 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Abnormality Detection Using Heterogeneous Autonomous Systems
Jun 05, 2020
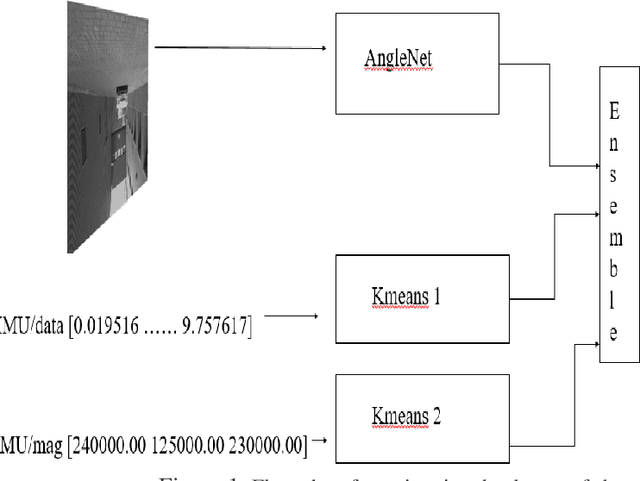


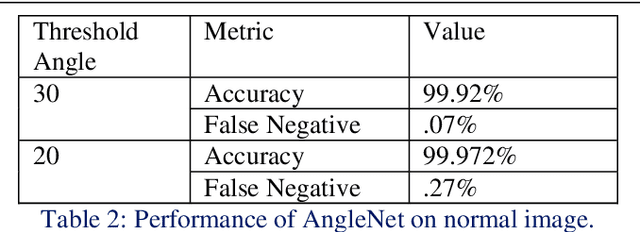
Anomaly detection in a surveillance scenario is an emerging and challenging field of research. For autonomous vehicles like drones or cars, it is immensely important to distinguish between normal and abnormal states in real-time to avoid/detect potential threats. But the nature and degree of abnormality may vary depending upon the actual environment and adversary. As a result, it is impractical to model all cases a priori and use supervised methods to classify. Also, an autonomous vehicle provides various data types like images and other analog or digital sensor data. In this paper, a heterogeneous system is proposed which estimates the degree of abnormality of an environment using drone-feed, analyzing real-time image and IMU sensor data in an unsupervised manner. Here, we have demonstrated AngleNet (a novel CNN architecture) to estimate the angle between a normal image and another image under consideration, which provides us with a measure of anomaly. Moreover, the IMU data are used in clustering models to predict abnormality. Finally, the results from these two algorithms are ensembled to estimate the final abnormality. The proposed method performs satisfactorily on the IEEE SP Cup-2020 dataset with an accuracy of 99.92%. Additionally, we have also tested this approach on an in-house dataset to validate its robustness.
Mean Oriented Riesz Features for Micro Expression Classification
May 13, 2020
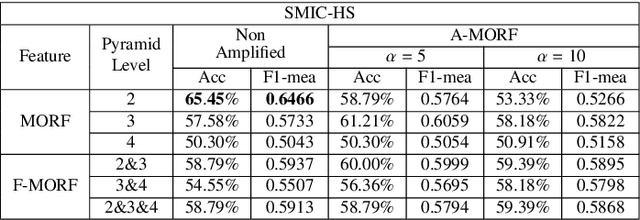
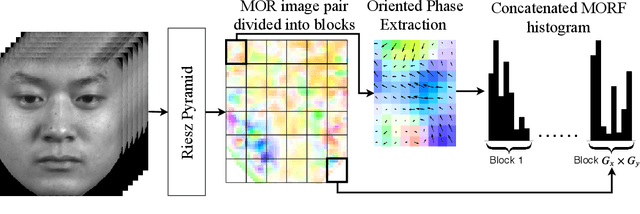
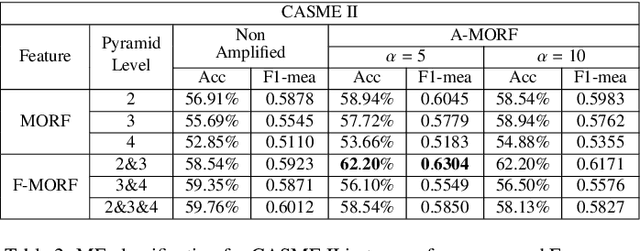
Micro-expressions are brief and subtle facial expressions that go on and off the face in a fraction of a second. This kind of facial expressions usually occurs in high stake situations and is considered to reflect a human's real intent. There has been some interest in micro-expression analysis, however, a great majority of the methods are based on classically established computer vision methods