 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Holographic Visualisation of Radiology Data and Automated Machine Learning-based Medical Image Segmentation
Aug 15, 2018

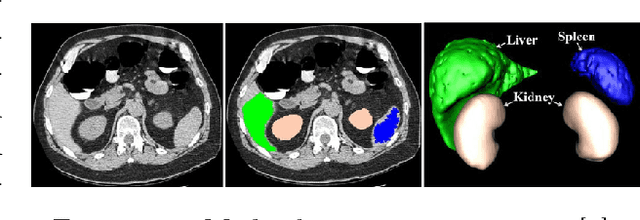
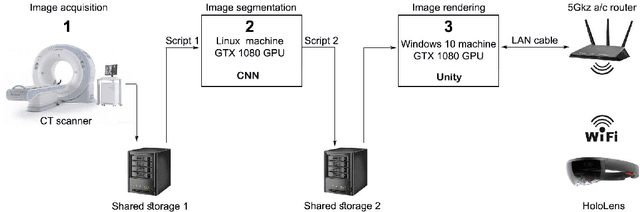
Within this thesis we propose a platform for combining Augmented Reality (AR) hardware with machine learning in a user-oriented pipeline, offering to the medical staff an intuitive 3D visualization of volumetric Computed Tomography (CT) and Magnetic Resonance Imaging (MRI) medical image segmentations inside the AR headset, that does not need human intervention for loading, processing and segmentation of medical images. The AR visualization, based on Microsoft HoloLens, employs a modular and thus scalable frontend-backend architecture for real-time visualizations on multiple AR headsets. As Convolutional Neural Networks (CNNs) have lastly demonstrated superior performance for the machine learning task of image semantic segmentation, the pipeline also includes a fully automated CNN algorithm for the segmentation of the liver from CT scans. The model is based on the Deep Retinal Image Understanding (DRIU) model which is a Fully Convolutional Network with side outputs from feature maps with different resolution, extracted at different stages of the network. The algorithm is 2.5D which means that the input is a set of consecutive scan slices. The experiments have been performed on the Liver Tumor Segmentation Challenge (LiTS) dataset for liver segmentation and demonstrated good results and flexibility. While multiple approaches exist in the domain, only