 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D Surface Reconstruction From Multi-Date Satellite Images
Feb 04, 2021



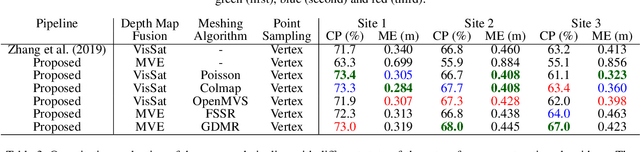
The reconstruction of accurate three-dimensional environment models is one of the most fundamental goals in the field of photogrammetry. Since satellite images provide suitable properties for obtaining large-scale environment reconstructions, there exist a variety of Stereo Matching based methods to reconstruct point clouds for satellite image pairs. Recently, the first Structure from Motion (SfM) based approach has been proposed, which allows to reconstruct point clouds from multiple satellite images. In this work, we propose an extension of this SfM based pipeline that allows us to reconstruct not only point clouds but watertight meshes including texture information. We provide a detailed description of several steps that are mandatory to exploit state-of-the-art mesh reconstruction algorithms in the context of satellite imagery. This includes a decomposition of finite projective camera calibration matrices, a skew correction of corresponding depth maps and input images as well as the recovery of real-world depth maps from reparameterized depth values. The paper presents an extensive quantitative evaluation on multi-date satellite images demonstrating that the proposed pipeline combined with current meshing algorithms outperforms state-of-the-art point cloud reconstruction algorithms in terms of completeness and median error. We make the source code of our pipeline publicly available.
Keep it Simple: Data-efficient Learning for Controlling Complex Systems with Simple Models
Feb 04, 2021
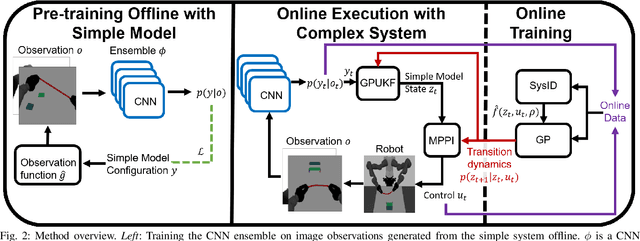


When manipulating a novel object with complex dynamics, a state representation is not always available, for example for deformable objects. Learning both a representation and dynamics from observations requires large amounts of data. We propose Learned Visual Similarity Predictive Control (LVSPC), a novel method for data-efficient learning to control systems with complex dynamics and high-dimensional state spaces from images. LVSPC leverages a given simple model approximation from which image observations can be generated. We use these images to train a perception model that estimates the simple model state from observations of the complex system online. We then use data from the complex system to fit the parameters of the simple model and learn where this model is inaccurate, also online. Finally, we use Model Predictive Control and bias the controller away from regions where the simple model is inaccurate and thus where the controller is less reliable. We evaluate LVSPC on two tasks; manipulating a tethered mass and a rope. We find that our method performs comparably to state-of-the-art reinforcement learning methods with an order of magnitude less data. LVSPC also completes the rope manipulation task on a real robot with 80% success rate after only 10 trials, despite using a perception system trained only on images from simulation.
