 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Face Hallucination Using Split-Attention in Split-Attention Network
Oct 22, 2020
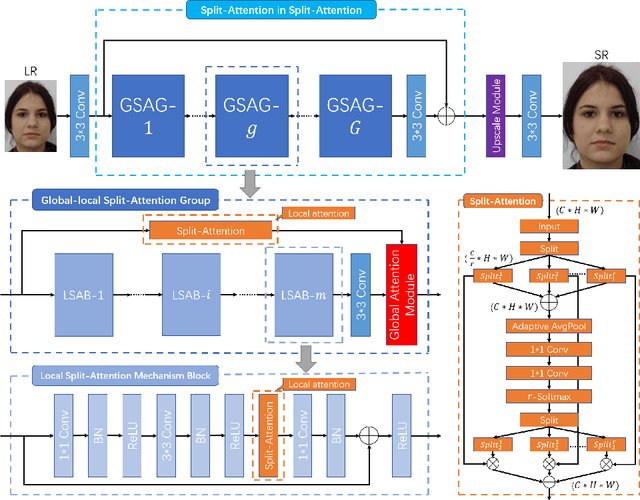

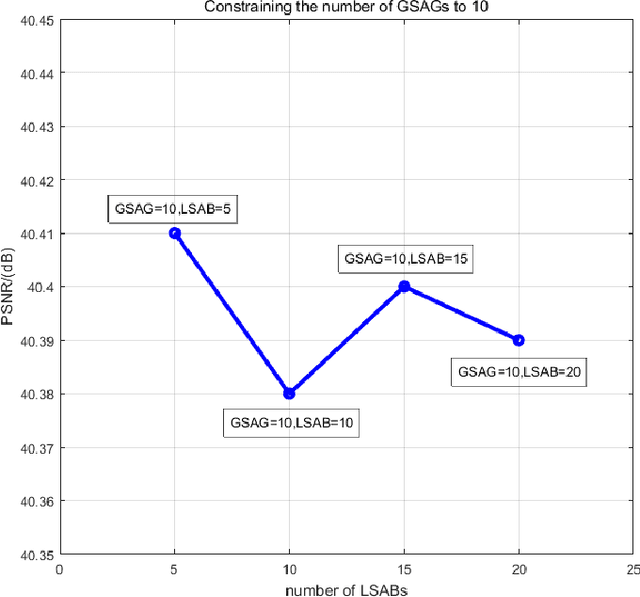
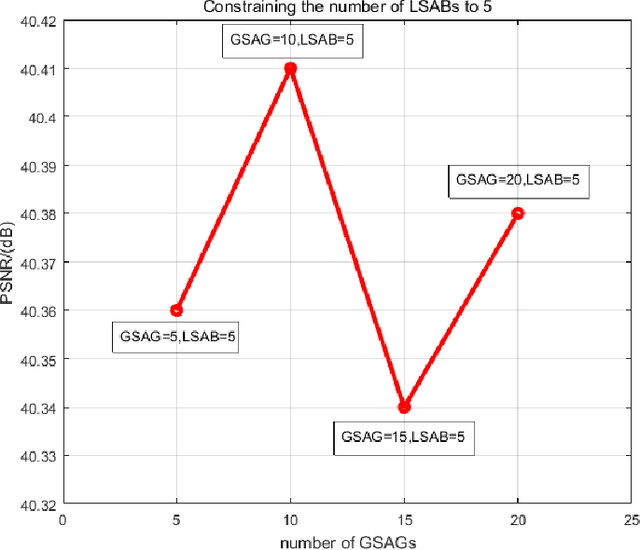
Face hallucination is a domain-specific super-resolution (SR), that generates high-resolution (HR) facial images from the observed one/multiple low-resolution (LR) input/s. Recently, convolutional neural networks(CNNs) are successfully applied into face hallucination to model the complex nonlinear mapping between HR and LR images. Although global attention mechanism equipped into CNNs naturally focus on the facial structure information, it always ignore the local and cross feature structure information, resulting in limited reconstruction performance. In order to solve this problem, we propose global-local split-attention mechanism and design a Split-Attention in Split-Attention (SIS) network to enable local attention across feature-map groups attaining global attention and to improve the ability of feature representations. SIS can generate and focus the local attention of neural network on the interaction of face key structure information in channel-level, thereby improve the performance of face image reconstruction. Experimental results show that the proposed approach consistently and significantly improves the reconstruction performances for face hallucination.
