 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Graph Unlearning
Mar 27, 2021
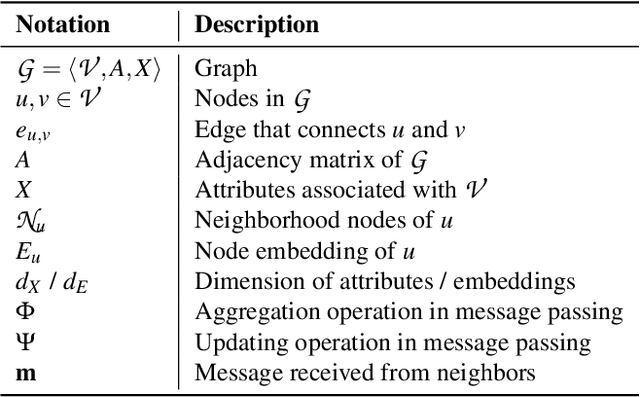

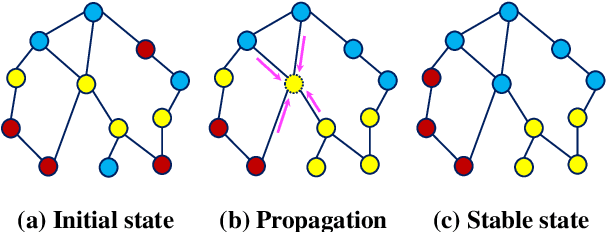
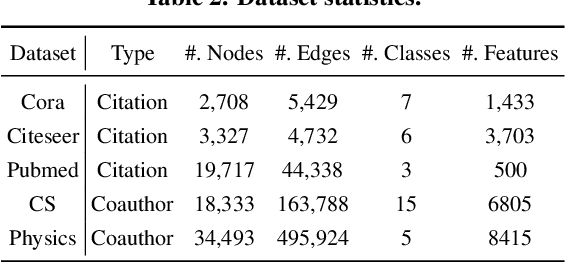
The right to be forgotten states that a data subject has the right to erase their data from an entity storing it. In the context of machine learning (ML), it requires the ML model provider to remove the data subject's data from the training set used to build the ML model, a process known as \textit{machine unlearning}. While straightforward and legitimate, retraining the ML model from scratch upon receiving unlearning requests incurs high computational overhead when the training set is large. To address this issue, a number of approximate algorithms have been proposed in the domain of image and text data, among which SISA is the state-of-the-art solution. It randomly partitions the training set into multiple shards and trains a constituent model for each shard. However, directly applying SISA to the graph data can severely damage the graph structural information, and thereby the resulting ML model utility. In this paper, we propose GraphEraser, a novel machine unlearning method tailored to graph data. Its contributions include two novel graph partition algorithms, and a learning-based aggregation method. We conduct extensive experiments on five real-world datasets to illustrate the unlearning efficiency and model utility of GraphEraser. We observe that GraphEraser achieves 2.06$\times$ (small dataset) to 35.94$\times$ (large dataset) unlearning time improvement compared to retraining from scratch. On the other hand, GraphEraser achieves up to $62.5\%$ higher F1 score than that of random partitioning. In addition, our proposed learning-based aggregation method achieves up to $112\%$ higher F1 score than that of the majority vote aggregation.
