 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoRGS: Efficient Per-Gaussian Motion Reasoning for Streamable Dynamic 3D Scenes
Mar 26, 2026Online reconstruction of dynamic scenes aims to learn from streaming multi-view inputs under low-latency constraints. The fast training and real-time rendering capabilities of 3D Gaussian Splatting have made on-the-fly reconstruction practically feasible, enabling online 4D reconstruction. However, existing online approaches, despite their efficiency and visual quality, fail to learn per-Gaussian motion that reflects true scene dynamics. Without explicit motion cues, appearance and motion are optimized solely under photometric loss, causing per-Gaussian motion to chase pixel residuals rather than true 3D motion. To address this, we propose MoRGS, an efficient online per-Gaussian motion reasoning framework that explicitly models per-Gaussian motion to improve 4D reconstruction quality. Specifically, we leverage optical flow on a sparse set of key views as lightweight motion cues that regularize per-Gaussian motion beyond photometric supervision. To compensate for the sparsity of flow supervision, we learn a per-Gaussian motion offset field that reconciles discrepancies between projected 3D motion and observed flow across views and time. In addition, we introduce a per-Gaussian motion confidence that separates dynamic from static Gaussians and weights Gaussian attribute residual updates, thereby suppressing redundant motion in static regions for better temporal consistency and accelerating the modeling of large motions. Extensive experiments demonstrate that MoRGS achieves state-of-the-art reconstruction quality and motion fidelity among online methods, while maintaining streamable performance.
Revisiting Weakly-Supervised Video Scene Graph Generation via Pair Affinity Learning
Mar 23, 2026Weakly-supervised video scene graph generation (WS-VSGG) aims to parse video content into structured relational triplets without bounding box annotations and with only sparse temporal labeling, significantly reducing annotation costs. Without ground-truth bounding boxes, these methods rely on off-the-shelf detectors to generate object proposals, yet largely overlook a fundamental discrepancy from fullysupervised pipelines. Fully-supervised detectors implicitly filter out noninteractive objects, while off-the-shelf detectors indiscriminately detect all visible objects, overwhelming relation models with noisy pairs.We address this by introducing a learnable pair affinity that estimates the likelihood of interaction between subject-object pairs. Through Pair Affinity Learning and Scoring (PALS), pair affinity is incorporated into inferencetime ranking and further integrated into contextual reasoning through Pair Affinity Modulation (PAM), enabling the model to suppress noninteractive pairs and focus on relationally meaningful ones. To provide cleaner supervision for pair affinity learning, we further propose Relation- Aware Matching (RAM), which leverages vision-language grounding to resolve class-level ambiguity in pseudo-label generation. Extensive experiments on Action Genome demonstrate that our approach consistently yields substantial improvements across different baselines and backbones, achieving state-of-the-art WS-VSGG performance.
DualFocus: Depth from Focus with Spatio-Focal Dual Variational Constraints
Sep 26, 2025Depth-from-Focus (DFF) enables precise depth estimation by analyzing focus cues across a stack of images captured at varying focal lengths. While recent learning-based approaches have advanced this field, they often struggle in complex scenes with fine textures or abrupt depth changes, where focus cues may become ambiguous or misleading. We present DualFocus, a novel DFF framework that leverages the focal stack's unique gradient patterns induced by focus variation, jointly modeling focus changes over spatial and focal dimensions. Our approach introduces a variational formulation with dual constraints tailored to DFF: spatial constraints exploit gradient pattern changes across focus levels to distinguish true depth edges from texture artifacts, while focal constraints enforce unimodal, monotonic focus probabilities aligned with physical focus behavior. These inductive biases improve robustness and accuracy in challenging regions. Comprehensive experiments on four public datasets demonstrate that DualFocus consistently outperforms state-of-the-art methods in both depth accuracy and perceptual quality.
