images, this work is a step towards developing a fully automated efficient decision support system to assist domain experts.
Open-Vocabulary Object Detection Using Captions
Nov 20, 2020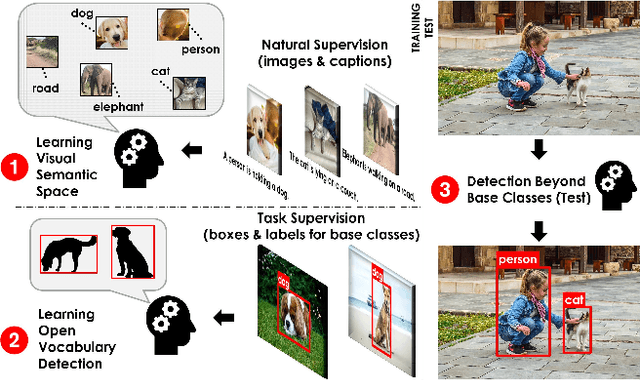
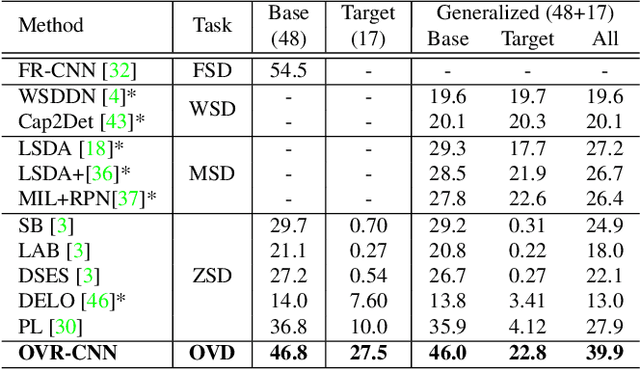
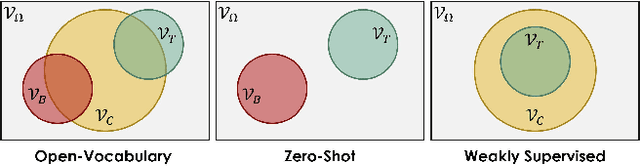
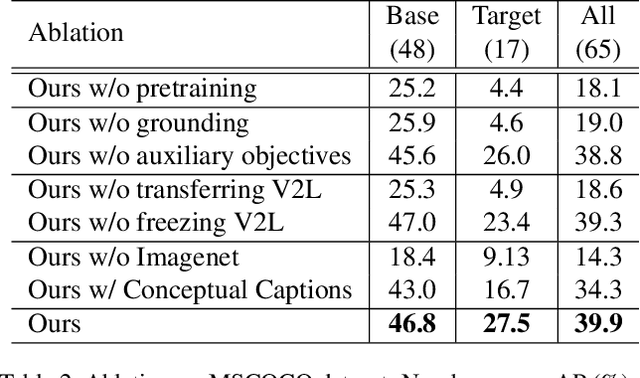
Despite the remarkable accuracy of deep neural networks in object detection, they are costly to train and scale due to supervision requirements. Particularly, learning more object categories typically requires proportionally more bounding box annotations. Weakly supervised and zero-shot learning techniques have been explored to scale object detectors to more categories with less supervision, but they have not been as successful and widely adopted as supervised models. In this paper, we put forth a novel formulation of the object detection problem, namely open-vocabulary object detection, which is more general, more practical, and more effective than weakly supervised and zero-shot approaches. We propose a new method to train object detectors using bounding box annotations for a limited set of object categories, as well as image-caption pairs that cover a larger variety of objects at a significantly lower cost. We show that the proposed method can detect and localize objects for which no bounding box annotation is provided during training, at a significantly higher accuracy than zero-shot approaches. Meanwhile, objects with bounding box annotation can be detected almost as accurately as supervised methods, which is significantly better than weakly supervised baselines. Accordingly, we establish a new state of the art for scalable object detection.
