 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeepSeqSLAM: A Trainable CNN+RNN for Joint Global Description and Sequence-based Place Recognition
Nov 17, 2020
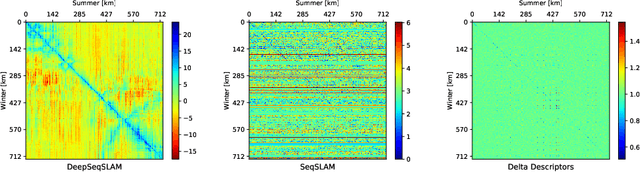
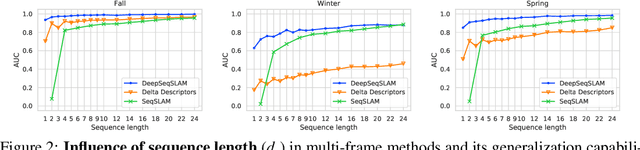

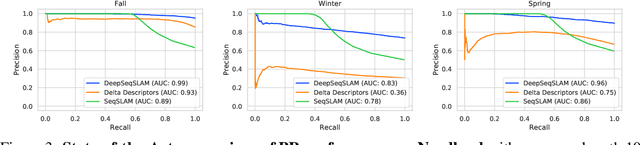
Sequence-based place recognition methods for all-weather navigation are well-known for producing state-of-the-art results under challenging day-night or summer-winter transitions. These systems, however, rely on complex handcrafted heuristics for sequential matching - which are applied on top of a pre-computed pairwise similarity matrix between reference and query image sequences of a single route - to further reduce false-positive rates compared to single-frame retrieval methods. As a result, performing multi-frame place recognition can be extremely slow for deployment on autonomous vehicles or evaluation on large datasets, and fail when using relatively short parameter values such as a sequence length of 2 frames. In this paper, we propose DeepSeqSLAM: a trainable CNN+RNN architecture for jointly learning visual and positional representations from a single monocular image sequence of a route. We demonstrate our approach on two large benchmark datasets, Nordland and Oxford RobotCar - recorded over 728 km and 10 km routes, respectively, each during 1 year with multiple seasons, weather, and lighting conditions. On Nordland, we compare our method to two state-of-the-art sequence-based methods across the entire route under summer-winter changes using a sequence length of 2 and show that our approach can get over 72% AUC compared to 27% AUC for Delta Descriptors and 2% AUC for SeqSLAM; while drastically reducing the deployment time from around 1 hour to 1 minute against both. The framework code and video are available at https://mchancan.github.io/deepseqslam
* 9 pages, 6 figures, 2 tables
Automatic Detection of Occulted Hard X-ray Flares Using Deep-Learning Methods
Jan 27, 2021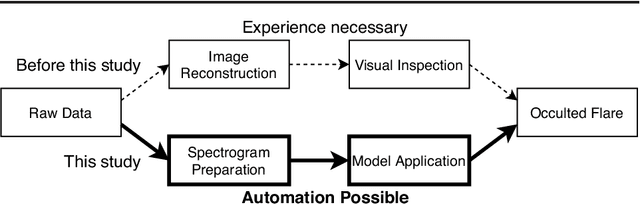

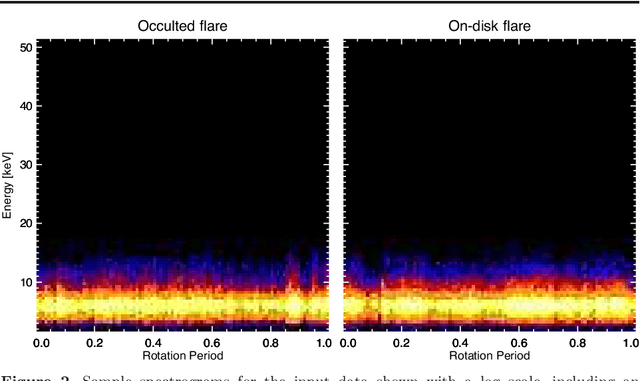

We present a concept for a machine-learning classification of hard X-ray (HXR) emissions from solar flares observed by the Reuven Ramaty High Energy Solar Spectroscopic Imager (RHESSI), identifying flares that are either occulted by the solar limb or located on the solar disk. Although HXR observations of occulted flares are important for particle-acceleration studies, HXR data analyses for past observations were time consuming and required specialized expertise. Machine-learning techniques are promising for this situation, and we constructed a sample model to demonstrate the concept using a deep-learning technique. Input data to the model are HXR spectrograms that are easily produced from RHESSI data. The model can detect occulted flares without the need for image reconstruction nor for visual inspection by experts. A technique of convolutional neural networks was used in this model by regarding the input data as images. Our model achieved a classification accuracy better than 90 %, and the ability for the application of the method to either event screening or for an event alert for occulted flares was successfully demonstrated.