few of them have focused on overcoming the practical aspects which still largely hold this technology away from the operating rooms. In line with this, we also are next planning an evaluation from medical doctors and radiologists in a real-world environment.
BMART-Enabled Field-Map Combination of Projection-Reconstruction Phase-Cycled SSFP Cardiac Cine for Banding and Flow-Artifact Reduction
Feb 23, 2021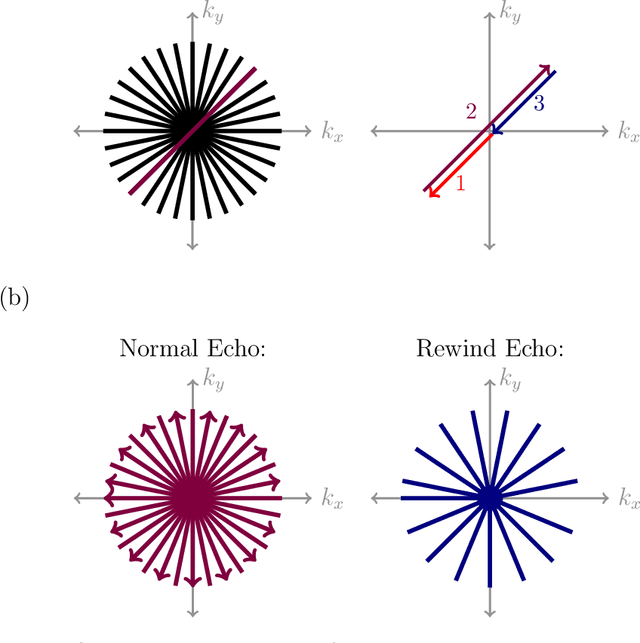
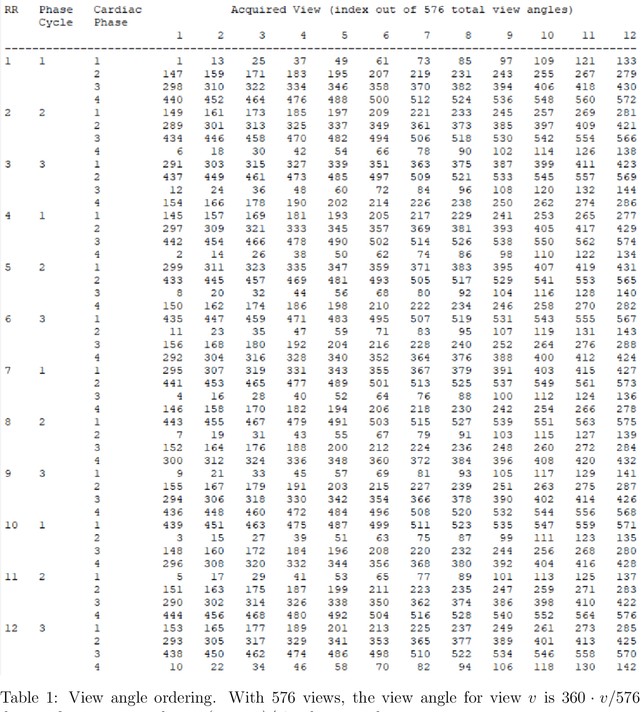
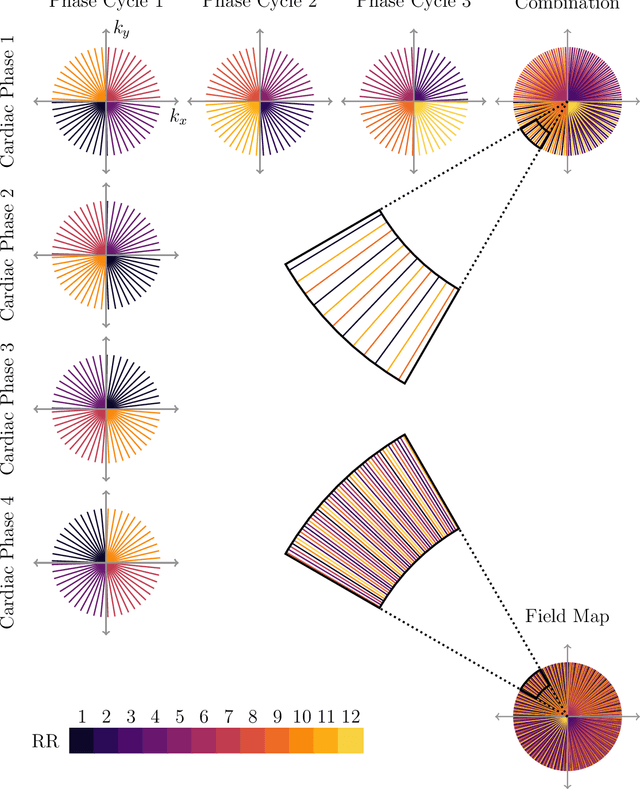
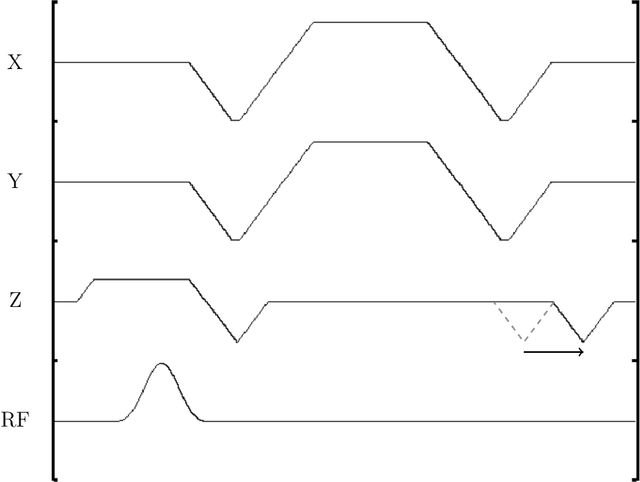
Purpose: To develop a method for banding-free bSSFP cardiac cine with substantially reduced flow artifacts. Methods: A projection-reconstruction (PR) trajectory is proposed for a frequency-modulated cine sequence, facilitating reconstruction of three phase cycles and a field-map time series from a short, breath-held scan. Data is also acquired during the gradient rewinders to enable generation of field maps using BMART, B$_0$ mapping using rewinding trajectories, where the rewind data forms the second TE image for calculating the field map. A field-map-based combination method is developed which weights the phase-cycle component images to include only passband signal in the final cine images, and exclude stopband and near-band flow artifacts. Results: The weights derived from the BMART-generated field maps mask out banding and near-band flow artifacts in and around the heart. Therefore, the field-map-based phase-cycle combination, which is facilitated by the PR acquisition with BMART, results in more homogeneous blood pools and reduced hyperintense regions than root-sum-of-squares. Conclusion: With the proposed techniques, using a non-Cartesian trajectory for a frequency-modulated cine sequence enables flow-artifact-reduced banding-free cardiac imaging within a short breath-hold.
