 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FAIM -- A ConvNet Method for Unsupervised 3D Medical Image Registration
Nov 22, 2018
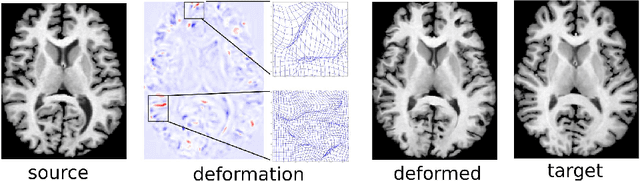

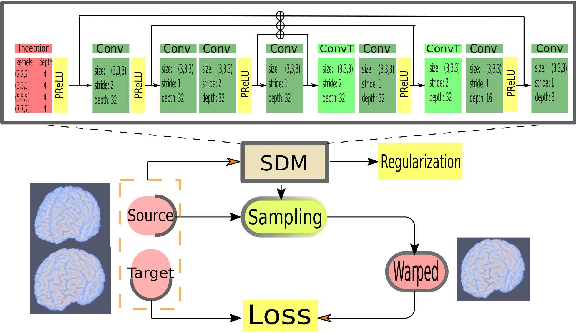

We present a new unsupervised learning algorithm, "FAIM", for 3D medical image registration. Based on a convolutional neural net, FAIM learns from a training set of pairs of images, without needing ground truth information such as landmarks or dense registrations. Once trained, FAIM can register a new pair of images in less than a second, with competitive quality. We compared FAIM with a similar method, VoxelMorph, as well as a diffeomorphic method, uTIlzReg GeoShoot, on the LPBA40 and Mindboggle101 datasets. Results for FAIM were comparable or better than the other methods on pairwise registrations. The effect of different regularization choices on the predicted deformations is briefly investigated. Finally, an application to fast construction of a template and atlas is demonstrated.
Robust Alignment of Multi-Exposed Images with Saturated Regions
Dec 20, 2020
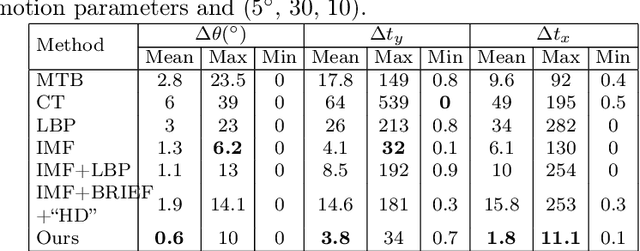

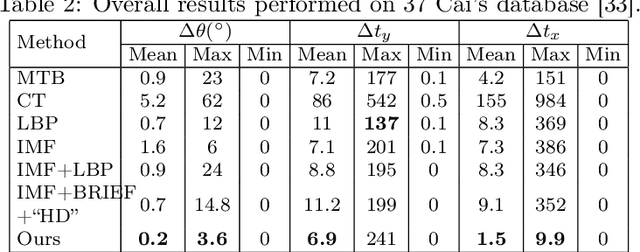
It is challenging to align multi-exposed images due to large illumination variations, especially in presence of saturated regions. In this paper, a novel image alignment algorithm is proposed to cope with the multi-exposed images with saturated regions. Specifically, the multi-exposed images are first normalized by using intensity mapping functions (IMFs) in consideration of saturated pixels. Then, the normalized images are coded by using the local binary pattern (LBP). Finally, the coded images are aligned by formulating an optimization problem by using a differentiable Hamming distance. Experimental results show that the proposed algorithm outperforms state-of-the-art alignment methods for multi-exposed images in terms of alignment accuracy and robustness to exposure values.
