 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Extract a Video Sequence from a Single Motion-Blurred Image
Apr 11, 2018



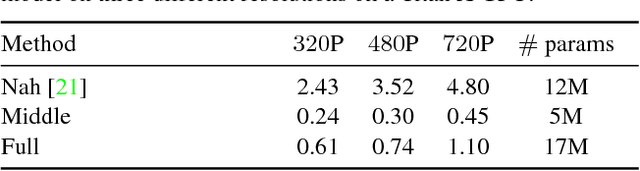
We present a method to extract a video sequence from a single motion-blurred image. Motion-blurred images are the result of an averaging process, where instant frames are accumulated over time during the exposure of the sensor. Unfortunately, reversing this process is nontrivial. Firstly, averaging destroys the temporal ordering of the frames. Secondly, the recovery of a single frame is a blind deconvolution task, which is highly ill-posed. We present a deep learning scheme that gradually reconstructs a temporal ordering by sequentially extracting pairs of frames. Our main contribution is to introduce loss functions invariant to the temporal order. This lets a neural network choose during training what frame to output among the possible combinations. We also address the ill-posedness of deblurring by designing a network with a large receptive field and implemented via resampling to achieve a higher computational efficiency. Our proposed method can successfully retrieve sharp image sequences from a single motion blurred image and can generalize well on synthetic and real datasets captured with different cameras.
A Novel Nudity Detection Algorithm for Web and Mobile Application Development
Jun 02, 2020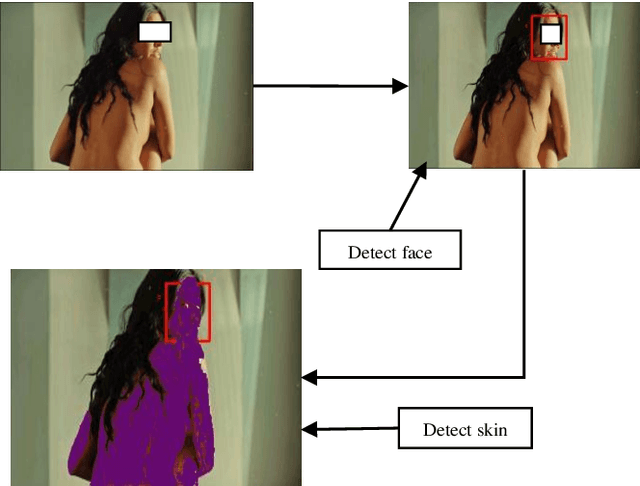



In our current web and mobile application development runtime nude image content detection is very important. This paper presents a runtime nudity detection method for web and mobile application development. We use two parameters to detect the nude content of an image. One is the number of skin pixels another is face region. A skin color model based on RGB, HSV color spaces are used to detect skin pixels in an image. Google vision api is used to detect the face region. By the percentage of skin regions and face regions an image is identified nude or not. The success of this algorithm exists in detecting skin regions and face regions. The skin detection algorithm can detect skin 95% accurately with a low false-positive rate and the google vision api for web and mobile applications can detect face 99% accurately with less than 1 second time. From the experimental analysis, we have seen that the proposed algorithm can detect 95% percent accurately the nudity of an image.
Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image
Jul 26, 2019
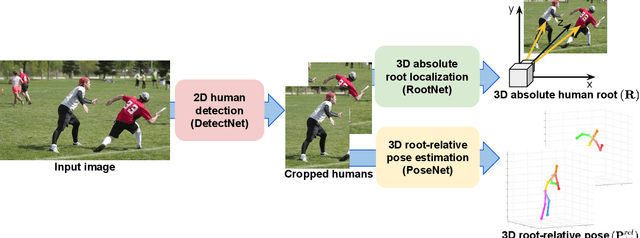
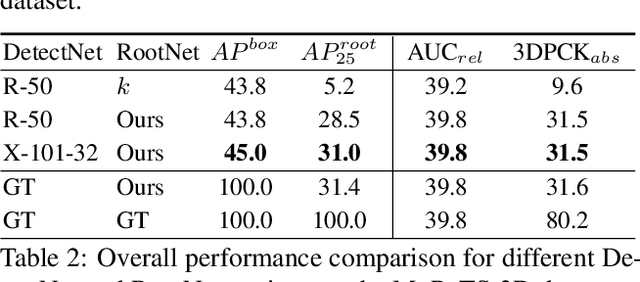
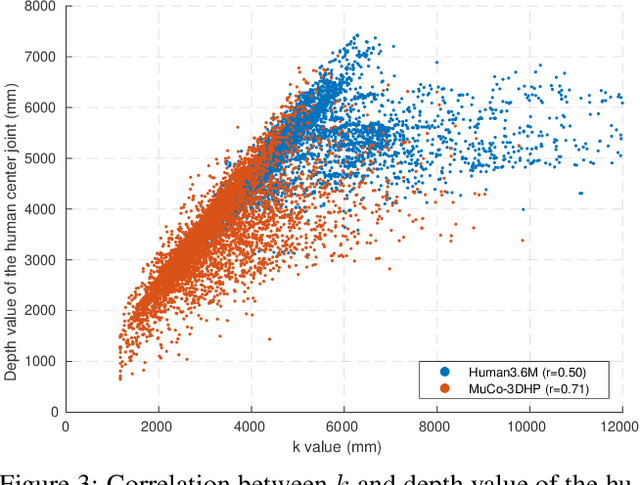
Although significant improvement has been achieved in 3D human pose estimation, most of the previous methods only consider a single-person case. In this work, we firstly propose a fully learning-based, camera distance-aware top-down approach for 3D multi-person pose estimation from a single RGB image. The pipeline of the proposed system consists of human detection, absolute 3D human root localization, and root-relative 3D single-person pose estimation models. Our system achieves comparable results with the state-of-the-art 3D single-person pose estimation models without any groundtruth information and significantly outperforms previous 3D multi-person pose estimation methods on publicly available datasets. The code is available in \footnote{\url{https://github.com/mks0601/3DMPPE_ROOTNET_RELEASE}}\footnote{\url{https://github.com/mks0601/3DMPPE_POSENET_RELEASE}}.
Do not repeat these mistakes -- a critical appraisal of applications of explainable artificial intelligence for image based COVID-19 detection