Regularization Strategy for Point Cloud via Rigidly Mixed Sample
Feb 03, 2021

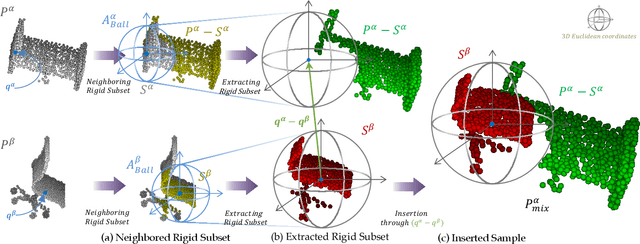
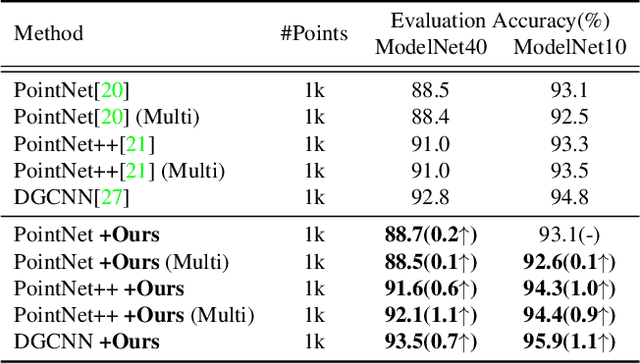
Data augmentation is an effective regularization strategy to alleviate the overfitting, which is an inherent drawback of the deep neural networks. However, data augmentation is rarely considered for point cloud processing despite many studies proposing various augmentation methods for image data. Actually, regularization is essential for point clouds since lack of generality is more likely to occur in point cloud due to small datasets. This paper proposes a Rigid Subset Mix (RSMix), a novel data augmentation method for point clouds that generates a virtual mixed sample by replacing part of the sample with shape-preserved subsets from another sample. RSMix preserves structural information of the point cloud sample by extracting subsets from each sample without deformation using a neighboring function. The neighboring function was carefully designed considering unique properties of point cloud, unordered structure and non-grid. Experiments verified that RSMix successfully regularized the deep neural networks with remarkable improvement for shape classification. We also analyzed various combinations of data augmentations including RSMix with single and multi-view evaluations, based on abundant ablation studies.
