 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably accurate adaptive sampling for collocation points in physics-informed neural networks
Apr 01, 2025Despite considerable scientific advances in numerical simulation, efficiently solving PDEs remains a complex and often expensive problem. Physics-informed Neural Networks (PINN) have emerged as an efficient way to learn surrogate solvers by embedding the PDE in the loss function and minimizing its residuals using automatic differentiation at so-called collocation points. Originally uniformly sampled, the choice of the latter has been the subject of recent advances leading to adaptive sampling refinements for PINNs. In this paper, leveraging a new quadrature method for approximating definite integrals, we introduce a provably accurate sampling method for collocation points based on the Hessian of the PDE residuals. Comparative experiments conducted on a set of 1D and 2D PDEs demonstrate the benefits of our method.
Leveraging PAC-Bayes Theory and Gibbs Distributions for Generalization Bounds with Complexity Measures
Feb 19, 2024



In statistical learning theory, a generalization bound usually involves a complexity measure imposed by the considered theoretical framework. This limits the scope of such bounds, as other forms of capacity measures or regularizations are used in algorithms. In this paper, we leverage the framework of disintegrated PAC-Bayes bounds to derive a general generalization bound instantiable with arbitrary complexity measures. One trick to prove such a result involves considering a commonly used family of distributions: the Gibbs distributions. Our bound stands in probability jointly over the hypothesis and the learning sample, which allows the complexity to be adapted to the generalization gap as it can be customized to fit both the hypothesis class and the task.
Fair Text Classification with Wasserstein Independence
Nov 21, 2023Group fairness is a central research topic in text classification, where reaching fair treatment between sensitive groups (e.g. women vs. men) remains an open challenge. This paper presents a novel method for mitigating biases in neural text classification, agnostic to the model architecture. Considering the difficulty to distinguish fair from unfair information in a text encoder, we take inspiration from adversarial training to induce Wasserstein independence between representations learned to predict our target label and the ones learned to predict some sensitive attribute. Our approach provides two significant advantages. Firstly, it does not require annotations of sensitive attributes in both testing and training data. This is more suitable for real-life scenarios compared to existing methods that require annotations of sensitive attributes at train time. Second, our approach exhibits a comparable or better fairness-accuracy trade-off compared to existing methods.
Learning Stochastic Majority Votes by Minimizing a PAC-Bayes Generalization Bound
Jun 23, 2021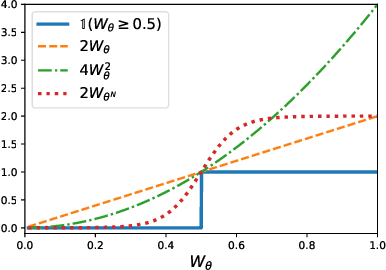
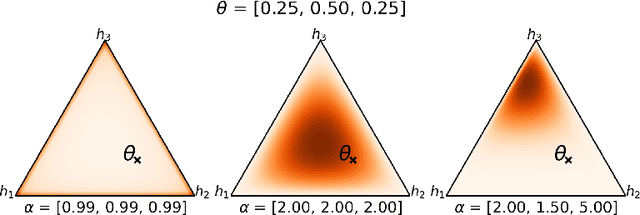
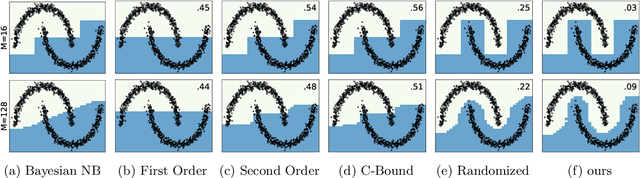
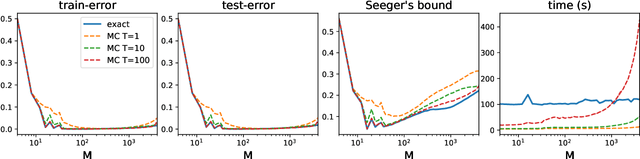
We investigate a stochastic counterpart of majority votes over finite ensembles of classifiers, and study its generalization properties. While our approach holds for arbitrary distributions, we instantiate it with Dirichlet distributions: this allows for a closed-form and differentiable expression for the expected risk, which then turns the generalization bound into a tractable training objective. The resulting stochastic majority vote learning algorithm achieves state-of-the-art accuracy and benefits from (non-vacuous) tight generalization bounds, in a series of numerical experiments when compared to competing algorithms which also minimize PAC-Bayes objectives -- both with uninformed (data-independent) and informed (data-dependent) priors.
