 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Augmentation-based Model Re-adaptation Framework for Robust Image Segmentation
Sep 14, 2024



Image segmentation is a crucial task in computer vision, with wide-ranging applications in industry. The Segment Anything Model (SAM) has recently attracted intensive attention; however, its application in industrial inspection, particularly for segmenting commercial anti-counterfeit codes, remains challenging. Unlike open-source datasets, industrial settings often face issues such as small sample sizes and complex textures. Additionally, computational cost is a key concern due to the varying number of trainable parameters. To address these challenges, we propose an Augmentation-based Model Re-adaptation Framework (AMRF). This framework leverages data augmentation techniques during training to enhance the generalisation of segmentation models, allowing them to adapt to newly released datasets with temporal disparity. By observing segmentation masks from conventional models (FCN and U-Net) and a pre-trained SAM model, we determine a minimal augmentation set that optimally balances training efficiency and model performance. Our results demonstrate that the fine-tuned FCN surpasses its baseline by 3.29% and 3.02% in cropping accuracy, and 5.27% and 4.04% in classification accuracy on two temporally continuous datasets. Similarly, the fine-tuned U-Net improves upon its baseline by 7.34% and 4.94% in cropping, and 8.02% and 5.52% in classification. Both models outperform the top-performing SAM models (ViT-Large and ViT-Base) by an average of 11.75% and 9.01% in cropping accuracy, and 2.93% and 4.83% in classification accuracy, respectively.
How Quality Affects Deep Neural Networks in Fine-Grained Image Classification
May 09, 2024



In this paper, we propose a No-Reference Image Quality Assessment (NRIQA) guided cut-off point selection (CPS) strategy to enhance the performance of a fine-grained classification system. Scores given by existing NRIQA methods on the same image may vary and not be as independent of natural image augmentations as expected, which weakens their connection and explainability to fine-grained image classification. Taking the three most commonly adopted image augmentation configurations -- cropping, rotating, and blurring -- as the entry point, we formulate a two-step mechanism for selecting the most discriminative subset from a given image dataset by considering both the confidence of model predictions and the density distribution of image qualities over several NRIQA methods. Concretely, the cut-off points yielded by those methods are aggregated via majority voting to inform the process of image subset selection. The efficacy and efficiency of such a mechanism have been confirmed by comparing the models being trained on high-quality images against a combination of high- and low-quality ones, with a range of 0.7% to 4.2% improvement on a commercial product dataset in terms of mean accuracy through four deep neural classifiers. The robustness of the mechanism has been proven by the observations that all the selected high-quality images can work jointly with 70% low-quality images with 1.3% of classification precision sacrificed when using ResNet34 in an ablation study.
Robust and Explainable Fine-Grained Visual Classification with Transfer Learning: A Dual-Carriageway Framework
May 09, 2024In the realm of practical fine-grained visual classification applications rooted in deep learning, a common scenario involves training a model using a pre-existing dataset. Subsequently, a new dataset becomes available, prompting the desire to make a pivotal decision for achieving enhanced and leveraged inference performance on both sides: Should one opt to train datasets from scratch or fine-tune the model trained on the initial dataset using the newly released dataset? The existing literature reveals a lack of methods to systematically determine the optimal training strategy, necessitating explainability. To this end, we present an automatic best-suit training solution searching framework, the Dual-Carriageway Framework (DCF), to fill this gap. DCF benefits from the design of a dual-direction search (starting from the pre-existing or the newly released dataset) where five different training settings are enforced. In addition, DCF is not only capable of figuring out the optimal training strategy with the capability of avoiding overfitting but also yields built-in quantitative and visual explanations derived from the actual input and weights of the trained model. We validated DCF's effectiveness through experiments with three convolutional neural networks (ResNet18, ResNet34 and Inception-v3) on two temporally continued commercial product datasets. Results showed fine-tuning pathways outperformed training-from-scratch ones by up to 2.13% and 1.23% on the pre-existing and new datasets, respectively, in terms of mean accuracy. Furthermore, DCF identified reflection padding as the superior padding method, enhancing testing accuracy by 3.72% on average. This framework stands out for its potential to guide the development of robust and explainable AI solutions in fine-grained visual classification tasks.