GPR-based Model Reconstruction System for Underground Utilities Using GPRNet
Nov 05, 2020
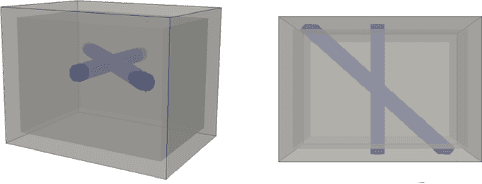
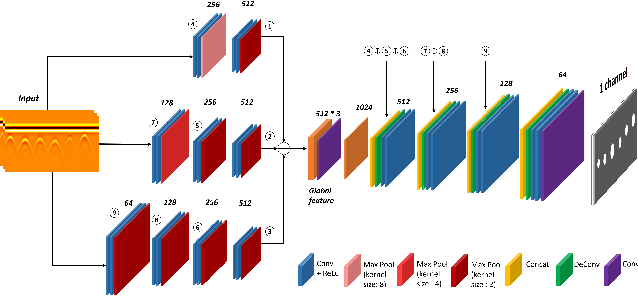
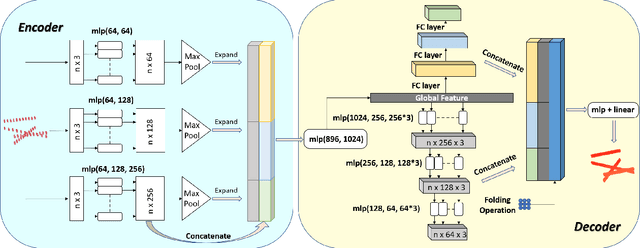
Ground Penetrating Radar (GPR) is one of the most important non-destructive evaluation (NDE) instruments to detect and locate underground objects (i.e. rebars, utility pipes). Many of the previous researches focus on GPR image-based feature detection only, and none can process sparse GPR measurements to successfully reconstruct a very fine and detailed 3D model of underground objects for better visualization. To address this problem, this paper presents a novel robotic system to collect GPR data, localize the underground utilities, and reconstruct the underground objects' dense point cloud model. This system is composed of three modules: 1) visual-inertial-based GPR data collection module which tags the GPR measurements with positioning information provided by an omnidirectional robot; 2) a deep neural network (DNN) migration module to interpret the raw GPR B-scan image into a cross-section of object model; 3) a DNN-based 3D reconstruction module, i.e., GPRNet, to generate underground utility model with the fine 3D point cloud. The experiments show that our method can generate a dense and complete point cloud model of pipe-shaped utilities based on a sparse input, i.e., GPR raw data, with various levels of incompleteness and noise. The experiment results on synthetic data as well as field test data verified the effectiveness of our method.
Expressway visibility estimation based on image entropy and piecewise stationary time series analysis
Apr 08, 2018



Vision-based methods for visibility estimation can play a critical role in reducing traffic accidents caused by fog and haze. To overcome the disadvantages of current visibility estimation methods, we present a novel data-driven approach based on Gaussian image entropy and piecewise stationary time series analysis (SPEV). This is the first time that Gaussian image entropy is used for estimating atmospheric visibility. To lessen the impact of landscape and sunshine illuminance on visibility estimation, we used region of interest (ROI) analysis and took into account relative ratios of image entropy, to improve estimation accuracy. We assume fog and haze cause blurred images and that fog and haze can be considered as a piecewise stationary signal. We used piecewise stationary time series analysis to construct the piecewise causal relationship between image entropy and visibility. To obtain a real-world visibility measure during fog and haze, a subjective assessment was established through a study with 36 subjects who performed visibility observations. Finally, a total of two million videos were used for training the SPEV model and validate its effectiveness. The videos were collected from the constantly foggy and hazy Tongqi expressway in Jiangsu, China. The contrast model of visibility estimation was used for algorithm performance comparison, and the validation results of the SPEV model were encouraging as 99.14% of the relative errors were less than 10%.