such as local binary patterns, histogram of gradients and optical flow. A novel methodology for micro-expression recognition using the Riesz pyramid, a multi-scale steerable Hilbert transform is presented. In fact, an image sequence is transformed with this tool, then the image phase variations are extracted and filtered as proxies for motion. Furthermore, the dominant orientation constancy from the Riesz transform is exploited to average the micro-expression sequence into an image pair. Based on that, the Mean Oriented Riesz Feature description is introduced. Finally the performance of our methods are tested in two spontaneous micro-expressions databases and compared to state-of-the-art methods.
A Unifying Framework for Formal Theories of Novelty:Framework, Examples and Discussion
Dec 08, 2020
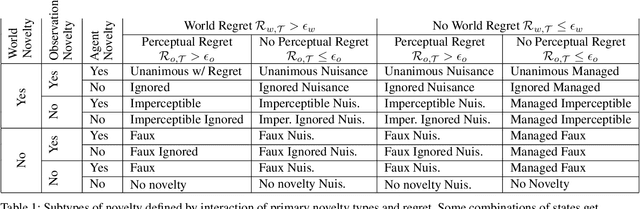
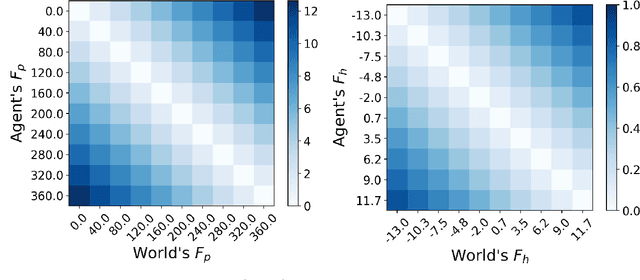
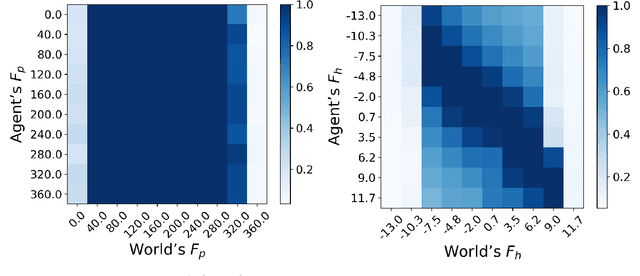
Managing inputs that are novel, unknown, or out-of-distribution is critical as an agent moves from the lab to the open world. Novelty-related problems include being tolerant to novel perturbations of the normal input, detecting when the input includes novel items, and adapting to novel inputs. While significant research has been undertaken in these areas, a noticeable gap exists in the lack of a formalized definition of novelty that transcends problem domains. As a team of researchers spanning multiple research groups and different domains, we have seen, first hand, the difficulties that arise from ill-specified novelty problems, as well as inconsistent definitions and terminology. Therefore, we present the first unified framework for formal theories of novelty and use the framework to formally define a family of novelty types. Our framework can be applied across a wide range of domains, from symbolic AI to reinforcement learning, and beyond to open world image recognition. Thus, it can be used to help kick-start new research efforts and accelerate ongoing work on these important novelty-related problems. This extended version of our AAAI 2021 paper included more details and examples in multiple domains.