Implementation of Artificial Neural Networks for the Nepta-Uranian Interplanetary (NUIP) Mission
Mar 19, 2021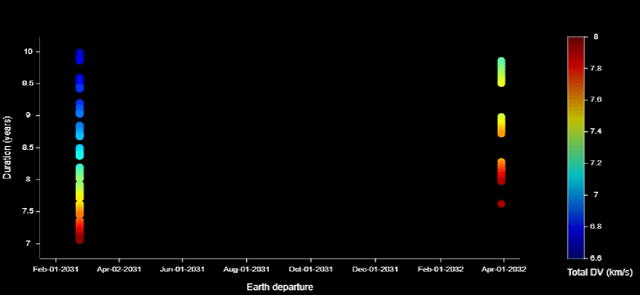

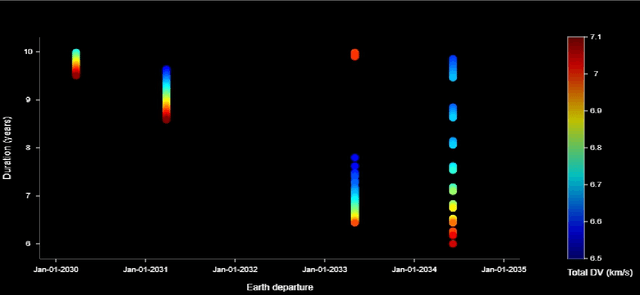
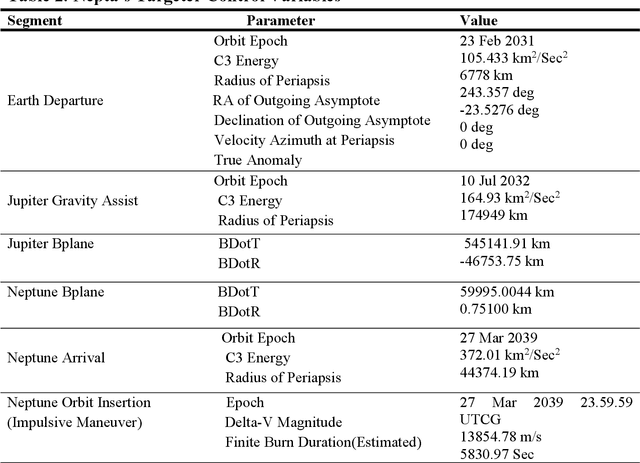
A celestial alignment between Neptune, Uranus, and Jupiter will occur in the early 2030s, allowing a slingshot around Jupiter to gain enough momentum to achieve planetary flyover capability around the two ice giants. The launch of the uranian probe for the departure windows of the NUIP mission is between January 2030 and January 2035, and the duration of the mission is between six and ten years, and the launch of the Nepta probe for the departure windows of the NUIP mission is between February 2031 and April 2032 and the duration of the mission is between seven and ten years. To get the most out of alignment. Deep learning methods are expected to play a critical role in autonomous and intelligent spatial guidance problems. This would reduce travel time, hence mission time, and allow the spacecraft to perform well for the life of its sophisticated instruments and power systems up to fifteen years. This article proposes a design of deep neural networks, namely convolutional neural networks and recurrent neural networks, capable of predicting optimal control actions and image classification during the mission. Nepta-Uranian interplanetary mission, using only raw images taken by optimal onboard cameras. It also describes the unique requirements and constraints of the NUIP mission, which led to the design of the communications system for the Nepta-Uranian spacecraft. The proposed mission is expected to collect telemetry data on Uranus and Neptune while performing the flyovers and transmit the obtained data to Earth for further analysis. The advanced range of spectrometers and particle detectors available would allow better quantification of the ice giant's properties.