Detailed Human Shape Estimation from a Single Image by Hierarchical Mesh Deformation
May 08, 2019
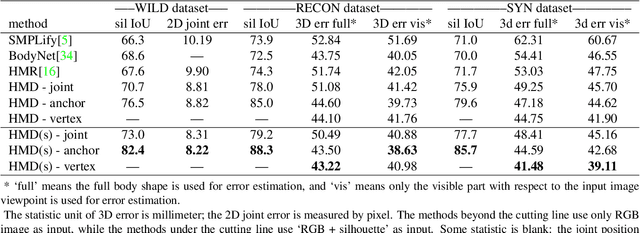

This paper presents a novel framework to recover detailed human body shapes from a single image. It is a challenging task due to factors such as variations in human shapes, body poses, and viewpoints. Prior methods typically attempt to recover the human body shape using a parametric based template that lacks the surface details. As such the resulting body shape appears to be without clothing. In this paper, we propose a novel learning-based framework that combines the robustness of parametric model with the flexibility of free-form 3D deformation. We use the deep neural networks to refine the 3D shape in a Hierarchical Mesh Deformation (HMD) framework, utilizing the constraints from body joints, silhouettes, and per-pixel shading information. We are able to restore detailed human body shapes beyond skinned models. Experiments demonstrate that our method has outperformed previous state-of-the-art approaches, achieving better accuracy in terms of both 2D IoU number and 3D metric distance. The code is available in https://github.com/zhuhao-nju/hmd.git
Bone Feature Segmentation in Ultrasound Spine Image with Robustness to Speckle and Regular Occlusion Noise
Oct 08, 2020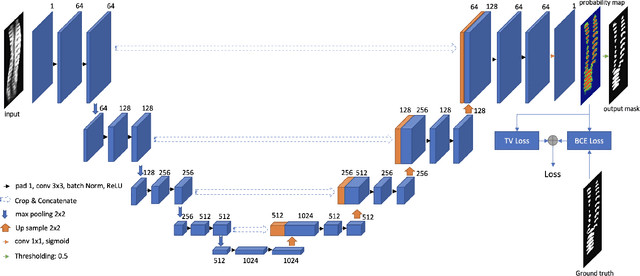
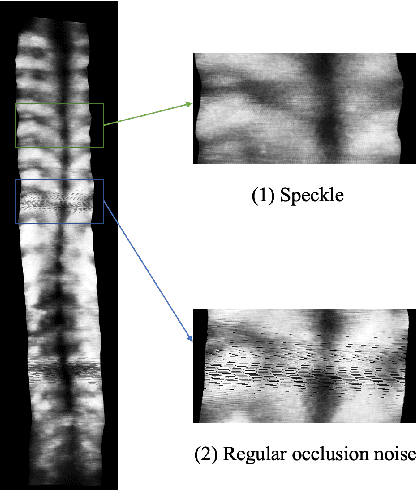

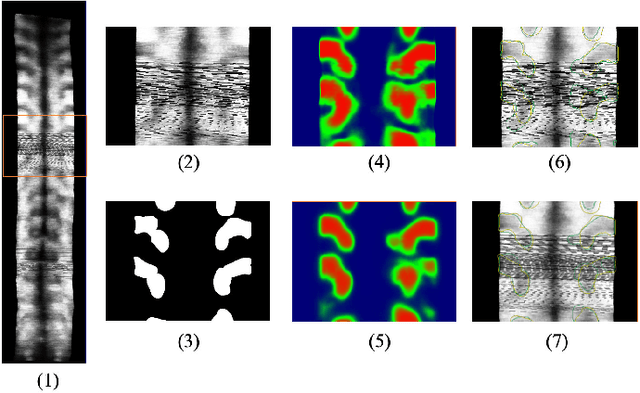
3D ultrasound imaging shows great promise for scoliosis diagnosis thanks to its low-costing, radiation-free and real-time characteristics. The key to accessing scoliosis by ultrasound imaging is to accurately segment the bone area and measure the scoliosis degree based on the symmetry of the bone features. The ultrasound images tend to contain many speckles and regular occlusion noise which is difficult, tedious and time-consuming for experts to find out the bony feature. In this paper, we propose a robust bone feature segmentation method based on the U-net structure for ultrasound spine Volume Projection Imaging (VPI) images. The proposed segmentation method introduces a total variance loss to reduce the sensitivity of the model to small-scale and regular occlusion noise. The proposed approach improves 2.3% of Dice score and 1% of AUC score as compared with the u-net model and shows high robustness to speckle and regular occlusion noise.
