 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-MAS: Extremely Large-Scale Multi-Modal Sensor Dataset for Outdoor Surveillance in Real Environments
Dec 30, 2022



In robotics and computer vision communities, extensive studies have been widely conducted regarding surveillance tasks, including human detection, tracking, and motion recognition with a camera. Additionally, deep learning algorithms are widely utilized in the aforementioned tasks as in other computer vision tasks. Existing public datasets are insufficient to develop learning-based methods that handle various surveillance for outdoor and extreme situations such as harsh weather and low illuminance conditions. Therefore, we introduce a new large-scale outdoor surveillance dataset named eXtremely large-scale Multi-modAl Sensor dataset (X-MAS) containing more than 500,000 image pairs and the first-person view data annotated by well-trained annotators. Moreover, a single pair contains multi-modal data (e.g. an IR image, an RGB image, a thermal image, a depth image, and a LiDAR scan). This is the first large-scale first-person view outdoor multi-modal dataset focusing on surveillance tasks to the best of our knowledge. We present an overview of the proposed dataset with statistics and present methods of exploiting our dataset with deep learning-based algorithms. The latest information on the dataset and our study are available at https://github.com/lge-robot-navi, and the dataset will be available for download through a server.
A Self-Reasoning Framework for Anomaly Detection Using Video-Level Labels
Aug 27, 2020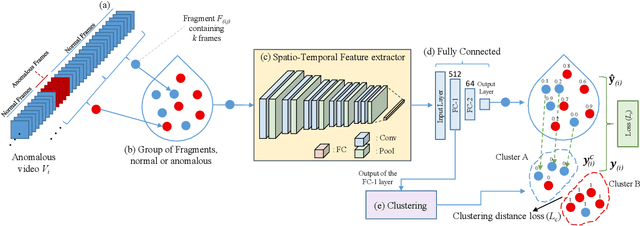
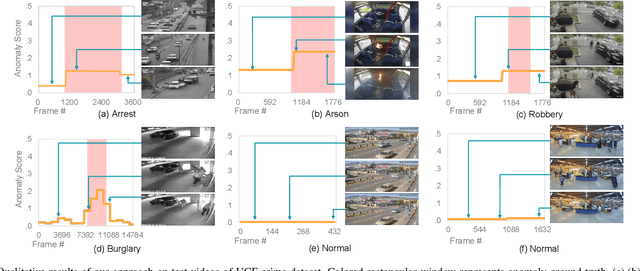

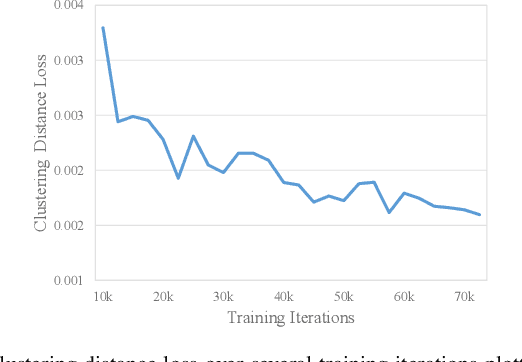
Anomalous event detection in surveillance videos is a challenging and practical research problem among image and video processing community. Compared to the frame-level annotations of anomalous events, obtaining video-level annotations is quite fast and cheap though such high-level labels may contain significant noise. More specifically, an anomalous labeled video may actually contain anomaly only in a short duration while the rest of the video frames may be normal. In the current work, we propose a weakly supervised anomaly detection framework based on deep neural networks which is trained in a self-reasoning fashion using only video-level labels. To carry out the self-reasoning based training, we generate pseudo labels by using binary clustering of spatio-temporal video features which helps in mitigating the noise present in the labels of anomalous videos. Our proposed formulation encourages both the main network and the clustering to complement each other in achieving the goal of more accurate anomaly detection. The proposed framework has been evaluated on publicly available real-world anomaly detection datasets including UCF-crime, ShanghaiTech and UCSD Ped2. The experiments demonstrate superiority of our proposed framework over the current state-of-the-art methods.