Full and Reduced Order Observers for Image-based Depth Estimation using Concurrent Learning
Aug 11, 2020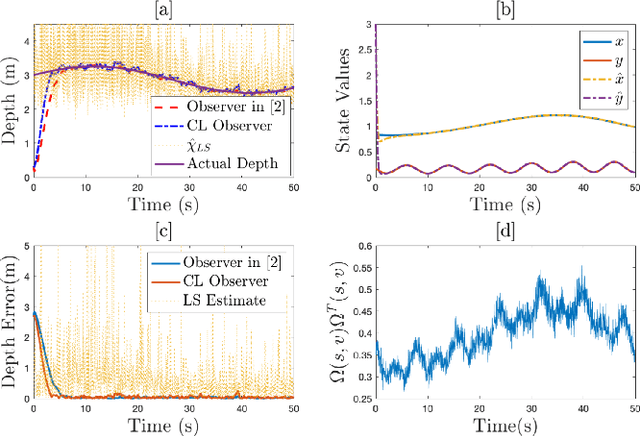
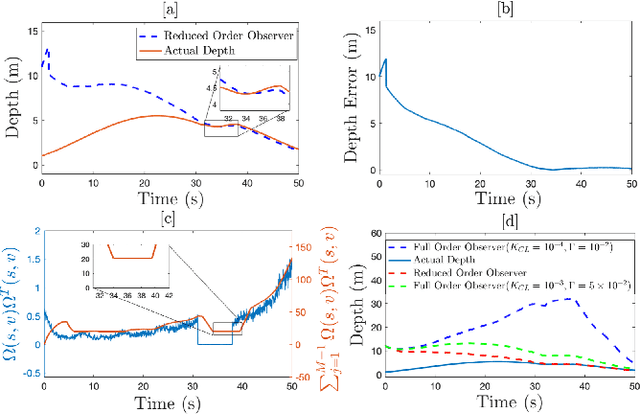
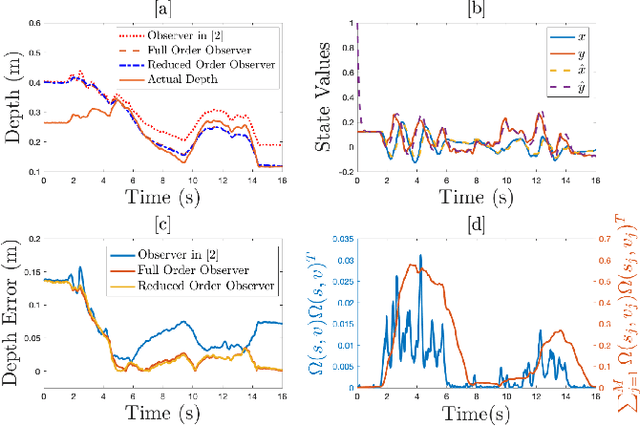
In this paper concurrent learning (CL)-based full and reduced order observers for a perspective dynamical system (PDS) are developed. The PDS is a widely used model for estimating the depth of a feature point from a sequence of camera images. Building on the current progress of CL for parameter estimation in adaptive control, a state observer is developed for the PDS model where the inverse depth appears as a time-varying parameter in the dynamics. The data recorded over a sliding time window in the near past is used in the CL term to design the full and the reduced order state observers. A Lyapunov-based stability analysis is carried out to prove the uniformly ultimately bounded (UUB) stability of the developed observers. Simulation results are presented to validate the accuracy and convergence of the developed observers in terms of convergence time, root mean square error (RMSE) and mean absolute percentage error (MAPE) metrics. Real world depth estimation experiments are performed to demonstrate the performance of the observers using aforementioned metrics on a 7-DoF manipulator with an eye-in-hand configuration.
Seeing with Humans: Gaze-Assisted Neural Image Captioning
Aug 18, 2016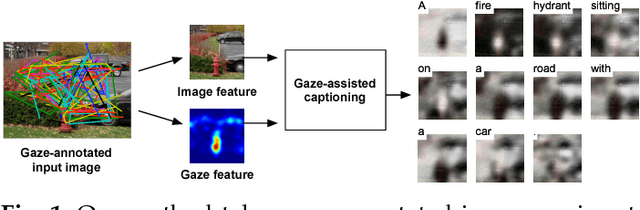
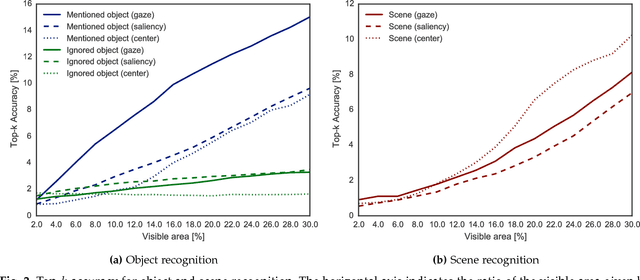
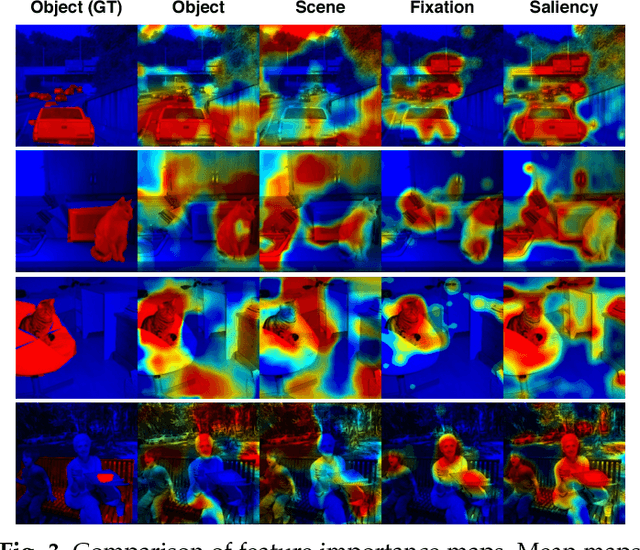
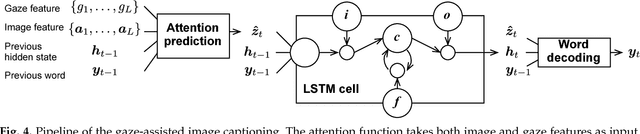