Dec 16, 2020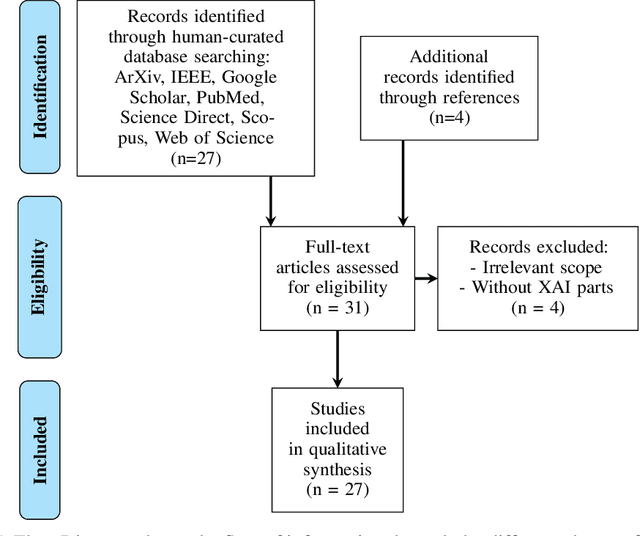
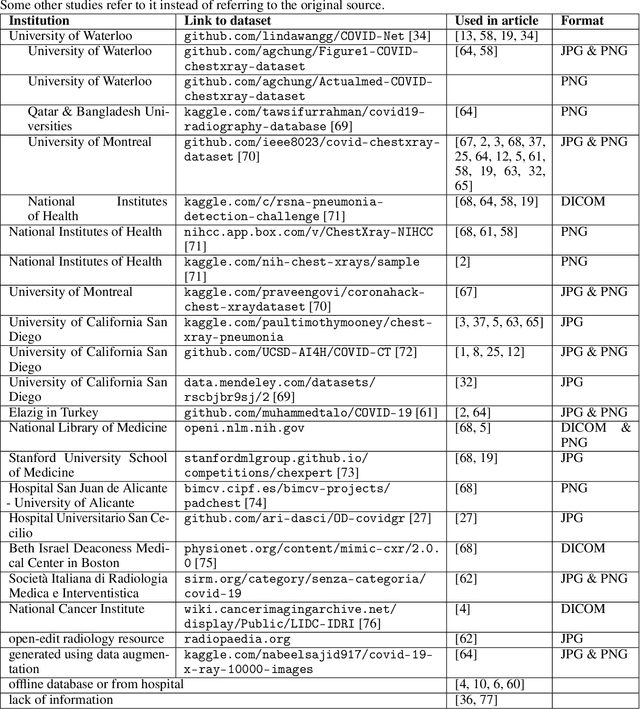
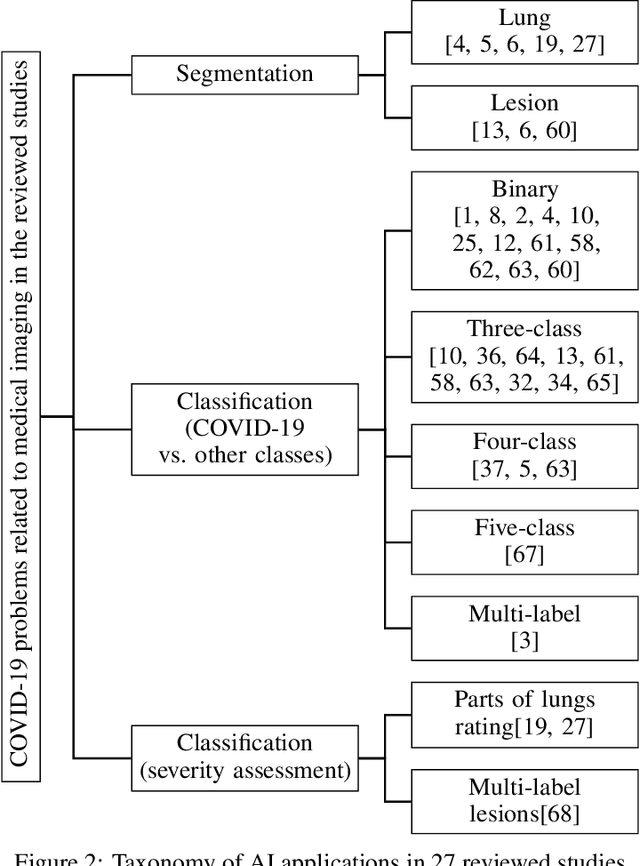
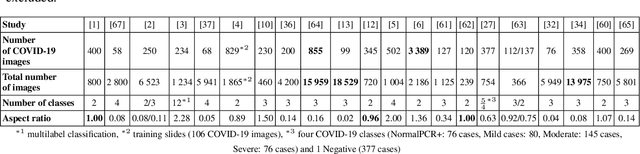
The sudden outbreak and uncontrolled spread of COVID-19 disease is one of the most important global problems today. In a short period of time, it has led to the development of many deep neural network models for COVID-19 detection with modules for explainability. In this work, we carry out a systematic analysis of various aspects of proposed models. Our analysis revealed numerous mistakes made at different stages of data acquisition, model development, and explanation construction. In this work, we overview the approaches proposed in the surveyed ML articles and indicate typical errors emerging from the lack of deep understanding of the radiography domain. We present the perspective of both: experts in the field - radiologists, and deep learning engineers dealing with model explanations. The final result is a proposed a checklist with the minimum conditions to be met by a reliable COVID-19 diagnostic model.