Learning Deformable Registration of Medical Images with Anatomical Constraints
Jan 20, 2020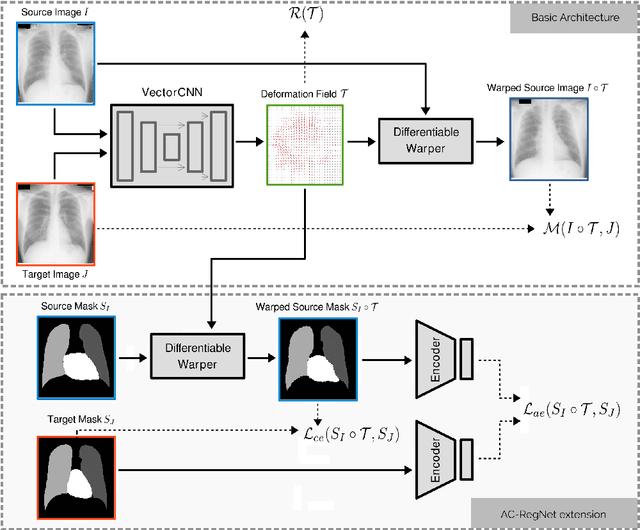
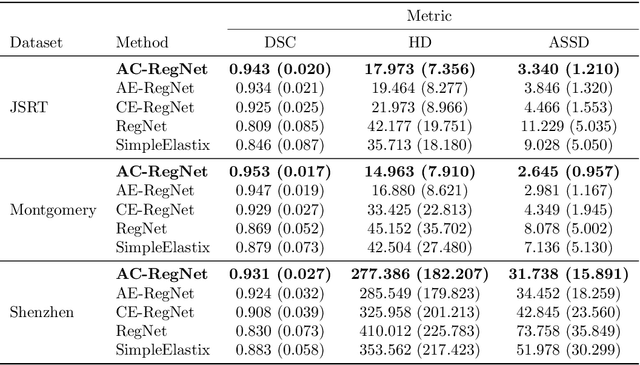
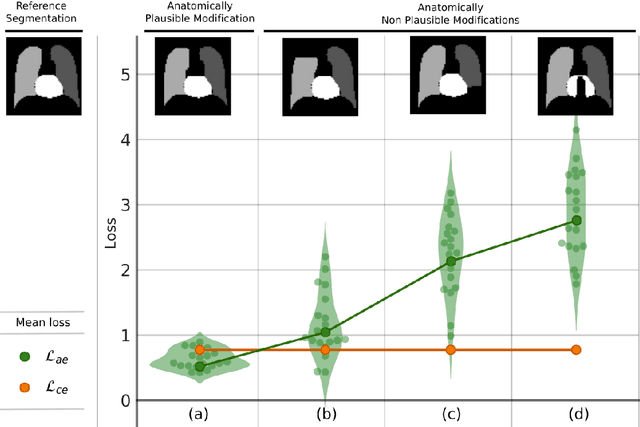
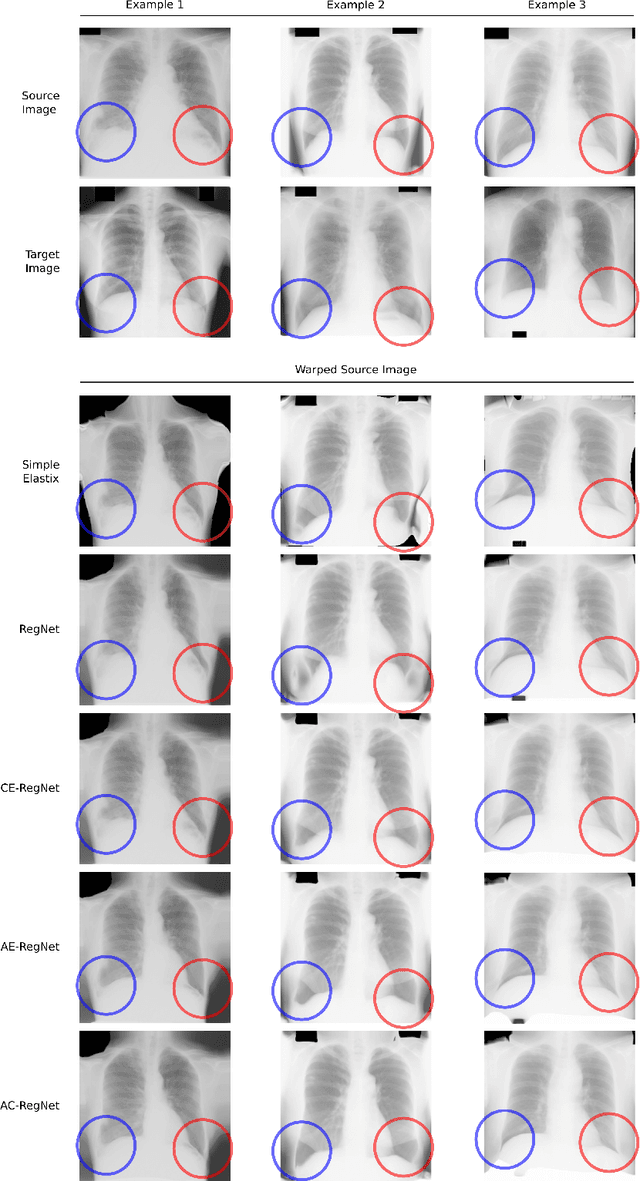
Deformable image registration is a fundamental problem in the field of medical image analysis. During the last years, we have witnessed the advent of deep learning-based image registration methods which achieve state-of-the-art performance, and drastically reduce the required computational time. However, little work has been done regarding how can we encourage our models to produce not only accurate, but also anatomically plausible results, which is still an open question in the field. In this work, we argue that incorporating anatomical priors in the form of global constraints into the learning process of these models, will further improve their performance and boost the realism of the warped images after registration. We learn global non-linear representations of image anatomy using segmentation masks, and employ them to constraint the registration process. The proposed AC-RegNet architecture is evaluated in the context of chest X-ray image registration using three different datasets, where the high anatomical variability makes the task extremely challenging. Our experiments show that the proposed anatomically constrained registration model produces more realistic and accurate results than state-of-the-art methods, demonstrating the potential of this approach.