Robust 3D U-Net Segmentation of Macular Holes
Mar 01, 2021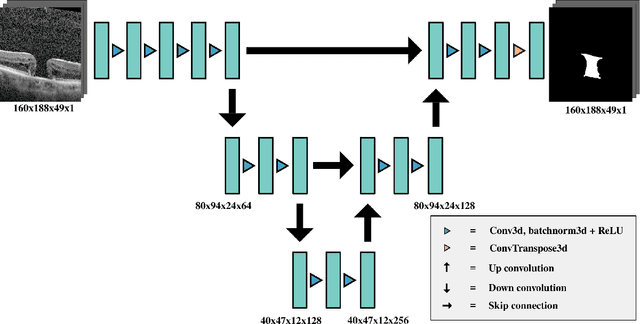
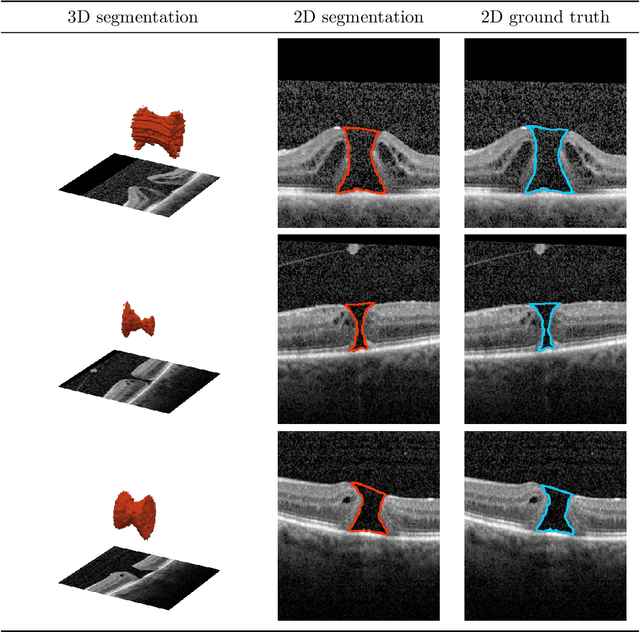

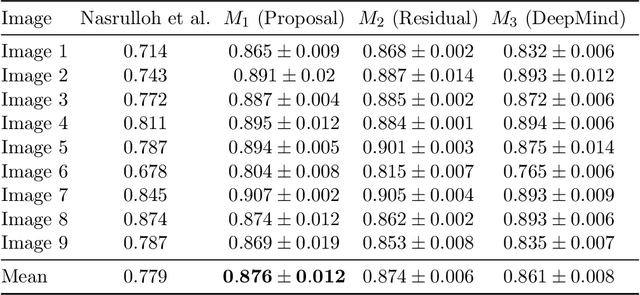
Macular holes are a common eye condition which result in visual impairment. We look at the application of deep convolutional neural networks to the problem of macular hole segmentation. We use the 3D U-Net architecture as a basis and experiment with a number of design variants. Manually annotating and measuring macular holes is time consuming and error prone. Previous automated approaches to macular hole segmentation take minutes to segment a single 3D scan. Our proposed model generates significantly more accurate segmentations in less than a second. We found that an approach of architectural simplification, by greatly simplifying the network capacity and depth, exceeds both expert performance and state-of-the-art models such as residual 3D U-Nets.