ProDepth: Boosting Self-Supervised Multi-Frame Monocular Depth with Probabilistic Fusion
Jul 12, 2024



Self-supervised multi-frame monocular depth estimation relies on the geometric consistency between successive frames under the assumption of a static scene. However, the presence of moving objects in dynamic scenes introduces inevitable inconsistencies, causing misaligned multi-frame feature matching and misleading self-supervision during training. In this paper, we propose a novel framework called ProDepth, which effectively addresses the mismatch problem caused by dynamic objects using a probabilistic approach. We initially deduce the uncertainty associated with static scene assumption by adopting an auxiliary decoder. This decoder analyzes inconsistencies embedded in the cost volume, inferring the probability of areas being dynamic. We then directly rectify the erroneous cost volume for dynamic areas through a Probabilistic Cost Volume Modulation (PCVM) module. Specifically, we derive probability distributions of depth candidates from both single-frame and multi-frame cues, modulating the cost volume by adaptively fusing those distributions based on the inferred uncertainty. Additionally, we present a self-supervision loss reweighting strategy that not only masks out incorrect supervision with high uncertainty but also mitigates the risks in remaining possible dynamic areas in accordance with the probability. Our proposed method excels over state-of-the-art approaches in all metrics on both Cityscapes and KITTI datasets, and demonstrates superior generalization ability on the Waymo Open dataset.
FIMP: Future Interaction Modeling for Multi-Agent Motion Prediction
Jan 29, 2024



Multi-agent motion prediction is a crucial concern in autonomous driving, yet it remains a challenge owing to the ambiguous intentions of dynamic agents and their intricate interactions. Existing studies have attempted to capture interactions between road entities by using the definite data in history timesteps, as future information is not available and involves high uncertainty. However, without sufficient guidance for capturing future states of interacting agents, they frequently produce unrealistic trajectory overlaps. In this work, we propose Future Interaction modeling for Motion Prediction (FIMP), which captures potential future interactions in an end-to-end manner. FIMP adopts a future decoder that implicitly extracts the potential future information in an intermediate feature-level, and identifies the interacting entity pairs through future affinity learning and top-k filtering strategy. Experiments show that our future interaction modeling improves the performance remarkably, leading to superior performance on the Argoverse motion forecasting benchmark.
Leveraging Spatio-Temporal Dependency for Skeleton-Based Action Recognition
Dec 09, 2022



Skeleton-based action recognition has attracted considerable attention due to its compact skeletal structure of the human body. Many recent methods have achieved remarkable performance using graph convolutional networks (GCNs) and convolutional neural networks (CNNs), which extract spatial and temporal features, respectively. Although spatial and temporal dependencies in the human skeleton have been explored, spatio-temporal dependency is rarely considered. In this paper, we propose the Inter-Frame Curve Network (IFC-Net) to effectively leverage the spatio-temporal dependency of the human skeleton. Our proposed network consists of two novel elements: 1) The Inter-Frame Curve (IFC) module; and 2) Dilated Graph Convolution (D-GC). The IFC module increases the spatio-temporal