 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCKConv: Learning Feature Voxelization for Point Cloud Analysis
Jul 27, 2021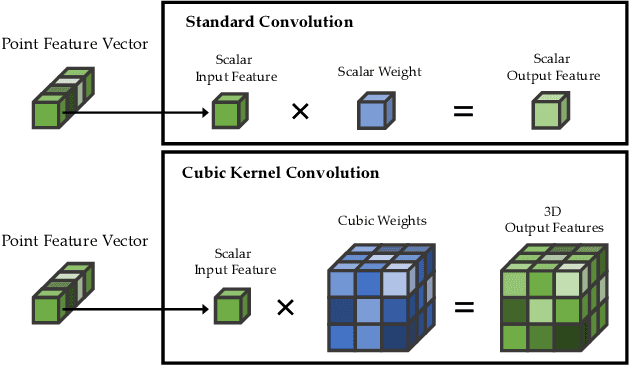
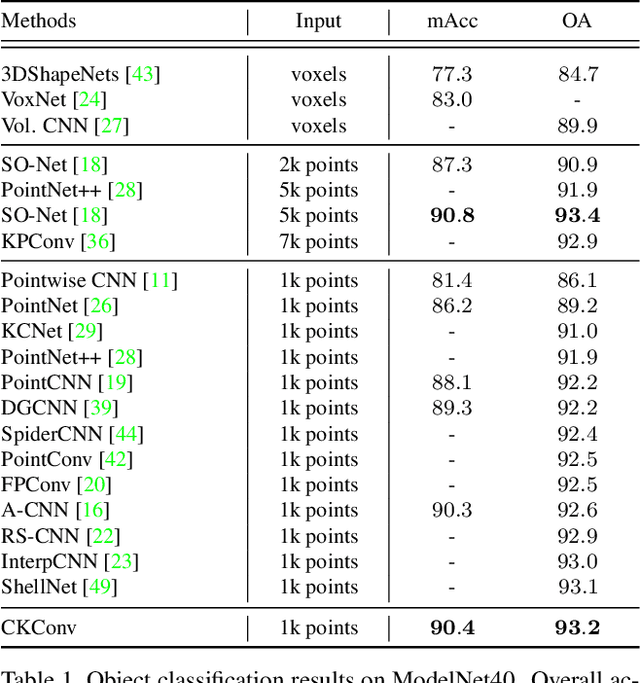
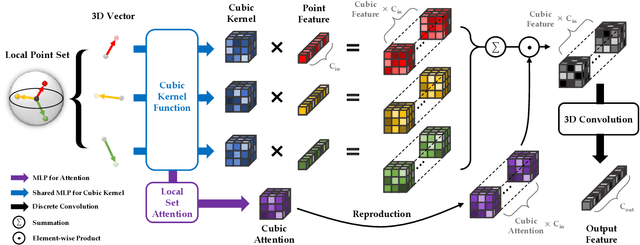
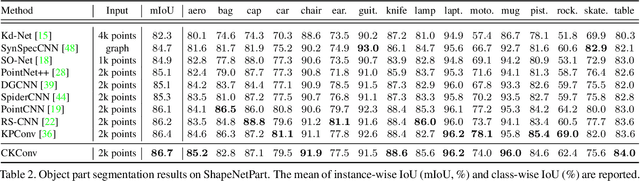
Despite the remarkable success of deep learning, optimal convolution operation on point cloud remains indefinite due to its irregular data structure. In this paper, we present Cubic Kernel Convolution (CKConv) that learns to voxelize the features of local points by exploiting both continuous and discrete convolutions. Our continuous convolution uniquely employs a 3D cubic form of kernel weight representation that splits a feature into voxels in embedding space. By consecutively applying discrete 3D convolutions on the voxelized features in a spatial manner, preceding continuous convolution is forced to learn spatial feature mapping, i.e., feature voxelization. In this way, geometric information can be detailed by encoding with subdivided features, and our 3D convolutions on these fixed structured data do not suffer from discretization artifacts thanks to voxelization in embedding space. Furthermore, we propose a spatial attention module, Local Set Attention (LSA), to provide comprehensive structure awareness within the local point set and hence produce representative features. By learning feature voxelization with LSA, CKConv can extract enriched features for effective point cloud analysis. We show that CKConv has great applicability to point cloud processing tasks including object classification, object part segmentation, and scene semantic segmentation with state-of-the-art results.