Unsupervised Spatial-spectral Network Learning for Hyperspectral Compressive Snapshot Reconstruction
Dec 18, 2020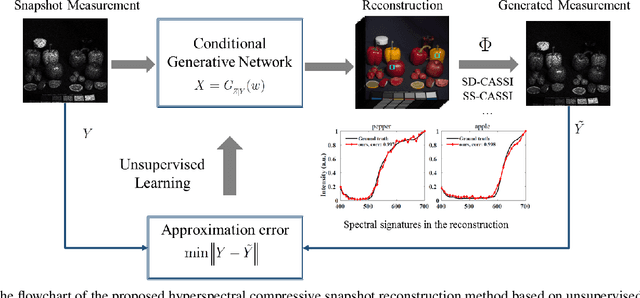


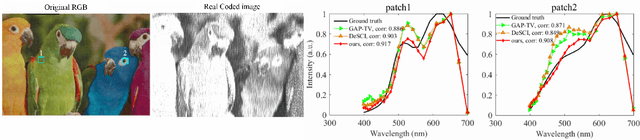
Hyperspectral compressive imaging takes advantage of compressive sensing theory to achieve coded aperture snapshot measurement without temporal scanning, and the entire three-dimensional spatial-spectral data is captured by a two-dimensional projection during a single integration period. Its core issue is how to reconstruct the underlying hyperspectral image using compressive sensing reconstruction algorithms. Due to the diversity in the spectral response characteristics and wavelength range of different spectral imaging devices, previous works are often inadequate to capture complex spectral variations or lack the adaptive capacity to new hyperspectral imagers. In order to address these issues, we propose an unsupervised spatial-spectral network to reconstruct hyperspectral images only from the compressive snapshot measurement. The proposed network acts as a conditional generative model conditioned on the snapshot measurement, and it exploits the spatial-spectral attention module to capture the joint spatial-spectral correlation of hyperspectral images. The network parameters are optimized to make sure that the network output can closely match the given snapshot measurement according to the imaging model, thus the proposed network can adapt to different imaging settings, which can inherently enhance the applicability of the network. Extensive experiments upon multiple datasets demonstrate that our network can achieve better reconstruction results than the state-of-the-art methods.
Synthesising clinically realistic Chest X-rays using Generative Adversarial Networks
Oct 07, 2020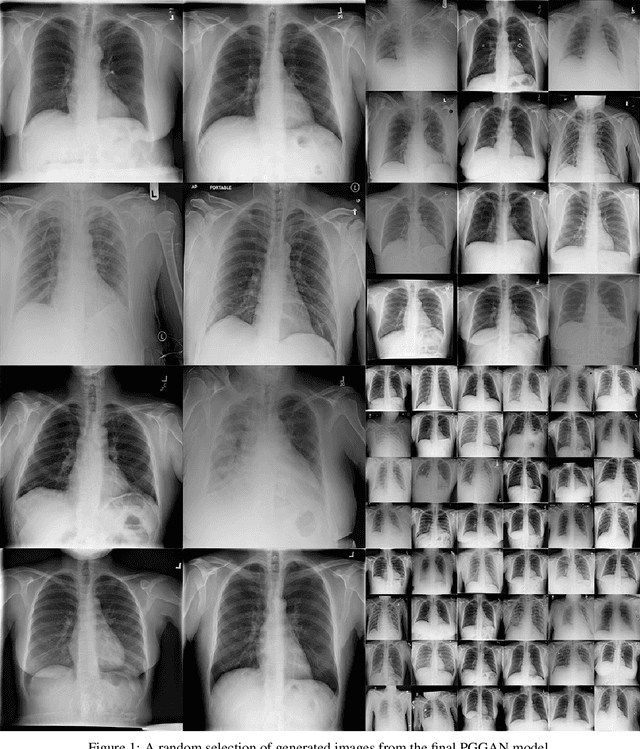
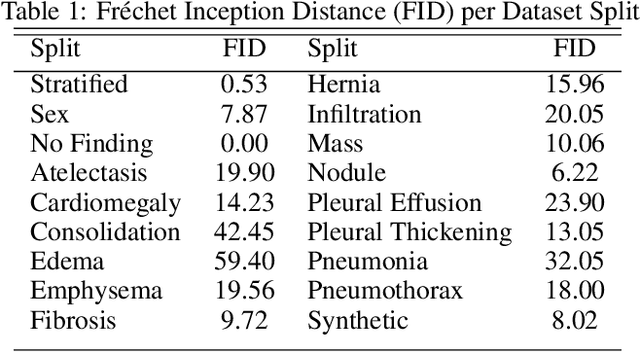
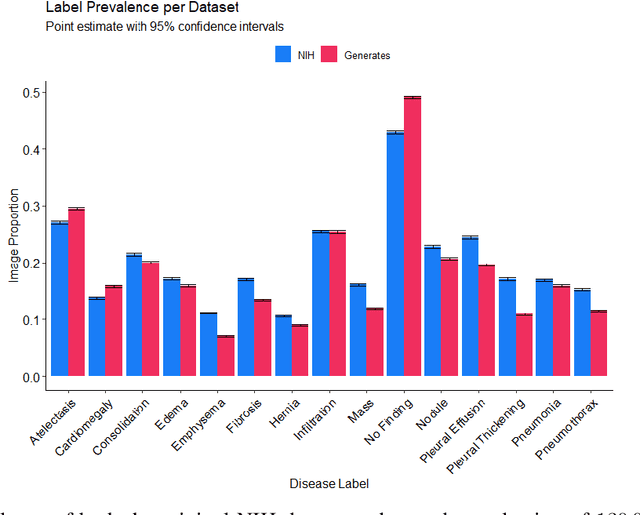