Not Half Bad: Exploring Half-Precision in Graph Convolutional Neural Networks
Oct 23, 2020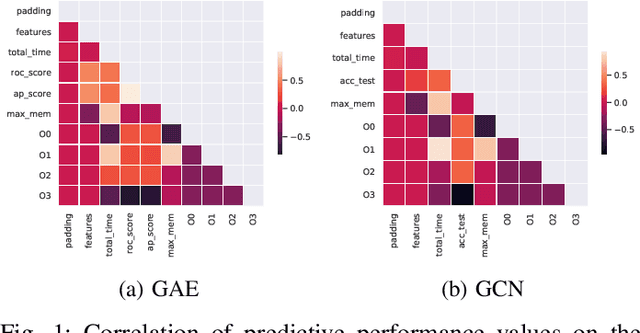
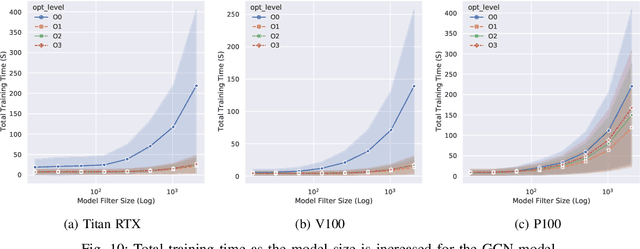
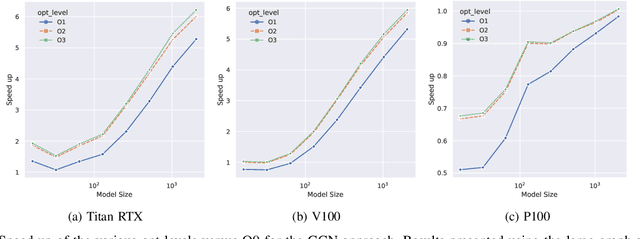

With the growing significance of graphs as an effective representation of data in numerous applications, efficient graph analysis using modern machine learning is receiving a growing level of attention. Deep learning approaches often operate over the entire adjacency matrix -- as the input and intermediate network layers are all designed in proportion to the size of the adjacency matrix -- leading to intensive computation and large memory requirements as the graph size increases. It is therefore desirable to identify efficient measures to reduce both run-time and memory requirements allowing for the analysis of the largest graphs possible. The use of reduced precision operations within the forward and backward passes of a deep neural network along with novel specialised hardware in modern GPUs can offer promising avenues towards efficiency. In this paper, we provide an in-depth exploration of the use of reduced-precision operations, easily integrable into the highly popular PyTorch framework, and an analysis of the effects of Tensor Cores on graph convolutional neural networks. We perform an extensive experimental evaluation of three GPU architectures and two widely-used graph analysis tasks (vertex classification and link prediction) using well-known benchmark and synthetically generated datasets. Thus allowing us to make important observations on the effects of reduced-precision operations and Tensor Cores on computational and memory usage of graph convolutional neural networks -- often neglected in the literature.
Camera Bias in a Fine Grained Classification Task
Jul 16, 2020
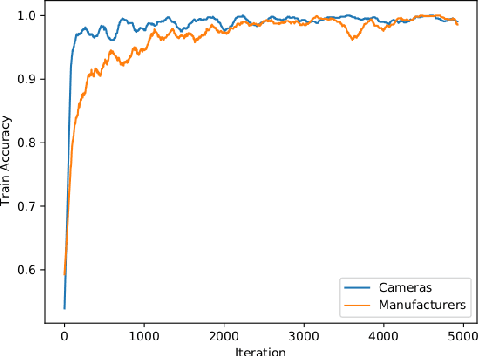
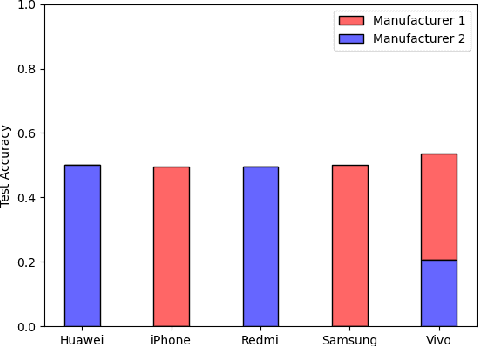
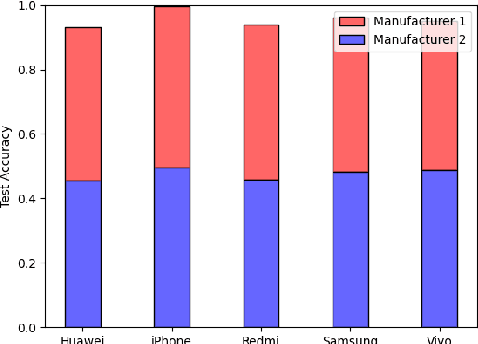
We show that correlations between the camera used to acquire an image and the class label of that image can be exploited by convolutional neural networks (CNN), resulting in a model that "cheats" at an image classification task by recognizing which camera took the image and inferring the class label from the camera. We show that models trained on a dataset with camera / label correlations do not generalize well to images in which those correlations are absent, nor to images from unencountered cameras. Furthermore, we investigate which visual features they are exploiting for camera recognition. Our experiments present evidence against the importance of global color statistics, lens deformation and chromatic aberration, and in favor of high frequency features, which may be introduced by image processing algorithms built into the cameras.