Gaze reflects how humans process visual scenes and is therefore increasingly used in computer vision systems. Previous works demonstrated the potential of gaze for object-centric tasks, such as object localization and recognition, but it remains unclear if gaze can also be beneficial for scene-centric tasks, such as image captioning. We present a new perspective on gaze-assisted image captioning by studying the interplay between human gaze and the attention mechanism of deep neural networks. Using a public large-scale gaze dataset, we first assess the relationship between state-of-the-art object and scene recognition models, bottom-up visual saliency, and human gaze. We then propose a novel split attention model for image captioning. Our model integrates human gaze information into an attention-based long short-term memory architecture, and allows the algorithm to allocate attention selectively to both fixated and non-fixated image regions. Through evaluation on the COCO/SALICON datasets we show that our method improves image captioning performance and that gaze can complement machine attention for semantic scene understanding tasks.
Model Compression Using Optimal Transport
Dec 07, 2020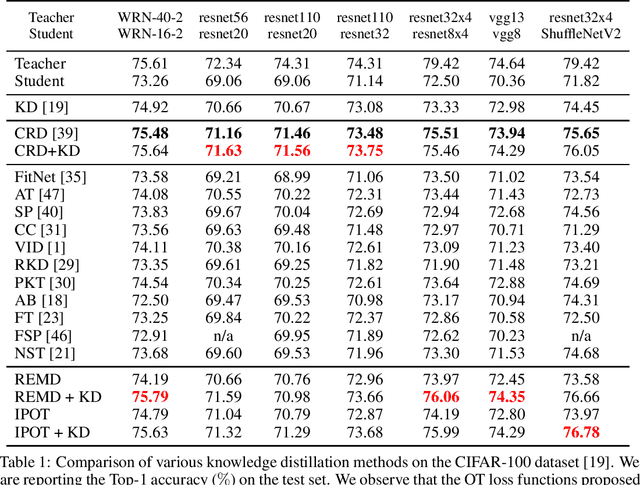
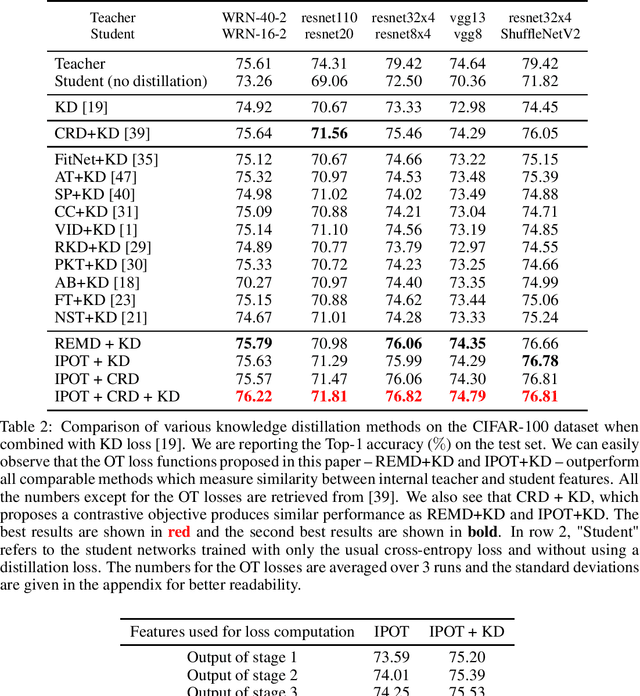
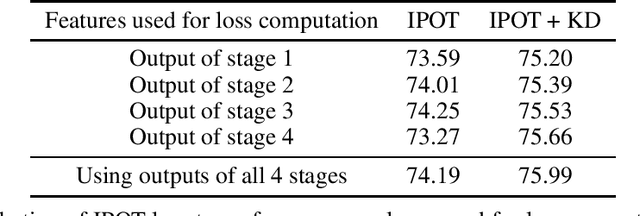

Model compression methods are important to allow for easier deployment of deep learning models in compute, memory and energy-constrained environments such as mobile phones. Knowledge distillation is a class of model compression algorithm where knowledge from a large teacher network is transferred to a smaller student network thereby improving the student's performance. In this paper, we show how optimal transport-based loss functions can be used for training a student network which encourages learning student network parameters that help bring the distribution of student features closer to that of the teacher features. We present image classification results on CIFAR-100, SVHN and ImageNet and show that the proposed optimal transport loss functions perform comparably to or better than other loss functions.
