 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Neural Collapse in Meta Learning Models for Few-shot Learning
Oct 08, 2023Meta-learning frameworks for few-shot learning aims to learn models that can learn new skills or adapt to new environments rapidly with a few training examples. This has led to the generalizability of the developed model towards new classes with just a few labelled samples. However these networks are seen as black-box models and understanding the representations learnt under different learning scenarios is crucial. Neural collapse ($\mathcal{NC}$) is a recently discovered phenomenon which showcases unique properties at the network proceeds towards zero loss. The input features collapse to their respective class means, the class means form a Simplex equiangular tight frame (ETF) where the class means are maximally distant and linearly separable, and the classifier acts as a simple nearest neighbor classifier. While these phenomena have been observed in simple classification networks, this study is the first to explore and understand the properties of neural collapse in meta learning frameworks for few-shot learning. We perform studies on the Omniglot dataset in the few-shot setting and study the neural collapse phenomenon. We observe that the learnt features indeed have the trend of neural collapse, especially as model size grows, but to do not necessarily showcase the complete collapse as measured by the $\mathcal{NC}$ properties.
Weakly Supervised Few-shot Object Segmentation using Co-Attention with Visual and Semantic Inputs
Feb 07, 2020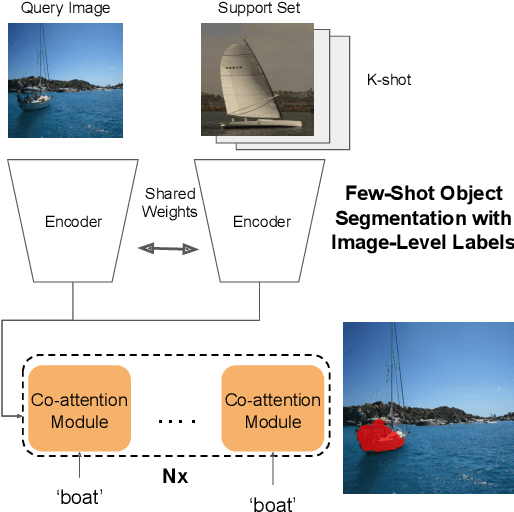
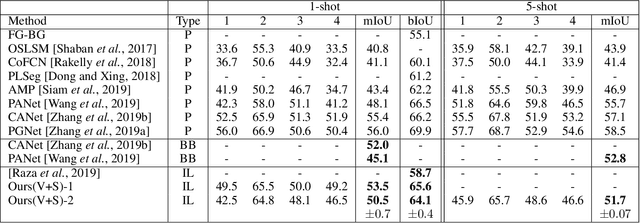
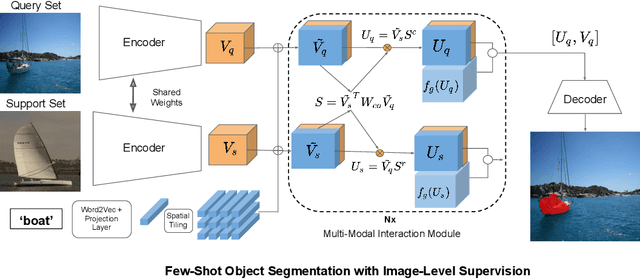
Significant progress has been made recently in developing few-shot object segmentation methods. Learning is shown to be successful in few segmentation settings, including pixel-level, scribbles and bounding boxes. This paper takes another approach, i.e., only requiring image-level classification data for few-shot object segmentation. We propose a novel multi-modal interaction module for few-shot object segmentation that utilizes a co-attention mechanism using both visual and word embedding. Our model using image-level labels achieves 4.8% improvement over previously proposed image-level few-shot object segmentation. It also outperforms state-of-the-art methods that use weak bounding box supervision on PASCAL-$5^i$. Our results show that few-shot segmentation benefits from utilizing word embeddings, and that we are able to perform few-shot segmentation using stacked joint visual semantic processing with weak image-level labels. We further propose a novel setup, Temporal Object Segmentation for Few-shot Learning (TOSFL) for videos. TOSFL requires only image-level labels for the first frame in order to segment objects in the following frames. TOSFL provides a novel benchmark for video segmentation, which can be used on a variety of public video data such as Youtube-VOS, as demonstrated in our experiment.
One-Shot Weakly Supervised Video Object Segmentation
Dec 18, 2019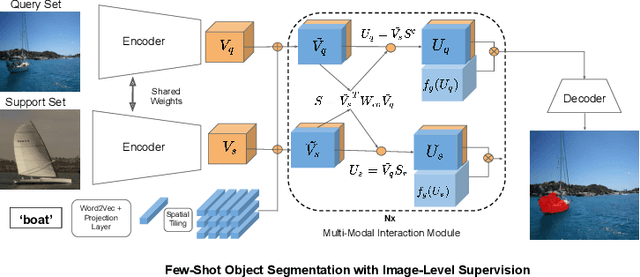
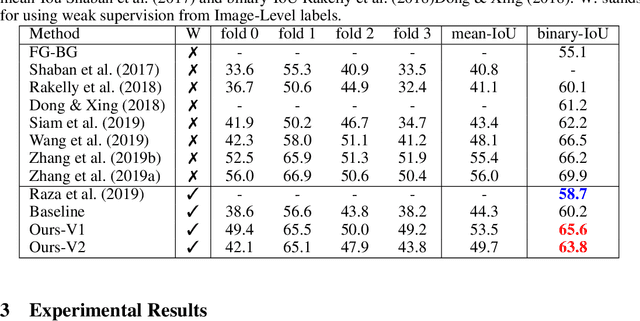


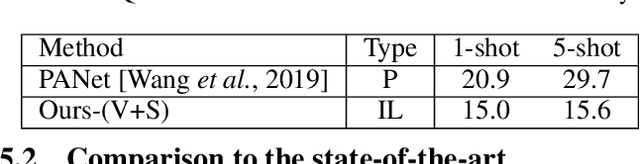
Conventional few-shot object segmentation methods learn object segmentation from a few labelled support images with strongly labelled segmentation masks. Recent work has shown to perform on par with weaker levels of supervision in terms of scribbles and bounding boxes. However, there has been limited attention given to the problem of few-shot object segmentation with image-level supervision. We propose a novel multi-modal interaction module for few-shot object segmentation that utilizes a co-attention mechanism using both visual and word embeddings. It enables our model to achieve 5.1% improvement over previously proposed image-level few-shot object segmentation. Our method compares relatively close to the state of the art methods that use strong supervision, while ours use the least possible supervision. We further propose a novel setup for few-shot weakly supervised video object segmentation(VOS) that relies on image-level labels for the first frame. The proposed setup uses weak annotation unlike semi-supervised VOS setting that utilizes strongly labelled segmentation masks. The setup evaluates the effectiveness of generalizing to novel classes in the VOS setting. The setup splits the VOS data into multiple folds with different categories per fold. It provides a potential setup to evaluate how few-shot object segmentation methods can benefit from additional object poses, or object interactions that is not available in static frames as in PASCAL-5i benchmark.