Body models in humans, animals, and robots
Oct 19, 2020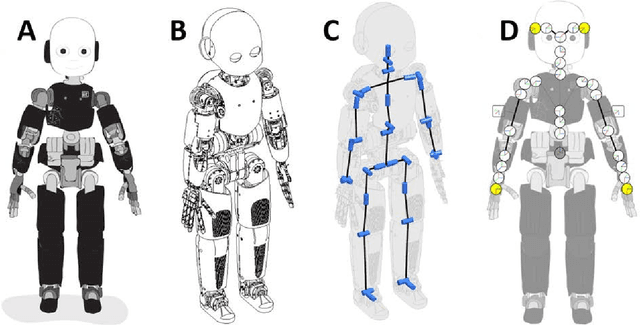

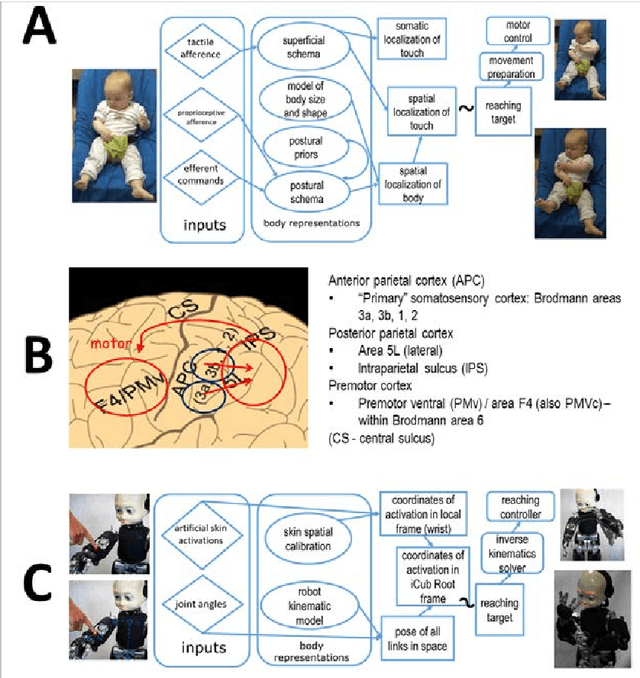
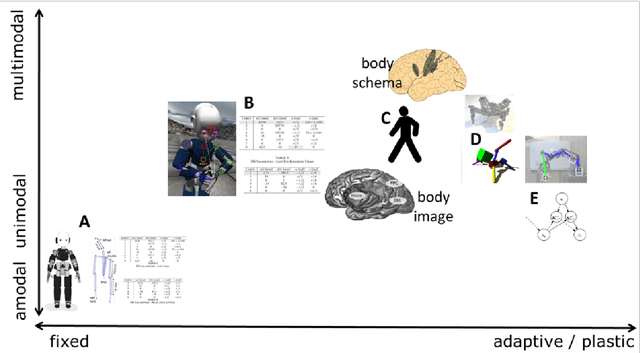
Humans and animals excel in combining information from multiple sensory modalities, controlling their complex bodies, adapting to growth, failures, or using tools. These capabilities are also highly desirable in robots. They are displayed by machines to some extent - yet, as is so often the case, the artificial creatures are lagging behind. The key foundation is an internal representation of the body that the agent - human, animal, or robot - has developed. In the biological realm, evidence has been accumulated by diverse disciplines giving rise to the concepts of body image, body schema, and others. In robotics, a model of the robot is an indispensable component that enables to control the machine. In this article I compare the character of body representations in biology with their robotic counterparts and relate that to the differences in performance that we observe. I put forth a number of axes regarding the nature of such body models: fixed vs. plastic, amodal vs. modal, explicit vs. implicit, serial vs. parallel, modular vs. holistic, and centralized vs. distributed. An interesting trend emerges: on many of the axes, there is a sequence from robot body models, over body image, body schema, to the body representation in lower animals like the octopus. In some sense, robots have a lot in common with Ian Waterman - "the man who lost his body" - in that they rely on an explicit, veridical body model (body image taken to the extreme) and lack any implicit, multimodal representation (like the body schema) of their bodies. I will then detail how robots can inform the biological sciences dealing with body representations and finally, I will study which of the features of the "body in the brain" should be transferred to robots, giving rise to more adaptive and resilient, self-calibrating machines.
