 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Motion-blurred Video Interpolation and Extrapolation
Mar 04, 2021
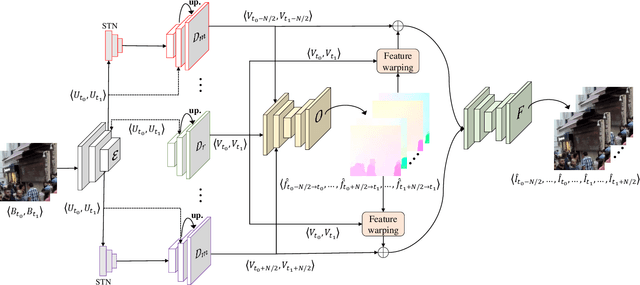
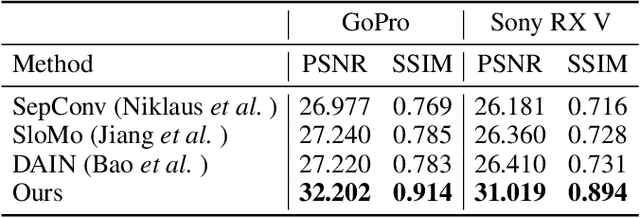

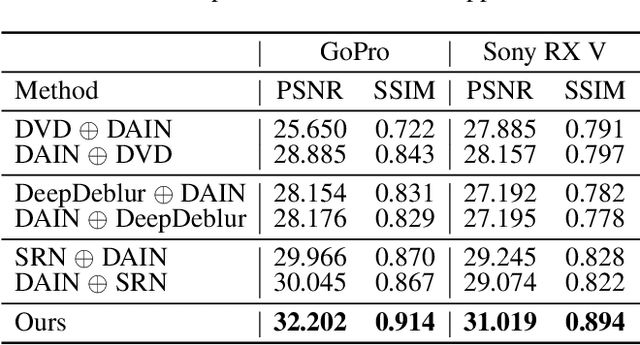
Abrupt motion of camera or objects in a scene result in a blurry video, and therefore recovering high quality video requires two types of enhancements: visual enhancement and temporal upsampling. A broad range of research attempted to recover clean frames from blurred image sequences or temporally upsample frames by interpolation, yet there are very limited studies handling both problems jointly. In this work, we present a novel framework for deblurring, interpolating and extrapolating sharp frames from a motion-blurred video in an end-to-end manner. We design our framework by first learning the pixel-level motion that caused the blur from the given inputs via optical flow estimation and then predict multiple clean frames by warping the decoded features with the estimated flows. To ensure temporal coherence across predicted frames and address potential temporal ambiguity, we propose a simple, yet effective flow-based rule. The effectiveness and favorability of our approach are highlighted through extensive qualitative and quantitative evaluations on motion-blurred datasets from high speed videos.