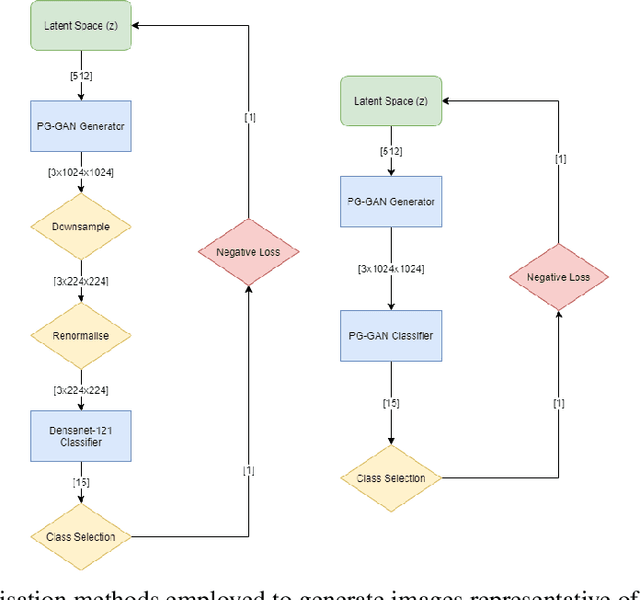
Chest x-rays are one of the most commonly performed medical investigations globally and are vital to identifying a number of conditions. These images are however protected under patient confidentiality and as such require the removal of identifying information as well as ethical clearance to be released. Generative adversarial networks (GANs) are a branch of deep learning which are capable of producing synthetic samples of a desired distribution. Image generation is one such application with recent advances enabling the production of high-resolution images, a feature vital to the utility of x-rays given the scale of various pathologies. We apply the Progressive Growing GAN (PGGAN) to the task of chest x-ray generation with the goal of being able to produce images without any ethical concerns that may be used for medical education or in other machine learning work. We evaluate the properties of the generated x-rays with a practicing radiologist and demonstrate that high-quality, realistic images can be produced with global features consistent with pathologies seen in the NIH dataset. Improvements in the reproduction of small-scale details remains for future work. We train a classification model on the NIH images and evaluate the distribution of disease labels across the generated samples. We find that the model is capable of reproducing all the abnormalities in a similar proportion to the source image distribution as labelled by the classifier. We additionally demonstrate that the latent space can be optimised to produce images of a particular class despite unconditional training, with the model producing related features and complications for the class of interest. We also validate the application of the Fr'echet Inception Distance (FID) to x-ray images and determine that the PGGAN reproduces x-ray images with an FID of 8.02, which is similar to other high resolution tasks.
