 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
One Shot Learning for Deformable Medical Image Registration and Periodic Motion Tracking
Jul 11, 2019
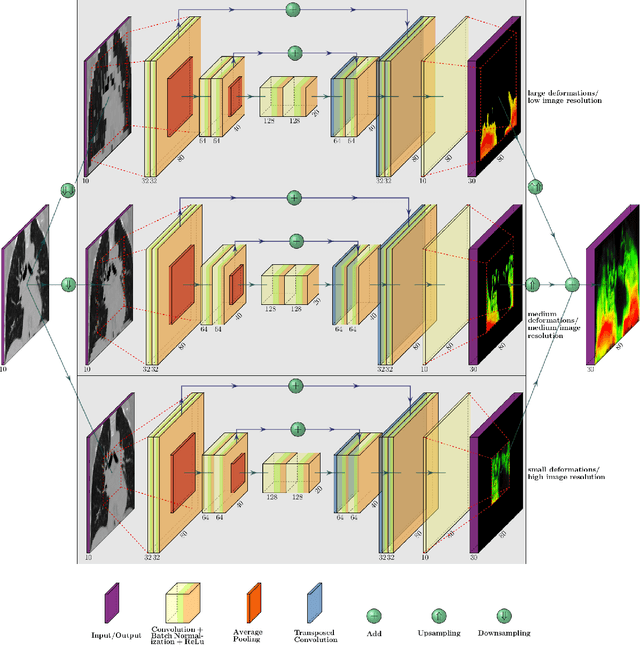
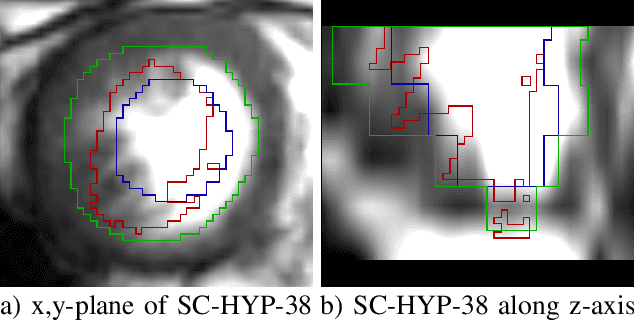
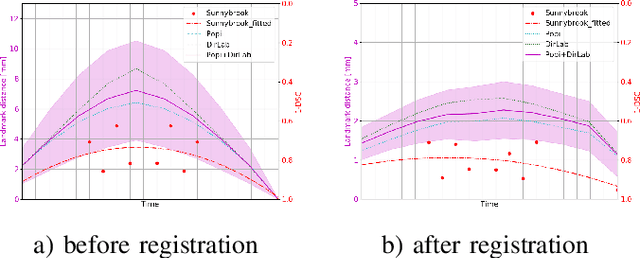
Deformable image registration is a very important field of research in medical imaging. Recently multiple deep learning approaches were published in this area showing promising results. However, drawbacks of deep learning methods are the need for a large amount of training datasets and their inability to register unseen images different from the training datasets. One shot learning comes without the need of large training datasets and has already been proven to be applicable to 3D data. In this work we present an one shot registration approach for periodic motion tracking in 3D and 4D datasets. When applied to 3D dataset the algorithm calculates the inverse of a registration vector field simultaneously. For registration we employed a U-Net combined with a coarse to fine approach and a differential spatial transformer module. The algorithm was thoroughly tested with multiple 4D and 3D datasets publicly available. The results show that the presented approach is able to track periodic motion and to yield a competitive registration accuracy. Possible applications are the use as a stand-alone algorithm for 3D and 4D motion tracking or in the beginning of studies until enough datasets for a separate training phase are available.
Noise2Inpaint: Learning Referenceless Denoising by Inpainting Unrolling
Jun 16, 2020
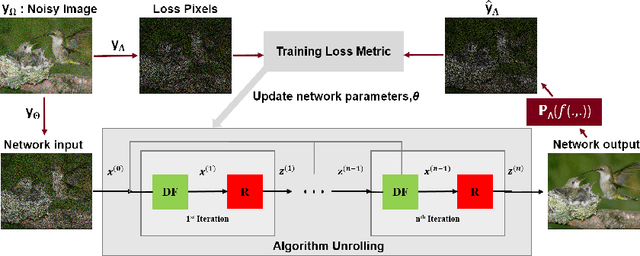


Deep learning based image denoising methods have been recently popular due to their improved performance. Traditionally, these methods are trained in a supervised manner, requiring a set of noisy input and clean target image pairs. More recently, self-supervised approaches have been proposed to learn denoising from noisy images only, without requiring clean ground truth during training. Succinctly, these methods assume that an image pixel is correlated with its neighboring pixels, while the noise is independent. In this work, building on these approaches and recent methods from image reconstruction, we introduce Noise2Inpaint (N2I), a training approach that recasts the denoising problem into a regularized image inpainting framework. This allows us to use an objective function, which can incorporate different statistical properties of the noise as needed. We use algorithm unrolling to unroll an iterative optimization for solving this objective function and train the unrolled network end-to-end. The training is self-supervised without requiring clean target images, where pixels in the noisy image are split into two disjoint sets. One of these is used to impose data fidelity in the unrolled network, while the other one defines the loss. We demonstrate that N2I performs successful denoising on real-world datasets, while preserving better details compared to its self-supervised counterpart Noise2Void.