UNet++: A Nested U-Net Architecture for Medical Image Segmentation
Jul 18, 2018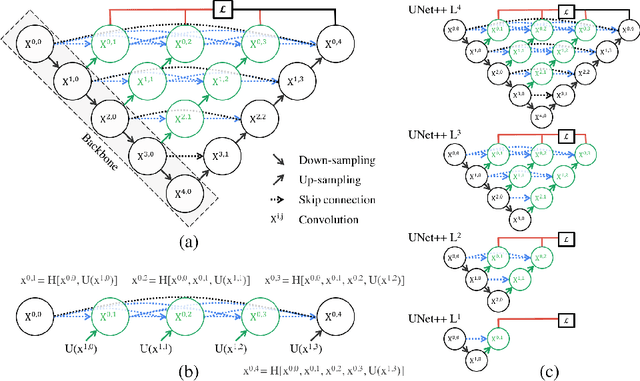
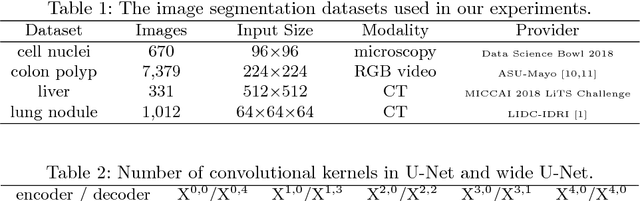

In this paper, we present UNet++, a new, more powerful architecture for medical image segmentation. Our architecture is essentially a deeply-supervised encoder-decoder network where the encoder and decoder sub-networks are connected through a series of nested, dense skip pathways. The re-designed skip pathways aim at reducing the semantic gap between the feature maps of the encoder and decoder sub-networks. We argue that the optimizer would deal with an easier learning task when the feature maps from the decoder and encoder networks are semantically similar. We have evaluated UNet++ in comparison with U-Net and wide U-Net architectures across multiple medical image segmentation tasks: nodule segmentation in the low-dose CT scans of chest, nuclei segmentation in the microscopy images, liver segmentation in abdominal CT scans, and polyp segmentation in colonoscopy videos. Our experiments demonstrate that UNet++ with deep supervision achieves an average IoU gain of 3.9 and 3.4 points over U-Net and wide U-Net, respectively.
Sequential Image-based Attention Network for Inferring Force Estimation without Haptic Sensor
Nov 17, 2018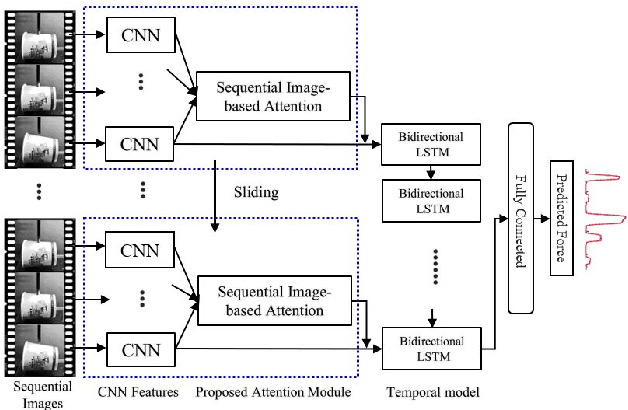
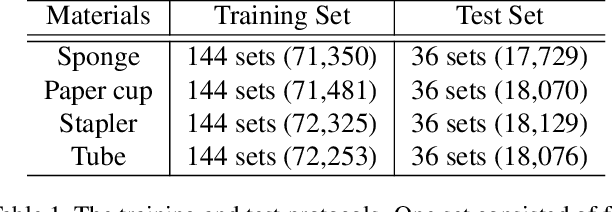
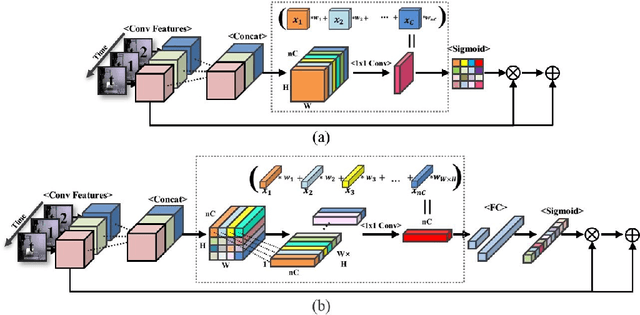
Humans can infer approximate interaction force between objects from only vision information because we already have learned it through experiences. Based on this idea, we propose a recurrent convolutional neural network-based method using sequential images for inferring interaction force without using a haptic sensor. For training and validating deep learning methods, we collected a large number of images and corresponding interaction forces through an electronic motor-based device. To concentrate on changing shapes of a target object by the external force in images, we propose a sequential image-based attention module, which learns a salient model from temporal dynamics. The proposed sequential image-based attention module consists of a sequential spatial attention module and a sequential channel attention module, which are extended to exploit multiple sequential images. For gaining better accuracy, we also created a weighted average pooling layer for both spatial and channel attention modules. The extensive experimental results verified that the proposed method successfully infers interaction forces under the various conditions, such as different target materials, illumination changes, and external force directions.