High resolution weakly supervised localization architectures for medical images
Oct 22, 2020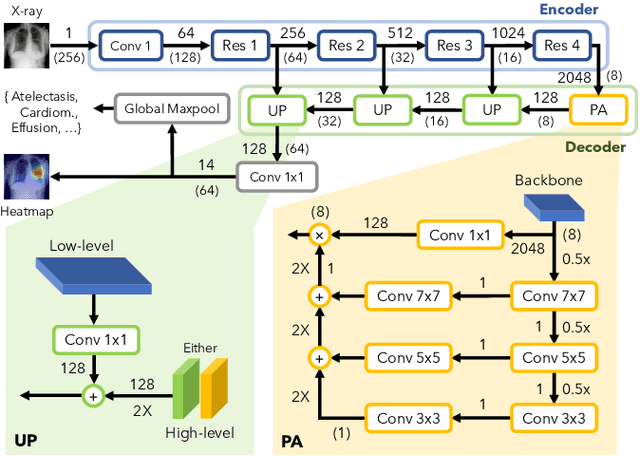

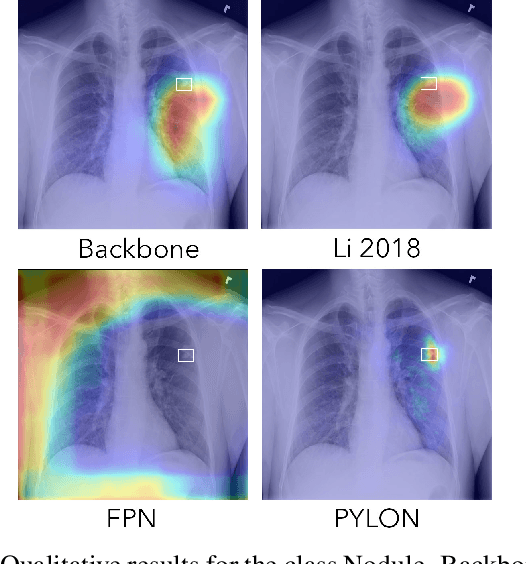
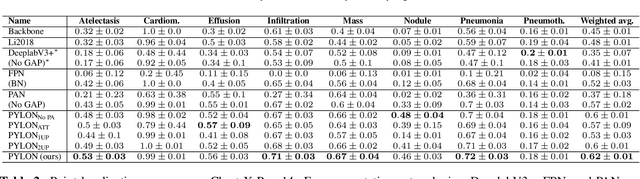
In medical imaging, Class-Activation Map (CAM) serves as the main explainability tool by pointing to the region of interest. Since the localization accuracy from CAM is constrained by the resolution of the model's feature map, one may expect that segmentation models, which generally have large feature maps, would produce more accurate CAMs. However, we have found that this is not the case due to task mismatch. While segmentation models are developed for datasets with pixel-level annotation, only image-level annotation is available in most medical imaging datasets. Our experiments suggest that Global Average Pooling (GAP) and Group Normalization are the main culprits that worsen the localization accuracy of CAM. To address this issue, we propose Pyramid Localization Network (PYLON), a model for high-accuracy weakly-supervised localization that achieved 0.62 average point localization accuracy on NIH's Chest X-Ray 14 dataset, compared to 0.45 for a traditional CAM model. Source code and extended results are available at https://github.com/cmb-chula/pylon.