Image Denoising via CNNs: An Adversarial Approach
Aug 01, 2017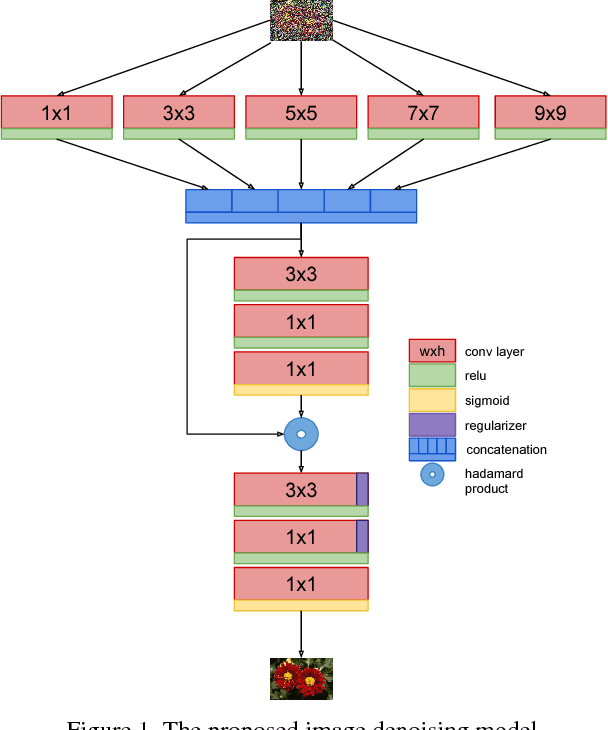
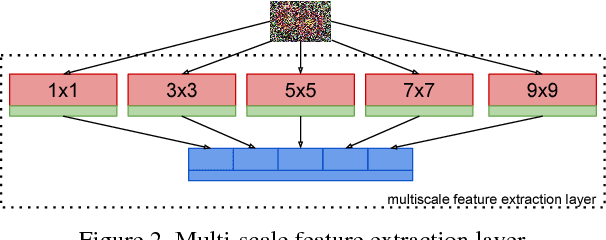
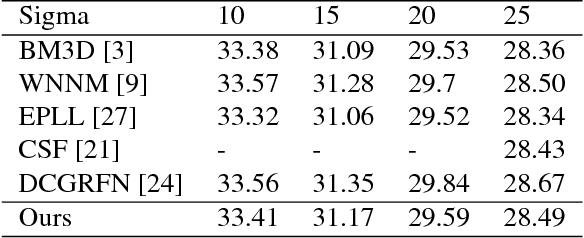

Is it possible to recover an image from its noisy version using convolutional neural networks? This is an interesting problem as convolutional layers are generally used as feature detectors for tasks like classification, segmentation and object detection. We present a new CNN architecture for blind image denoising which synergically combines three architecture components, a multi-scale feature extraction layer which helps in reducing the effect of noise on feature maps, an l_p regularizer which helps in selecting only the appropriate feature maps for the task of reconstruction, and finally a three step training approach which leverages adversarial training to give the final performance boost to the model. The proposed model shows competitive denoising performance when compared to the state-of-the-art approaches.