Mean Oriented Riesz Features for Micro Expression Classification
May 13, 2020
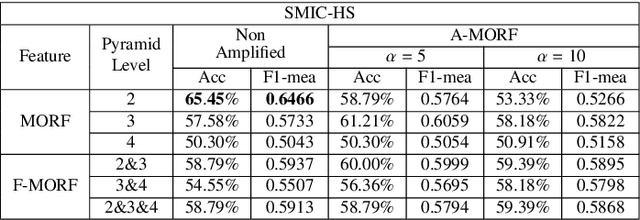
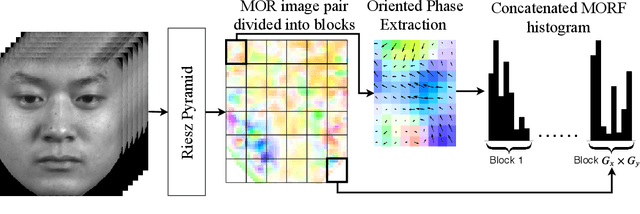
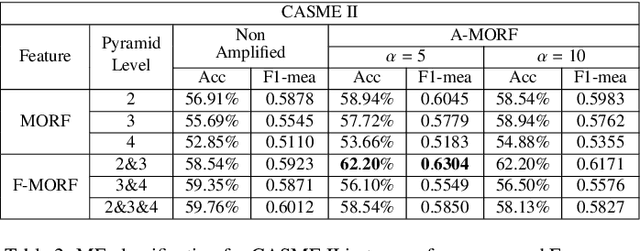
Micro-expressions are brief and subtle facial expressions that go on and off the face in a fraction of a second. This kind of facial expressions usually occurs in high stake situations and is considered to reflect a human's real intent. There has been some interest in micro-expression analysis, however, a great majority of the methods are based on classically established computer vision methods such as local binary patterns, histogram of gradients and optical flow. A novel methodology for micro-expression recognition using the Riesz pyramid, a multi-scale steerable Hilbert transform is presented. In fact, an image sequence is transformed with this tool, then the image phase variations are extracted and filtered as proxies for motion. Furthermore, the dominant orientation constancy from the Riesz transform is exploited to average the micro-expression sequence into an image pair. Based on that, the Mean Oriented Riesz Feature description is introduced. Finally the performance of our methods are tested in two spontaneous micro-expressions databases and compared to state-of-the-art methods.