receptive field by identifying meaningful node connections between every adjacent frame and generating spatio-temporal curves based on the identified node connections. The D-GC allows the network to have a large spatial receptive field, which specifically focuses on the spatial domain. The kernels of D-GC are computed from the given adjacency matrices of the graph and reflect large receptive field in a way similar to the dilated CNNs. Our IFC-Net combines these two modules and achieves state-of-the-art performance on three skeleton-based action recognition benchmarks: NTU-RGB+D 60, NTU-RGB+D 120, and Northwestern-UCLA.
CKConv: Learning Feature Voxelization for Point Cloud Analysis
Jul 27, 2021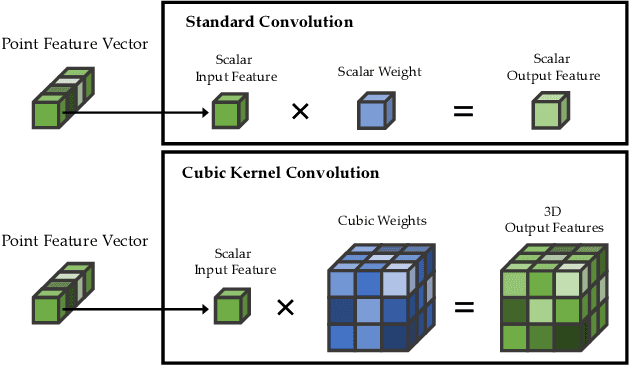
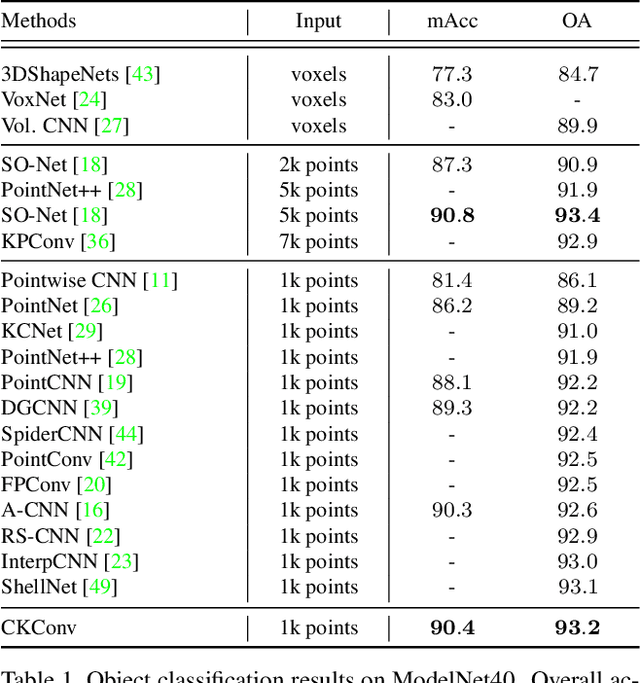
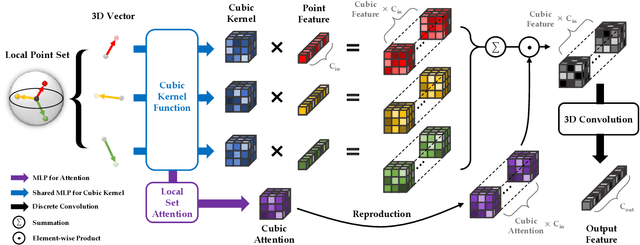
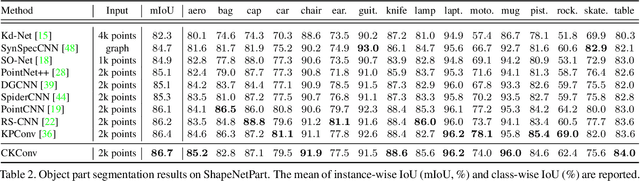
Despite the remarkable success of deep learning, optimal convolution operation on point cloud remains indefinite due to its irregular data structure. In this paper, we present Cubic Kernel Convolution (CKConv) that learns to voxelize the features of local points by exploiting both continuous and discrete convolutions. Our continuous convolution uniquely employs a 3D cubic form of kernel weight representation that splits a feature into voxels in embedding space. By consecutively applying discrete 3D convolutions on the voxelized features in a spatial manner, preceding continuous convolution is forced to learn spatial feature mapping, i.e., feature voxelization. In this way, geometric information can be detailed by encoding with subdivided features, and our 3D convolutions on these fixed structured data do not suffer from discretization artifacts thanks to voxelization in embedding space. Furthermore, we propose a spatial attention module, Local Set Attention (LSA), to provide comprehensive structure awareness within the local point set and hence produce representative features. By learning feature voxelization with LSA, CKConv can extract enriched features for effective point cloud analysis. We show that CKConv has great applicability to point cloud processing tasks including object classification, object part segmentation, and scene semantic segmentation with state-of-the-art results.
Regularization Strategy for Point Cloud via Rigidly Mixed Sample
Feb 03, 2021

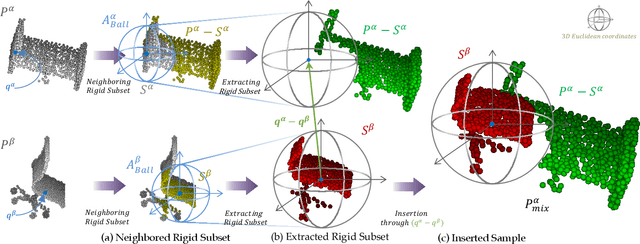
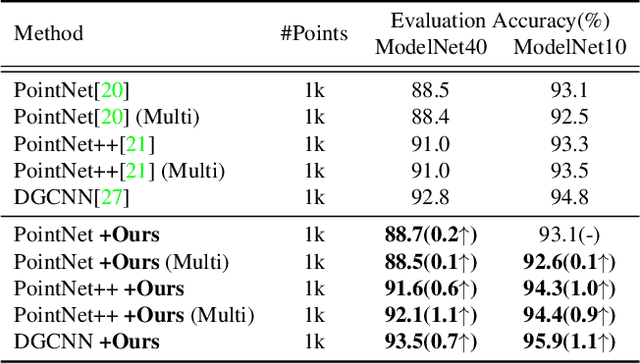
Data augmentation is an effective regularization strategy to alleviate the overfitting, which is an inherent drawback of the deep neural networks. However, data augmentation is rarely considered for point cloud processing despite many studies proposing various augmentation methods for image data. Actually, regularization is essential for point clouds since lack of generality is more likely to occur in point cloud due to small datasets. This paper proposes a Rigid Subset Mix (RSMix), a novel data augmentation method for point clouds that generates a virtual mixed sample by replacing part of the sample with shape-preserved subsets from another sample. RSMix preserves structural information of the point cloud sample by extracting subsets from each sample without deformation using a neighboring function. The neighboring function was carefully designed considering unique properties of point cloud, unordered structure and non-grid. Experiments verified that RSMix successfully regularized the deep neural networks with remarkable improvement for shape classification. We also analyzed various combinations of data augmentations including RSMix with single and multi-view evaluations, based on abundant ablation studies.