VisionGuard: Runtime Detection of Adversarial Inputs to Perception Systems
Feb 23, 2020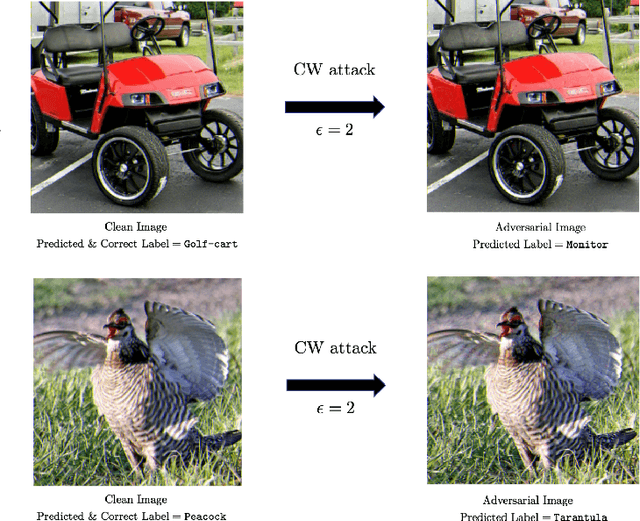
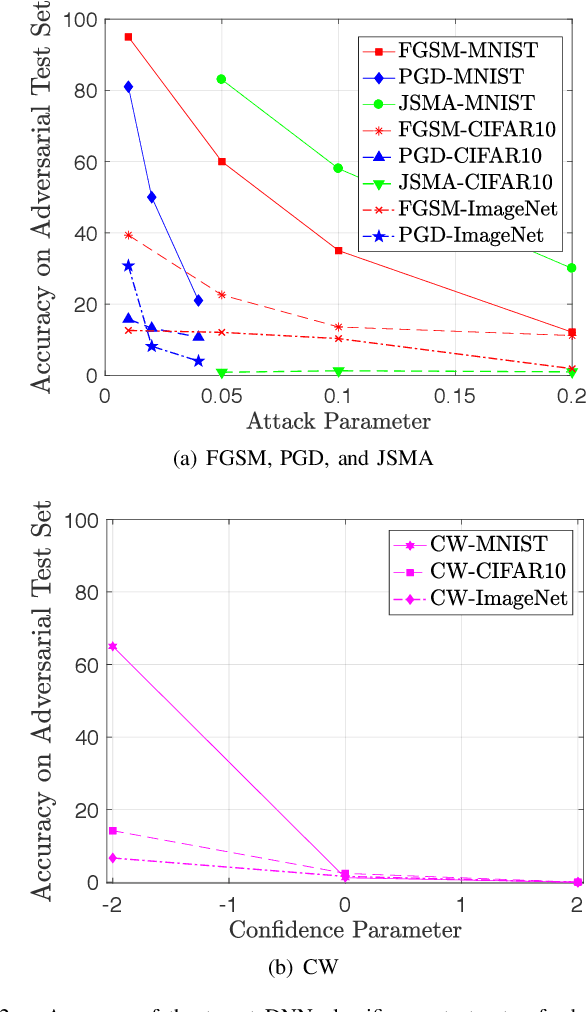
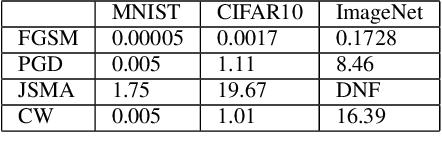
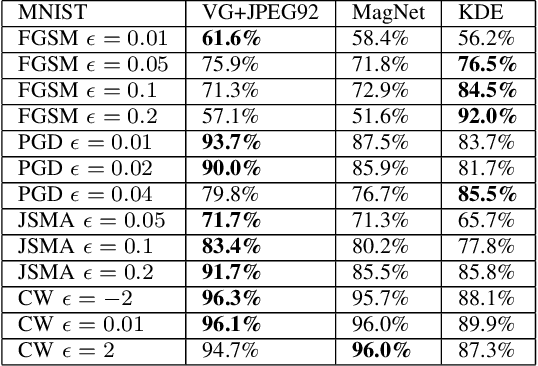
Deep neural network (DNN) models have proven to be vulnerable to adversarial attacks. In this paper, we propose VisionGuard, a novel attack- and dataset-agnostic and computationally-light defense mechanism for adversarial inputs to DNN-based perception systems. In particular, VisionGuard relies on the observation that adversarial images are sensitive to lossy compression transformations. Specifically, to determine if an image is adversarial, VisionGuard checks if the output of the target classifier on a given input image changes significantly after feeding it a transformed version of the image under investigation. Moreover, we show that VisionGuard is computationally-light both at runtime and design-time which makes it suitable for real-time applications that may also involve large-scale image domains. To highlight this, we demonstrate the efficiency of VisionGuard on ImageNet, a task that is computationally challenging for the majority of relevant defenses. Finally, we include extensive comparative experiments on the MNIST, CIFAR10, and ImageNet datasets that show that VisionGuard outperforms existing defenses in terms of scalability and detection performance.