CPR-GCN: Conditional Partial-Residual Graph Convolutional Network in Automated Anatomical Labeling of Coronary Arteries
Mar 30, 2020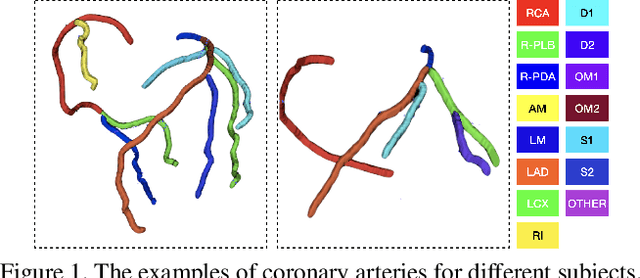
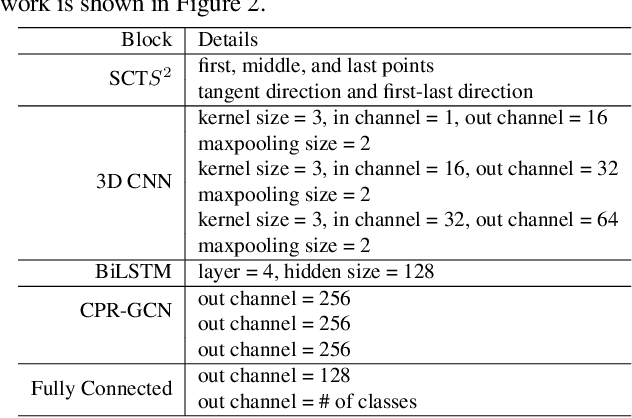
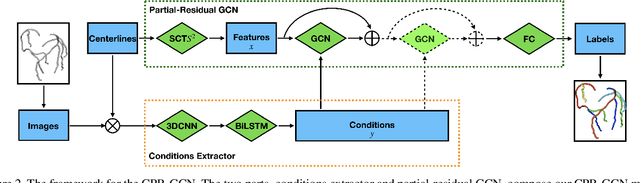
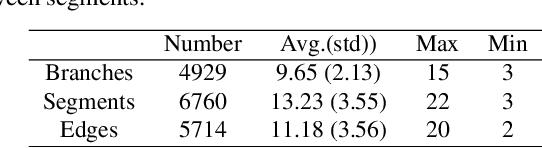
Automated anatomical labeling plays a vital role in coronary artery disease diagnosing procedure. The main challenge in this problem is the large individual variability inherited in human anatomy. Existing methods usually rely on the position information and the prior knowledge of the topology of the coronary artery tree, which may lead to unsatisfactory performance when the main branches are confusing. Motivated by the wide application of the graph neural network in structured data, in this paper, we propose a conditional partial-residual graph convolutional network (CPR-GCN), which takes both position and CT image into consideration, since CT image contains abundant information such as branch size and spanning direction. Two majority parts, a Partial-Residual GCN and a conditions extractor, are included in CPR-GCN. The conditions extractor is a hybrid model containing the 3D CNN and the LSTM, which can extract 3D spatial image features along the branches. On the technical side, the Partial-Residual GCN takes the position features of the branches, with the 3D spatial image features as conditions, to predict the label for each branches. While on the mathematical side, our approach twists the partial differential equation (PDE) into the graph modeling. A dataset with 511 