 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Impact of Facial Tattoos and Paintings on Face Recognition Systems
Mar 27, 2021
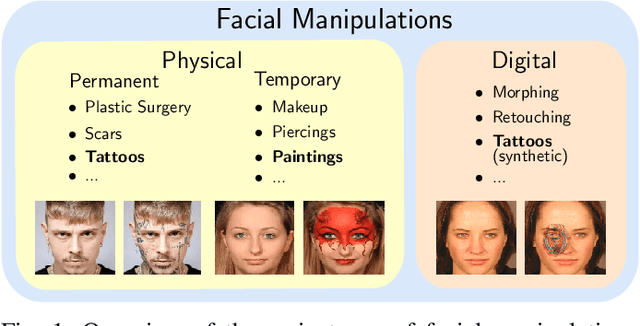
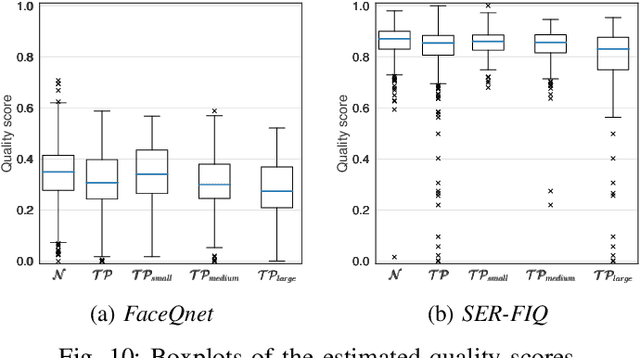
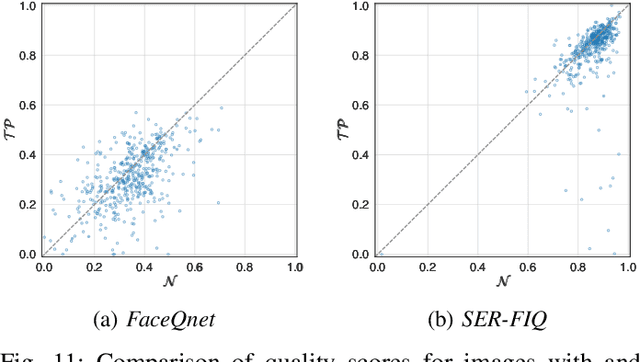

In the past years, face recognition technologies have shown impressive recognition performance, mainly due to recent developments in deep convolutional neural networks. Notwithstanding those improvements, several challenges which affect the performance of face recognition systems remain. In this work, we investigate the impact that facial tattoos and paintings have on current face recognition systems. To this end, we first collected an appropriate database containing image-pairs of individuals with and without facial tattoos or paintings. The assembled database was used to evaluate how facial tattoos and paintings affect the detection, quality estimation, as well as the feature extraction and comparison modules of a face recognition system. The impact on these modules was evaluated using state-of-the-art open-source and commercial systems. The obtained results show that facial tattoos and paintings affect all the tested modules, especially for images where a large area of the face is covered with tattoos or paintings. Our work is an initial case-study and indicates a need to design algorithms which are robust to the visual changes caused by facial tattoos and paintings.