On the Effectiveness of Image Rotation for Open Set Domain Adaptation
Jul 24, 2020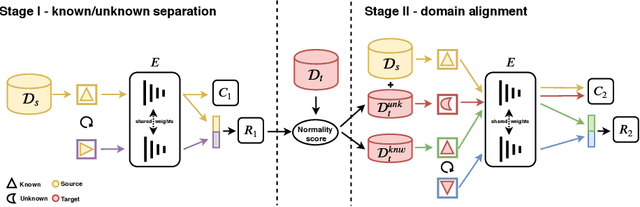
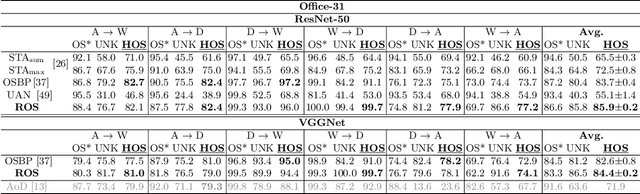
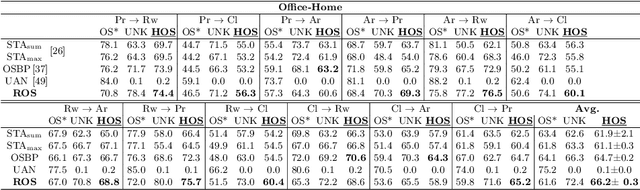

Open Set Domain Adaptation (OSDA) bridges the domain gap between a labeled source domain and an unlabeled target domain, while also rejecting target classes that are not present in the source. To avoid negative transfer, OSDA can be tackled by first separating the known/unknown target samples and then aligning known target samples with the source data. We propose a novel method to addresses both these problems using the self-supervised task of rotation recognition. Moreover, we assess the performance with a new open set metric that properly balances the contribution of recognizing the known classes and rejecting the unknown samples. Comparative experiments with existing OSDA methods on the standard Office-31 and Office-Home benchmarks show that: (i) our method outperforms its competitors, (ii) reproducibility for this field is a crucial issue to tackle, (iii) our metric provides a reliable tool to allow fair open set evaluation.
Structure-Aware Completion of Photogrammetric Meshes in Urban Road Environment
Nov 24, 2020

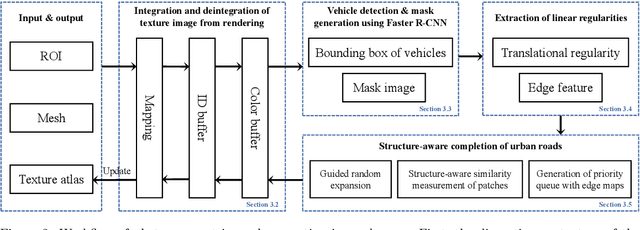

Photogrammetric mesh models obtained from aerial oblique images have been widely used for urban reconstruction. However, the photogrammetric meshes also suffer from severe texture problems, especially on the road areas due to occlusion. This paper proposes a structure-aware completion approach to improve the quality of meshes by removing undesired vehicles on the road seamlessly. Specifically, the discontinuous texture atlas is first integrated to a continuous screen space through rendering by the graphics pipeline; the rendering also records necessary mapping for deintegration to the original texture atlas after editing. Vehicle regions are masked by a standard object detection approach, e.g. Faster RCNN. Then, the masked regions are completed guided by the linear structures and regularities in the road region, which is implemented based on Patch Match. Finally, the completed rendered image is deintegrated to the original texture atlas and the triangles for the vehicles are also flattened for improved meshes. Experimental evaluations and analyses are conducted against three datasets, which are captured with different sensors and ground sample distances. The results reveal that the proposed method can quite realistic meshes after removing the vehicles. The structure-aware completion approach for road regions outperforms popular image completion methods and ablation study further confirms the effectiveness of the linear guidance. It should be noted that the proposed method is also capable to handle tiled mesh models for large-scale scenes. Dataset and code are available at vrlab.org.cn/~hanhu/projects/mesh.