Weakly Supervised Few-shot Object Segmentation using Co-Attention with Visual and Semantic Inputs
Feb 07, 2020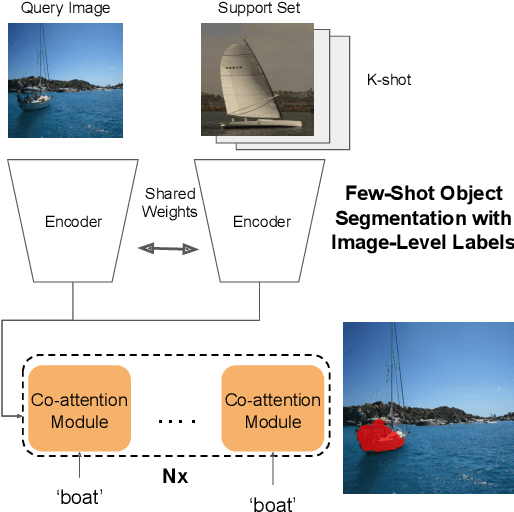
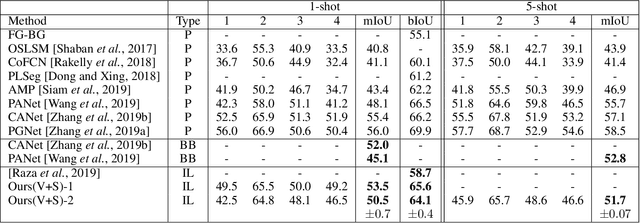
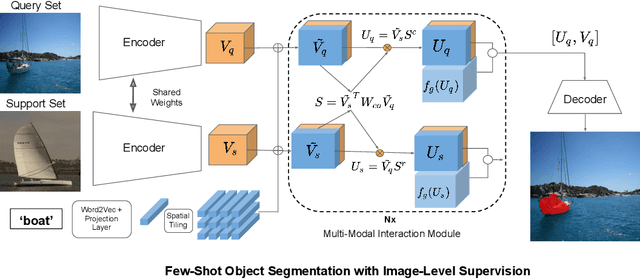
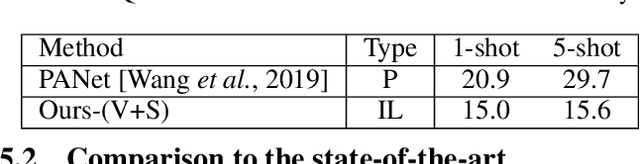
Significant progress has been made recently in developing few-shot object segmentation methods. Learning is shown to be successful in few segmentation settings, including pixel-level, scribbles and bounding boxes. This paper takes another approach, i.e., only requiring image-level classification data for few-shot object segmentation. We propose a novel multi-modal interaction module for few-shot object segmentation that utilizes a co-attention mechanism using both visual and word embedding. Our model using image-level labels achieves 4.8% improvement over previously proposed image-level few-shot object segmentation. It also outperforms state-of-the-art methods that use weak bounding box supervision on PASCAL-$5^i$. Our results show that few-shot segmentation benefits from utilizing word embeddings, and that we are able to perform few-shot segmentation using stacked joint visual semantic processing with weak image-level labels. We further propose a novel setup, Temporal Object Segmentation for Few-shot Learning (TOSFL) for videos. TOSFL requires only image-level labels for the first frame in order to segment objects in the following frames. TOSFL provides a novel benchmark for video segmentation, which can be used on a variety of public video data such as Youtube-VOS, as demonstrated in our experiment.