Brain Tumors Classification for MR images based on Attention Guided Deep Learning Model
Apr 06, 2021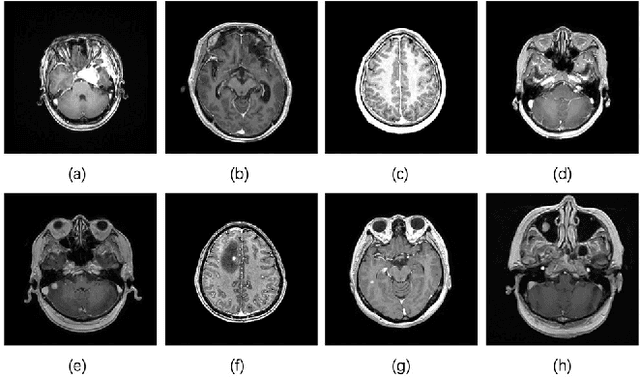
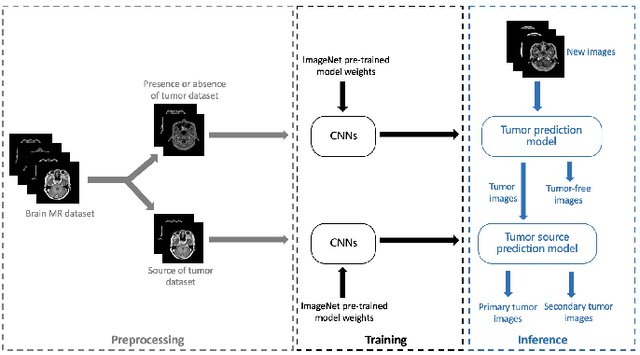
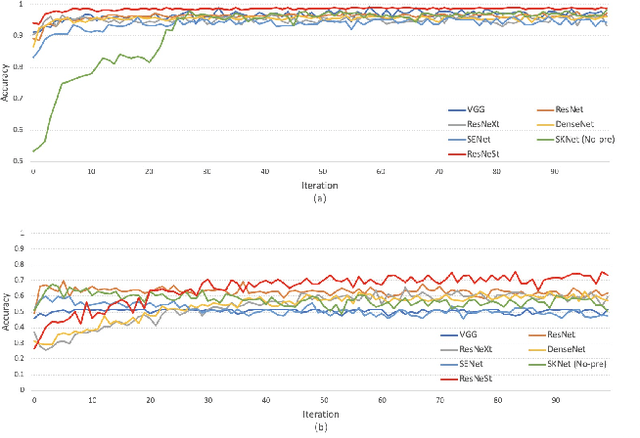
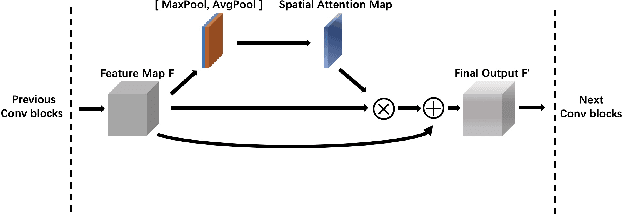
In the clinical diagnosis and treatment of brain tumors, manual image reading consumes a lot of energy and time. In recent years, the automatic tumor classification technology based on deep learning has entered people's field of vision. Brain tumors can be divided into primary and secondary intracranial tumors according to their source. However, to our best knowledge, most existing research on brain tumors are limited to primary intracranial tumor images and cannot classify the source of the tumor. In order to solve the task of tumor source type classification, we analyze the existing technology and propose an attention guided deep convolution neural network (CNN) model. Meanwhile, the method proposed in this paper also effectively improves the accuracy of classifying the presence or absence of tumor. For the brain MR dataset, our method can achieve the average accuracy of 99.18% under ten-fold cross-validation for identifying the presence or absence of tumor, and 83.38% for classifying the source of tumor. Experimental results show that our method is consistent with the method of medical experts. It can assist doctors in achieving efficient clinical diagnosis of brain tumors.
Embedded Computer Vision System Applied to a Four-Legged Line Follower Robot
Jan 12, 2021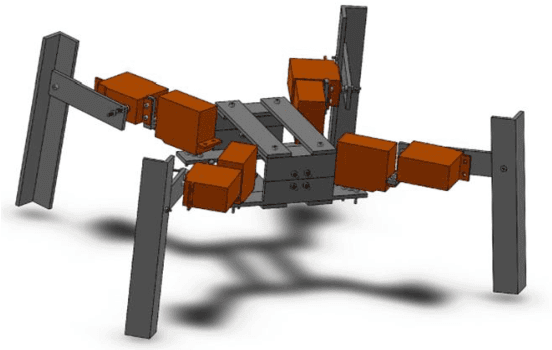
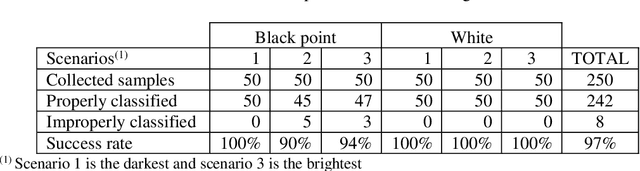
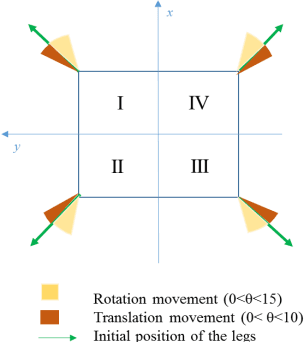

Robotics can be defined as the connection of perception to action. Taking this further, this project aims to drive a robot using an automated computer vision embedded system, connecting the robot's vision to its behavior. In order to implement a color recognition system on the robot, open source tools are chosen, such as Processing language, Android system, Arduino platform and Pixy camera. The constraints are clear: simplicity, replicability and financial viability. In order to integrate Robotics, Computer Vision and Image Processing, the robot is applied on a typical mobile robot's issue: line following. The problem of distinguishing the path from the background is analyzed through different approaches: the popular Otsu's Method, thresholding based on color combinations through experimentation and color tracking via hue and saturation. Decision making of where to move next is based on the line center of the path and is fully automated. Using a four-legged robot as platform and a camera as its only sensor, the robot is capable of successfully follow a line. From capturing the image to moving the robot, it's evident how integrative Robotics can be. The issue of this paper alone involves knowledge of Mechanical Engineering, Electronics, Control Systems and Programming. Everything related to this work was documented and made available on an open source online page, so it can be useful in learning and experimenting with robotics.