Turkey Behavior Identification System with a GUI Using Deep Learning and Video Analytics
Feb 09, 2021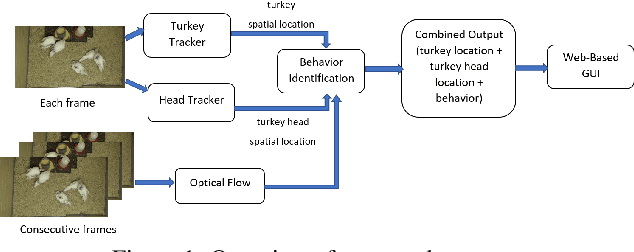
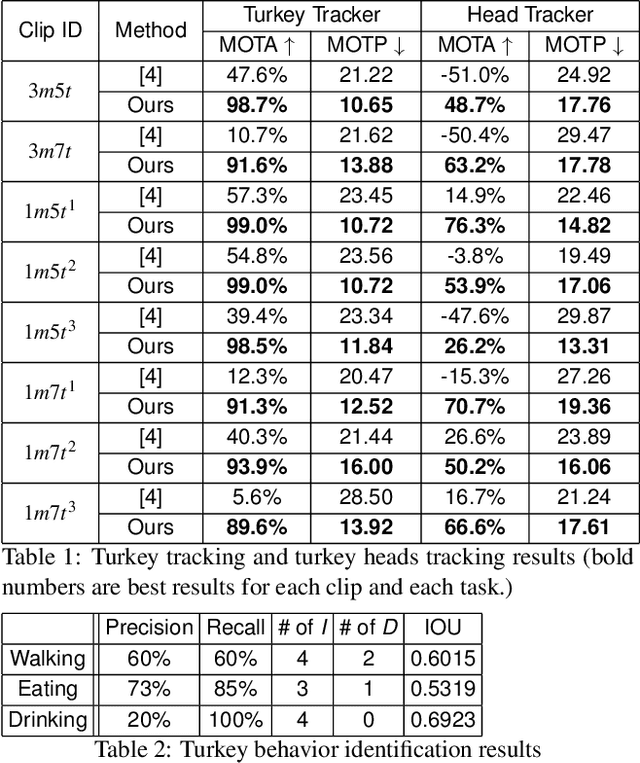


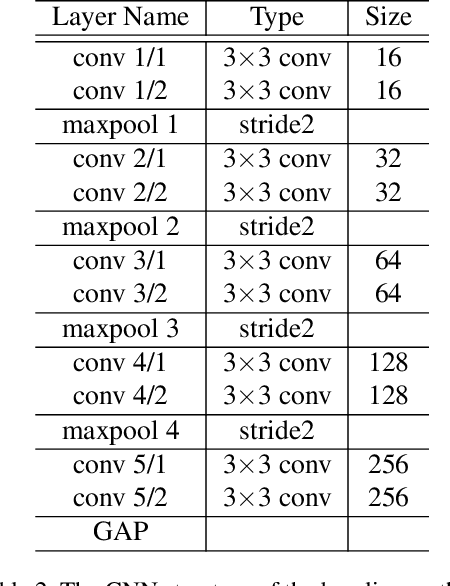
In this paper, we propose a video analytics system to identify the behavior of turkeys. Turkey behavior provides evidence to assess turkey welfare, which can be negatively impacted by uncomfortable ambient temperature and various diseases. In particular, healthy and sick turkeys behave differently in terms of the duration and frequency of activities such as eating, drinking, preening, and aggressive interactions. Our system incorporates recent advances in object detection and tracking to automate the process of identifying and analyzing turkey behavior captured by commercial grade cameras. We combine deep-learning and traditional image processing methods to address challenges in this practical agricultural problem. Our system also includes a web-based user interface to create visualization of automated analysis results. Together, we provide an improved tool for turkey researchers to assess turkey welfare without the time-consuming and labor-intensive manual inspection.