Robust Lane Detection via Expanded Self Attention
Feb 14, 2021
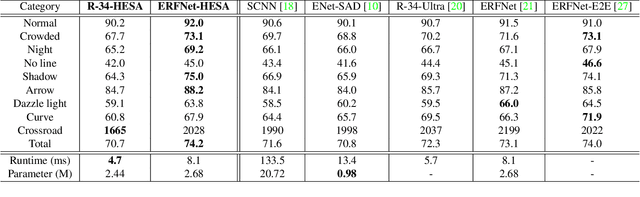
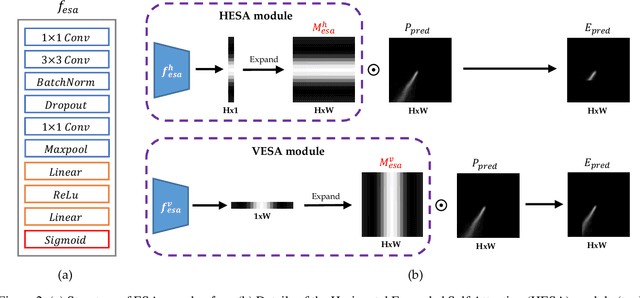
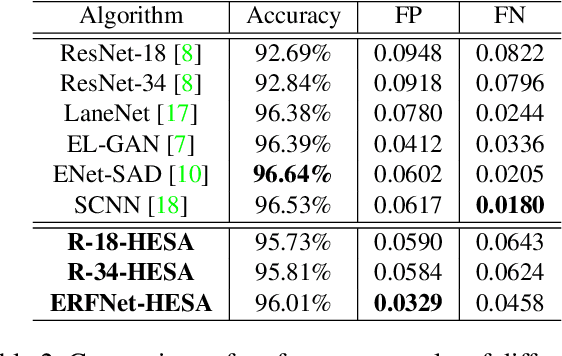
The image-based lane detection algorithm is one of the key technologies in autonomous vehicles. Modern deep learning methods achieve high performance in lane detection, but it is still difficult to accurately detect lanes in challenging situations such as congested roads and extreme lighting conditions. To be robust on these challenging situations, it is important to extract global contextual information even from limited visual cues. In this paper, we propose a simple but powerful self-attention mechanism optimized for lane detection called the Expanded Self Attention (ESA) module. Inspired by the simple geometric structure of lanes, the proposed method predicts the confidence of a lane along the vertical and horizontal directions in an image. The prediction of the confidence enables estimating occluded locations by extracting global contextual information. ESA module can be easily implemented and applied to any encoder-decoder-based model without increasing the inference time. The performance of our method is evaluated on three popular lane detection benchmarks (TuSimple, CULane and BDD100K). We achieve state-of-the-art performance in CULane and BDD100K and distinct improvement on TuSimple dataset. The experimental results show that our approach is robust to occlusion and extreme lighting conditions.
Regularization Strategy for Point Cloud via Rigidly Mixed Sample
Feb 03, 2021

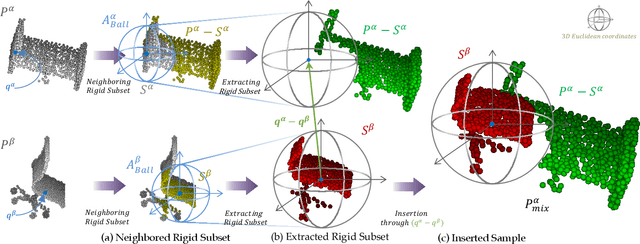
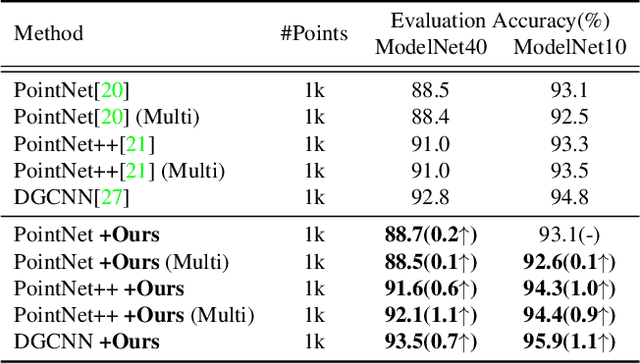
Data augmentation is an effective regularization strategy to alleviate the overfitting, which is an inherent drawback of the deep neural networks. However, data augmentation is rarely considered for point cloud processing despite many studies proposing various augmentation methods for image data. Actually, regularization is essential for point clouds since lack of generality is more likely to occur in point cloud due to small datasets. This paper proposes a Rigid Subset Mix (RSMix), a novel data augmentation method for point clouds that generates a virtual mixed sample by replacing part of the sample with shape-preserved subsets from another sample. RSMix preserves structural information of the point cloud sample by extracting subsets from each sample without deformation using a neighboring function. The neighboring function was carefully designed considering unique properties of point cloud, unordered structure and non-grid. Experiments verified that RSMix successfully regularized the deep neural networks with remarkable improvement for shape classification. We also analyzed various combinations of data augmentations including RSMix with single and multi-view evaluations, based on abundant ablation studies.