Self-Supervised Goal-Conditioned Pick and Place
Aug 26, 2020
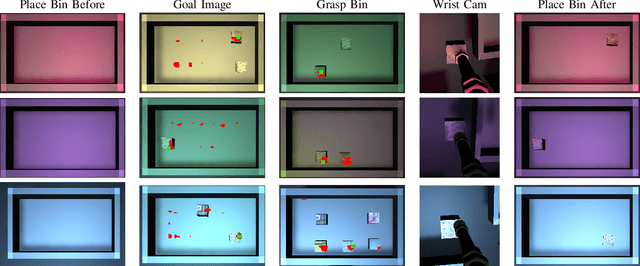
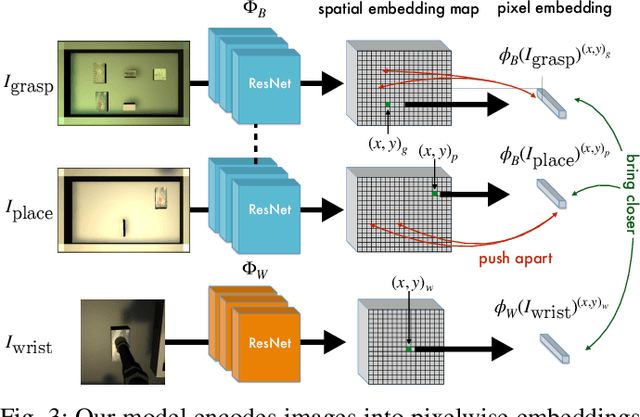

Robots have the capability to collect large amounts of data autonomously by interacting with objects in the world. However, it is often not obvious \emph{how} to learning from autonomously collected data without human-labeled supervision. In this work we learn pixel-wise object representations from unsupervised pick and place data that generalize to new objects. We introduce a novel framework for using these representations in order to predict where to pick and where to place in order to match a goal image. Finally, we demonstrate the utility of our approach in a simulated grasping environment.
IIRC: Incremental Implicitly-Refined Classification
Dec 23, 2020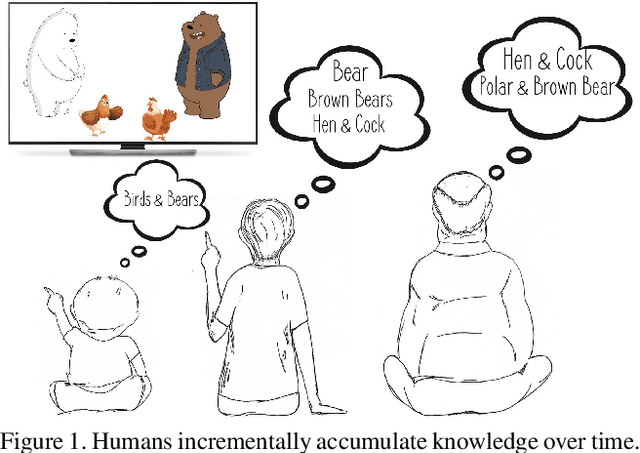

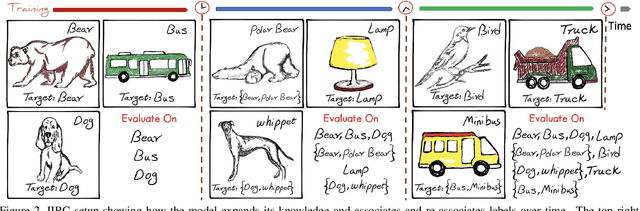

We introduce the "Incremental Implicitly-Refined Classi-fication (IIRC)" setup, an extension to the class incremental learning setup where the incoming batches of classes have two granularity levels. i.e., each sample could have a high-level (coarse) label like "bear" and a low-level (fine) label like "polar bear". Only one label is provided at a time, and the model has to figure out the other label if it has already learnfed it. This setup is more aligned with real-life scenarios, where a learner usually interacts with the same family of entities multiple times, discovers more granularity about them, while still trying not to forget previous knowledge. Moreover, this setup enables evaluating models for some important lifelong learning challenges that cannot be easily addressed under the existing setups. These challenges can be motivated by the example "if a model was trained on the class bear in one task and on polar bear in another task, will it forget the concept of bear, will it rightfully infer that a polar bear is still a bear? and will it wrongfully associate the label of polar bear to other breeds of bear?". We develop a standardized benchmark