Spatial-Channel Transformer Network for Trajectory Prediction on the Traffic Scenes
Jan 27, 2021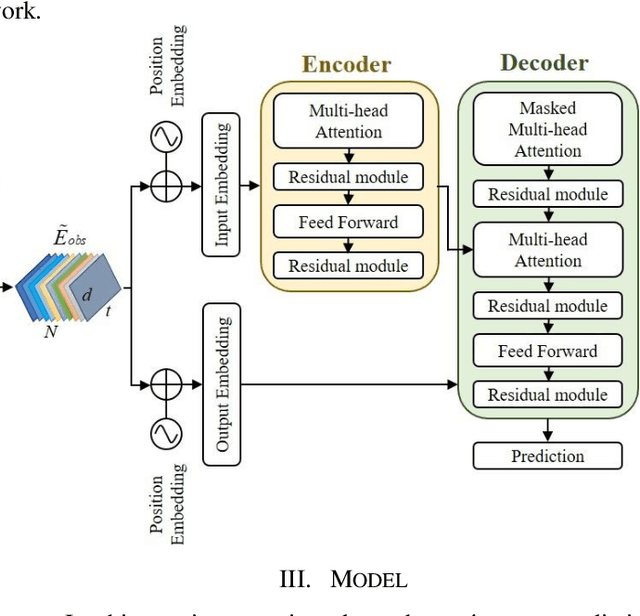
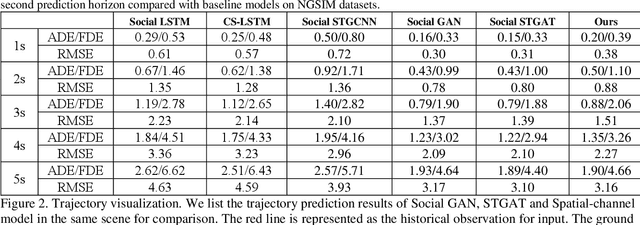
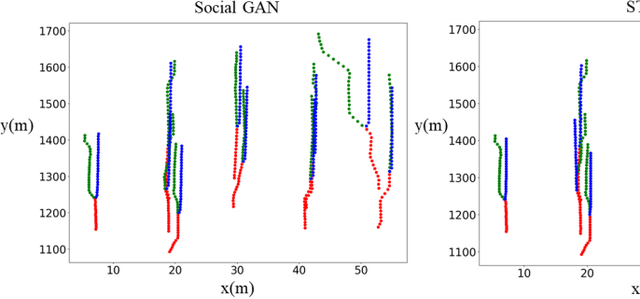
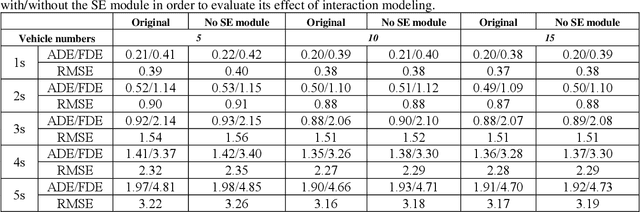
Predicting motion of surrounding agents is critical to real-world applications of tactical path planning for autonomous driving. Due to the complex temporal dependencies and social interactions of agents, on-line trajectory prediction is a challenging task. With the development of attention mechanism in recent years, transformer model has been applied in natural language sequence processing first and then image processing. In this paper, we present a Spatial-Channel Transformer Network for trajectory prediction with attention functions. Instead of RNN models, we employ transformer model to capture the spatial-temporal features of agents. A channel-wise module is inserted to measure the social interaction between agents. We find that the Spatial-Channel Transformer Network achieves promising results on real-world trajectory prediction datasets on the traffic scenes.