A Simplified Approach to Deep Learning for Image Segmentation
Aug 31, 2018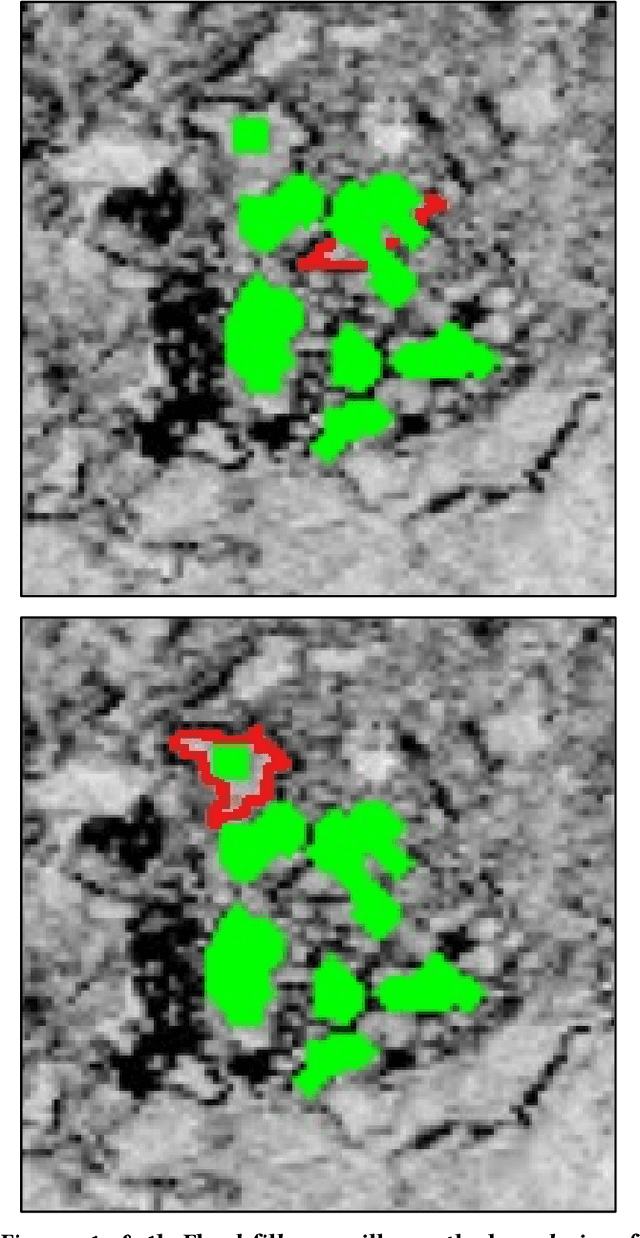

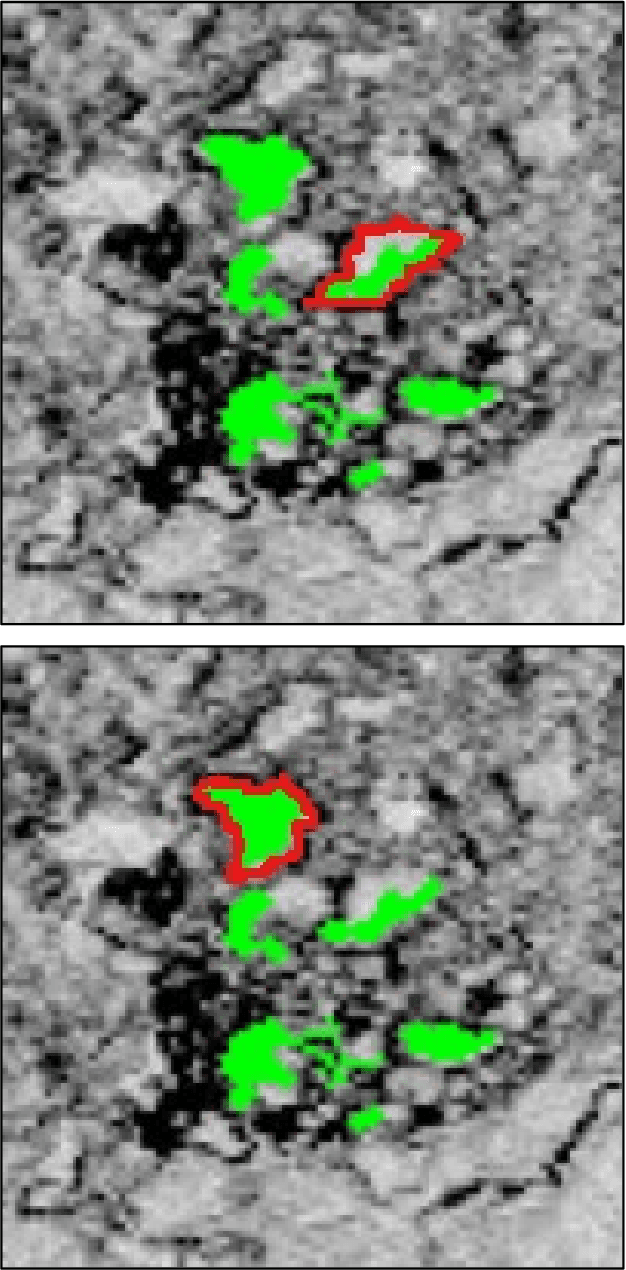

Leaping into the rapidly developing world of deep learning is an exciting and sometimes confusing adventure. All of the advice and tutorials available can be hard to organize and work through, especially when training specific models on specific datasets, different from those originally used to train the network. In this short guide, we aim to walk the reader through the techniques that we have used to successfully train two deep neural networks for pixel-wise classification, including some data management and augmentation approaches for working with image data that may be insufficiently annotated or relatively homogenous.