AutoNLU: An On-demand Cloud-based Natural Language Understanding System for Enterprises
Nov 26, 2020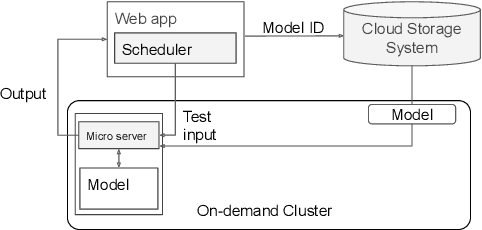
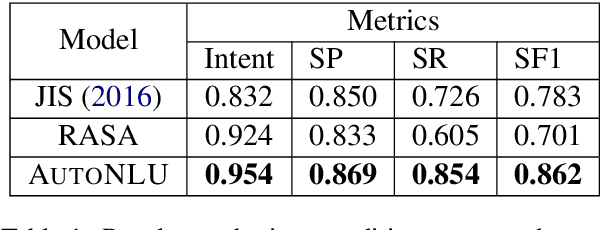
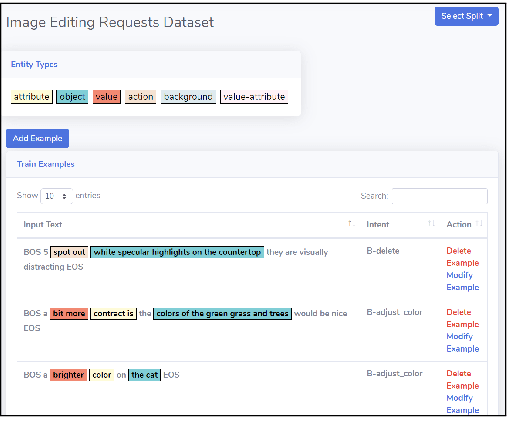
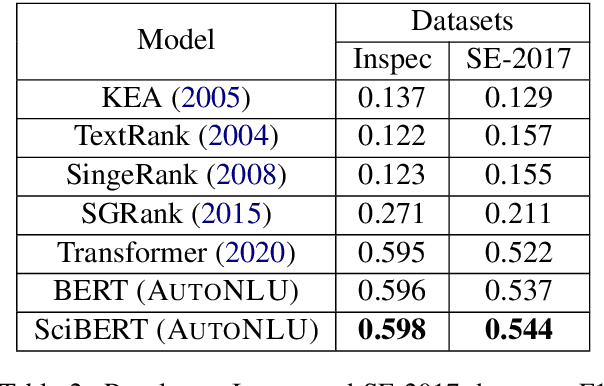
With the renaissance of deep learning, neural networks have achieved promising results on many natural language understanding (NLU) tasks. Even though the source codes of many neural network models are publicly available, there is still a large gap from open-sourced models to solving real-world problems in enterprises. Therefore, to fill this gap, we introduce AutoNLU, an on-demand cloud-based system with an easy-to-use interface that covers all common use-cases and steps in developing an NLU model. AutoNLU has supported many product teams within Adobe with different use-cases and datasets, quickly delivering them working models. To demonstrate the effectiveness of AutoNLU, we present two case studies. i) We build a practical NLU model for handling various image-editing requests in Photoshop. ii) We build powerful keyphrase extraction models that achieve state-of-the-art results on two public benchmarks. In both cases, end users only need to write a small amount of code to convert their datasets into a common format used by AutoNLU.