How Unique Is a Face: An Investigative Study
Feb 09, 2021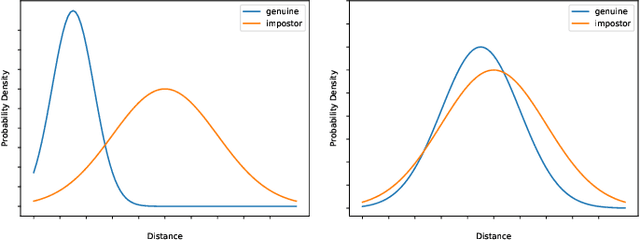

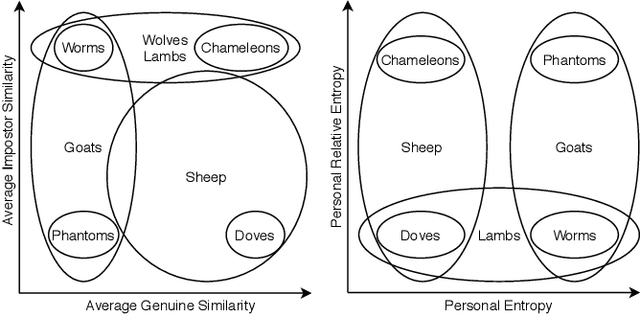
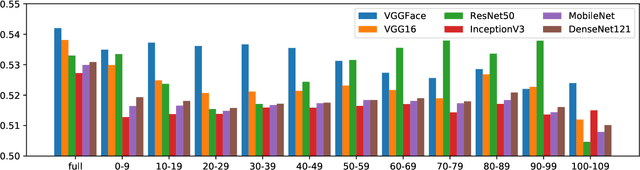
Face recognition has been widely accepted as a means of identification in applications ranging from border control to security in the banking sector. Surprisingly, while widely accepted, we still lack the understanding of uniqueness or distinctiveness of faces as biometric modality. In this work, we study the impact of factors such as image resolution, feature representation, database size, age and gender on uniqueness denoted by the Kullback-Leibler divergence between genuine and impostor distributions. Towards understanding the impact, we present experimental results on the datasets AT&T, LFW, IMDb-Face, as well as ND-TWINS, with the feature extraction algorithms VGGFace, VGG16, ResNet50, InceptionV3, MobileNet and DenseNet121, that reveal the quantitative impact of the named factors. While these are early results, our findings indicate the need for a better understanding of the concept of biometric uniqueness and its implication on face recognition.
Reconstruction-Based Membership Inference Attacks are Easier on Difficult Problems
Feb 15, 2021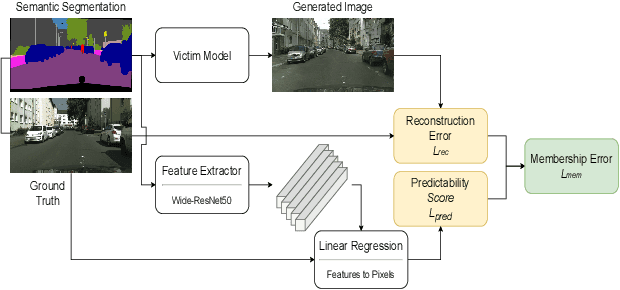
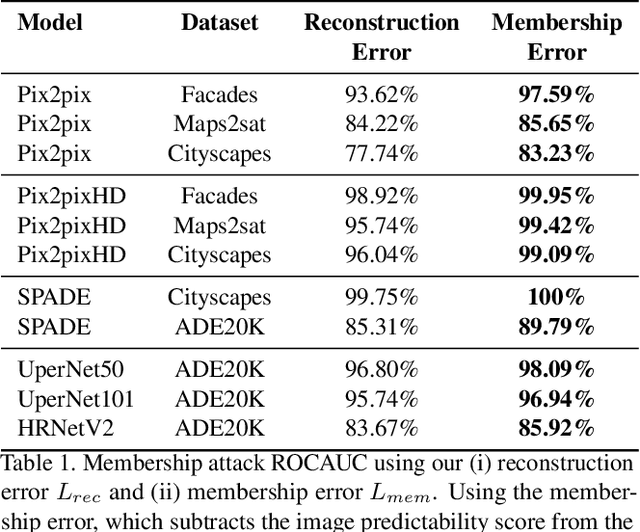

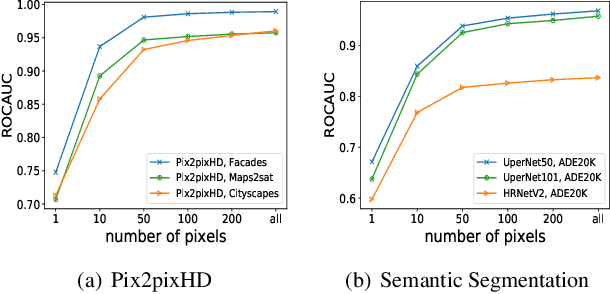
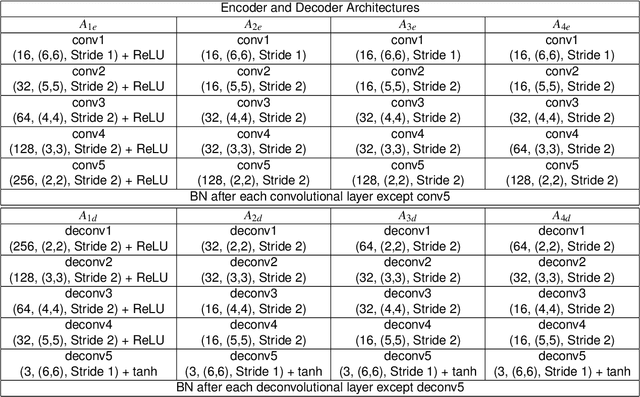
Membership inference attacks (MIA) try to detect if data samples were used to train a neural network model, e.g. to detect copyright abuses. We show that models with higher dimensional input and output are more vulnerable to MIA, and address in more detail models for image translation and semantic segmentation. We show that reconstruction-errors can lead to very effective MIA attacks as they are indicative of memorization. Unfortunately, reconstruction error alone is less effective at discriminating between