Robust super-resolution depth imaging via a multi-feature fusion deep network
Nov 20, 2020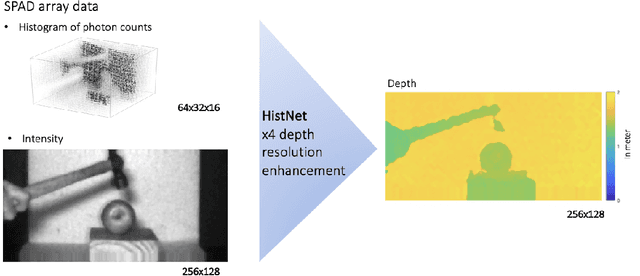
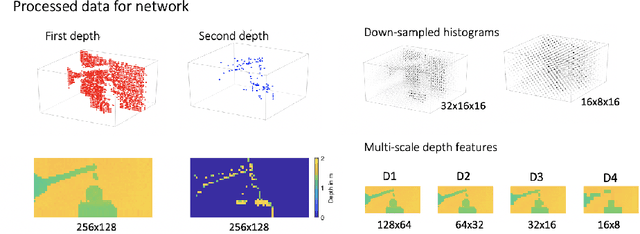
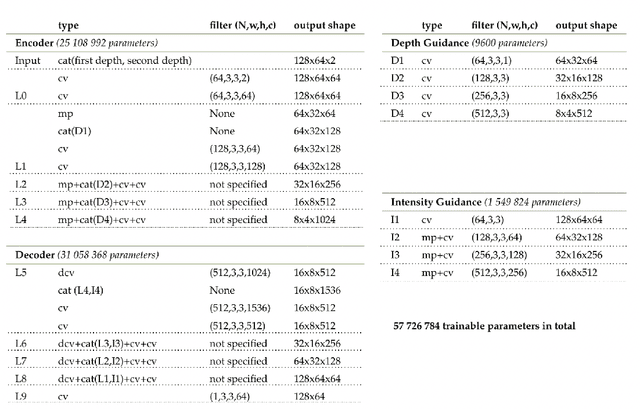
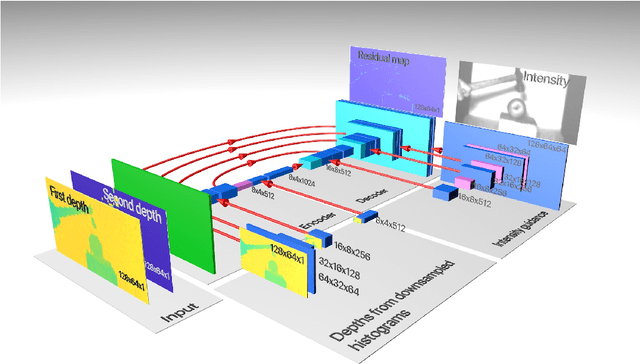
Three-dimensional imaging plays an important role in imaging applications where it is necessary to record depth. The number of applications that use depth imaging is increasing rapidly, and examples include self-driving autonomous vehicles and auto-focus assist on smartphone cameras. Light detection and ranging (LIDAR) via single-photon sensitive detector (SPAD) arrays is an emerging technology that enables the acquisition of depth images at high frame rates. However, the spatial resolution of this technology is typically low in comparison to the intensity images recorded by conventional cameras. To increase the native resolution of depth images from a SPAD camera, we develop a deep network built specifically to take advantage of the multiple features that can be extracted from a camera's histogram data. The network is designed for a SPAD camera operating in a dual-mode such that it captures alternate low resolution depth and high resolution intensity images at high frame rates, thus the system does not require any additional sensor to provide intensity images. The network then uses the intensity images and multiple features extracted from downsampled histograms to guide the upsampling of the depth. Our network provides significant image resolution enhancement and image denoising across a wide range of signal-to-noise ratios and photon levels. We apply the network to a range of 3D data, demonstrating denoising and a four-fold resolution enhancement of depth.