Spirit Distillation: Precise Real-time Prediction with Insufficient Data
Mar 25, 2021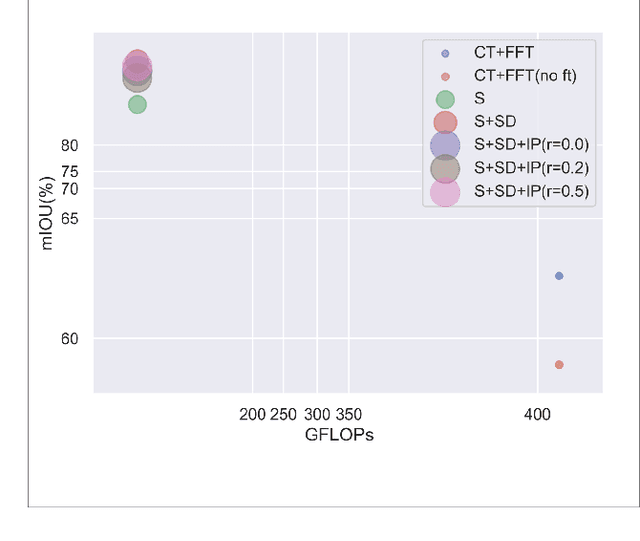
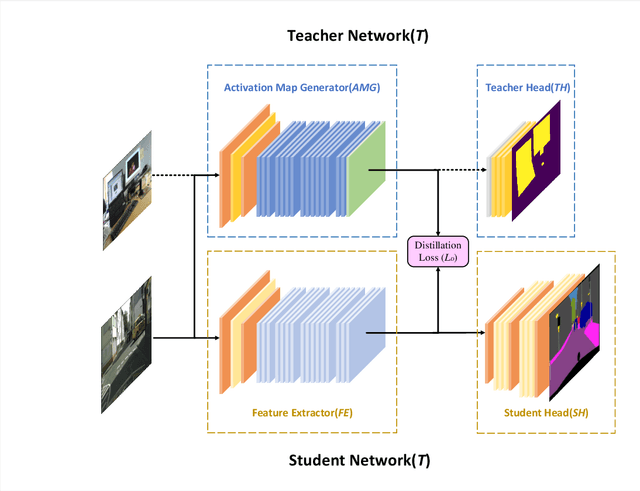
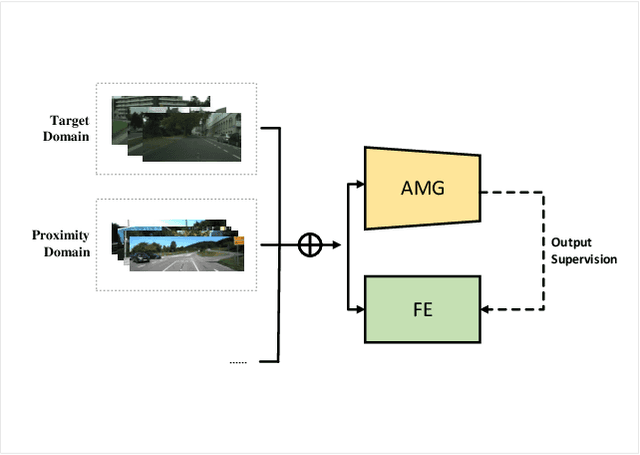
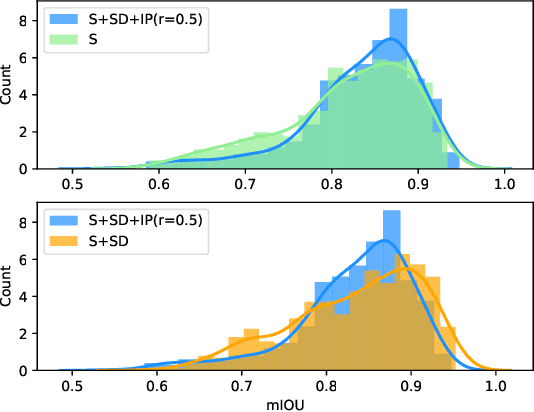
Recent trend demonstrates the effectiveness of deep neural networks (DNNs) apply on the task of environment perception in autonomous driving system. While large-scale and complete data can train out fine DNNs, collecting it is always difficult, expensive, and time-consuming. Also, the significance of both accuracy and efficiency cannot be over-emphasized due to the requirement of real-time recognition. To alleviate the conflicts between weak data and high computational consumption of DNNs, we propose a new training framework named Spirit Distillation(SD). It extends the ideas of fine-tuning-based transfer learning(FTT) and feature-based knowledge distillation. By allowing the student to mimic its teacher in feature extraction, the gap of general features between the teacher-student networks is bridged. The Image Party distillation enhancement method(IP) is also proposed, which shuffling images from various domains, and randomly selecting a few as mini-batch. With this approach, the overfitting that the student network to the general features of the teacher network can be easily avoided. Persuasive experiments and discussions are conducted on CityScapes with the prompt of COCO2017 and KITTI. Results demonstrate the boosting performance in segmentation(mIOU and high-precision accuracy boost by 1.4% and 8.2% respectively, with 78.2% output variance), and can gain a precise compact network with only 41.8\% FLOPs(see Fig. 1). This paper is a pioneering work on knowledge distillation applied to few-shot learning. The proposed methods significantly reduce the dependence on data of DNNs training, and improves the robustness of DNNs when facing rare situations, with real-time requirement satisfied. We provide important technical support for the advancement of scene perception technology for autonomous driving.