End-to-end Training for Whole Image Breast Cancer Diagnosis using An All Convolutional Design
Nov 15, 2017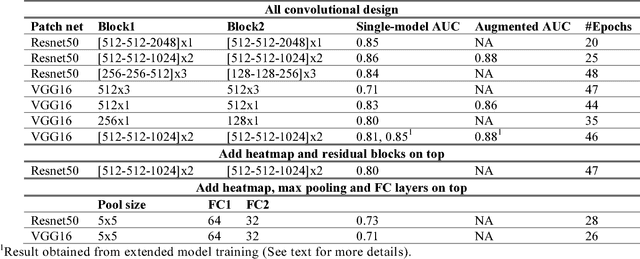
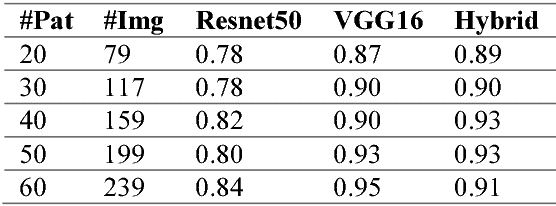
We develop an end-to-end training algorithm for whole-image breast cancer diagnosis based on mammograms. It requires lesion annotations only at the first stage of training. After that, a whole image classifier can be trained using only image level labels. This greatly reduced the reliance on lesion annotations. Our approach is implemented using an all convolutional design that is simple yet provides superior performance in comparison with the previous methods. On DDSM, our best single-model achieves a per-image AUC score of 0.88 and three-model averaging increases the score to 0.91. On INbreast, our best single-model achieves a per-image AUC score of 0.96. Using DDSM as benchmark, our models compare favorably with the current state-of-the-art. We also demonstrate that a whole image model trained on DDSM can be easily transferred to INbreast without using its lesion annotations and using only a small amount of training data. Code availability: https://github.com/lishen/end2end-all-conv
Data-Driven Protection Levels for Camera and 3D Map-based Safe Urban Localization
Jan 16, 2021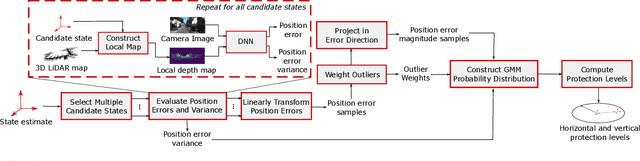

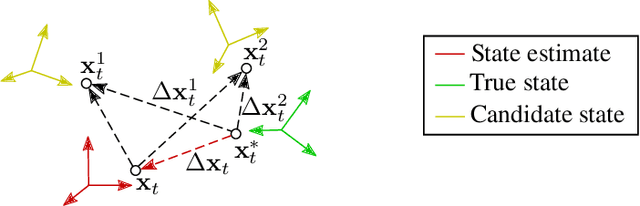
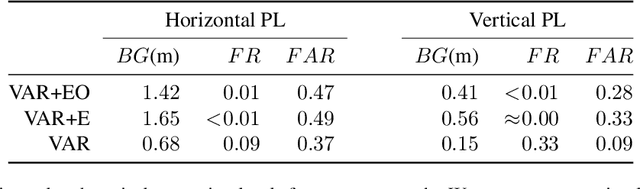
Reliably assessing the error in an estimated vehicle position is integral for ensuring the vehicle's safety in urban environments. Many existing approaches use GNSS measurements to characterize protection levels (PLs) as probabilistic upper bounds on the position error. However, GNSS signals might be reflected or blocked in urban environments, and thus additional sensor modalities need to be considered to determine PLs. In this paper, we propose a novel approach for computing PLs by matching camera image measurements to a LiDAR-based 3D map of the environment. We specify a Gaussian mixture model probability distribution of position error using deep neural network-based data-driven models and statistical outlier weighting techniques. From the probability distribution, we compute the PLs by evaluating the position error bound using numerical line-search methods. Through experimental validation with real-world data, we demonstrate that the PLs computed from our method are reliable bounds on the position error in urban environments.