Context Aware 3D UNet for Brain Tumor Segmentation
Oct 25, 2020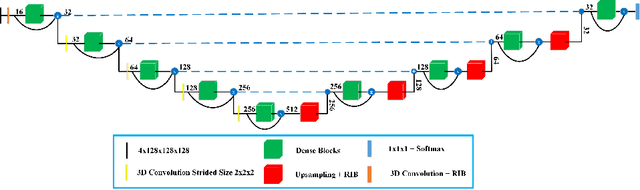
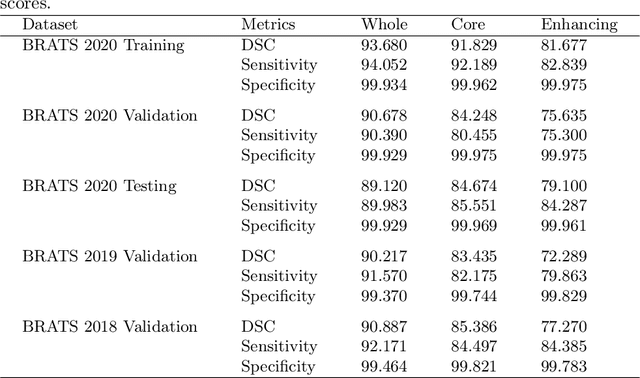
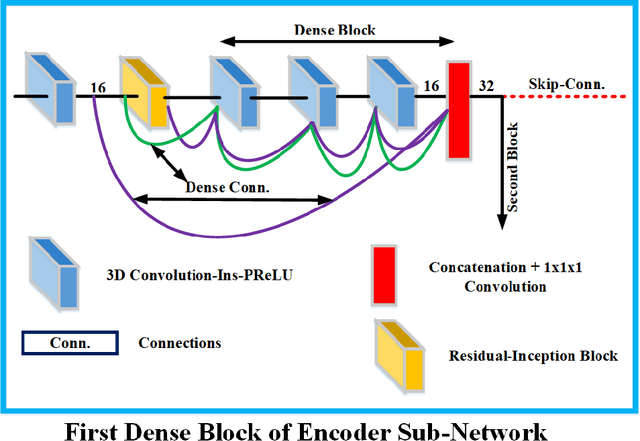

Deep convolutional neural network (CNN) achieves remarkable performance for medical image analysis. UNet is the primary source in the performance of 3D CNN architectures for medical imaging tasks, including brain tumor segmentation. The skip connection in the UNet architecture concatenates features from both encoder and decoder paths to extract multi-contexual information from image data. The multi-scaled features play an essential role in brain tumor segmentation. However, the limited use of features can degrade the performance of the UNet approach for segmentation. In this paper, we propose a modified UNet architecture for brain tumor segmentation. In the proposed architecture, we used densely connected blocks in both encoder and decoder paths to extract multi-contexual information from the concept of feature reusability. The proposed residual inception blocks (RIB) are used to extract local and global information by merging features of different kernel sizes. We validate the proposed architecture on the multimodal brain tumor segmentation challenges (BRATS) 2020 testing dataset. The dice (DSC) scores of the whole tumor (WT), tumor core (TC), and enhancement tumor (ET) are 89.12%, 84.74%, and 79.12%, respectively. Our proposed work is in the top ten methods based on the dice scores of the testing dataset.