Salient Object Detection via Integrity Learning
Feb 21, 2021
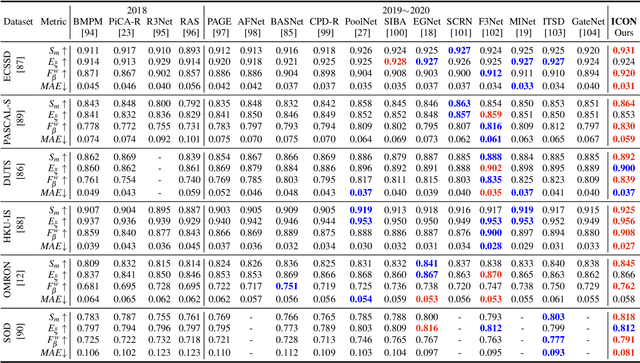
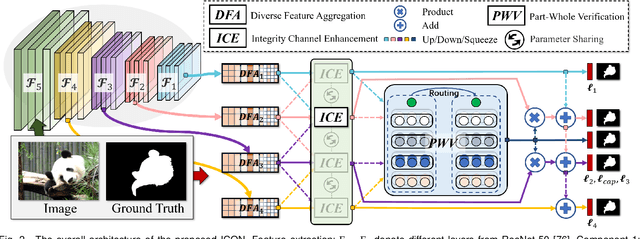
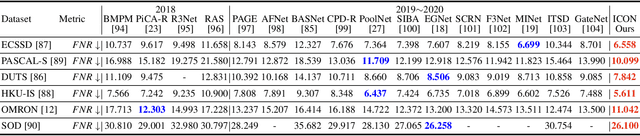
Albeit current salient object detection (SOD) works have achieved fantastic progress, they are cast into the shade when it comes to the integrity of the predicted salient regions. We define the concept of integrity at both the micro and macro level. Specifically, at the micro level, the model should highlight all parts that belong to a certain salient object, while at the macro level, the model needs to discover all salient objects from the given image scene. To facilitate integrity learning for salient object detection, we design a novel Integrity Cognition Network (ICON), which explores three important components to learn strong integrity features. 1) Unlike the existing models that focus more on feature discriminability, we introduce a diverse feature aggregation (DFA) component to aggregate features with various receptive fields (i.e.,, kernel shape and context) and increase the feature diversity. Such diversity is the foundation for mining the integral salient objects. 2) Based on the DFA features, we introduce the integrity channel enhancement (ICE) component with the goal of enhancing feature channels that highlight the integral salient objects at the macro level, while suppressing the other distracting ones. 3) After extracting the enhanced features, the part-whole verification (PWV) method is employed to determine whether the part and whole object features have strong agreement. Such part-whole agreements can further improve the micro-level integrity for each salient object. To demonstrate the effectiveness of ICON, comprehensive experiments are conducted on seven challenging benchmarks, where promising results are achieved.