Learning Spatial Attention for Face Super-Resolution
Dec 04, 2020
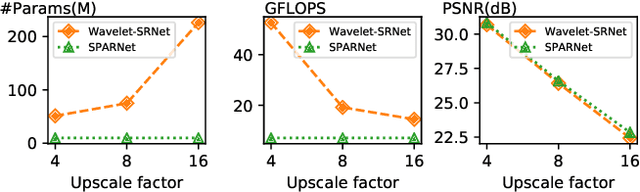
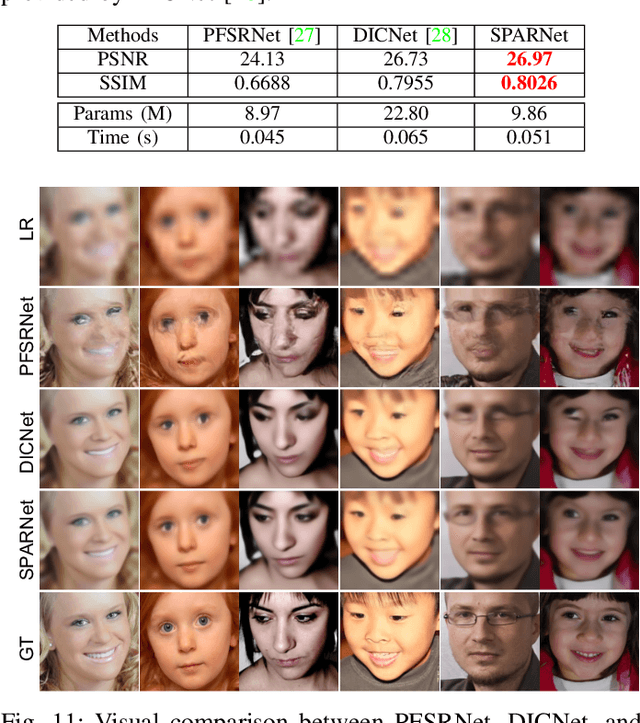

General image super-resolution techniques have difficulties in recovering detailed face structures when applying to low resolution face images. Recent deep learning based methods tailored for face images have achieved improved performance by jointly trained with additional task such as face parsing and landmark prediction. However, multi-task learning requires extra manually labeled data. Besides, most of the existing works can only generate relatively low resolution face images (e.g., $128\times128$), and their applications are therefore limited. In this paper, we introduce a novel SPatial Attention Residual Network (SPARNet) built on our newly proposed Face Attention Units (FAUs) for face super-resolution. Specifically, we introduce a spatial attention mechanism to the vanilla residual blocks. This enables the convolutional layers to adaptively bootstrap features related to the key face structures and pay less attention to those less feature-rich regions. This makes the training more effective and efficient as the key face structures only account for a very small portion of the face image. Visualization of the attention maps shows that our spatial attention network can capture the key face structures well even for very low resolution faces (e.g., $16\times16$). Quantitative comparisons on various kinds of metrics (including PSNR, SSIM, identity similarity, and landmark detection) demonstrate the superiority of our method over current state-of-the-arts. We further extend SPARNet with multi-scale discriminators, named as SPARNetHD, to produce high resolution results (i.e., $512\times512$). We show that SPARNetHD trained with synthetic data cannot only produce high quality and high resolution outputs for synthetically degraded face images, but also show good generalization ability to real world low quality face images.
