 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Reconstruction of Animatable 3D Avatars with Cloth Dynamics from a Single Image
Mar 16, 2026Existing single-image 3D human avatar methods primarily rely on rigid joint transformations, limiting their ability to model realistic cloth dynamics. We present DynaAvatar, a zero-shot framework that reconstructs animatable 3D human avatars with motion-dependent cloth dynamics from a single image. Trained on large-scale multi-person motion datasets, DynaAvatar employs a Transformer-based feed-forward architecture that directly predicts dynamic 3D Gaussian deformations without subject-specific optimization. To overcome the scarcity of dynamic captures, we introduce a static-to-dynamic knowledge transfer strategy: a Transformer pretrained on large-scale static captures provides strong geometric and appearance priors, which are efficiently adapted to motion-dependent deformations through lightweight LoRA fine-tuning on dynamic captures. We further propose the DynaFlow loss, an optical flow-guided objective that provides reliable motion-direction geometric cues for cloth dynamics in rendered space. Finally, we reannotate the missing or noisy SMPL-X fittings in existing dynamic capture datasets, as most public dynamic capture datasets contain incomplete or unreliable fittings that are unsuitable for training high-quality 3D avatar reconstruction models. Experiments demonstrate that DynaAvatar produces visually rich and generalizable animations, outperforming prior methods.
PERSONA: Personalized Whole-Body 3D Avatar with Pose-Driven Deformations from a Single Image
Aug 13, 2025



Two major approaches exist for creating animatable human avatars. The first, a 3D-based approach, optimizes a NeRF- or 3DGS-based avatar from videos of a single person, achieving personalization through a disentangled identity representation. However, modeling pose-driven deformations, such as non-rigid cloth deformations, requires numerous pose-rich videos, which are costly and impractical to capture in daily life. The second, a diffusion-based approach, learns pose-driven deformations from large-scale in-the-wild videos but struggles with identity preservation and pose-dependent identity entanglement. We present PERSONA, a framework that combines the strengths of both approaches to obtain a personalized 3D human avatar with pose-driven deformations from a single image. PERSONA leverages a diffusion-based approach to generate pose-rich videos from the input image and optimizes a 3D avatar based on them. To ensure high authenticity and sharp renderings across diverse poses, we introduce balanced sampling and geometry-weighted optimization. Balanced sampling oversamples the input image to mitigate identity shifts in diffusion-generated training videos. Geometry-weighted optimization prioritizes geometry constraints over image loss, preserving rendering quality in diverse poses.
Real-Time Navigation System for a Low-Cost Mobile Robot with an RGB-D Camera
Mar 04, 2021


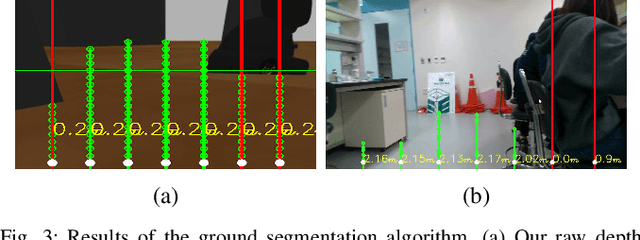
Currently, mobile robots are developing rapidly and are finding numerous applications in industry. However, there remain a number of problems related to their practical use, such as the need for expensive hardware and their high power consumption levels. In this study, we propose a navigation system that is operable on a low-end computer with an RGB-D camera and a mobile robot platform for the operation of an integrated autonomous driving system. The proposed system does not require LiDARs or a GPU. Our raw depth image ground segmentation approach extracts a traversability map for the safe driving of low-body mobile robots. It is designed to guarantee real-time performance on a low-cost commercial single board computer with integrated SLAM, global path planning, and motion planning. Running sensor data processing and other autonomous driving functions simultaneously, our navigation method performs rapidly at a refresh rate of 18Hz for control command, whereas other systems have slower refresh rates. Our method outperforms current state-of-the-art navigation approaches as shown in 3D simulation tests. In addition, we demonstrate the applicability of our mobile robot system through successful autonomous driving in a residential lobby.