Multi-Scale Thermal to Visible Face Verification via Attribute Guided Synthesis
Apr 20, 2020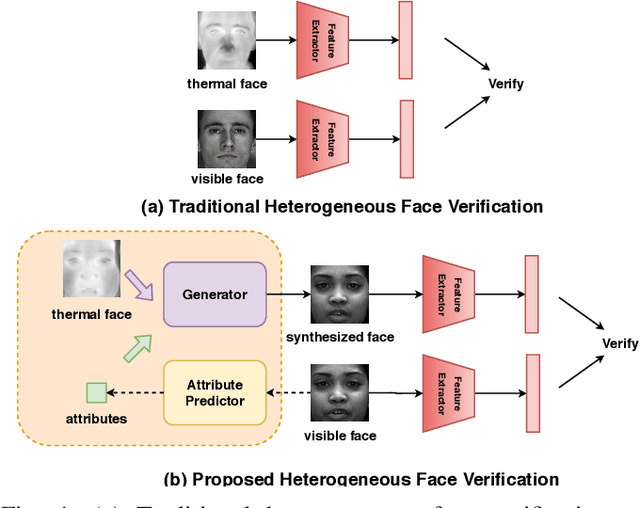



Thermal-to-visible face verification is a challenging problem due to the large domain discrepancy between the modalities. Existing approaches either attempt to synthesize visible faces from thermal faces or extract robust features from these modalities for cross-modal matching. In this paper, we use attributes extracted from visible images to synthesize the attributepreserved visible images from thermal imagery for cross-modal matching. A pre-trained VGG-Face network is used to extract the attributes from the visible image. Then, a novel multi-scale generator is proposed to synthesize the visible image from the thermal image guided by the extracted attributes. Finally, a pretrained VGG-Face network is leveraged to extract features from the synthesized image and the input visible image for verification. An extended dataset consisting of polarimetric thermal faces of 121 subjects is also introduced. Extensive experiments evaluated on various datasets and protocols demonstrate that the proposed method achieves state-of-the-art per-formance.
BRULÉ: Barycenter-Regularized Unsupervised Landmark Extraction
Jun 20, 2020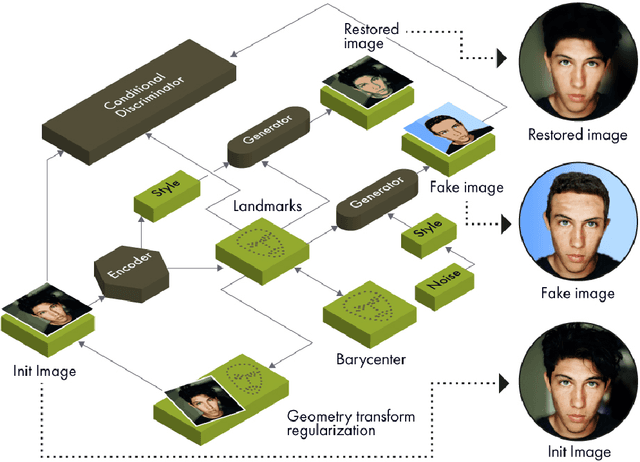
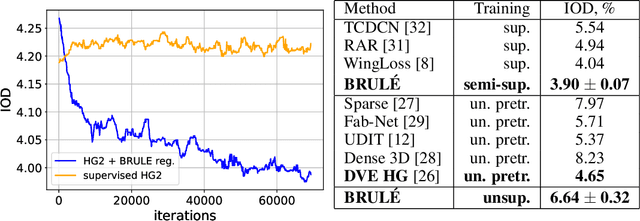
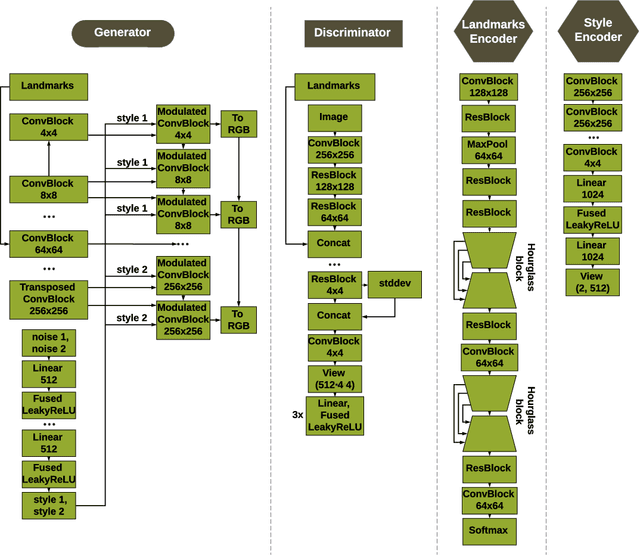

Unsupervised retrieval of image features is vital for many computer vision tasks where the annotation is missing or scarce. In this work, we propose a new unsupervised approach to detect the landmarks in images, and we validate it on the popular task of human face key-points extraction. The method is based on the idea of auto-encoding the wanted landmarks in the latent space while discarding the non-essential information in the image and effectively preserving the interpretability. The interpretable latent space representation is achieved with the aid of a novel two-step regularization paradigm. The first regularization step evaluates transport distance from a given set of landmarks to the average value (the barycenter by Wasserstein distance). The second regularization step controls deviations from the barycenter by applying random geometric deformations synchronously to the initial image and to the encoded landmarks. During decoding, we add style features generated from the noise and reconstruct the initial image by the generative adversarial network (GAN) with transposed convolutions modulated by this style. We demonstrate the effectiveness of the approach both in unsupervised and in semi-supervised training scenarios using the 300-W and the CelebA datasets. The proposed regularization paradigm is shown to prevent overfitting, and the detection quality is shown to improve beyond the supervised outcome.