* 8 pages, 6 figures (1a to 6c, plus 5 in appendix), PEARC '18: Practice and Experience in Advanced Research Computing, July 22--26, 2018, Pittsburgh, PA, USA
Dilated Convolutions with Lateral Inhibitions for Semantic Image Segmentation
Jun 16, 2020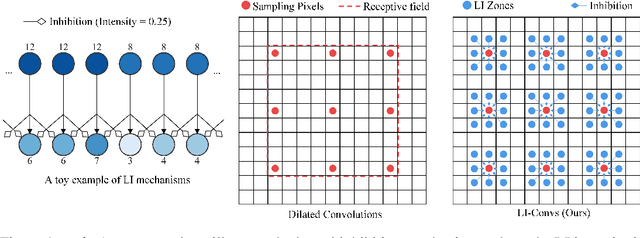
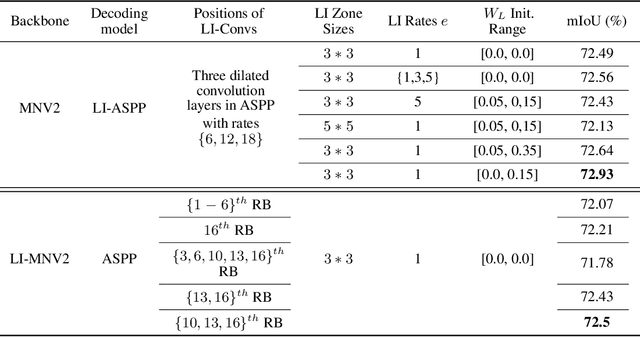

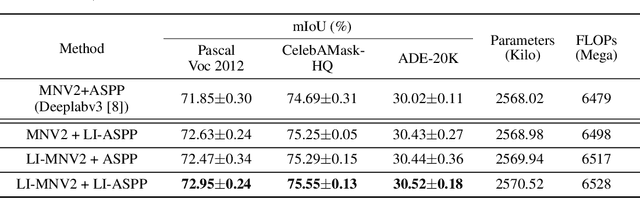
Dilated convolutions are widely used in deep semantic segmentation models as they can enlarge the filters' receptive field without adding additional weights nor sacrificing spatial resolution. However, as dilated convolutional filters do not possess positional knowledge about the pixels on semantically meaningful contours, they could lead to ambiguous predictions on object boundaries. In addition, although dilating the filter can expand its receptive field, the total number of sampled pixels remains unchanged, which usually comprises a small fraction of the receptive field's total area. Inspired by the Lateral Inhibition (LI) mechanisms in human visual systems, we propose the dilated convolution with lateral inhibitions (LI-Convs) to overcome these limitations. Introducing LI mechanisms improves the convolutional filter's sensitivity to semantic object boundaries. Moreover, since LI-Convs also implicitly take the pixels from the laterally inhibited zones into consideration, they can also extract features at a denser scale. By integrating LI-Convs into the Deeplabv3+ architecture, we propose the Lateral Inhibited Atrous Spatial Pyramid Pooling (LI-ASPP) and the Lateral Inhibited MobileNet-V2 (LI-MNV2). Experimental results on three benchmark datasets (PASCAL VOC 2012, CelebAMask-HQ and ADE20K) show that our LI-based segmentation models outperform the baseline on all of them, thus verify the effectiveness and generality of the proposed LI-Convs.
Ear2Face: Deep Biometric Modality Mapping
Jun 02, 2020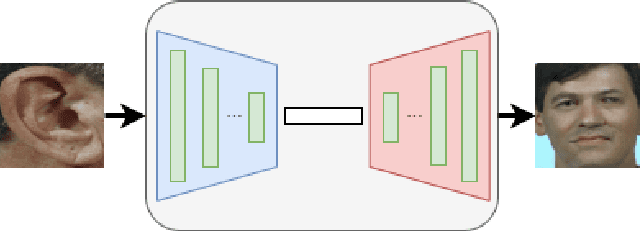
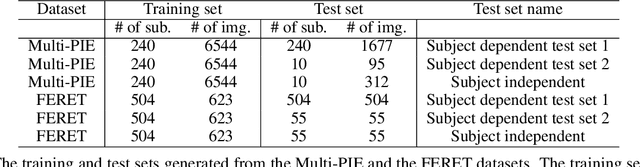
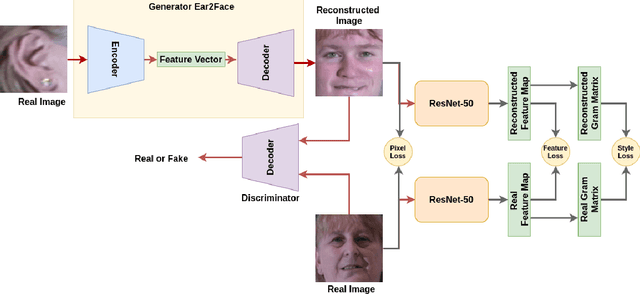

In this paper, we explore the correlation between different visual biometric modalities. For this purpose, we present an end-to-end deep neural network model that learns a mapping between the biometric modalities. Namely, our goal is to generate a frontal face image of a subject given his/her ear image as the input. We formulated the problem as a paired image-to-image translation task and collected datasets of ear and face image pairs from the Multi-PIE and FERET datasets to train our GAN-based models. We employed feature reconstruction and style reconstruction losses in addition to adversarial and pixel losses. We evaluated the proposed method both in terms of reconstruction quality and in terms of person identification accuracy. To assess the generalization capability of the learned mapping models, we also run cross-dataset experiments. That is, we trained the model on the FERET dataset and tested it on the Multi-PIE dataset and vice versa. We have achieved very promising results, especially on the FERET dataset, generating visually appealing face images from ear image inputs. Moreover, we attained a very high cross-modality person identification performance, for example, reaching 90.9% Rank-10 identification accuracy on the FERET dataset.