Event-based Synthetic Aperture Imaging with a Hybrid Network
Mar 04, 2021
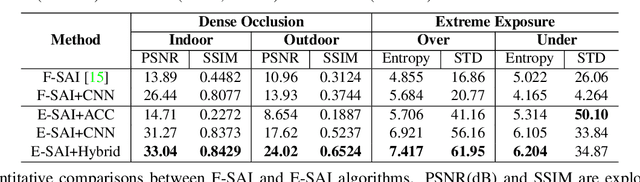


Synthetic aperture imaging (SAI) is able to achieve the see through effect by blurring out the off-focus foreground occlusions and reconstructing the in-focus occluded targets from multi-view images. However, very dense occlusions and extreme lighting conditions may bring significant disturbances to SAI based on conventional frame-based cameras, leading to performance degeneration. To address these problems, we propose a novel SAI system based on the event camera which can produce asynchronous events with extremely low latency and high dynamic range. Thus, it can eliminate the interference of dense occlusions by measuring with almost continuous views, and simultaneously tackle the over/under exposure problems. To reconstruct the occluded targets, we propose a hybrid encoder-decoder network composed of spiking neural networks (SNNs) and convolutional neural networks (CNNs). In the hybrid network, the spatio-temporal information of the collected events is first encoded by SNN layers, and then transformed to the visual image of the occluded targets by a style-transfer CNN decoder. Through experiments, the proposed method shows remarkable performance in dealing with very dense occlusions and extreme lighting conditions, and high quality visual images can be reconstructed using pure event data.
Adversarial Segmentation Loss for Sketch Colorization
Feb 11, 2021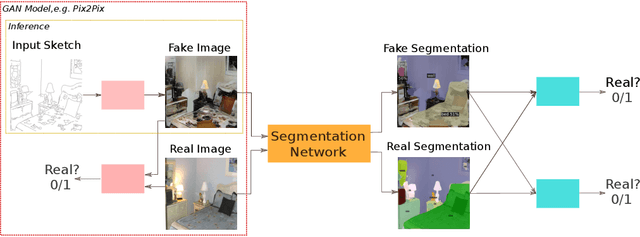


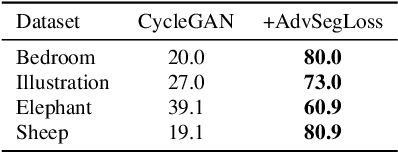
We introduce a new method for generating color images from sketches or edge maps. Current methods either require some form of additional user-guidance or are limited to the "paired" translation approach. We argue that segmentation information could provide valuable guidance for sketch colorization. To this end, we propose to leverage semantic image segmentation, as provided by a general purpose panoptic segmentation network, to create an additional adversarial loss function. Our loss function can be integrated to any baseline GAN model. Our method is not limited to datasets that contain segmentation labels, and it can be trained for "unpaired" translation tasks. We show the effectiveness of our method on four different datasets spanning scene level indoor, outdoor, and children book illustration images using qualitative, quantitative and user study analysis. Our model improves its baseline up to 35 points on the FID metric. Our code and pretrained models can be found at https://github.com/giddyyupp/AdvSegLoss.