An Adjusted Nearest Neighbor Algorithm Maximizing the F-Measure from Imbalanced Data
Sep 02, 2019
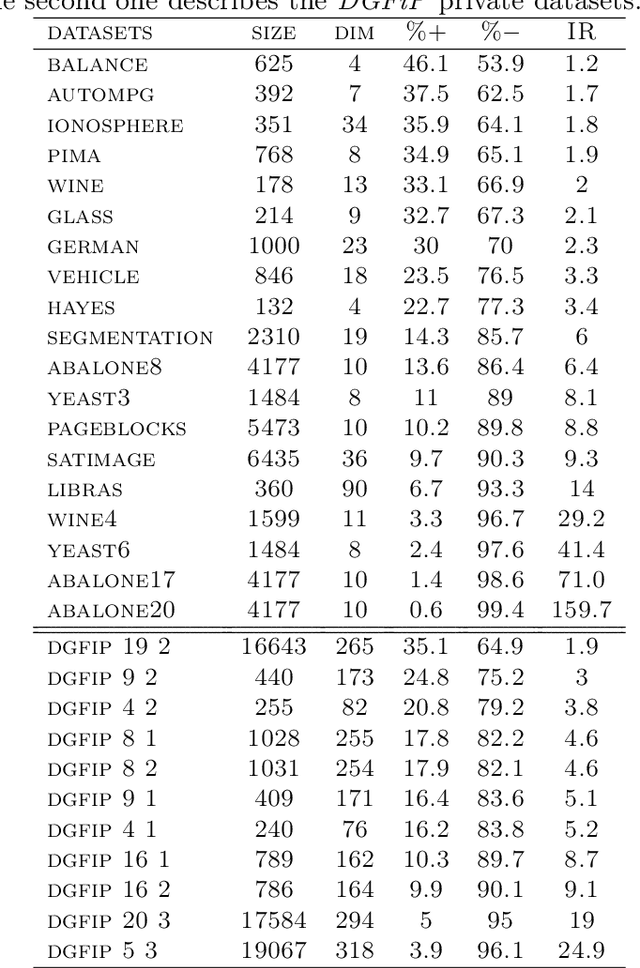
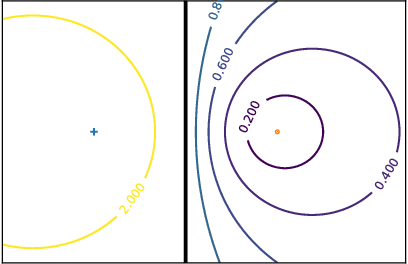
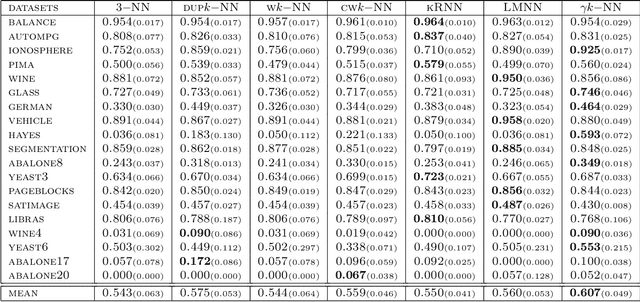
In this paper, we address the challenging problem of learning from imbalanced data using a Nearest-Neighbor (NN) algorithm. In this setting, the minority examples typically belong to the class of interest requiring the optimization of specific criteria, like the F-Measure. Based on simple geometrical ideas, we introduce an algorithm that reweights the distance between a query sample and any positive training example. This leads to a modification of the Voronoi regions and thus of the decision boundaries of the NN algorithm. We provide a theoretical justification about the weighting scheme needed to reduce the False Negative rate while controlling the number of False Positives. We perform an extensive experimental study on many public imbalanced datasets, but also on large scale non public data from the French Ministry of Economy and Finance on a tax fraud detection task, showing that our method is very effective and, interestingly, yields the best performance when combined with state of the art sampling methods.