PMVOS: Pixel-Level Matching-Based Video Object Segmentation
Sep 18, 2020Semi-supervised video object segmentation (VOS) aims to segment arbitrary target objects in video when the ground truth segmentation mask of the initial frame is provided. Due to this limitation of using prior knowledge about the target object, feature matching, which compares template features representing the target object with input features, is an essential step. Recently, pixel-level matching (PM), which matches every pixel in template features and input features, has been widely used for feature matching because of its high performance. However, despite its effectiveness, the information used to build the template features is limited to the initial and previous frames. We address this issue by proposing a novel method-PM-based video object segmentation (PMVOS)-that constructs strong template features containing the information of all past frames. Furthermore, we apply self-attention to the similarity maps generated from PM to capture global dependencies. On the DAVIS 2016 validation set, we achieve new state-of-the-art performance among real-time methods (> 30 fps), with a J&F score of 85.6%. Performance on the DAVIS 2017 and YouTube-VOS validation sets is also impressive, with J&F scores of 74.0% and 68.2%, respectively.
False Positive Removal for 3D Vehicle Detection with Penetrated Point Classifier
May 28, 2020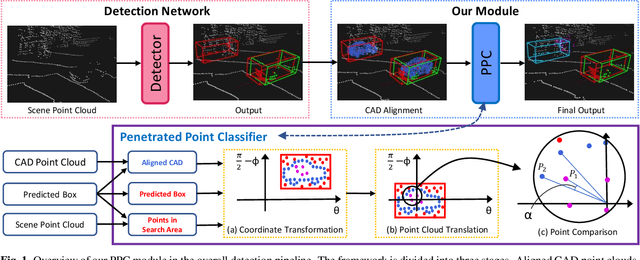

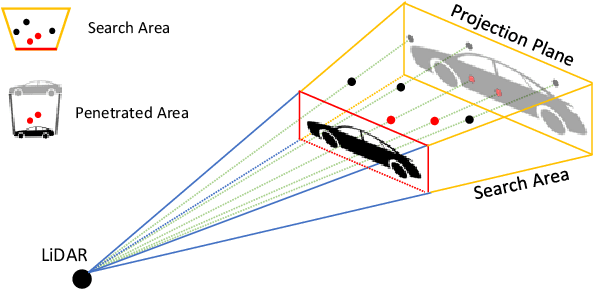
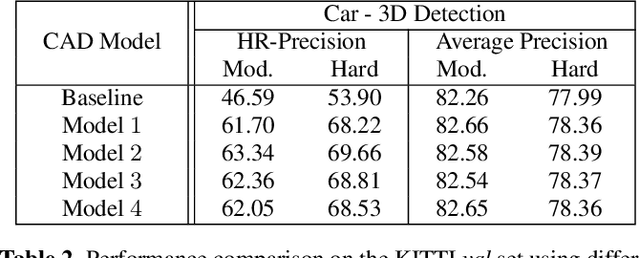
Recently, researchers have been leveraging LiDAR point cloud for higher accuracy in 3D vehicle detection. Most state-of-the-art methods are deep learning based, but are easily affected by the number of points generated on the object. This vulnerability leads to numerous false positive boxes at high recall positions, where objects are occasionally predicted with few points. To address the issue, we introduce Penetrated Point Classifier (PPC) based on the underlying property of LiDAR that points cannot be generated behind vehicles. It determines whether a point exists behind the vehicle of the predicted box, and if does, the box is distinguished as false positive. Our straightforward yet unprecedented approach is evaluated on KITTI dataset and achieved performance improvement of PointRCNN, one of the state-of-the-art methods. The experiment results show that precision at the highest recall position is dramatically increased by 15.46 percentage points and 14.63 percentage points on the moderate and hard difficulty of car class, respectively.