Segmentation of Macular Edema Datasets with Small Residual 3D U-Net Architectures
May 10, 2020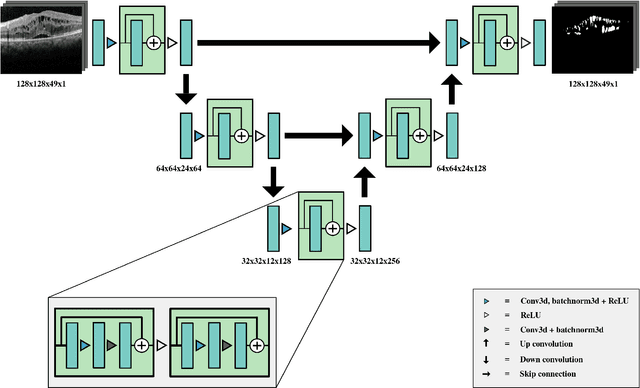


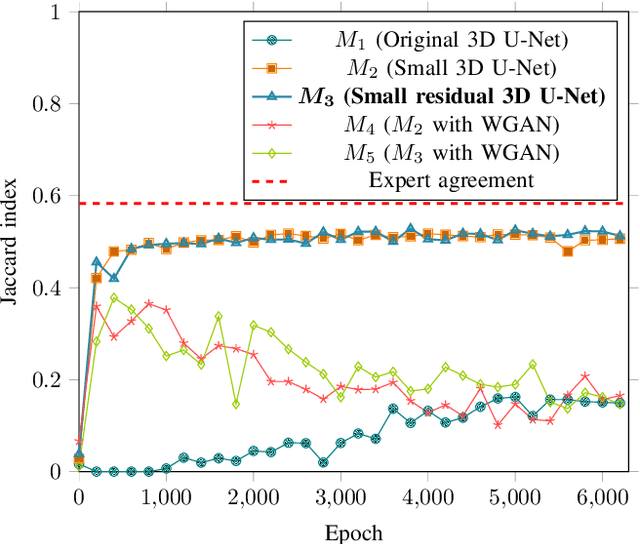
This paper investigates the application of deep convolutional neural networks with prohibitively small datasets to the problem of macular edema segmentation. In particular, we investigate several different heavily regularized architectures. We find that, contrary to popular belief, neural architectures within this application setting are able to achieve close to human-level performance on unseen test images without requiring large numbers of training examples. Annotating these 3D datasets is difficult, with multiple criteria required. It takes an experienced clinician two days to annotate a single 3D image, whereas our trained model achieves similar performance in less than a second. We found that an approach which uses targeted dataset augmentation, alongside architectural simplification with an emphasis on residual design, has acceptable generalization performance - despite relying on fewer than 15 training examples.