BIRNet: Brain Image Registration Using Dual-Supervised Fully Convolutional Networks
Feb 13, 2018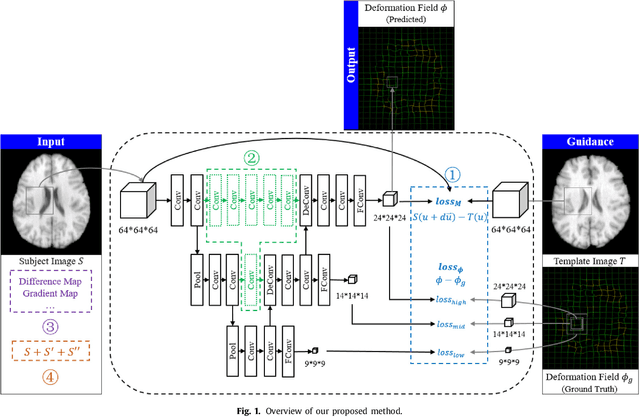

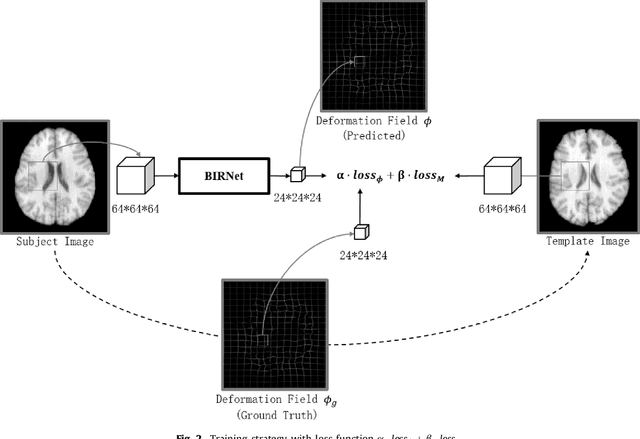
In this paper, we propose a deep learning approach for image registration by predicting deformation from image appearance. Since obtaining ground-truth deformation fields for training can be challenging, we design a fully convolutional network that is subject to dual-guidance: (1) Coarse guidance using deformation fields obtained by an existing registration method; and (2) Fine guidance using image similarity. The latter guidance helps avoid overly relying on the supervision from the training deformation fields, which could be inaccurate. For effective training, we further improve the deep convolutional network with gap filling, hierarchical loss, and multi-source strategies. Experiments on a variety of datasets show promising registration accuracy and efficiency compared with state-of-the-art methods.