Prediction of neonatal mortality in Sub-Saharan African countries using data-level linkage of multiple surveys
Nov 25, 2020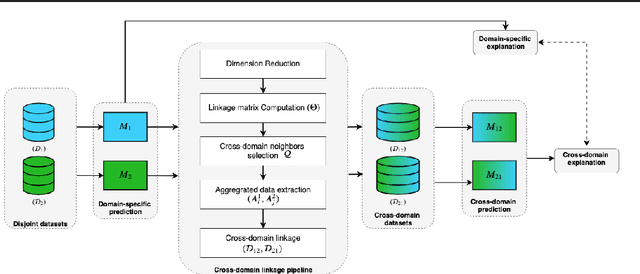
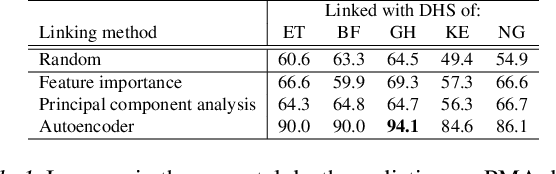
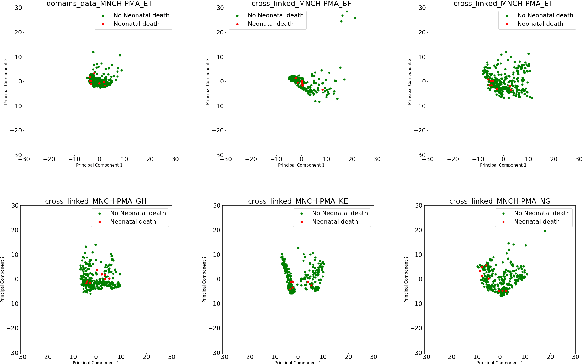
Existing datasets available to address crucial problems, such as child mortality and family planning discontinuation in developing countries, are not ample for data-driven approaches. This is partly due to disjoint data collection efforts employed across locations, times, and variations of modalities. On the other hand, state-of-the-art methods for small data problem are confined to image modalities. In this work, we proposed a data-level linkage of disjoint surveys across Sub-Saharan African countries to improve prediction performance of neonatal death and provide cross-domain explainability.
Multi-Focus Image Fusion Via Coupled Sparse Representation and Dictionary Learning
May 30, 2017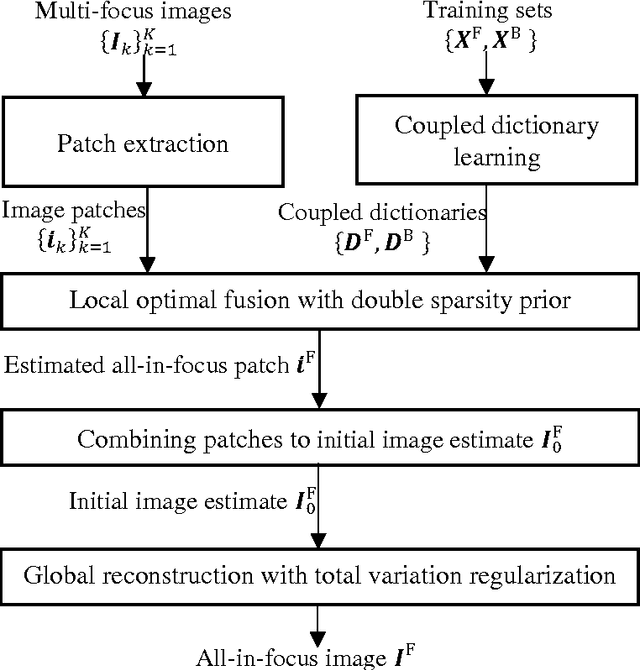


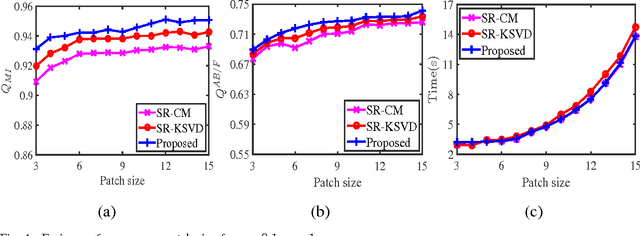
We address the multi-focus image fusion problem, where multiple images captured with different focal settings are to be fused into an all-in-focus image of higher quality. Algorithms for this problem necessarily admit the source image characteristics along with focused and blurred feature. However, most sparsity-based approaches use a single dictionary in focused feature space to describe multi-focus images, and ignore the representations in blurred feature space. Here, we propose a multi-focus image fusion approach based on coupled sparse representation. The approach exploits the facts that (i) the patches in given training set can be sparsely represented by a couple of overcomplete dictionaries related to the focused and blurred categories of images; and (ii) merging such representations leads to a more flexible and therefore better fusion strategy than the one based on just selecting the sparsest representation in the original image estimate. By jointly learning the coupled dictionary, we enforce the similarity of sparse representations in the focused and blurred feature spaces, and then introduce a fusion approach to combine these representations for generating an all-in-focus image. We also discuss the advantages of the fusion approach based on coupled sparse representation and present an efficient algorithm for learning the coupled dictionary. Extensive experimental comparisons with state-of-the-art multi-focus image fusion algorithms validate the effectiveness of the proposed approach.