that enables evaluating models on the IIRC setup. We evaluate several state-of-the-art lifelong learning algorithms and highlight their strengths and limitations. For example, distillation-based methods perform relatively well but are prone to incorrectly predicting too many labels per image. We hope that the proposed setup, along with the benchmark, would provide a meaningful problem setting to the practitioners
AVR: Attention based Salient Visual Relationship Detection
Mar 16, 2020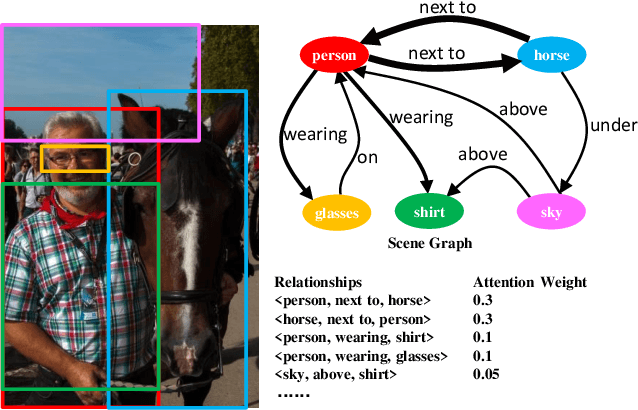
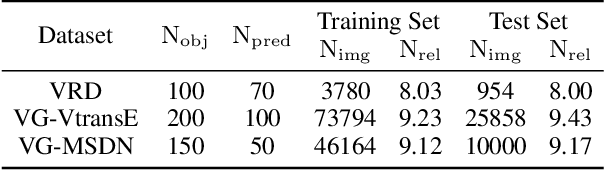
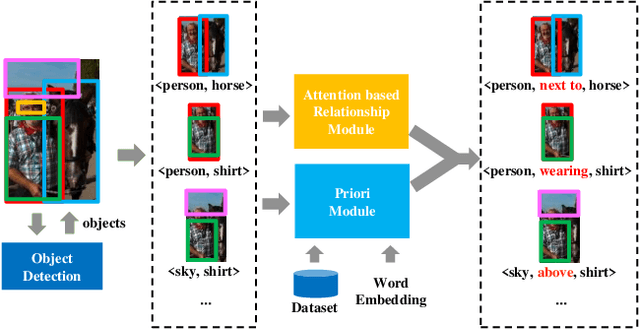
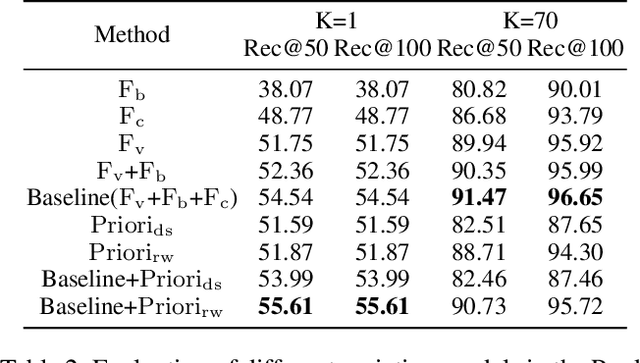
Visual relationship detection aims to locate objects in images and recognize the relationships between objects. Traditional methods treat all observed relationships in an image equally, which causes a relatively poor performance in the detection tasks on complex images with abundant visual objects and various relationships. To address this problem, we propose an attention based model, namely AVR, to achieve salient visual relationships based on both local and global context of the relationships. Specifically, AVR recognizes relationships and measures the attention on the relationships in the local context of an input image by fusing the visual features, semantic and spatial information of the relationships. AVR then applies the attention to assign important relationships with larger salient weights for effective information filtering. Furthermore, AVR is integrated with the priori knowledge in the global context of image datasets to improve the precision of relationship prediction, where the context is modeled as a heterogeneous graph to measure the priori probability of relationships based on the random walk algorithm. Comprehensive experiments are conducted to demonstrate the effectiveness of AVR in several real-world image datasets, and the results show that AVR outperforms state-of-the-art visual relationship detection methods significantly by up to $87.5\%$ in terms of recall.