Meta-learning of Pooling Layers for Character Recognition
Mar 17, 2021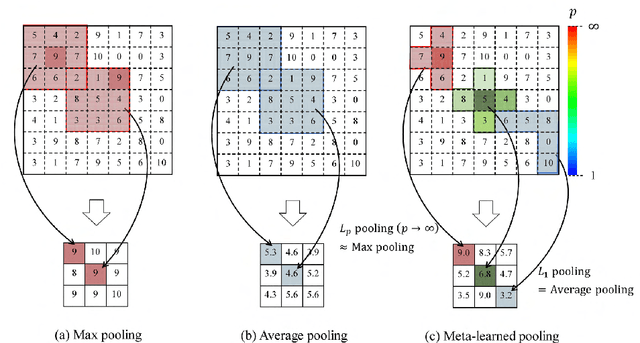
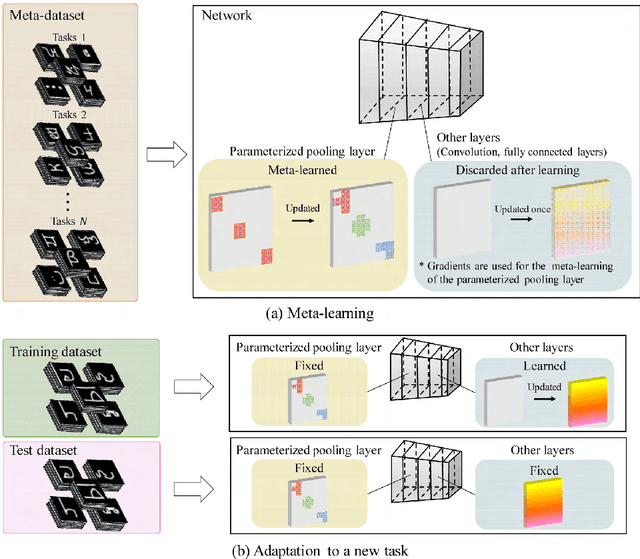
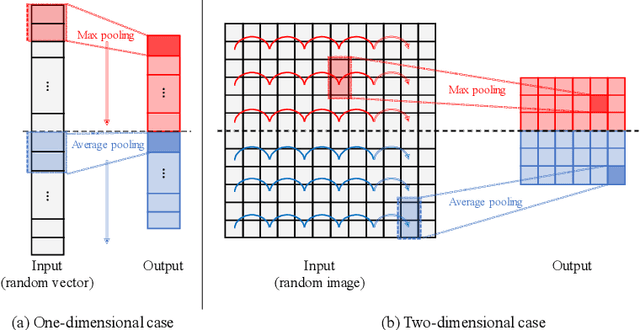
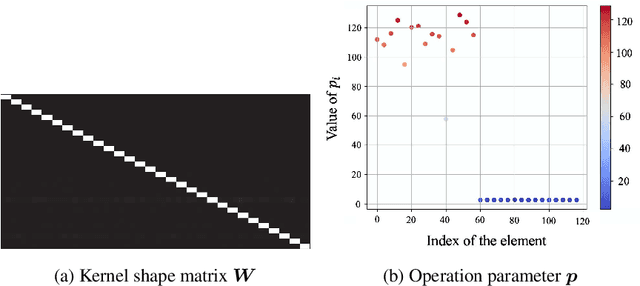
In convolutional neural network-based character recognition, pooling layers play an important role in dimensionality reduction and deformation compensation. However, their kernel shapes and pooling operations are empirically predetermined; typically, a fixed-size square kernel shape and max pooling operation are used. In this paper, we propose a meta-learning framework for pooling layers. As part of our framework, a parameterized pooling layer is proposed in which the kernel shape and pooling operation are trainable using two parameters, thereby allowing flexible pooling of the input data. We also propose a meta-learning algorithm for the parameterized pooling layer, which allows us to acquire a suitable pooling layer across multiple tasks. In the experiment, we applied the proposed meta-learning framework to character recognition tasks. The results demonstrate that a pooling layer that is suitable across character recognition tasks was obtained via meta-learning, and the obtained pooling layer improved the performance of the model in both few-shot character recognition and noisy image recognition tasks.