Predicting Visual Features from Text for Image and Video Caption Retrieval
Jul 14, 2018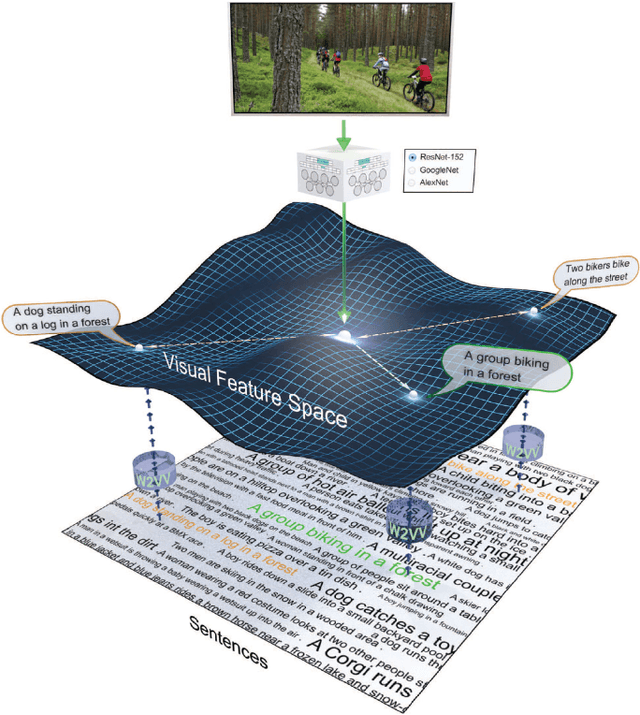

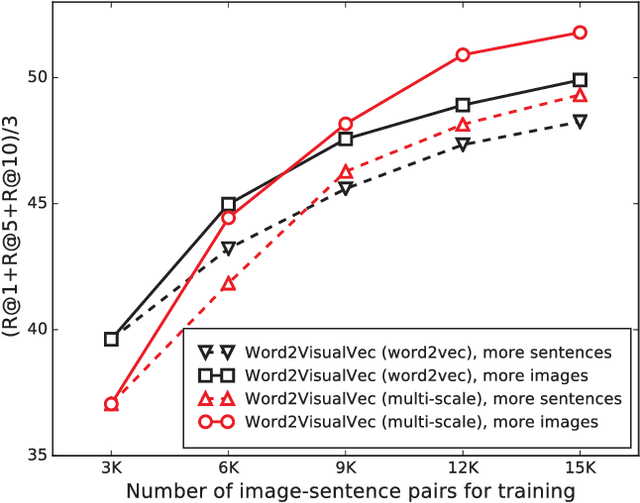
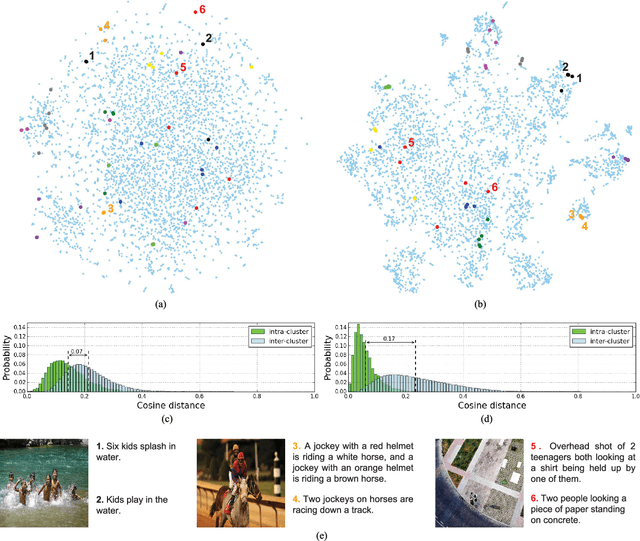
This paper strives to find amidst a set of sentences the one best describing the content of a given image or video. Different from existing works, which rely on a joint subspace for their image and video caption retrieval, we propose to do so in a visual space exclusively. Apart from this conceptual novelty, we contribute \emph{Word2VisualVec}, a deep neural network architecture that learns to predict a visual feature representation from textual input. Example captions are encoded into a textual embedding based on multi-scale sentence vectorization and further transferred into a deep visual feature of choice via a simple multi-layer perceptron. We further generalize Word2VisualVec for video caption retrieval, by predicting from text both 3-D convolutional neural network features as well as a visual-audio representation. Experiments on Flickr8k, Flickr30k, the Microsoft Video Description dataset and the very recent NIST TrecVid challenge for video caption retrieval detail Word2VisualVec's properties, its benefit over textual embeddings, the potential for multimodal query composition and its state-of-the-art results.