Generative networks as inverse problems with fractional wavelet scattering networks
Jul 28, 2020
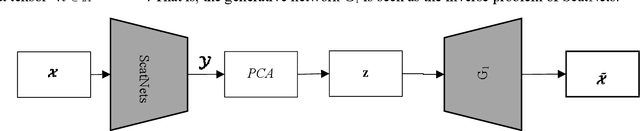
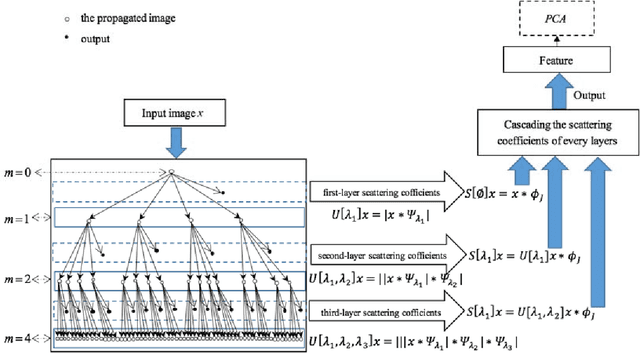
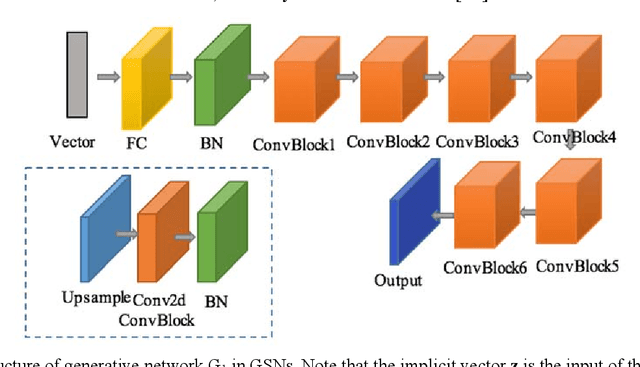
Deep learning is a hot research topic in the field of machine learning methods and applications. Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs) provide impressive image generations from Gaussian white noise, but both of them are difficult to train since they need to train the generator (or encoder) and the discriminator (or decoder) simultaneously, which is easy to cause unstable training. In order to solve or alleviate the synchronous training difficult problems of GANs and VAEs, recently, researchers propose Generative Scattering Networks (GSNs), which use wavelet scattering networks (ScatNets) as the encoder to obtain the features (or ScatNet embeddings) and convolutional neural networks (CNNs) as the decoder to generate the image. The advantage of GSNs is the parameters of ScatNets are not needed to learn, and the disadvantage of GSNs is that the expression ability of ScatNets is slightly weaker than CNNs and the dimensional reduction method of Principal Component Analysis (PCA) is easy to lead overfitting in the training of GSNs, and therefore affect the generated quality in the testing process. In order to further improve the quality of generated images while keep the advantages of GSNs, this paper proposes Generative Fractional Scattering Networks (GFRSNs), which use more expressive fractional wavelet scattering networks (FrScatNets) instead of ScatNets as the encoder to obtain the features (or FrScatNet embeddings) and use the similar CNNs of GSNs as the decoder to generate the image. Additionally, this paper develops a new dimensional reduction method named Feature-Map Fusion (FMF) instead of PCA for better keeping the information of FrScatNets and the effect of image fusion on the quality of image generation is also discussed.