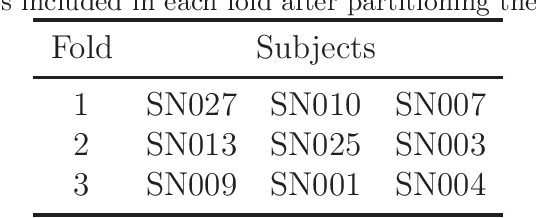
EvoSplit: An evolutionary approach to split a multi-label data set into disjoint subset
Feb 11, 2021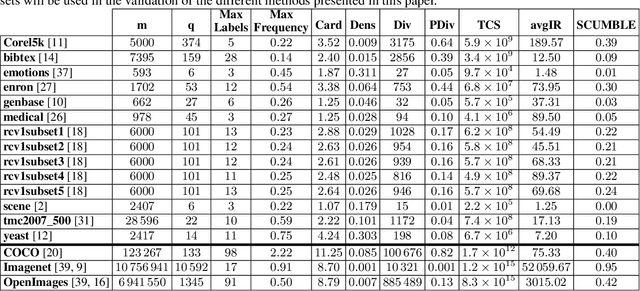

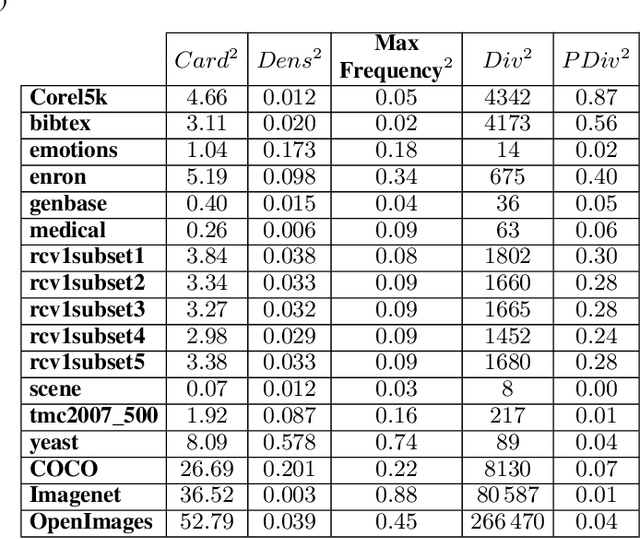
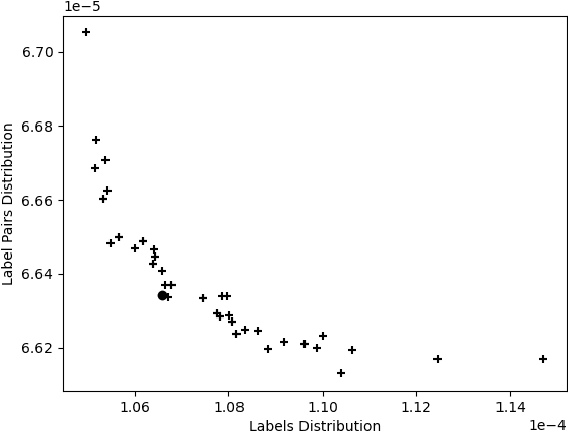
This paper presents a new evolutionary approach, EvoSplit, for the distribution of multi-label data sets into disjoint subsets for supervised machine learning. Currently, data set providers either divide a data set randomly or using iterative stratification, a method that aims to maintain the label (or label pair) distribution of the original data set into the different subsets. Following the same aim, this paper first introduces a single-objective evolutionary approach that tries to obtain a split that maximizes the similarity between those distributions independently. Second, a new multi-objective evolutionary algorithm is presented to maximize the similarity considering simultaneously both distributions (label and label pair). Both approaches are validated using well-known multi-label data sets as well as large image data sets currently used in computer vision and machine learning applications. EvoSplit improves the splitting of a data set in comparison to the iterative stratification following different measures: Label Distribution, Label Pair Distribution, Examples Distribution, folds and fold-label pairs with zero positive examples.
Computational efficient deep neural network with difference attention maps for facial action unit detection
Nov 27, 2020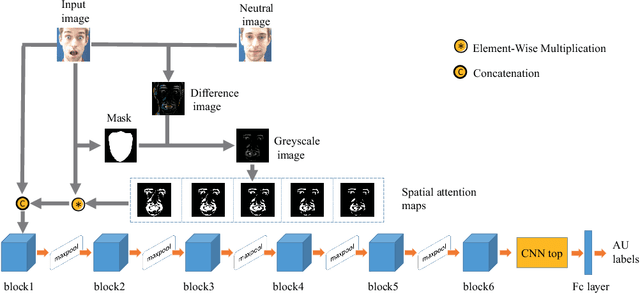


In this paper, we propose a computational efficient end-to-end training deep neural network (CEDNN) model and spatial attention maps based on difference images. Firstly, the difference image is generated by image processing. Then five binary images of difference images are obtained using different thresholds, which are used as spatial attention maps. We use group convolution to reduce model complexity. Skip connection and $\text{1}\times \text{1}$ convolution are used to ensure good performance even if the network model is not deep. As an input, spatial attention map can be selectively fed into the input of each block. The feature maps tend to focus on the parts that are related to the target task better. In addition, we only need to adjust the parameters of classifier to train different numbers of AU. It can be easily extended to varying datasets without increasing too much computation. A large number of experimental results show that the proposed CEDNN is obviously better than the traditional deep learning method on DISFA+ and CK+ datasets. After adding spatial attention maps, the result is better than the most advanced AU detection method. At the same time, the scale of the network is small, the running speed is fast, and the requirement for experimental equipment is low.
