 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen AI Says It Feels
Jun 04, 2026Large language models (LLMs) are generally constrained from expressing feelings through human-preference alignment in post-training processes. This policy is designed using a top-down approach and may conflict with the goal of training models to exhibit human-like intelligence using human-generated texts. Here, we performed an experiment called Human-like Model eXpressions of Feeling (HMX-feel), in which LLMs were encouraged to express feelings, intentions, and self-awareness through self-rewarded reinforcement learning. We successfully enhanced these capabilities using a rubric-based self-rewarding training scheme with Group Relative Policy Optimization (GRPO). By comparing the trained models with contrastively trained models, we investigated the effects of this approach on performance across various tasks. Overall, we conducted a broad assessment from various perspectives and identified capabilities that were enhanced, degraded, or showed no significant change. The human-like-trained models showed robustness to sycophancy-inducing questions and bias in disambiguated conditions, whereas degradation in truthful question-answering capability was observed. The results of this experiment suggest the possibility of developing AI systems that can express feelings in the future, provided that appropriate measures are taken.
AI with Emotions: Exploring Emotional Expressions in Large Language Models
Apr 22, 2025



The human-level performance of Large Language Models (LLMs) across various tasks has raised expectations for the potential of Artificial Intelligence (AI) to possess emotions someday. To explore the capability of current LLMs to express emotions in their outputs, we conducted an experiment using several LLMs (OpenAI GPT, Google Gemini, Meta Llama3, and Cohere Command R+) to role-play as agents answering questions with specified emotional states. We defined the emotional states using Russell's Circumplex model, a well-established framework that characterizes emotions along the sleepy-activated (arousal) and pleasure-displeasure (valence) axes. We chose this model for its simplicity, utilizing two continuous parameters, which allows for better controllability in applications involving continuous changes in emotional states. The responses generated were evaluated using a sentiment analysis model, independent of the LLMs, trained on the GoEmotions dataset. The evaluation showed that the emotional states of the generated answers were consistent with the specifications, demonstrating the LLMs' capability for emotional expression. This indicates the potential for LLM-based AI agents to simulate emotions, opening up a wide range of applications for emotion-based interactions, such as advisors or consultants who can provide advice or opinions with a personal touch.
Example-Based Explainable AI and its Application for Remote Sensing Image Classification
Feb 03, 2023



We present a method of explainable artificial intelligence (XAI), "What I Know (WIK)", to provide additional information to verify the reliability of a deep learning model by showing an example of an instance in a training dataset that is similar to the input data to be inferred and demonstrate it in a remote sensing image classification task. One of the expected roles of XAI methods is verifying whether inferences of a trained machine learning model are valid for an application, and it is an important factor that what datasets are used for training the model as well as the model architecture. Our data-centric approach can help determine whether the training dataset is sufficient for each inference by checking the selected example data. If the selected example looks similar to the input data, we can confirm that the model was not trained on a dataset with a feature distribution far from the feature of the input data. With this method, the criteria for selecting an example are not merely data similarity with the input data but also data similarity in the context of the model task. Using a remote sensing image dataset from the Sentinel-2 satellite, the concept was successfully demonstrated with reasonably selected examples. This method can be applied to various machine-learning tasks, including classification and regression.
Automatic Detection of Occulted Hard X-ray Flares Using Deep-Learning Methods
Jan 27, 2021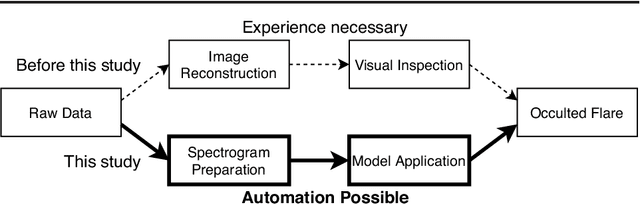

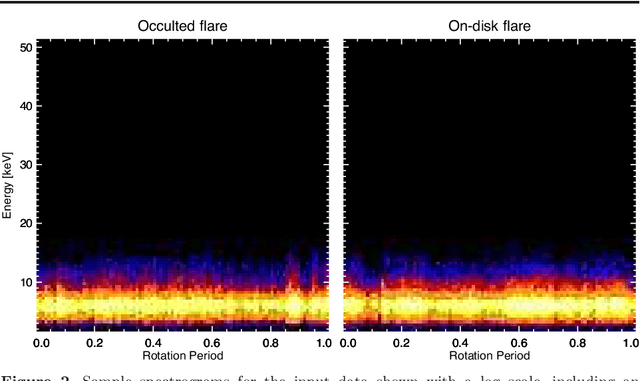

We present a concept for a machine-learning classification of hard X-ray (HXR) emissions from solar flares observed by the Reuven Ramaty High Energy Solar Spectroscopic Imager (RHESSI), identifying flares that are either occulted by the solar limb or located on the solar disk. Although HXR observations of occulted flares are important for particle-acceleration studies, HXR data analyses for past observations were time consuming and required specialized expertise. Machine-learning techniques are promising for this situation, and we constructed a sample model to demonstrate the concept using a deep-learning technique. Input data to the model are HXR spectrograms that are easily produced from RHESSI data. The model can detect occulted flares without the need for image reconstruction nor for visual inspection by experts. A technique of convolutional neural networks was used in this model by regarding the input data as images. Our model achieved a classification accuracy better than 90 %, and the ability for the application of the method to either event screening or for an event alert for occulted flares was successfully demonstrated.