Sequential Image-based Attention Network for Inferring Force Estimation without Haptic Sensor
Nov 17, 2018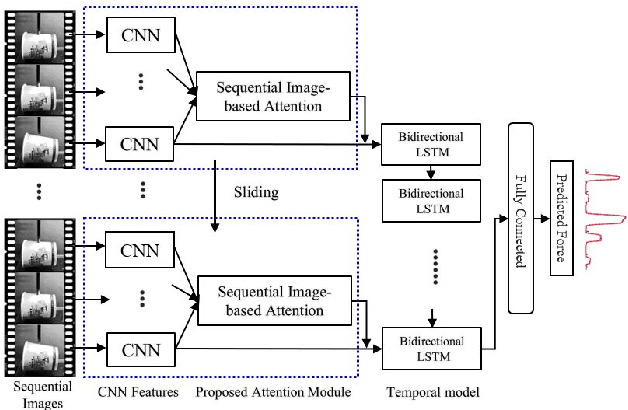
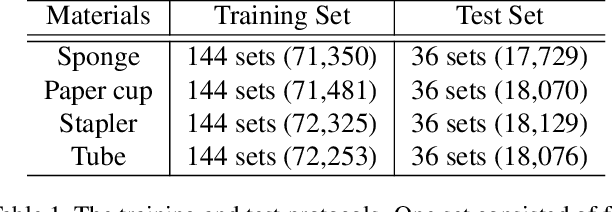
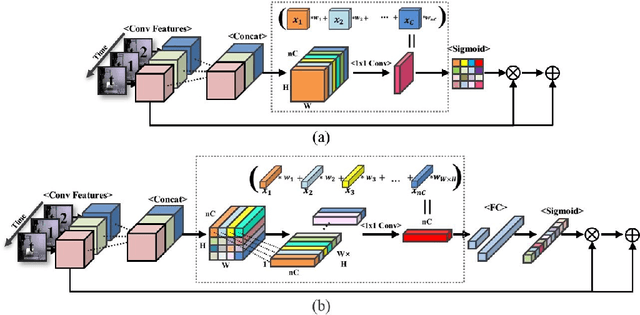
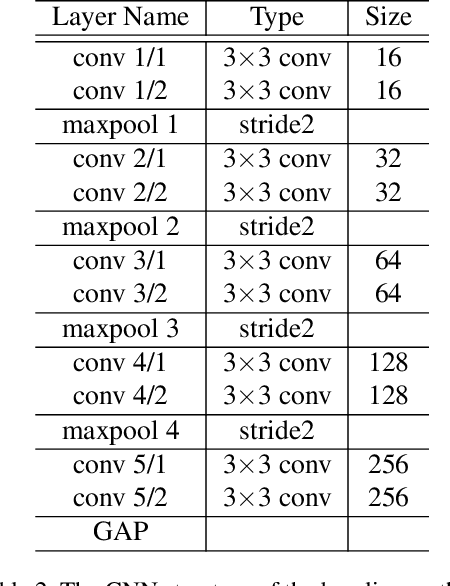
Humans can infer approximate interaction force between objects from only vision information because we already have learned it through experiences. Based on this idea, we propose a recurrent convolutional neural network-based method using sequential images for inferring interaction force without using a haptic sensor. For training and validating deep learning methods, we collected a large number of images and corresponding interaction forces through an electronic motor-based device. To concentrate on changing shapes of a target object by the external force in images, we propose a sequential image-based attention module, which learns a salient model from temporal dynamics. The proposed sequential image-based attention module consists of a sequential spatial attention module and a sequential channel attention module, which are extended to exploit multiple sequential images. For gaining better accuracy, we also created a weighted average pooling layer for both spatial and channel attention modules. The extensive experimental results verified that the proposed method successfully infers interaction forces under the various conditions, such as different target materials, illumination changes, and external force directions.