Oral-3D: Reconstructing the 3D Bone Structure of Oral Cavity from 2D Panoramic X-ray
Mar 26, 2020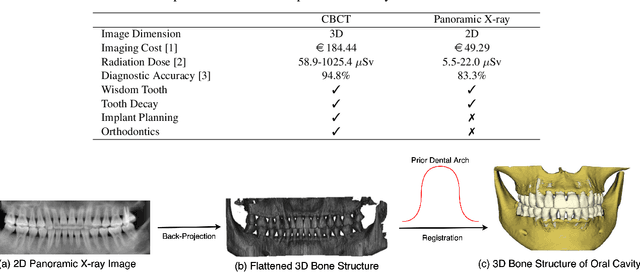

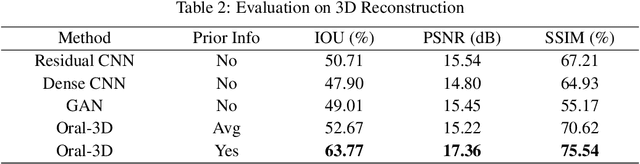
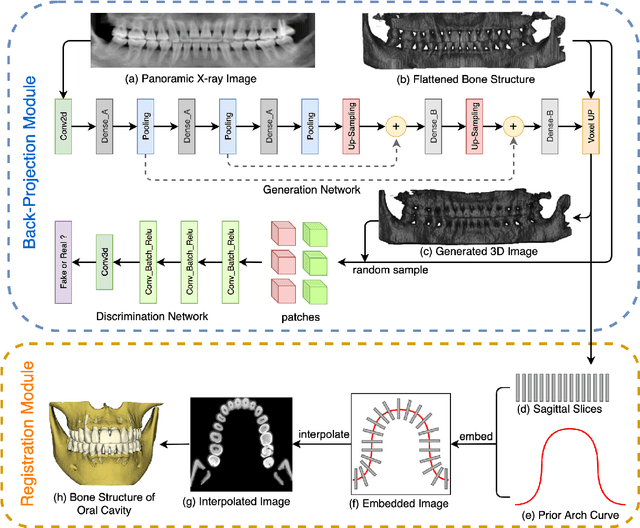
Panoramic X-ray and Cone Beam Computed Tomography (CBCT) are two of the most general imaging methods in digital dentistry. While CBCT can provide higher-dimension information, the panoramic X-ray has the advantages of lower radiation dose and cost. Consequently, generating 3D information of bony tissues from the X-ray that can reflect dental diseases is of great interest. This technique can be even more helpful for developing areas where the CBCT is not always available due to the lack of screening machines or high screening cost. In this paper, we present \textit{Oral-3D} to reconstruct the bone structure of oral cavity from a single panoramic X-ray image by taking advantage of some prior knowledge in oral structure, which conventionally can only be obtained by a 3D imaging method like CBCT. Specifically, we first train a generative network to back project the 2D X-ray image into 3D space, then restore the bone structure by registering the generated 3D image with the prior shape of the dental arch. To be noted, \textit{Oral-3D} can restore both the density of bony tissues and the curved mandible surface. Experimental results show that our framework can reconstruct the 3D structure with significantly high quality. To the best of our knowledge, this is the first work that explores 3D reconstruction from a 2D image in dental health.