Geometrical Stem Detection from Image Data for Precision Agriculture
Dec 13, 2018
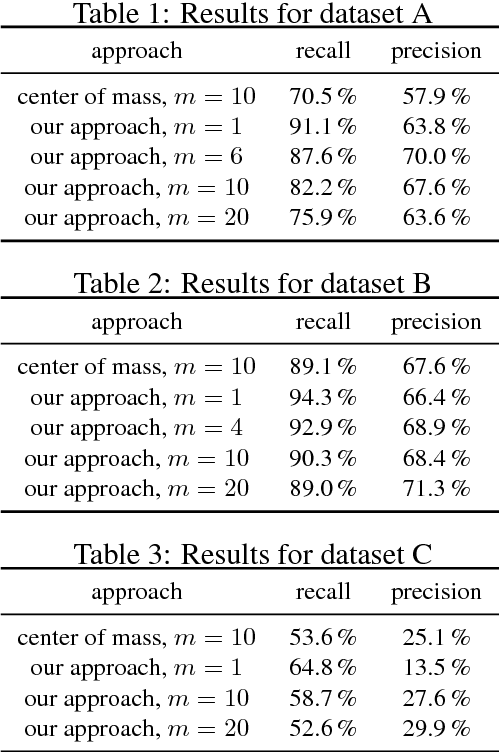
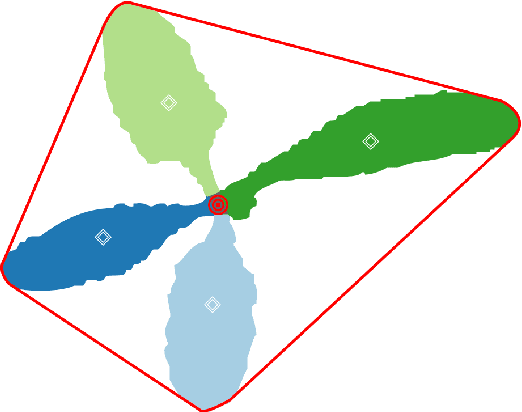
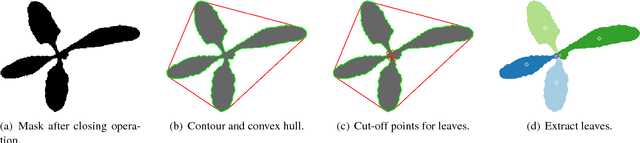
High efficiency in precision farming depends on accurate tools to perform weed detection and mapping of crops. This allows for precise removal of harmful weeds with a lower amount of pesticides, as well as increase of the harvest's yield by providing the farmer with valuable information. In this paper, we address the problem of fully automatic stem detection from image data for this purpose. Our approach runs on mobile agricultural robots taking RGB images. After processing the images to obtain a vegetation mask, our approach separates each plant into its individual leaves and later estimates a precise stem position. This allows an upstream mapping algorithm to add the high-resolution stem positions as a semantic aggregate to the global map of the robot, which can be used for weeding and for analyzing crop statistics. We implemented our approach and thoroughly tested it on three different datasets with vegetation masks and stem position ground truth. The experiments presented in this paper conclude that our module is able to detect leaves and estimate the stem's position at a rate of 56 Hz on a single CPU. We furthermore provide the software to the community.