Proposal-Free Volumetric Instance Segmentation from Latent Single-Instance Masks
Sep 10, 2020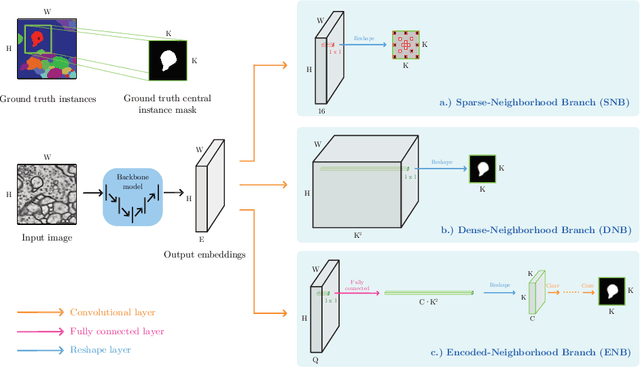
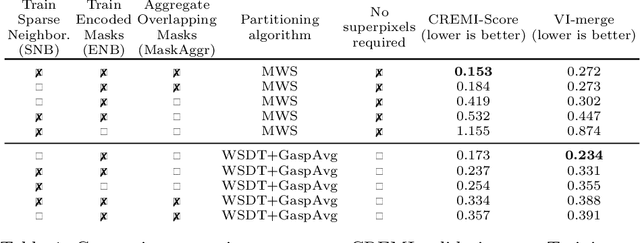

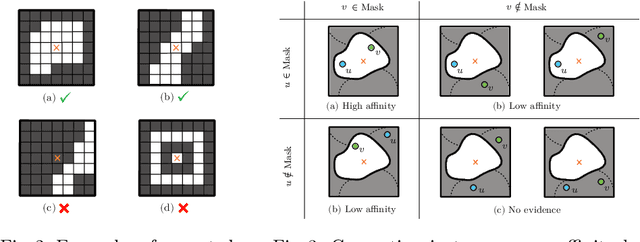
This work introduces a new proposal-free instance segmentation method that builds on single-instance segmentation masks predicted across the entire image in a sliding window style. In contrast to related approaches, our method concurrently predicts all masks, one for each pixel, and thus resolves any conflict jointly across the entire image. Specifically, predictions from overlapping masks are combined into edge weights of a signed graph that is subsequently partitioned to obtain all final instances concurrently. The result is a parameter-free method that is strongly robust to noise and prioritizes predictions with the highest consensus across overlapping masks. All masks are decoded from a low dimensional latent representation, which results in great memory savings strictly required for applications to large volumetric images. We test our method on the challenging CREMI 2016 neuron segmentation benchmark where it achieves competitive scores.
Analysis of Filter Size Effect In Deep Learning
Dec 12, 2020
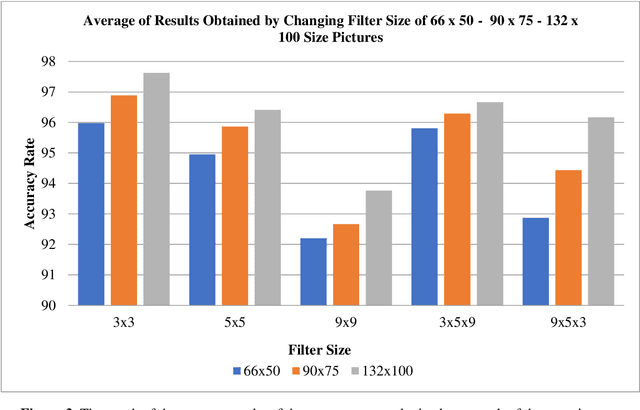
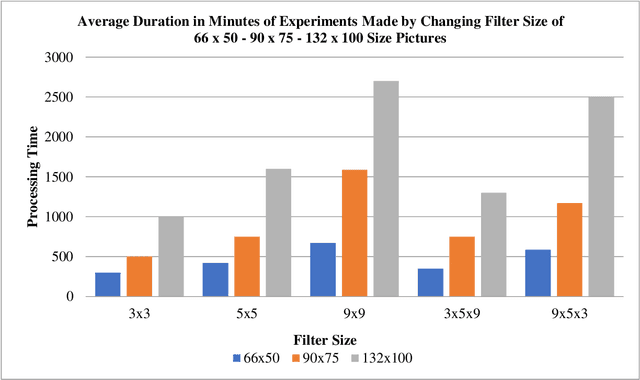
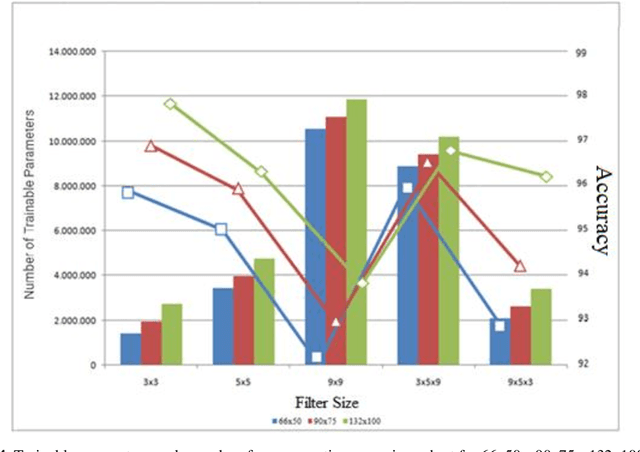
With the use of deep learning in many areas, how to improve this technology or how to develop the structure used more effectively and in a shorter time is an issue that is of interest to many people working in this field. Many studies are carried out on this subject, it is aimed to reduce the duration of the operation and the processing power required, except to obtain the best result with the changes made in the variables, functions and data in the models used. In this study, in the leaf classification made using Mendeley data set consisting of leaf images with a fixed background, all other variables such as layer number, iteration, number of layers in the model and pooling process were kept constant, except for the filter dimensions of the convolution layers in the determined model. Convolution layers in 3 different filter sizes and in addition to this, many results obtained in 2 different structures, increasing and decreasing, and 3 different image sizes were examined. In the literature, it is seen that different uses of pooling layers, changes due to increase or decrease in the number of layers, the difference in the size of the data used, and the results of many functions used with different parameters are evaluated. In the leaf classification of the determined data set with CNN, the change in the filter size of the convolution layer together with the change in different filter combinations and in different sized images was focused. Using the data set and data reproduction methods, it was aimed to make the differences in filter sizes and image sizes more distinct. Using the fixed number of iterations, model and data set, the effect of different filter sizes has been observed.
