 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative networks as inverse problems with fractional wavelet scattering networks
Paper and Code

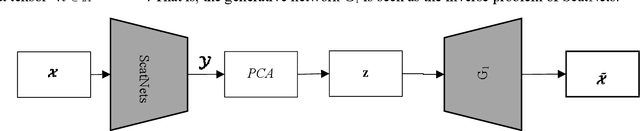
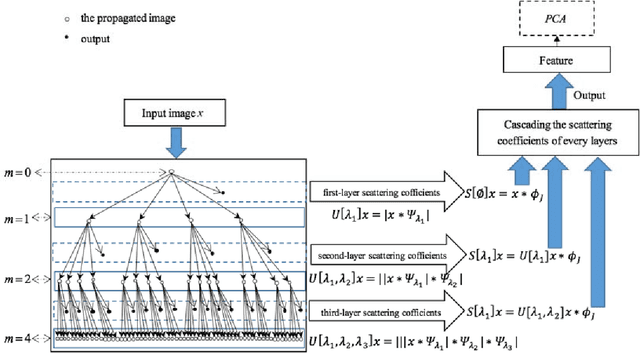
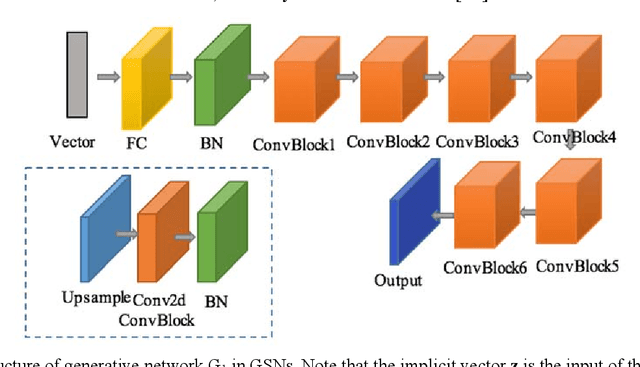
Deep learning is a hot research topic in the field of machine learning methods and applications. Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs) provide impressive image generations from Gaussian white noise, but both of them are difficult to train since they need to train the generator (or encoder) and the discriminator (or decoder) simultaneously, which is easy to cause unstable training. In order to solve or alleviate the synchronous training difficult problems of GANs and VAEs, recently, researchers propose Generative Scattering Networks (GSNs), which use wavelet scattering networks (ScatNets) as the encoder to obtain the features (or ScatNet embeddings) and convolutional neural networks (CNNs) as the decoder to generate the image. The advantage of GSNs is the parameters of ScatNets are not needed to learn, and the disadvantage of GSNs is that the expression ability of ScatNets is slightly weaker than CNNs and the dimensional reduction method of Principal Component Analysis (PCA) is easy to lead overfitting in the training of GSNs, and therefore affect the generated quality in the testing process. In order to further improve the quality of generated images while keep the advantages of GSNs, this paper proposes Generative Fractional Scattering Networks (GFRSNs), which use more expressive fractional wavelet scattering networks (FrScatNets) instead of ScatNets as the encoder to obtain the features (or FrScatNet embeddings) and use the similar CNNs of GSNs as the decoder to generate the image. Additionally, this paper develops a new dimensional reduction method named Feature-Map Fusion (FMF) instead of PCA for better keeping the information of FrScatNets and the effect of image fusion on the quality of image generation is also discussed.