Learning Interpretable Shapelets for Time Series Classification through Adversarial Regularization
Jun 12, 2019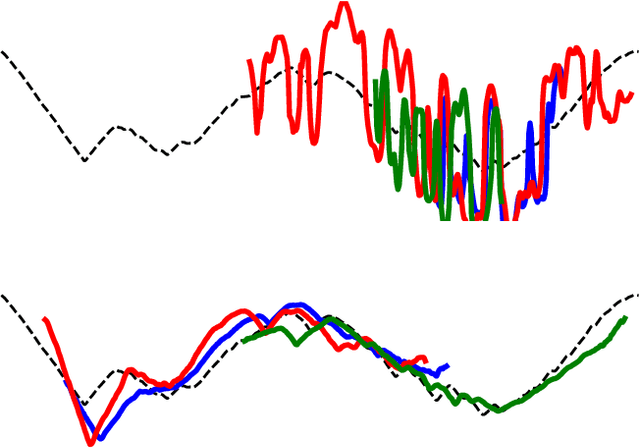
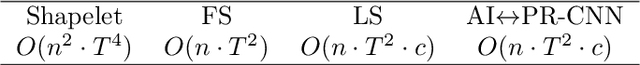
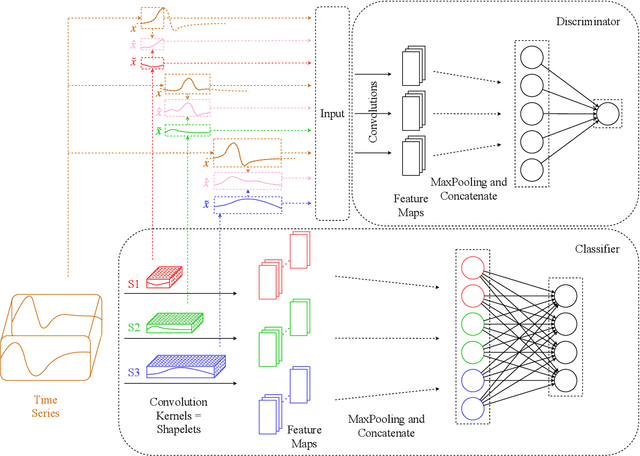
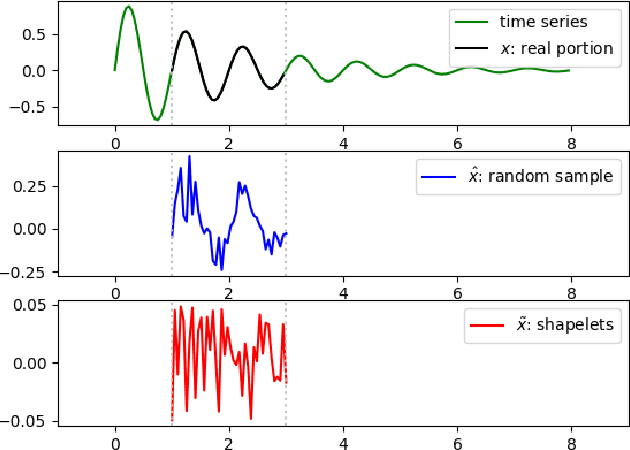
Times series classification can be successfully tackled by jointly learning a shapelet-based representation of the series in the dataset and classifying the series according to this representation. However, although the learned shapelets are discriminative, they are not always similar to pieces of a real series in the dataset. This makes it difficult to interpret the decision, i.e. difficult to analyze if there are particular behaviors in a series that triggered the decision. In this paper, we make use of a simple convolutional network to tackle the time series classification task and we introduce an adversarial regularization to constrain the model to learn more interpretable shapelets. Our classification results on all the usual time series benchmarks are comparable with the results obtained by similar state-of-the-art algorithms but our adversarially regularized method learns shapelets that are, by design, interpretable.
End-to-end Learning for Early Classification of Time Series
Jan 30, 2019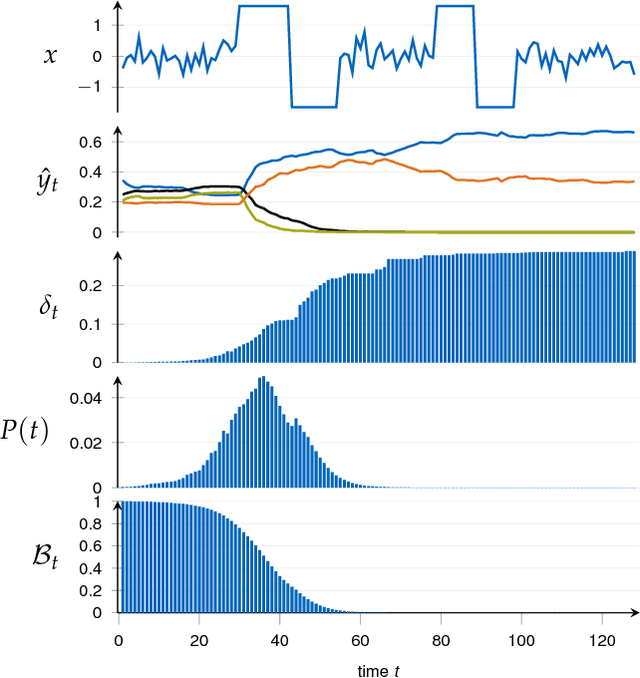

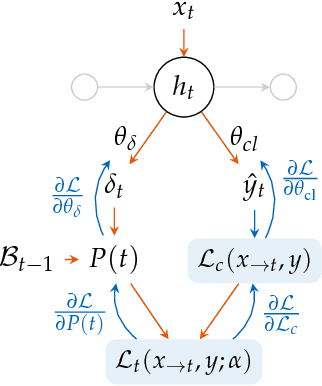
Classification of time series is a topical issue in machine learning. While accuracy stands for the most important evaluation criterion, some applications require decisions to be made as early as possible. Optimization should then target a compromise between earliness, i.e., a capacity of providing a decision early in the sequence, and accuracy. In this work, we propose a generic, end-to-end trainable framework for early classification of time series. This framework embeds a learnable decision mechanism that can be plugged into a wide range of already existing models. We present results obtained with deep neural networks on a diverse set of time series classification problems. Our approach compares well to state-of-the-art competitors while being easily adaptable by any existing neural network topology that evaluates a hidden state at each time step.