BézierSketch: A generative model for scalable vector sketches
Jul 04, 2020
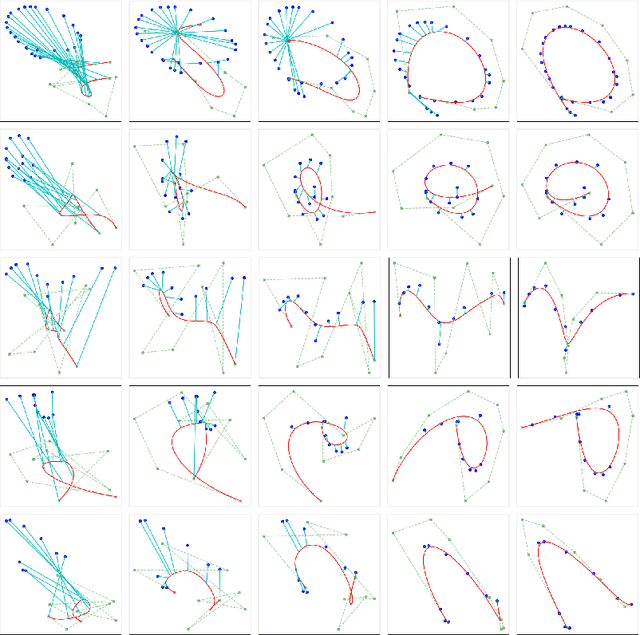
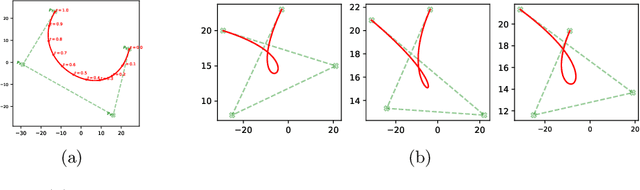
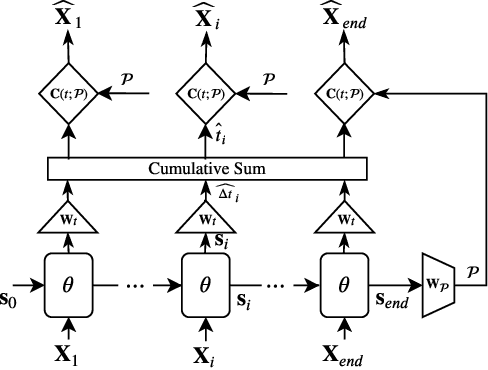
The study of neural generative models of human sketches is a fascinating contemporary modeling problem due to the links between sketch image generation and the human drawing process. The landmark SketchRNN provided breakthrough by sequentially generating sketches as a sequence of waypoints. However this leads to low-resolution image generation, and failure to model long sketches. In this paper we present B\'ezierSketch, a novel generative model for fully vector sketches that are automatically scalable and high-resolution. To this end, we first introduce a novel inverse graphics approach to stroke embedding that trains an encoder to embed each stroke to its best fit B\'ezier curve. This enables us to treat sketches as short sequences of paramaterized strokes and thus train a recurrent sketch generator with greater capacity for longer sketches, while producing scalable high-resolution results. We report qualitative and quantitative results on the Quick, Draw! benchmark.