subjects is collected from the clinic and annotated by two experts with a two-phase annotation process. According to the five-fold cross-validation, our CPR-GCN yields 95.8% meanRecall, 95.4% meanPrecision and 0.955 meanF1, which outperforms state-of-the-art approaches.
* This work is done by Xingjian Zhen during internship in Alibaba Damo Academy
MAV Navigation in Unknown Dark Underground Mines Using Deep Learning
Jun 07, 2020

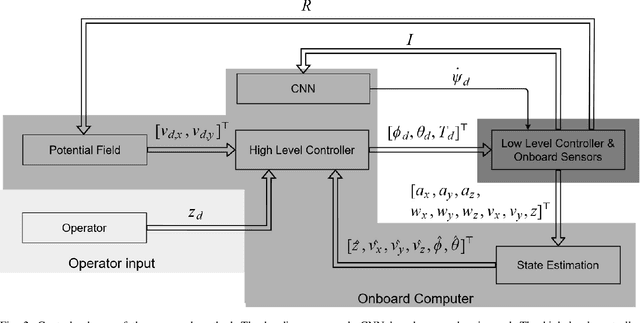
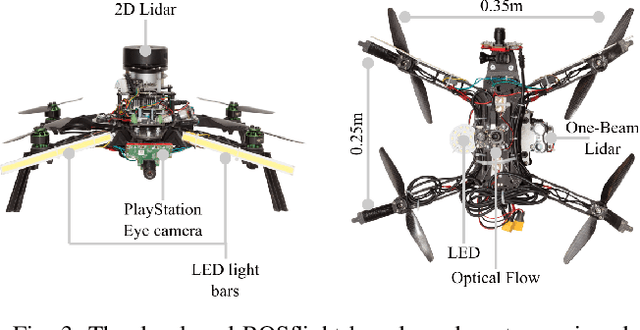
This article proposes a Deep Learning (DL) method to enable fully autonomous flights for low-cost Micro Aerial Vehicles (MAVs) in unknown dark underground mine tunnels. This kind of environments pose multiple challenges including lack of illumination, narrow passages, wind gusts and dust. The proposed method does not require accurate pose estimation and considers the flying platform as a floating object. The Convolutional Neural Network (CNN) supervised image classifier method corrects the heading of the MAV towards the center of the mine tunnel by processing the image frames from a single on-board camera, while the platform navigates at constant altitude and desired velocity references. Moreover, the output of the CNN module can be used from the operator as means of collision prediction information. The efficiency of the proposed method has been successfully experimentally evaluated in multiple field trials in an underground mine in Sweden, demonstrating the capability of the proposed method in different areas and illumination levels.