Deep Bi-Dense Networks for Image Super-Resolution
Oct 11, 2018
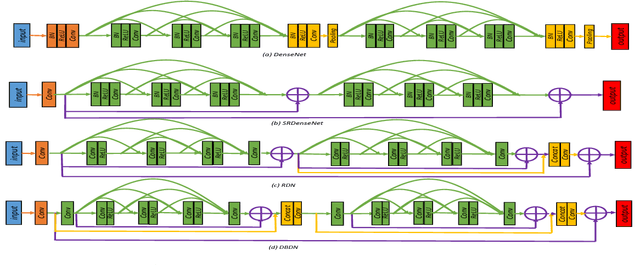
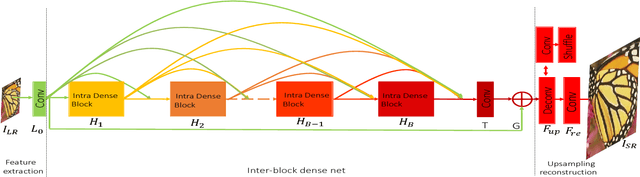
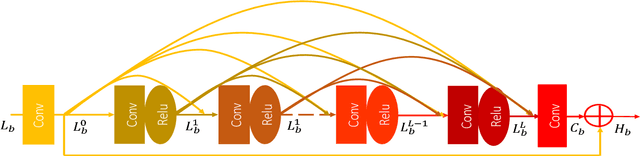
This paper proposes Deep Bi-Dense Networks (DBDN) for single image super-resolution. Our approach extends previous intra-block dense connection approaches by including novel inter-block dense connections. In this way, feature information propagates from a single dense block to all subsequent blocks, instead of to a single successor. To build a DBDN, we firstly construct intra-dense blocks, which extract and compress abundant local features via densely connected convolutional layers and compression layers for further feature learning. Then, we use an inter-block dense net to connect intra-dense blocks, which allow each intra-dense block propagates its own local features to all successors. Additionally, our bi-dense construction connects each block to the output, alleviating the vanishing gradient problems in training. The evaluation of our proposed method on five benchmark datasets shows that our DBDN outperforms the state of the art in SISR with a moderate number of network parameters.