A Neuro-Inspired Autoencoding Defense Against Adversarial Perturbations
Dec 21, 2020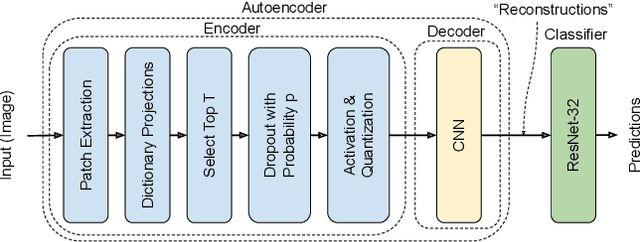

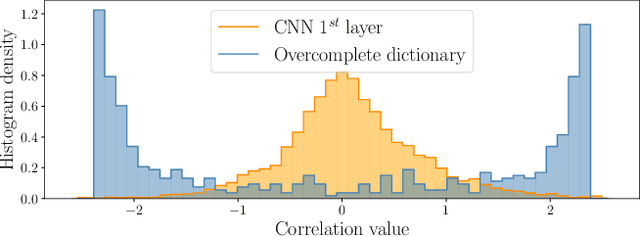
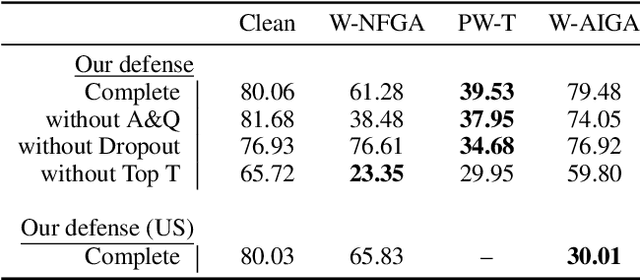
Deep Neural Networks (DNNs) are vulnerable to adversarial attacks: carefully constructed perturbations to an image can seriously impair classification accuracy, while being imperceptible to humans. While there has been a significant amount of research on defending against such attacks, most defenses based on systematic design principles have been defeated by appropriately modified attacks. For a fixed set of data, the most effective current defense is to train the network using adversarially perturbed examples. In this paper, we investigate a radically different, neuro-inspired defense mechanism, starting from the observation that human vision is virtually unaffected by adversarial examples designed for machines. We aim to reject L^inf bounded adversarial perturbations before they reach a classifier DNN, using an encoder with characteristics commonly observed in biological vision: sparse overcomplete representations, randomness due to synaptic noise, and drastic nonlinearities. Encoder training is unsupervised, using standard dictionary learning. A CNN-based decoder restores the size of the encoder output to that of the original image, enabling the use of a standard CNN for classification. Our nominal design is to train the decoder and classifier together in standard supervised fashion, but we also consider unsupervised decoder training based on a regression objective (as in a conventional autoencoder) with separate supervised training of the classifier. Unlike adversarial training, all training is based on clean images. Our experiments on the CIFAR-10 show performance competitive with state-of-the-art defenses based on adversarial training, and point to the promise of neuro-inspired techniques for the design of robust neural networks. In addition, we provide results for a subset of the Imagenet dataset to verify that our approach scales to larger images.
Bridge the Vision Gap from Field to Command: A Deep Learning Network Enhancing Illumination and Details
Jan 20, 2021


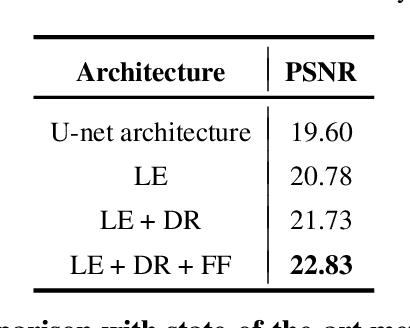
With the goal of tuning up the brightness, low-light image enhancement enjoys numerous applications, such as surveillance, remote sensing and computational photography. Images captured under low-light conditions often suffer from poor visibility and blur. Solely brightening the dark regions will inevitably amplify the blur, thus may lead to detail loss. In this paper, we propose a simple yet effective two-stream framework named NEID to tune up the brightness and enhance the details simultaneously without introducing many computational costs. Precisely, the proposed method consists of three parts: Light Enhancement (LE), Detail Refinement (DR) and Feature Fusing (FF) module, which can aggregate composite features oriented to multiple tasks based on channel attention mechanism. Extensive experiments conducted on several benchmark datasets demonstrate the efficacy of our method and its superiority over state-of-the-art methods.