Weakly-Supervised Semantic Segmentation via Sub-category Exploration
Aug 03, 2020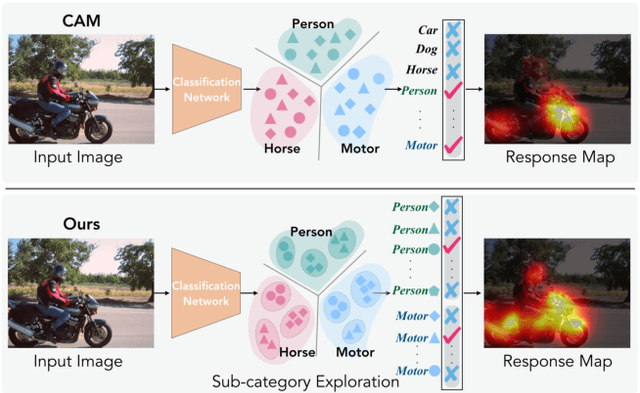
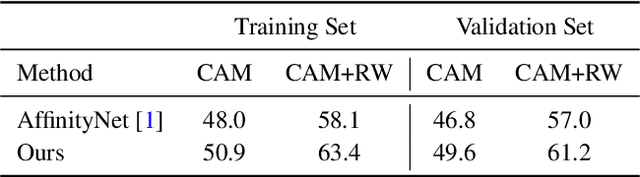
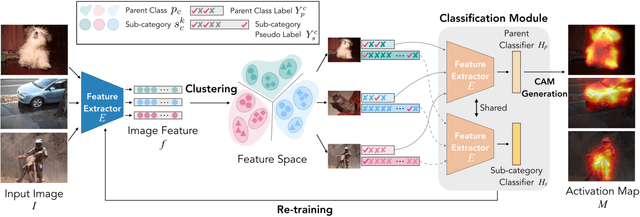
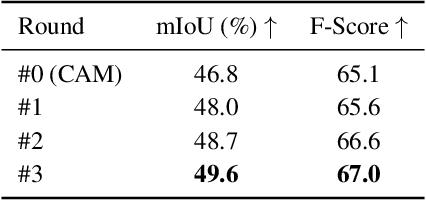
Existing weakly-supervised semantic segmentation methods using image-level annotations typically rely on initial responses to locate object regions. However, such response maps generated by the classification network usually focus on discriminative object parts, due to the fact that the network does not need the entire object for optimizing the objective function. To enforce the network to pay attention to other parts of an object, we propose a simple yet effective approach that introduces a self-supervised task by exploiting the sub-category information. Specifically, we perform clustering on image features to generate pseudo sub-categories labels within each annotated parent class, and construct a sub-category objective to assign the network to a more challenging task. By iteratively clustering image features, the training process does not limit itself to the most discriminative object parts, hence improving the quality of the response maps. We conduct extensive analysis to validate the proposed method and show that our approach performs favorably against the state-of-the-art approaches.