Weakly Supervised Few-shot Object Segmentation using Co-Attention with Visual and Semantic Inputs
Jan 26, 2020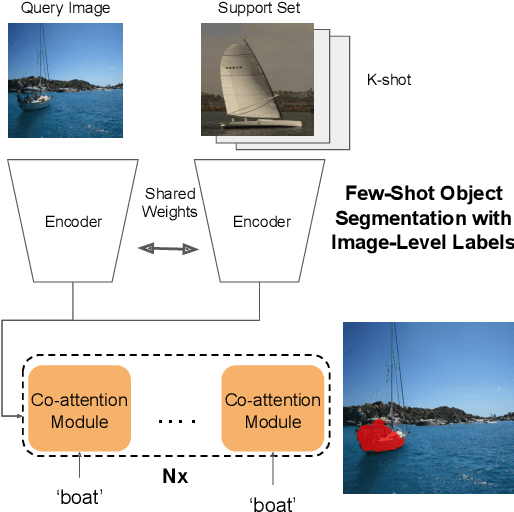
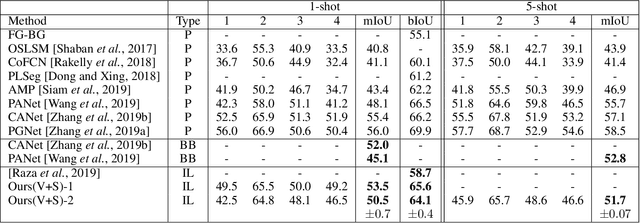
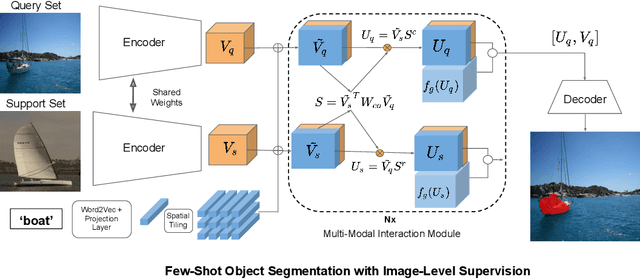
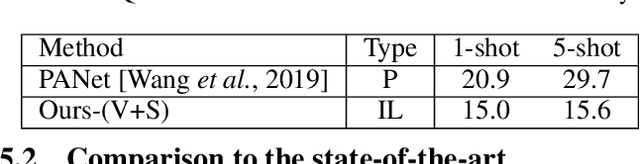
Significant progress has been made recently in developing few-shot object segmentation methods. Learning is shown to be successful in a few segmentation settings, including pixel-level, scribbles and bounding boxes. These methods can be classified as "strongly labelled" support images because significant image editing efforts are required to provide the labeling. This paper takes another approach, i.e., only requiring image-level classification data for few-shot object segmentation. The large amount of image-level labelled data signifies this approach, if successful. The problem is challenging because there is no obvious features that can be used for segmentation in the image-level data. We propose a novel multi-modal interaction module for few-shot object segmentation that utilizes a co-attention mechanism using both visual and word embedding. Our model using image-level labels achieves 4.8% improvement over previously proposed image-level few-shot object segmentation. It also outperforms state-of-the-art methods that use weak bounding box supervision on PASCAL-5i. Our results show that few-shot segmentation benefits from utilizing word embeddings, and that we are able to perform few-shot segmentation using stacked joint visual semantic processing with weak image-level labels. We further propose a novel setup, Temporal Object Segmentation for Few-shot Learning (TOSFL) for videos. TOSFL requires only image-level labels for the first frame in order to segment objects in the following frames. TOSFL provides a novel benchmark for video segmentation, which can be used on a variety of public video data such as Youtube-VOS, as demonstrated in our experiment.