Real-Time Navigation System for a Low-Cost Mobile Robot with an RGB-D Camera
Mar 04, 2021


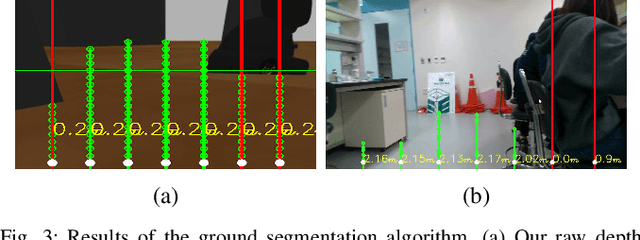
Currently, mobile robots are developing rapidly and are finding numerous applications in industry. However, there remain a number of problems related to their practical use, such as the need for expensive hardware and their high power consumption levels. In this study, we propose a navigation system that is operable on a low-end computer with an RGB-D camera and a mobile robot platform for the operation of an integrated autonomous driving system. The proposed system does not require LiDARs or a GPU. Our raw depth image ground segmentation approach extracts a traversability map for the safe driving of low-body mobile robots. It is designed to guarantee real-time performance on a low-cost commercial single board computer with integrated SLAM, global path planning, and motion planning. Running sensor data processing and other autonomous driving functions simultaneously, our navigation method performs rapidly at a refresh rate of 18Hz for control command, whereas other systems have slower refresh rates. Our method outperforms current state-of-the-art navigation approaches as shown in 3D simulation tests. In addition, we demonstrate the applicability of our mobile robot system through successful autonomous driving in a residential lobby.
Thinking Deeply with Recurrence: Generalizing from Easy to Hard Sequential Reasoning Problems
Feb 22, 2021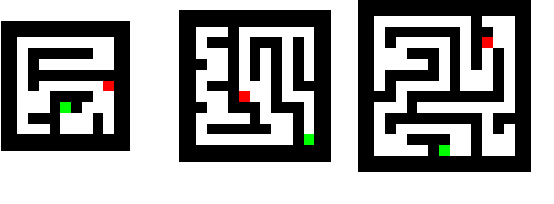
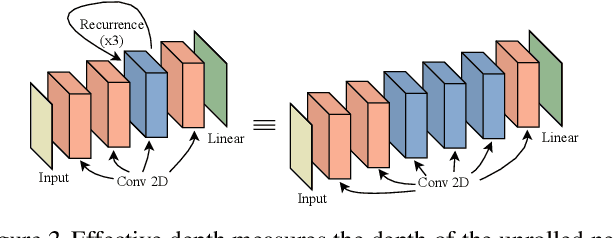

Deep neural networks are powerful machines for visual pattern recognition, but reasoning tasks that are easy for humans may still be difficult for neural models. Humans can extrapolate simple reasoning strategies to solve difficult problems using long sequences of abstract manipulations, i.e., harder problems are solved by thinking for longer. In contrast, the sequential computing budget of feed-forward networks is limited by their depth, and networks trained on simple problems have no way of extending their reasoning capabilities without retraining. In this work, we observe that recurrent networks have the uncanny ability to closely emulate the behavior of non-recurrent deep models, often doing so with far fewer parameters, on both image classification and maze solving tasks. We also explore whether recurrent networks can make the generalization leap from simple problems to hard problems simply by increasing the number of recurrent iterations used as test time. To this end, we show that recurrent networks that are trained to solve simple mazes with few recurrent steps can indeed solve much more complex problems simply by performing additional recurrences during inference.