Transforming Neural Network Visual Representations to Predict Human Judgments of Similarity
Oct 13, 2020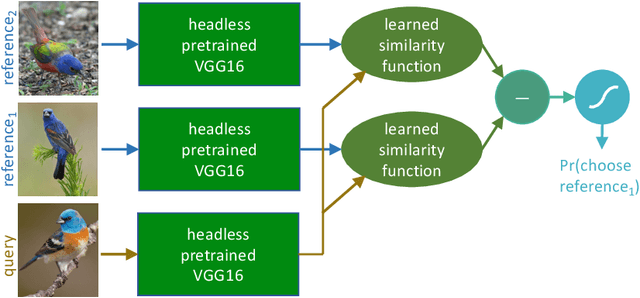
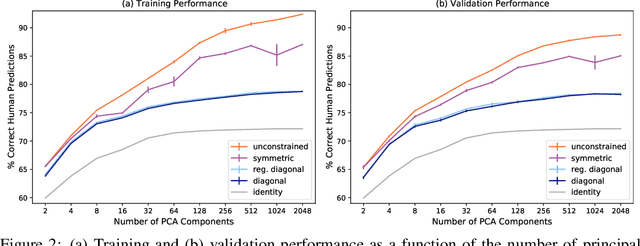
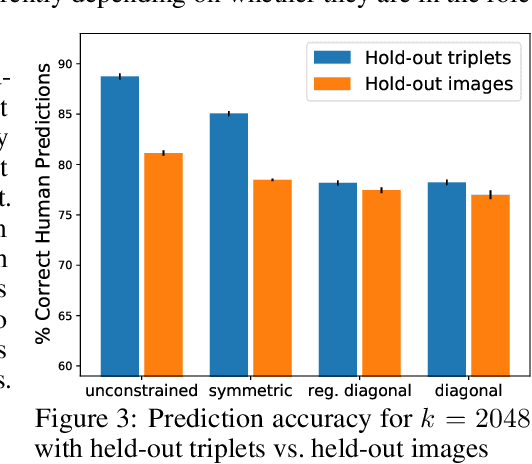
Deep-learning vision models have shown intriguing similarities and differences with respect to human vision. We investigate how to bring machine visual representations into better alignment with human representations. Human representations are often inferred from behavioral evidence such as the selection of an image most similar to a query image. We find that with appropriate linear transformations of deep embeddings, we can improve prediction of human binary choice on a data set of bird images from 72% at baseline to 89%. We hypothesized that deep embeddings have redundant, high (4096) dimensional representations; however, reducing the rank of these representations results in a loss of explanatory power. We hypothesized that the dilation transformation of representations explored in past research is too restrictive, and indeed we found that model explanatory power can be significantly improved with a more expressive linear transform. Most surprising and exciting, we found that, consistent with classic psychological literature, human similarity judgments are asymmetric: the similarity of X to Y is not necessarily equal to the similarity of Y to X, and allowing models to express this asymmetry improves explanatory power.