Re-evaluating Automatic Metrics for Image Captioning
Dec 22, 2016
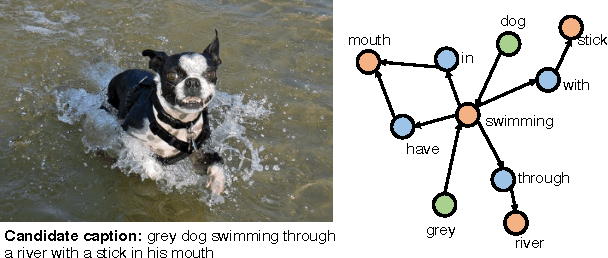
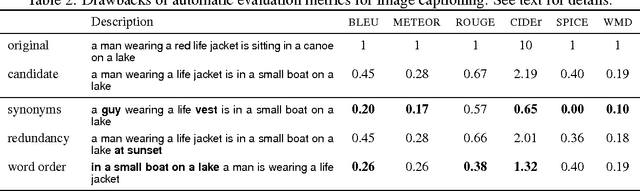
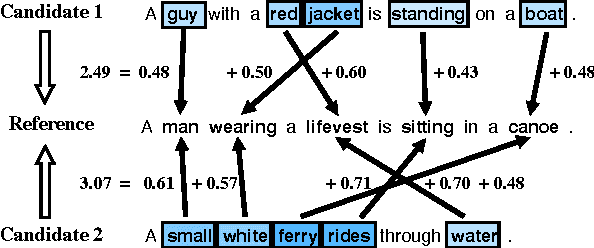
The task of generating natural language descriptions from images has received a lot of attention in recent years. Consequently, it is becoming increasingly important to evaluate such image captioning approaches in an automatic manner. In this paper, we provide an in-depth evaluation of the existing image captioning metrics through a series of carefully designed experiments. Moreover, we explore the utilization of the recently proposed Word Mover's Distance (WMD) document metric for the purpose of image captioning. Our findings outline the differences and/or similarities between metrics and their relative robustness by means of extensive correlation, accuracy and distraction based evaluations. Our results also demonstrate that WMD provides strong advantages over other metrics.
Riemannian-based Discriminant Analysis for Feature Extraction and Classification
Jan 20, 2021
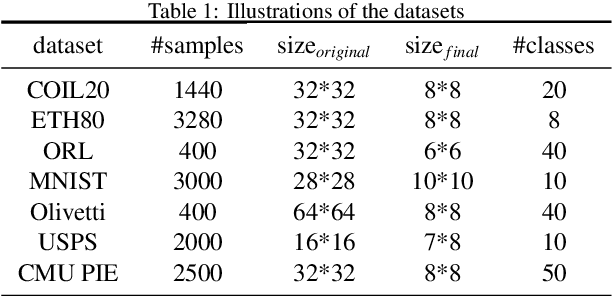
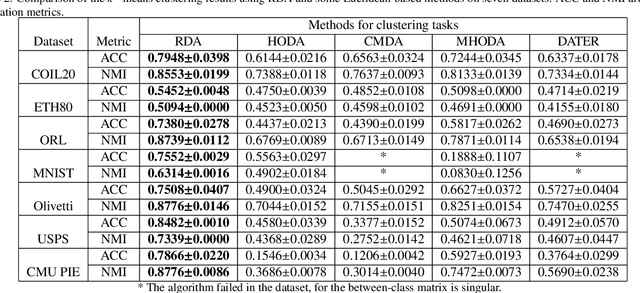
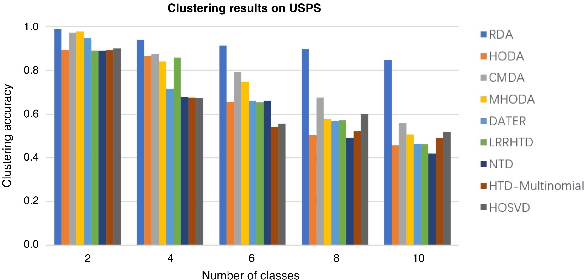
Discriminant analysis, as a widely used approach in machine learning to extract low-dimensional features from the high-dimensional data, applies the Fisher discriminant criterion to find the orthogonal discriminant projection subspace. But most of the Euclidean-based algorithms for discriminant analysis are easily convergent to a spurious local minima and hardly obtain an unique solution. To address such problem, in this study we propose a novel method named Riemannian-based Discriminant Analysis (RDA), which transforms the traditional Euclidean-based methods to the Riemannian manifold space. In RDA, the second-order geometry of trust-region methods is utilized to learn the discriminant bases. To validate the efficiency and effectiveness of RDA, we conduct a variety of experiments on image classification tasks. The numerical results suggest that RDA can extract statistically significant features and robustly outperform state-of-the-art algorithms in classification tasks.