GAN Compression: Efficient Architectures for Interactive Conditional GANs
Mar 19, 2020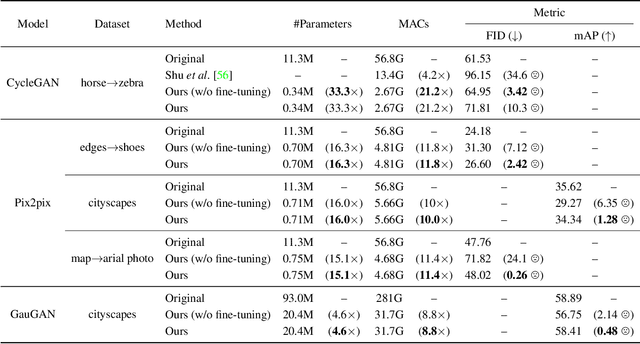
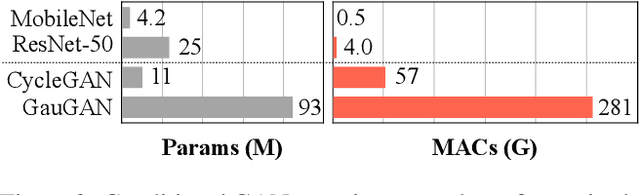
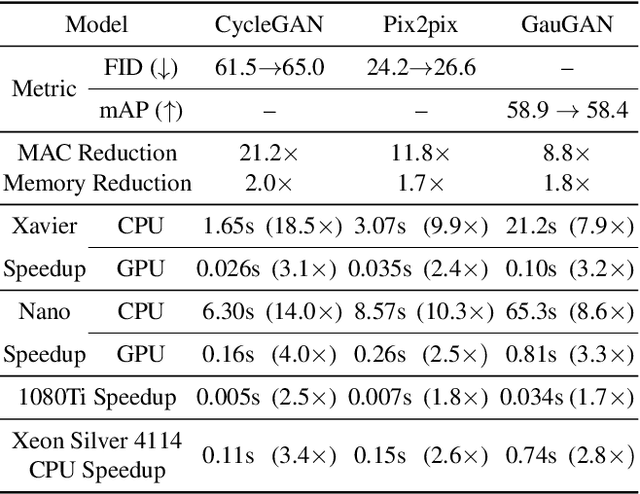
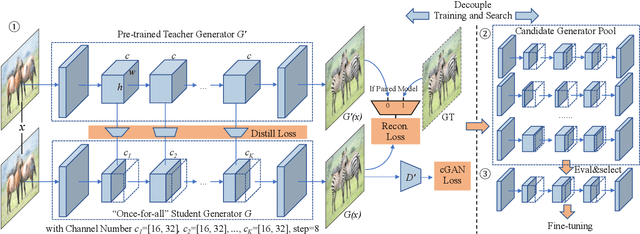
Conditional Generative Adversarial Networks (cGANs) have enabled controllable image synthesis for many computer vision and graphics applications. However, recent cGANs are 1-2 orders of magnitude more computationally-intensive than modern recognition CNNs. For example, GauGAN consumes 281G MACs per image, compared to 0.44G MACs for MobileNet-v3, making it difficult for interactive deployment. In this work, we propose a general-purpose compression framework for reducing the inference time and model size of the generator in cGANs. Directly applying existing CNNs compression methods yields poor performance due to the difficulty of GAN training and the differences in generator architectures. We address these challenges in two ways. First, to stabilize the GAN training, we transfer knowledge of multiple intermediate representations of the original model to its compressed model, and unify unpaired and paired learning. Second, instead of reusing existing CNN designs, our method automatically finds efficient architectures via neural architecture search (NAS). To accelerate the search process, we decouple the model training and architecture search via weight sharing. Experiments demonstrate the effectiveness of our method across different supervision settings (paired and unpaired), model architectures, and learning methods (e.g., pix2pix, GauGAN, CycleGAN). Without losing image quality, we reduce the computation of CycleGAN by more than 20X and GauGAN by 9X, paving the way for interactive image synthesis. The code and demo are publicly available.