non-predictable images used in training and easy to predict images that were never seen before. To overcome this, we propose using a novel predictability score that can be computed for each sample, and its computation does not require a training set. Our membership error, obtained by subtracting the predictability score from the reconstruction error, is shown to achieve high MIA accuracy on an extensive number of benchmarks.
Satellite Image Forgery Detection and Localization Using GAN and One-Class Classifier
Feb 13, 2018
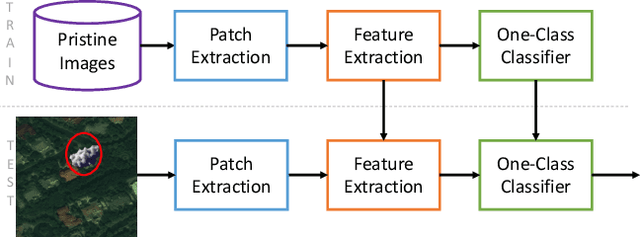

Current satellite imaging technology enables shooting high-resolution pictures of the ground. As any other kind of digital images, overhead pictures can also be easily forged. However, common image forensic techniques are often developed for consumer camera images, which strongly differ in their nature from satellite ones (e.g., compression schemes, post-processing, sensors, etc.). Therefore, many accurate state-of-the-art forensic algorithms are bound to fail if blindly applied to overhead image analysis. Development of novel forensic tools for satellite images is paramount to assess their authenticity and integrity. In this paper, we propose an algorithm for satellite image forgery detection and localization. Specifically, we consider the scenario in which pixels within a region of a satellite image are replaced to add or remove an object from the scene. Our algorithm works under the assumption that no forged images are available for training. Using a generative adversarial network (GAN), we learn a feature representation of pristine satellite images. A one-class support vector machine (SVM) is trained on these features to determine their distribution. Finally, image forgeries are detected as anomalies. The proposed algorithm is validated against different kinds of satellite images containing forgeries of different size and shape.