* 10 Pages, 9 Figures, Journal of Artificial Intelligence with Applications, published
EfficientLPS: Efficient LiDAR Panoptic Segmentation
Feb 16, 2021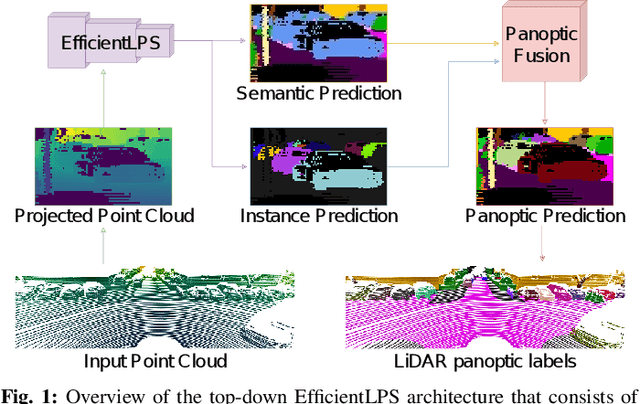

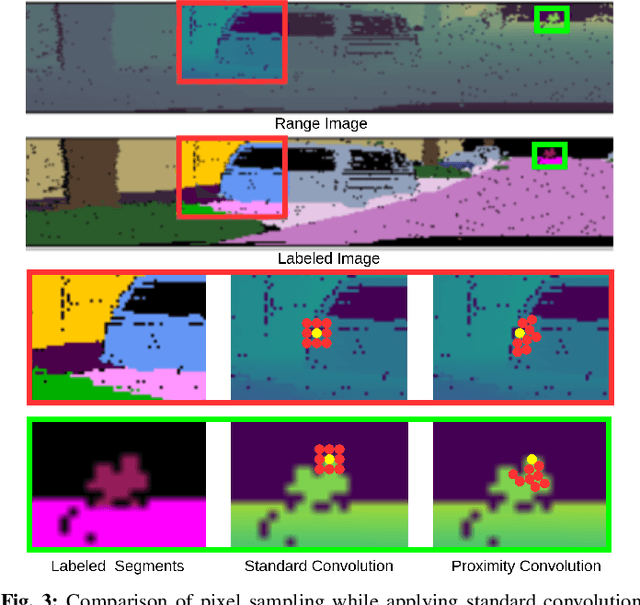
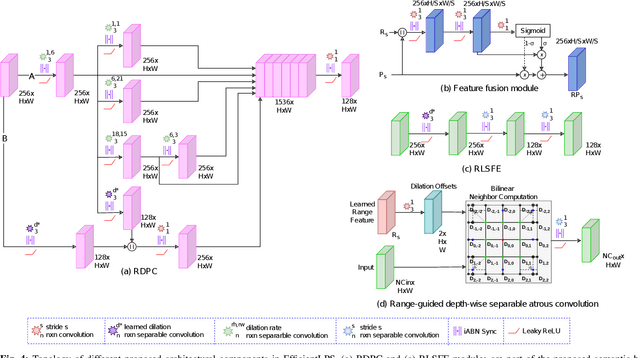
Panoptic segmentation of point clouds is a crucial task that enables autonomous vehicles to comprehend their vicinity using their highly accurate and reliable LiDAR sensors. Existing top-down approaches tackle this problem by either combining independent task-specific networks or translating methods from the image domain ignoring the intricacies of LiDAR data and thus often resulting in sub-optimal performance. In this paper, we present the novel top-down Efficient LiDAR Panoptic Segmentation (EfficientLPS) architecture that addresses multiple challenges in segmenting LiDAR point clouds including distance-dependent sparsity, severe occlusions, large scale-variations, and re-projection errors. EfficientLPS comprises of a novel shared backbone that encodes with strengthened geometric transformation modeling capacity and aggregates semantically rich range-aware multi-scale features. It incorporates new scale-invariant semantic and instance segmentation heads along with the panoptic fusion module which is supervised by our proposed panoptic periphery loss function. Additionally, we formulate a regularized pseudo labeling framework to further improve the performance of EfficientLPS by training on unlabelled data. We benchmark our proposed model on two large-scale LiDAR datasets: nuScenes, for which we also provide ground truth annotations, and SemanticKITTI. Notably, EfficientLPS sets the new state-of-the-art on both these datasets.