The Elements of End-to-end Deep Face Recognition: A Survey of Recent Advances
Sep 28, 2020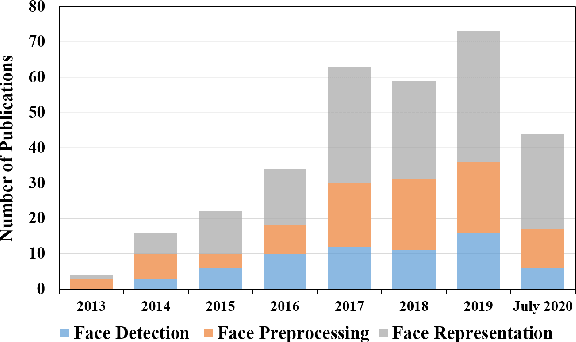
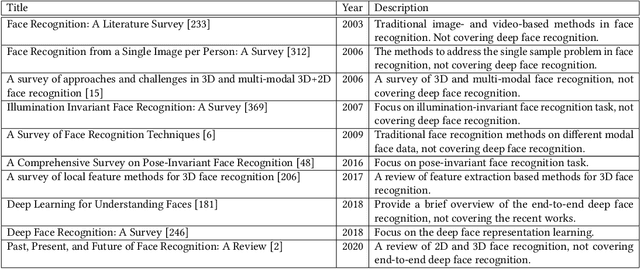
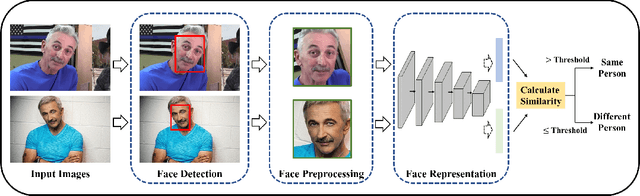
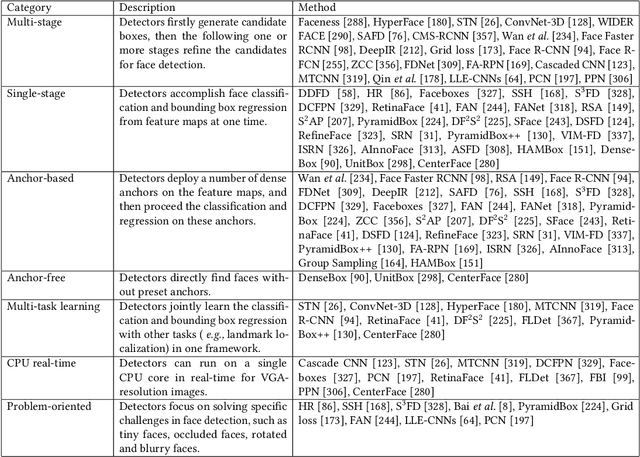
Face recognition is one of the most fundamental and long-standing topics in computer vision community. With the recent developments of deep convolutional neural networks and large-scale datasets, deep face recognition has made remarkable progress and been widely used in the real-world applications. Given a natural image or video frame as input, an end-to-end deep face recognition system outputs the face feature for recognition. To achieve this, the whole system is generally built with three key elements: face detection, face preprocessing, and face representation. The face detection locates faces in the image or frame. Then, the face preprocessing is proceeded to calibrate the faces to a canonical view and crop them to a normalized pixel size. Finally, in the stage of face representation, the discriminative features are extracted from the preprocessed faces for recognition. All of the three elements are fulfilled by deep convolutional neural networks. In this paper, we present a comprehensive survey about the recent advances of every element of the end-to-end deep face recognition, since the thriving deep learning techniques have greatly improved the capability of them. To start with, we introduce an overview of the end-to-end deep face recognition, which, as mentioned above, includes face detection, face preprocessing, and face representation. Then, we review the deep learning based advances of each element, respectively, covering many aspects such as the up-to-date algorithm designs, evaluation metrics, datasets, performance comparison, existing challenges, and promising directions for future research. We hope this survey could bring helpful thoughts to one for better understanding of the big picture of end-to-end face recognition and deeper exploration in a systematic way.
Deep Learning for Single Image Super-Resolution: A Brief Review
Aug 09, 2018


Single image super-resolution (SISR) is a notoriously challenging ill-posed problem, which aims to obtain a high- resolution (HR) output from one of its low-resolution (LR) versions. To solve the SISR problem, recently powerful deep learning algorithms have been employed and achieved the state- of-the-art performance. In this survey, we review representative deep learning-based SISR methods, and group them into two categories according to their major contributions to two essential aspects of SISR: the exploration of efficient neural network archi- tectures for SISR, and the development of effective optimization objectives for deep SISR learning. For each category, a baseline is firstly established and several critical limitations of the baseline are summarized. Then representative works on overcoming these limitations are presented based on their original contents as well as our critical understandings and analyses, and relevant comparisons are conducted from a variety of perspectives. Finally we conclude this review with some vital current challenges and future trends in SISR leveraging deep learning algorithms.