Locally Masked Convolution for Autoregressive Models
Jun 27, 2020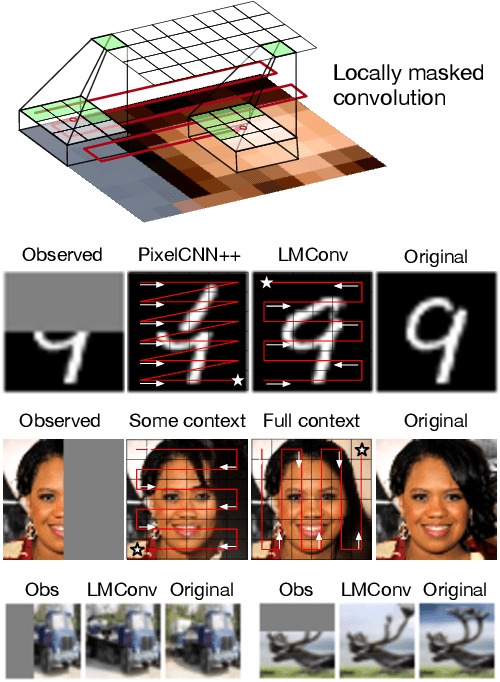
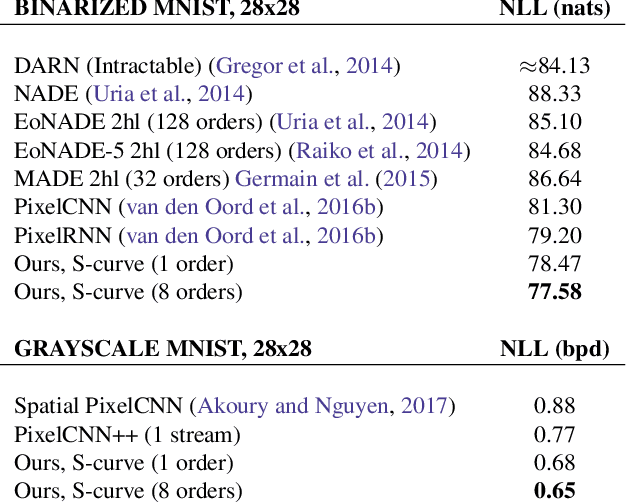
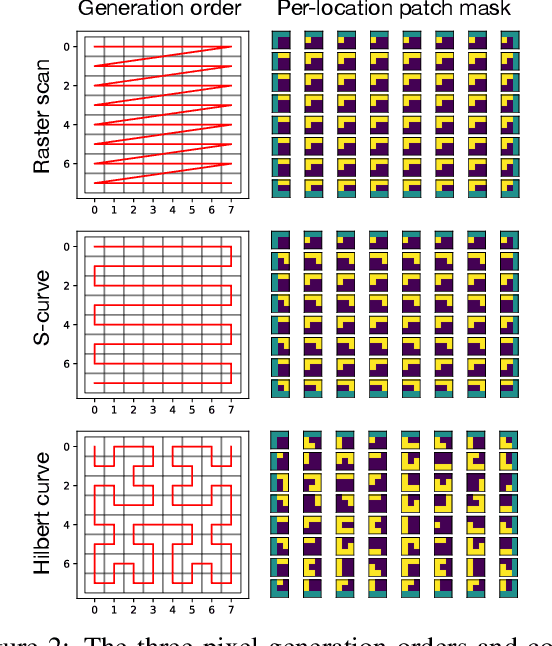

High-dimensional generative models have many applications including image compression, multimedia generation, anomaly detection and data completion. State-of-the-art estimators for natural images are autoregressive, decomposing the joint distribution over pixels into a product of conditionals parameterized by a deep neural network, e.g. a convolutional neural network such as the PixelCNN. However, PixelCNNs only model a single decomposition of the joint, and only a single generation order is efficient. For tasks such as image completion, these models are unable to use much of the observed context. To generate data in arbitrary orders, we introduce LMConv: a simple modification to the standard 2D convolution that allows arbitrary masks to be applied to the weights at each location in the image. Using LMConv, we learn an ensemble of distribution estimators that share parameters but differ in generation order, achieving improved performance on whole-image density estimation (2.89 bpd on unconditional CIFAR10), as well as globally coherent image completions. Our code is available at https://ajayjain.github.io/lmconv.