Exemplar-based Generative Facial Editing
May 31, 2020

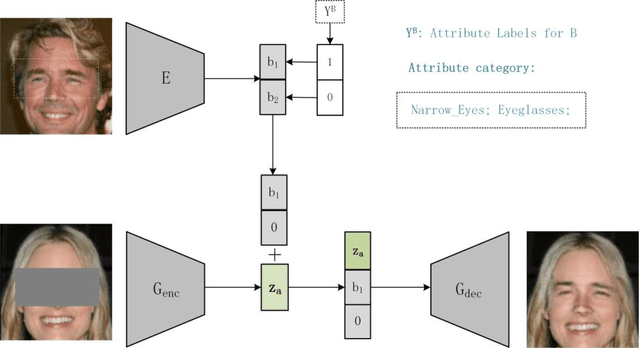

Image synthesis has witnessed substantial progress due to the increasing power of generative model. This paper we propose a novel generative approach for exemplar based facial editing in the form of the region inpainting. Our method first masks the facial editing region to eliminates the pixel constraints of the original image, then exemplar based facial editing can be achieved by learning the corresponding information from the reference image to complete the masked region. In additional, we impose the attribute labels constraint to model disentangled encodings in order to avoid undesired information being transferred from the exemplar to the original image editing region. Experimental results demonstrate our method can produce diverse and personalized face editing results and provide far more user control flexibility than nearly all existing methods.
Joint super-resolution and synthesis of 1 mm isotropic MP-RAGE volumes from clinical MRI exams with scans of different orientation, resolution and contrast
Dec 24, 2020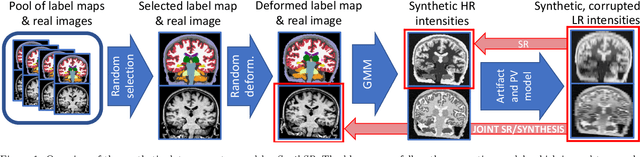

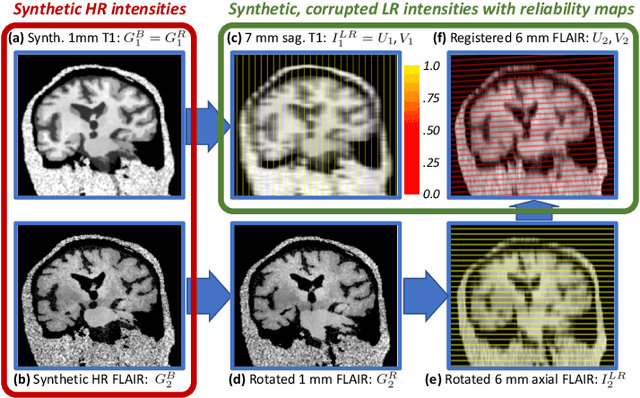
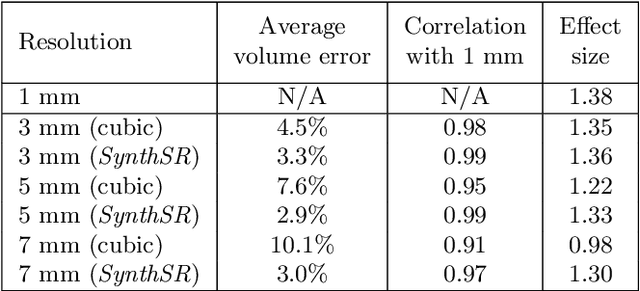
Most existing algorithms for automatic 3D morphometry of human brain MRI scans are designed for data with near-isotropic voxels at approximately 1 mm resolution, and frequently have contrast constraints as well - typically requiring T1 scans (e.g., MP-RAGE). This limitation prevents the analysis of millions of MRI scans acquired with large inter-slice spacing ("thick slice") in clinical settings every year. The inability to quantitatively analyze these scans hinders the adoption of quantitative neuroimaging in healthcare, and precludes research studies that could attain huge sample sizes and hence greatly improve our understanding of the human brain. Recent advances in CNNs are producing outstanding results in super-resolution and contrast synthesis of MRI. However, these approaches are very sensitive to the contrast, resolution and orientation of the input images, and thus do not generalize to diverse clinical acquisition protocols - even within sites. Here we present SynthSR, a method to train a CNN that receives one or more thick-slice scans with different contrast, resolution and orientation, and produces an isotropic scan of canonical contrast (typically a 1 mm MP-RAGE). The presented method does not require any preprocessing, e.g., skull stripping or bias field correction. Crucially, SynthSR trains on synthetic input images generated from 3D segmentations, and can thus be used to train CNNs for any combination of contrasts, resolutions and orientations without high-resolution training data. We test the images generated with SynthSR in an array of common downstream analyses, and show that they can be reliably used for subcortical segmentation and volumetry, image registration (e.g., for tensor-based morphometry), and, if some image quality requirements are met, even cortical thickness morphometry. The source code is publicly available at github.com/BBillot/SynthSR.