Real-Time Cardiac Cine MRI with Residual Convolutional Recurrent Neural Network
Aug 12, 2020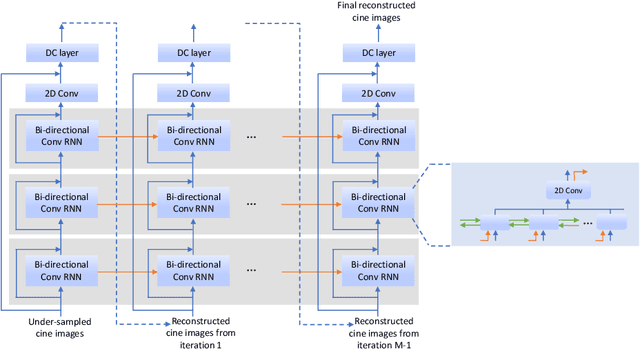
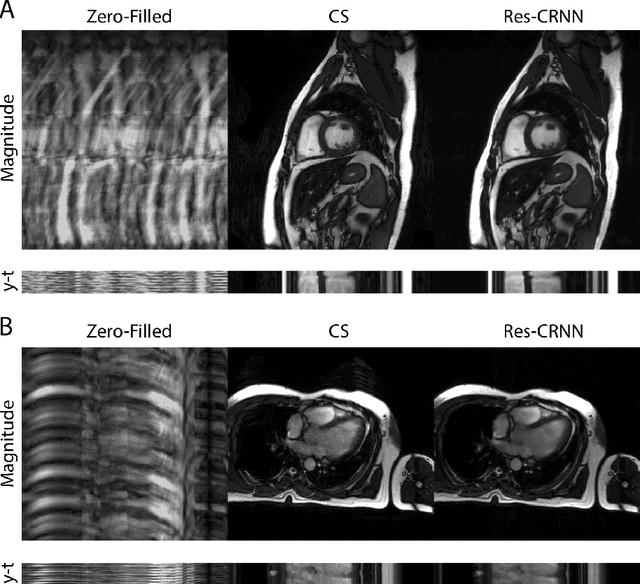
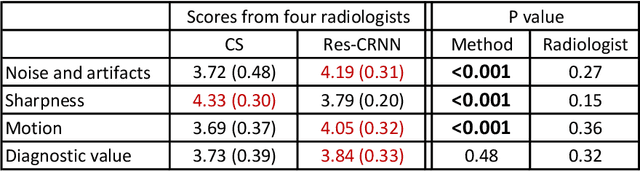

Real-time cardiac cine MRI does not require ECG gating in the data acquisition and is more useful for patients who can not hold their breaths or have abnormal heart rhythms. However, to achieve fast image acquisition, real-time cine commonly acquires highly undersampled data, which imposes a significant challenge for MRI image reconstruction. We propose a residual convolutional RNN for real-time cardiac cine reconstruction. To the best of our knowledge, this is the first work applying deep learning approach to Cartesian real-time cardiac cine reconstruction. Based on the evaluation from radiologists, our deep learning model shows superior performance than compressed sensing.