Metrics for Exposing the Biases of Content-Style Disentanglement
Aug 31, 2020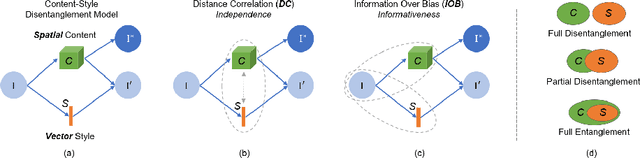
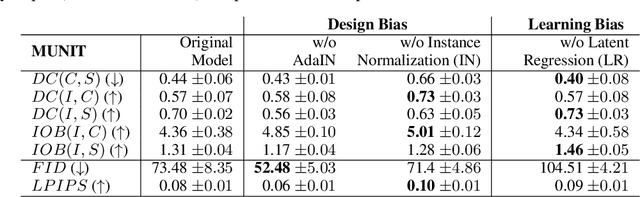
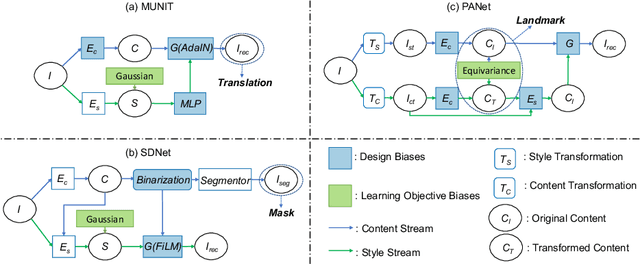
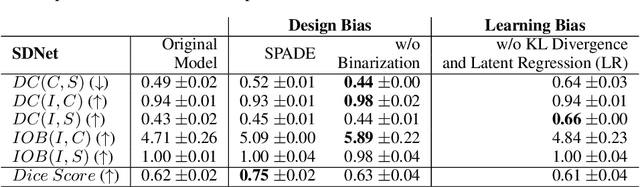
Recent state-of-the-art semi- and un-supervised solutions for challenging computer vision tasks have used the idea of encoding image content into a spatial tensor and image appearance or "style" into a vector. These decomposed representations take advantage of equivariant properties of network design and improve performance in equivariant tasks, such as image-to-image translation. Most of these methods use the term "disentangled" for their representations and employ model design, learning objectives, and data biases to achieve good model performance. While considerable effort has been made to measure disentanglement in vector representations, currently, metrics that can characterize the degree of disentanglement between content (spatial) and style (vector) representations and the relation to task performance are lacking. In this paper, we propose metrics to measure how (un)correlated, biased, and informative the content and style representations are. In particular, we first identify key design choices and learning constraints on three popular models that employ content-style disentanglement and derive ablated versions. Then, we use our metrics to ascertain the role of each bias. Our experiments reveal a "sweet-spot" between disentanglement, task performance and latent space interpretability. The proposed metrics enable the design of better models and the selection of models that achieve the desired performance and disentanglement. Our metrics library is available at https://github.com/TsaftarisCollaboratory/CSDisentanglement_Metrics_Library.