Contraction Mapping of Feature Norms for Classifier Learning on the Data with Different Quality
Jul 28, 2020
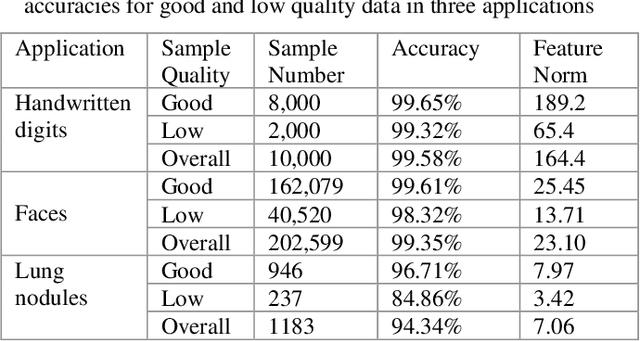
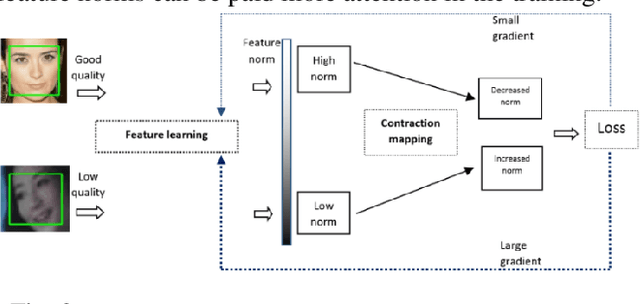
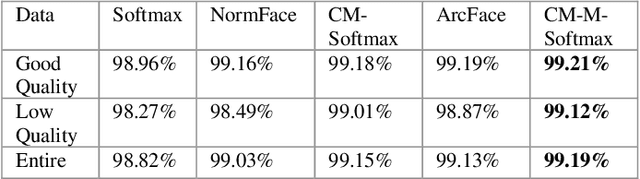
The popular softmax loss and its recent extensions have achieved great success in the deep learning-based image classification. However, the data for training image classifiers usually has different quality. Ignoring such problem, the correct classification of low quality data is hard to be solved. In this paper, we discover the positive correlation between the feature norm of an image and its quality through careful experiments on various applications and various deep neural networks. Based on this finding, we propose a contraction mapping function to compress the range of feature norms of training images according to their quality and embed this contraction mapping function into softmax loss or its extensions to produce novel learning objectives. The experiments on various classification applications, including handwritten digit recognition, lung nodule classification, face verification and face recognition, demonstrate that the proposed approach is promising to effectively deal with the problem of learning on the data with different quality and leads to the significant and stable improvements in the classification accuracy.
Demystifying Contrastive Self-Supervised Learning: Invariances, Augmentations and Dataset Biases
Jul 28, 2020

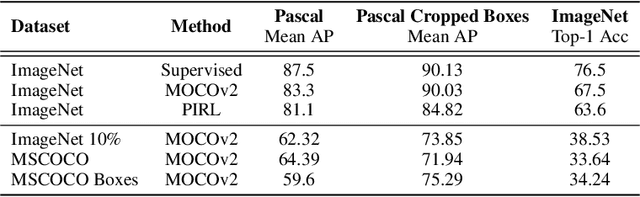
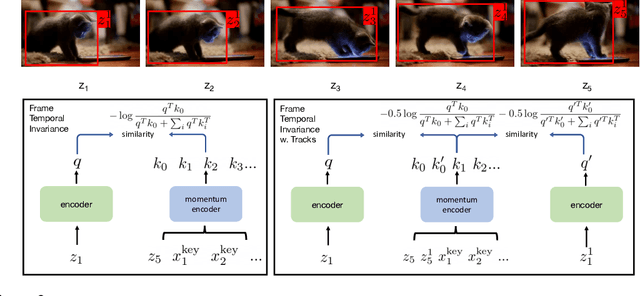
Self-supervised representation learning approaches have recently surpassed their supervised learning counterparts on downstream tasks like object detection and image classification. Somewhat mysteriously the recent gains in performance come from training instance classification models, treating each image and it's augmented versions as samples of a single class. In this work, we first present quantitative experiments to demystify these gains. We demonstrate that approaches like MOCO and PIRL learn occlusion-invariant representations. However, they fail to capture viewpoint and category instance invariance which are crucial components for object recognition. Second, we demonstrate that these approaches obtain further gains from access to a clean object-centric training dataset like Imagenet. Finally, we propose an approach to leverage unstructured videos to learn representations that possess higher viewpoint invariance. Our results show that the learned representations outperform MOCOv2 trained on the same data in terms of invariances encoded and the performance on downstream image classification and semantic segmentation tasks.