A HVS-inspired Attention Map to Improve CNN-based Perceptual Losses for Image Restoration
Mar 30, 2019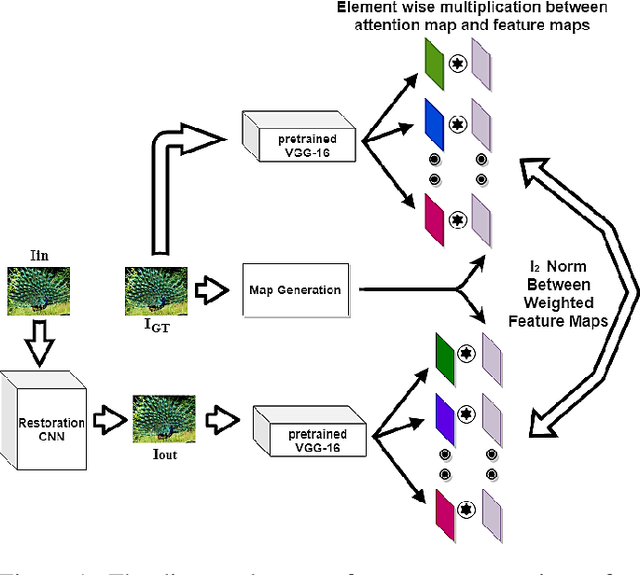
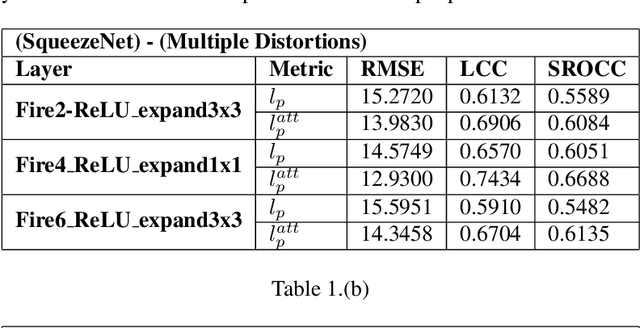
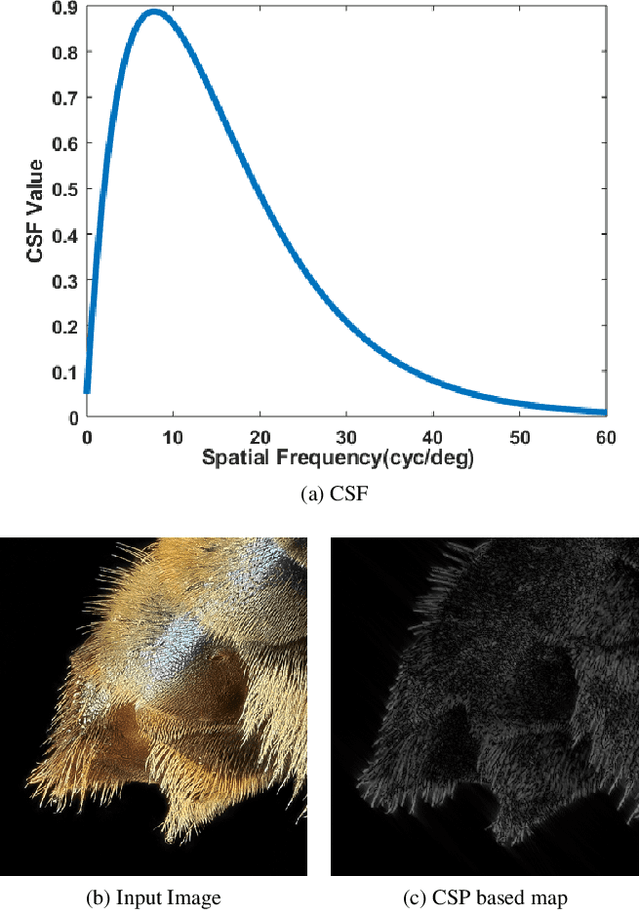
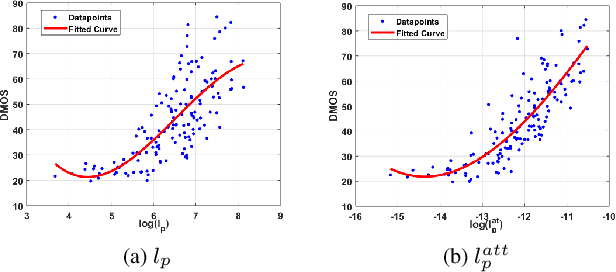
Deep Convolutional Neural Network (CNN) features have been demonstrated to be effective perceptual quality features. The perceptual loss, based on feature maps of pre-trained CNN's has proven to be remarkably effective for CNN based perceptual image restoration problems. In this work, taking inspiration from the the Human Visual System (HVS) and our visual perception, we propose a spatial attention mechanism based on the dependency human contrast sensitivity on spatial frequency. We identify regions in input images, based on underlying spatial frequency where the visual system might be most sensitive to distortions. Based on this prior, we design an attention map that is applied to feature maps in the perceptual loss, helping it to identify regions that are of more perceptual importance. The results will demonstrate that the proposed technique helps improving the correlation of the perceptual loss with human subjective assessment of perceptual quality and also results in a loss which delivers a better perception-distortion trade-off compared to the widely used perceptual loss in CNN based image restoration problems.