Unsupervised Anomaly Detection and Localisation with Multi-scale Interpolated Gaussian Descriptors
Jan 25, 2021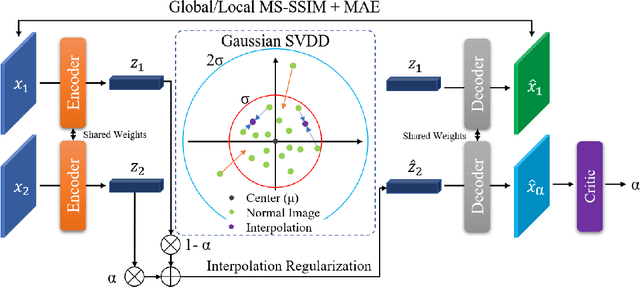
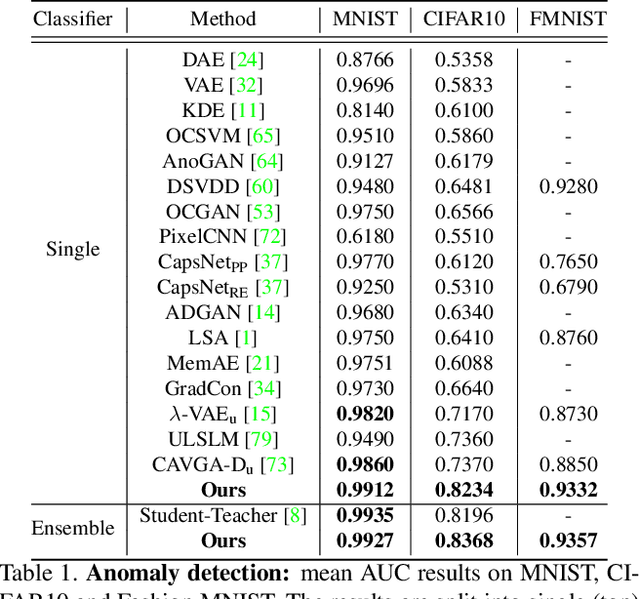
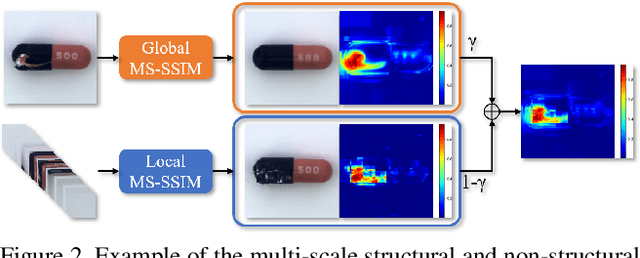
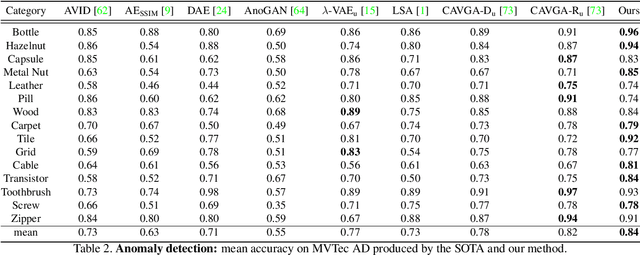
Current unsupervised anomaly detection and localisation systems are commonly formulated as one-class classifiers that depend on an effective estimation of the distribution of normal images and robust criteria to identify anomalies. However, the distribution of normal images estimated by current systems tends to be unstable for classes of normal images that are under-represented in the training set, and the anomaly identification criteria commonly explored in the field does not work well for multi-scale structural and non-structural anomalies. In this paper, we introduce an unsupervised anomaly detection and localisation method designed to address these two issues. More specifically, we introduce a normal image distribution estimation method that is robust to under-represented classes of normal images -- this method is based on adversarially interpolated descriptors from training images and a Gaussian classifier. We also propose a new anomaly identification criterion that can accurately detect and localise multi-scale structural and non-structural anomalies. In extensive experiments on MNIST, Fashion MNIST, CIFAR10 and MVTec AD data sets, our approach shows better results than the current state of the arts in the standard experimental setup for unsupervised anomaly detection and localisation. Code is available at https://github.com/tianyu0207/IGD.