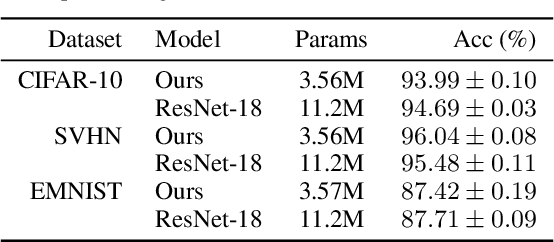
Combining GANs and AutoEncoders for Efficient Anomaly Detection
Nov 16, 2020
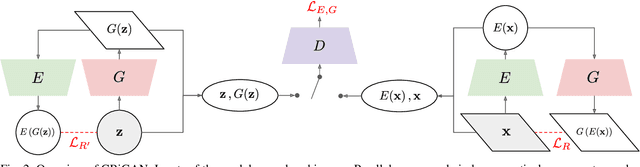
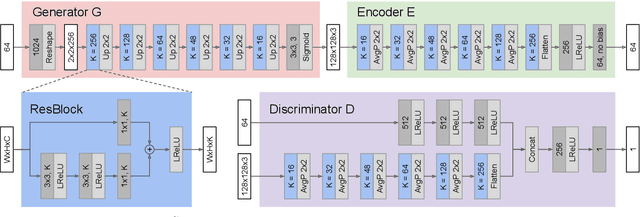
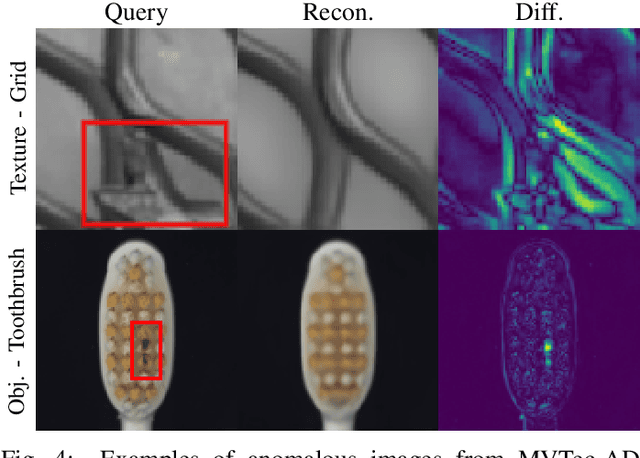
Deep learned models are now largely adopted in different fields, and they generally provide superior performances with respect to classical signal-based approaches. Notwithstanding this, their actual reliability when working in an unprotected environment is far enough to be proven. In this work, we consider a novel deep neural network architecture, named Neural Ordinary Differential Equations (N-ODE), that is getting particular attention due to an attractive property --- a test-time tunable trade-off between accuracy and efficiency. This paper analyzes the robustness of N-ODE image classifiers when faced against a strong adversarial attack and how its effectiveness changes when varying such a tunable trade-off. We show that adversarial robustness is increased when the networks operate in different tolerance regimes during test time and training time. On this basis, we propose a novel adversarial detection strategy for N-ODE nets based on the randomization of the adaptive ODE solver tolerance. Our evaluation performed on standard image classification benchmarks shows that our detection technique provides high rejection of adversarial examples while maintaining most of the original samples under white-box attacks and zero-knowledge adversaries.
Heuristics based Mosaic of Social-Sensor Services for Scene Reconstruction
Sep 21, 2020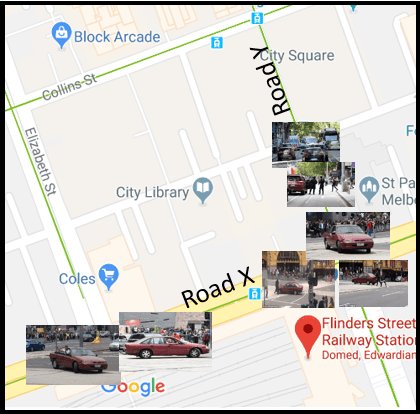
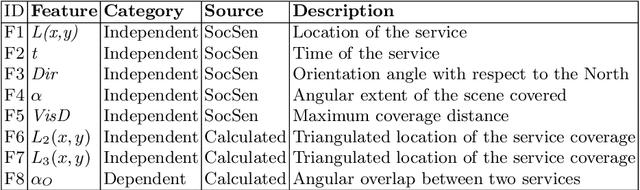
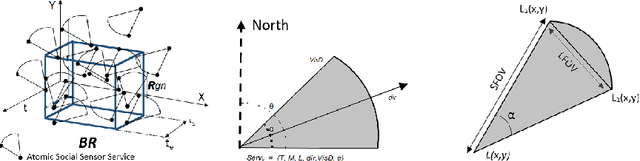

We propose a heuristics-based social-sensor cloud service selection and composition model to reconstruct mosaic scenes. The proposed approach leverages crowdsourced social media images to create an image mosaic to reconstruct a scene at a designated location and an interval of time. The novel approach relies on the set of features defined on the bases of the image metadata to determine the relevance and composability of services. Novel heuristics are developed to filter out non-relevant services. Multiple machine learning strategies are employed to produce smooth service composition resulting in a mosaic of relevant images indexed by geolocation and time. The preliminary analytical results prove the feasibility of the proposed composition model.