Verisimilar Image Synthesis for Accurate Detection and Recognition of Texts in Scenes
Sep 26, 2018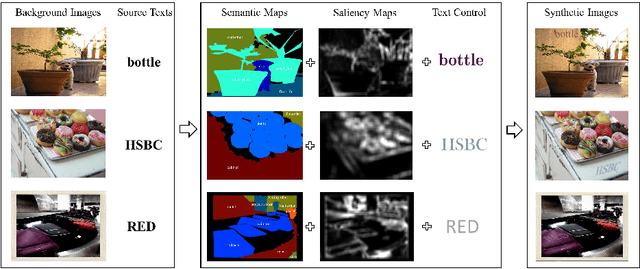
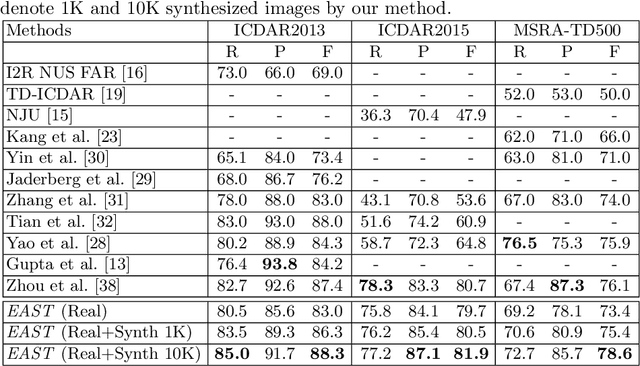

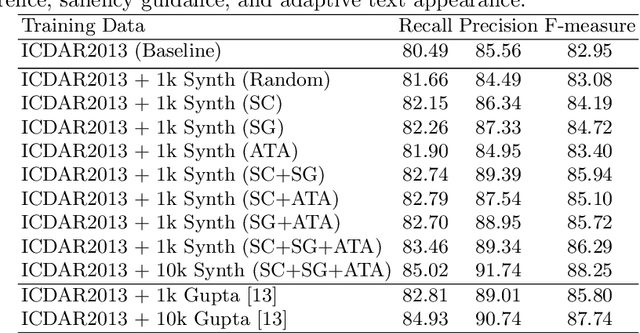
The requirement of large amounts of annotated images has become one grand challenge while training deep neural network models for various visual detection and recognition tasks. This paper presents a novel image synthesis technique that aims to generate a large amount of annotated scene text images for training accurate and robust scene text detection and recognition models. The proposed technique consists of three innovative designs. First, it realizes "semantic coherent" synthesis by embedding texts at semantically sensible regions within the background image, where the semantic coherence is achieved by leveraging the semantic annotations of objects and image regions that have been created in the prior semantic segmentation research. Second, it exploits visual saliency to determine the embedding locations within each semantic sensible region, which coincides with the fact that texts are often placed around homogeneous regions for better visibility in scenes. Third, it designs an adaptive text appearance model that determines the color and brightness of embedded texts by learning from the feature of real scene text images adaptively. The proposed technique has been evaluated over five public datasets and the experiments show its superior performance in training accurate and robust scene text detection and recognition models.
Astronomical image reconstruction with convolutional neural networks
Jun 07, 2017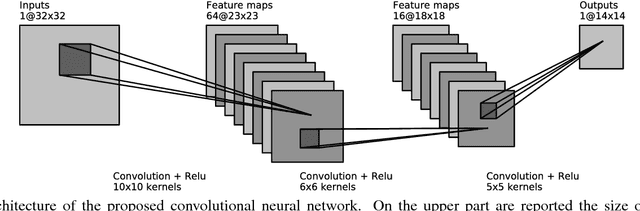
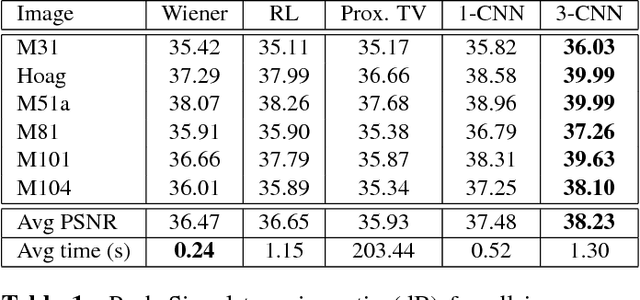


State of the art methods in astronomical image reconstruction rely on the resolution of a regularized or constrained optimization problem. Solving this problem can be computationally intensive and usually leads to a quadratic or at least superlinear complexity w.r.t. the number of pixels in the image. We investigate in this work the use of convolutional neural networks for image reconstruction in astronomy. With neural networks, the computationally intensive tasks is the training step, but the prediction step has a fixed complexity per pixel, i.e. a linear complexity. Numerical experiments show that our approach is both computationally efficient and competitive with other state of the art methods in addition to being interpretable.