Cross-Modality Multi-Atlas Segmentation Using Deep Neural Networks
Aug 15, 2020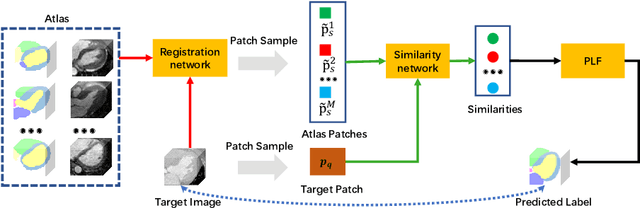
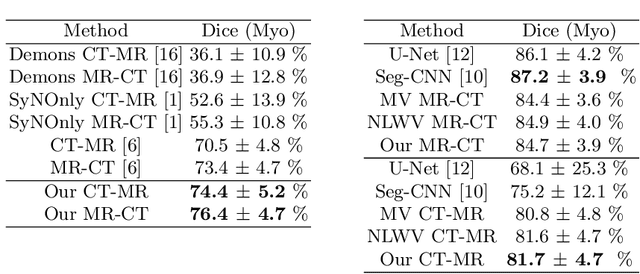
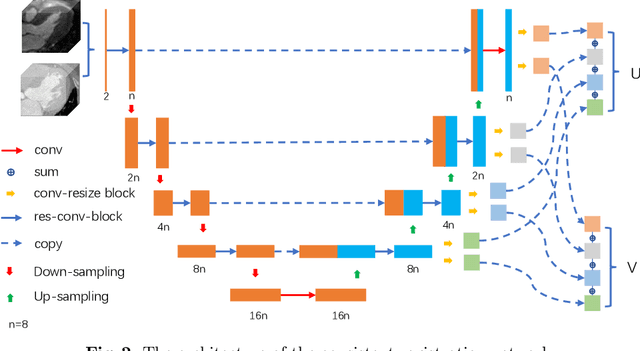
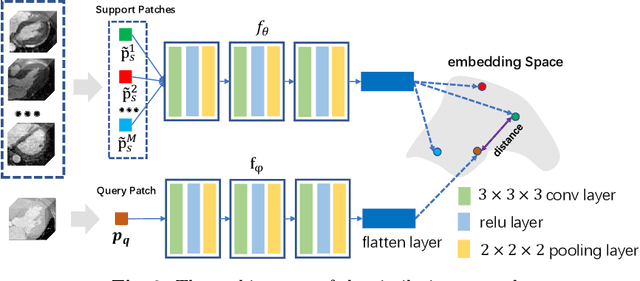
Both image registration and label fusion in the multi-atlas segmentation (MAS) rely on the intensity similarity between target and atlas images. However, such similarity can be problematic when target and atlas images are acquired using different imaging protocols. High-level structure information can provide reliable similarity measurement for cross-modality images when cooperating with deep neural networks (DNNs). This work presents a new MAS framework for cross-modality images, where both image registration and label fusion are achieved by DNNs. For image registration, we propose a consistent registration network, which can jointly estimate forward and backward dense displacement fields (DDFs). Additionally, an invertible constraint is employed in the network to reduce the correspondence ambiguity of the estimated DDFs. For label fusion, we adapt a few-shot learning network to measure the similarity of atlas and target patches. Moreover, the network can be seamlessly integrated into the patch-based label fusion. The proposed framework is evaluated on the MM-WHS dataset of MICCAI 2017. Results show that the framework is effective in both cross-modality registration and segmentation.