IoU is not submodular
Sep 03, 2018
This short article aims at demonstrate that the Intersection over Union (or Jaccard index) is not a submodular function. This mistake has been made in an article which is cited and used as a foundation in another article. The Intersection of Union is widely used in machine learning as a cost function especially for imbalance data and semantic segmentation.
Residual Conv-Deconv Grid Network for Semantic Segmentation
Jul 26, 2017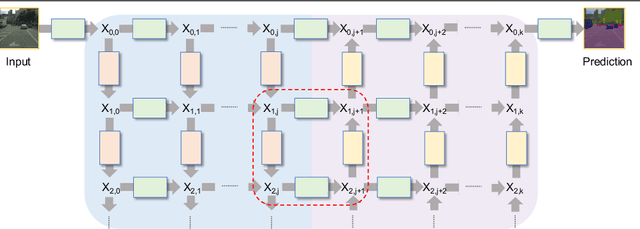
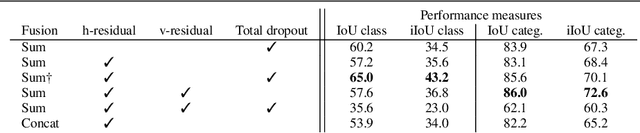
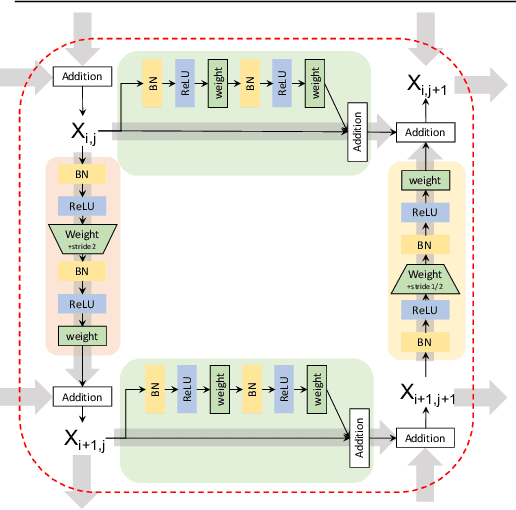

This paper presents GridNet, a new Convolutional Neural Network (CNN) architecture for semantic image segmentation (full scene labelling). Classical neural networks are implemented as one stream from the input to the output with subsampling operators applied in the stream in order to reduce the feature maps size and to increase the receptive field for the final prediction. However, for semantic image segmentation, where the task consists in providing a semantic class to each pixel of an image, feature maps reduction is harmful because it leads to a resolution loss in the output prediction. To tackle this problem, our GridNet follows a grid pattern allowing multiple interconnected streams to work at different resolutions. We show that our network generalizes many well known networks such as conv-deconv, residual or U-Net networks. GridNet is trained from scratch and achieves competitive results on the Cityscapes dataset.