Effective deep learning training for single-image super-resolution in endomicroscopy exploiting video-registration-based reconstruction
Mar 23, 2018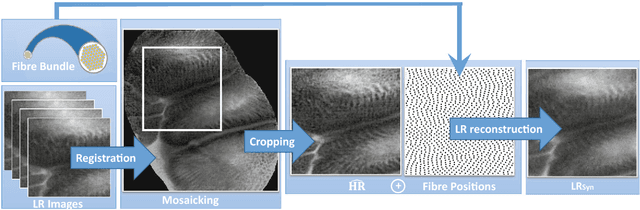
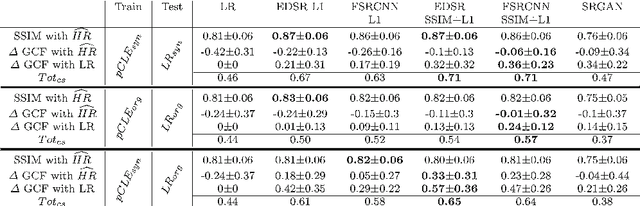
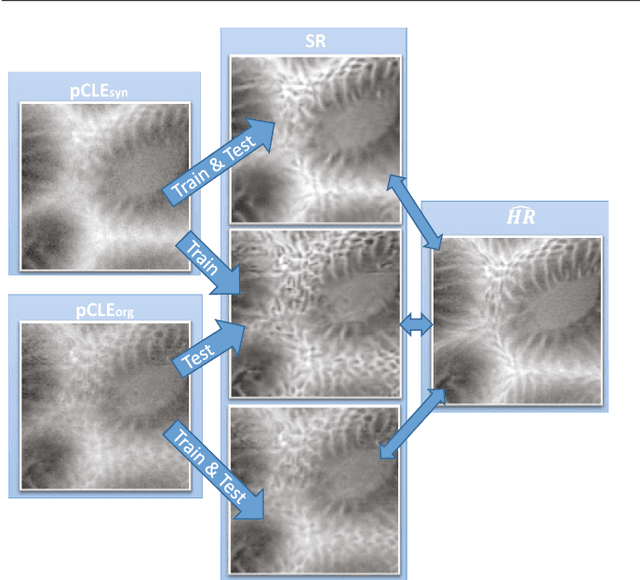

Purpose: Probe-based Confocal Laser Endomicroscopy (pCLE) is a recent imaging modality that allows performing in vivo optical biopsies. The design of pCLE hardware, and its reliance on an optical fibre bundle, fundamentally limits the image quality with a few tens of thousands fibres, each acting as the equivalent of a single-pixel detector, assembled into a single fibre bundle. Video-registration techniques can be used to estimate high-resolution (HR) images by exploiting the temporal information contained in a sequence of low-resolution (LR) images. However, the alignment of LR frames, required for the fusion, is computationally demanding and prone to artefacts. Methods: In this work, we propose a novel synthetic data generation approach to train exemplar-based Deep Neural Networks (DNNs). HR pCLE images with enhanced quality are recovered by the models trained on pairs of estimated HR images (generated by the video-registration algorithm) and realistic synthetic LR images. Performance of three different state-of-the-art DNNs techniques were analysed on a Smart Atlas database of 8806 images from 238 pCLE video sequences. The results were validated through an extensive Image Quality Assessment (IQA) that takes into account different quality scores, including a Mean Opinion Score (MOS). Results: Results indicate that the proposed solution produces an effective improvement in the quality of the obtained reconstructed image. Conclusion: The proposed training strategy and associated DNNs allows us to perform convincing super-resolution of pCLE images.