Camera Bias in a Fine Grained Classification Task
Jul 16, 2020
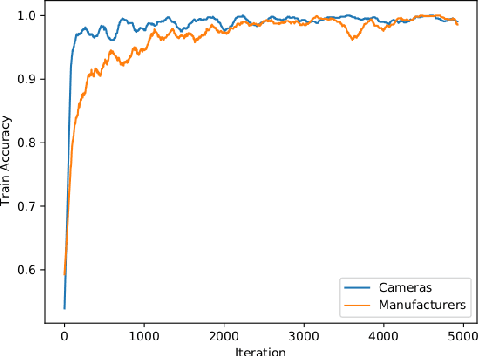
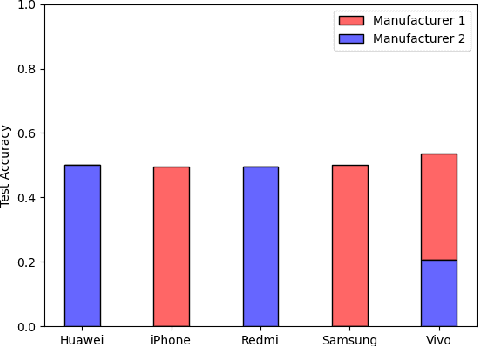
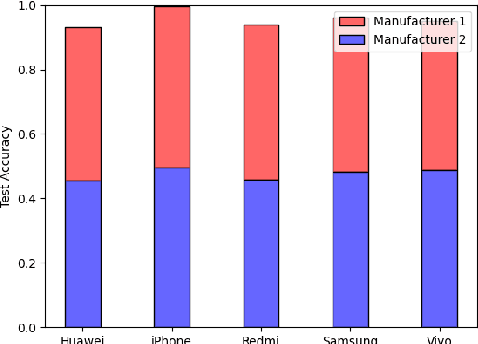
We show that correlations between the camera used to acquire an image and the class label of that image can be exploited by convolutional neural networks (CNN), resulting in a model that "cheats" at an image classification task by recognizing which camera took the image and inferring the class label from the camera. We show that models trained on a dataset with camera / label correlations do not generalize well to images in which those correlations are absent, nor to images from unencountered cameras. Furthermore, we investigate which visual features they are exploiting for camera recognition. Our experiments present evidence against the importance of global color statistics, lens deformation and chromatic aberration, and in favor of high frequency features, which may be introduced by image processing algorithms built into the cameras.
Attribute-Based Robotic Grasping with One-Grasp Adaptation
Apr 06, 2021
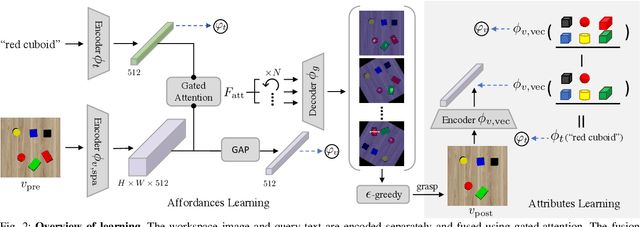


Robotic grasping is one of the most fundamental robotic manipulation tasks and has been actively studied. However, how to quickly teach a robot to grasp a novel target object in clutter remains challenging. This paper attempts to tackle the challenge by leveraging object attributes that facilitate recognition, grasping, and quick adaptation. In this work, we introduce an end-to-end learning method of attribute-based robotic grasping with one-grasp adaptation capability. Our approach fuses the embeddings of a workspace image and a query text using a gated-attention mechanism and learns to predict instance grasping affordances. Besides, we utilize object persistence before and after grasping to learn a joint metric space of visual and textual attributes. Our model is self-supervised in a simulation that only uses basic objects of various colors and shapes but generalizes to novel objects and real-world scenes. We further demonstrate that our model is capable of adapting to novel objects with only one grasp data and improving instance grasping performance significantly. Experimental results in both simulation and the real world demonstrate that our approach achieves over 80\% instance grasping success rate on unknown objects, which outperforms several baselines by large margins.