Deep Line Art Video Colorization with a Few References
Mar 24, 2020

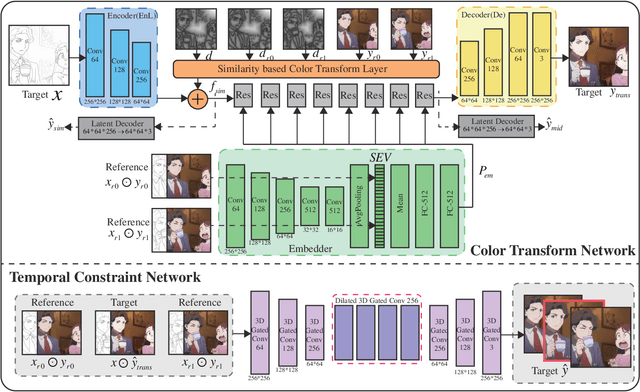

Coloring line art images based on the colors of reference images is an important stage in animation production, which is time-consuming and tedious. In this paper, we propose a deep architecture to automatically color line art videos with the same color style as the given reference images. Our framework consists of a color transform network and a temporal constraint network. The color transform network takes the target line art images as well as the line art and color images of one or more reference images as input, and generates corresponding target color images. To cope with larger differences between the target line art image and reference color images, our architecture utilizes non-local similarity matching to determine the region correspondences between the target image and the reference images, which are used to transform the local color information from the references to the target. To ensure global color style consistency, we further incorporate Adaptive Instance Normalization (AdaIN) with the transformation parameters obtained from a style embedding vector that describes the global color style of the references, extracted by an embedder. The temporal constraint network takes the reference images and the target image together in chronological order, and learns the spatiotemporal features through 3D convolution to ensure the temporal consistency of the target image and the reference image. Our model can achieve even better coloring results by fine-tuning the parameters with only a small amount of samples when dealing with an animation of a new style. To evaluate our method, we build a line art coloring dataset. Experiments show that our method achieves the best performance on line art video coloring compared to the state-of-the-art methods and other baselines.
Image Restoration with Locally Selected Class-Adapted Models
Aug 02, 2016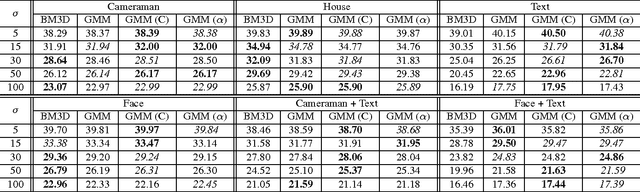

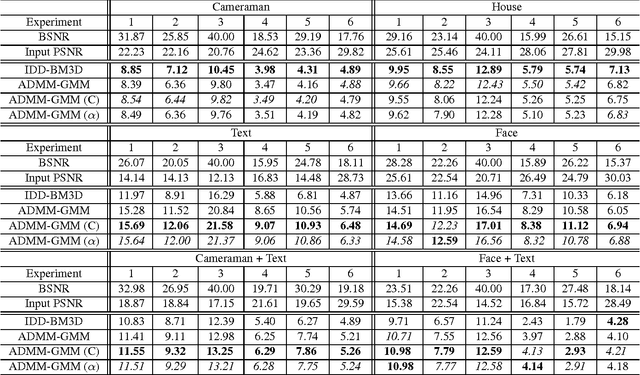

State-of-the-art algorithms for imaging inverse problems (namely deblurring and reconstruction) are typically iterative, involving a denoising operation as one of its steps. Using a state-of-the-art denoising method in this context is not trivial, and is the focus of current work. Recently, we have proposed to use a class-adapted denoiser (patch-based using Gaussian mixture models) in a so-called plug-and-play scheme, wherein a state-of-the-art denoiser is plugged into an iterative algorithm, leading to results that outperform the best general-purpose algorithms, when applied to an image of a known class (e.g. faces, text, brain MRI). In this paper, we extend that approach to handle situations where the image being processed is from one of a collection of possible classes or, more importantly, contains regions of different classes. More specifically, we propose a method to locally select one of a set of class-adapted Gaussian mixture patch priors, previously estimated from clean images of those classes. Our approach may be seen as simultaneously performing segmentation and restoration, thus contributing to bridging the gap between image restoration/reconstruction and analysis.