False Positive Removal for 3D Vehicle Detection with Penetrated Point Classifier
May 28, 2020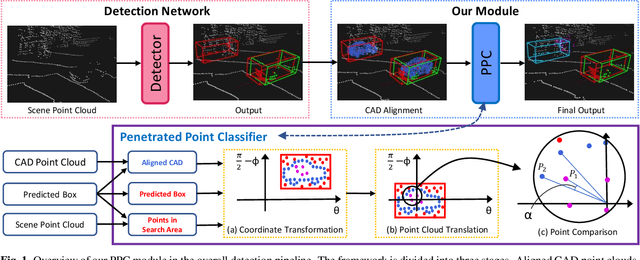

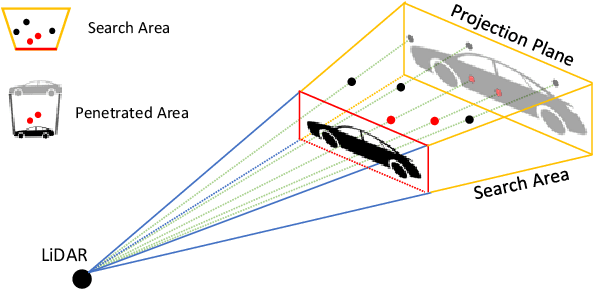
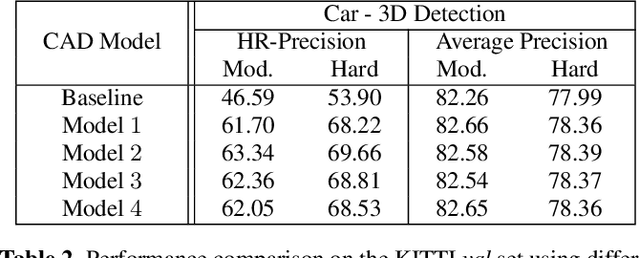
Recently, researchers have been leveraging LiDAR point cloud for higher accuracy in 3D vehicle detection. Most state-of-the-art methods are deep learning based, but are easily affected by the number of points generated on the object. This vulnerability leads to numerous false positive boxes at high recall positions, where objects are occasionally predicted with few points. To address the issue, we introduce Penetrated Point Classifier (PPC) based on the underlying property of LiDAR that points cannot be generated behind vehicles. It determines whether a point exists behind the vehicle of the predicted box, and if does, the box is distinguished as false positive. Our straightforward yet unprecedented approach is evaluated on KITTI dataset and achieved performance improvement of PointRCNN, one of the state-of-the-art methods. The experiment results show that precision at the highest recall position is dramatically increased by 15.46 percentage points and 14.63 percentage points on the moderate and hard difficulty of car class, respectively.
AD-VO: Scale-Resilient Visual Odometry Using Attentive Disparity Map
Jan 07, 2020

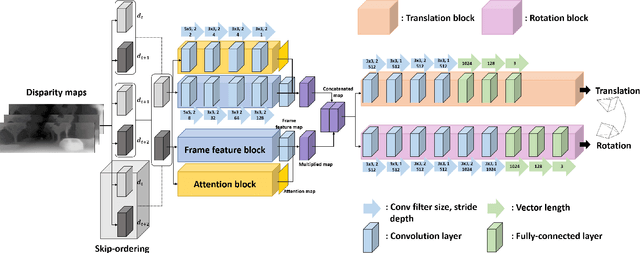
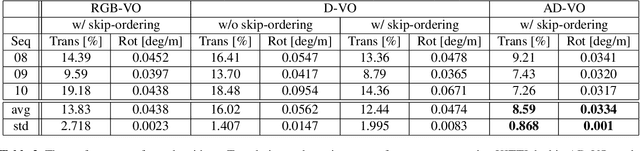
Visual odometry is an essential key for a localization module in SLAM systems. However, previous methods require tuning the system to adapt environment changes. In this paper, we propose a learning-based approach for frame-to-frame monocular visual odometry estimation. The proposed network is only learned by disparity maps for not only covering the environment changes but also solving the scale problem. Furthermore, attention block and skip-ordering scheme are introduced to achieve robust performance in various driving environment. Our network is compared with the conventional methods which use common domain such as color or optical flow. Experimental results confirm that the proposed network shows better performance than other approaches with higher and more stable results.