TMIXT: A process flow for Transcribing MIXed handwritten and machine-printed Text
Apr 28, 2019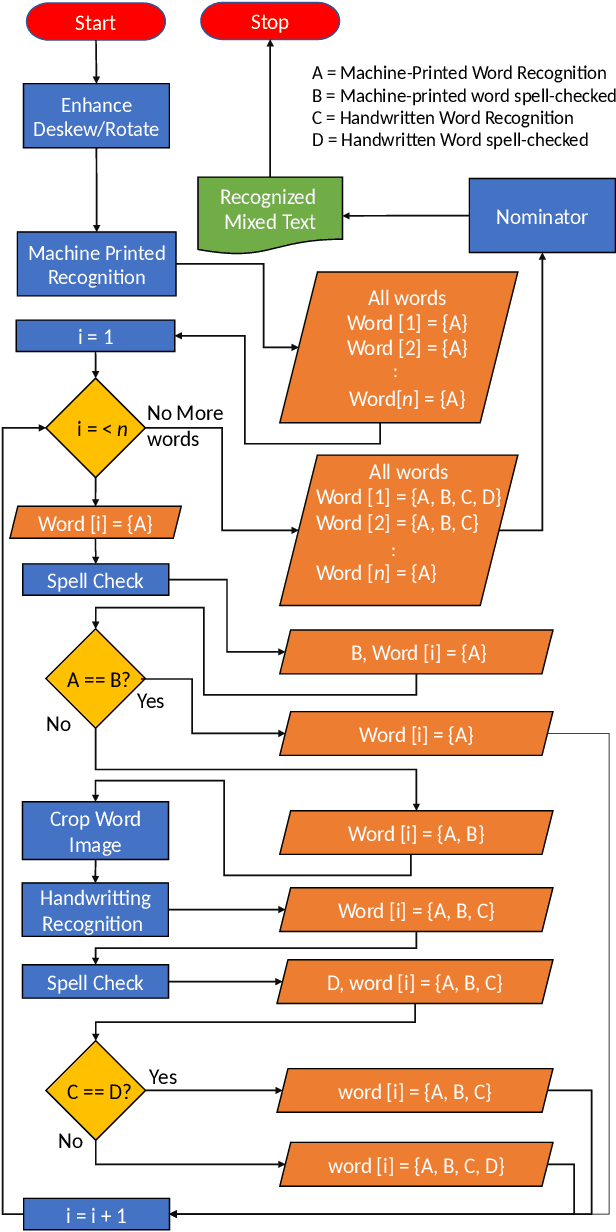



Handling large corpuses of documents is of significant importance in many fields, no more so than in the areas of crime investigation and defence, where an organisation may be presented with a large volume of scanned documents which need to be processed in a finite time. However, this problem is exacerbated both by the volume, in terms of scanned documents and the complexity of the pages, which need to be processed. Often containing many different elements, which each need to be processed and understood. Text recognition, which is a primary task of this process, is usually dependent upon the type of text, being either handwritten or machine-printed. Accordingly, the recognition involves prior classification of the text category, before deciding on the recognition method to be applied. This poses a more challenging task if a document contains both handwritten and machine-printed text. In this work, we present a generic process flow for text recognition in scanned documents containing mixed handwritten and machine-printed text without the need to classify text in advance. We realize the proposed process flow using several open-source image processing and text recognition packages1. The evaluation is performed using a specially developed variant, presented in this work, of the IAM handwriting database, where we achieve an average transcription accuracy of nearly 80% for pages containing both printed and handwritten text.
* big data, unstructured data, Optical Character Recognition (OCR), Handwritten Text Recognition (HTR), machine-printed text recognition, IAM handwriting database, TMIXT
Phenotypic Profiling of High Throughput Imaging Screens with Generic Deep Convolutional Features
Mar 15, 2019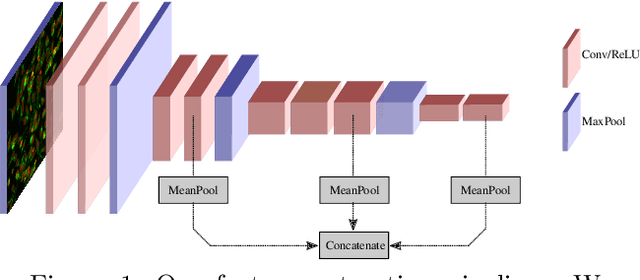

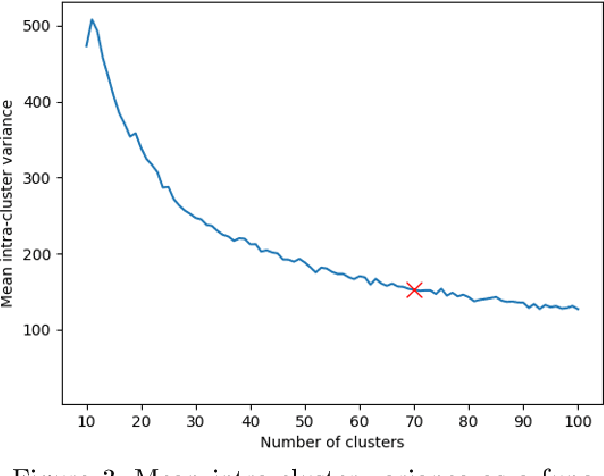
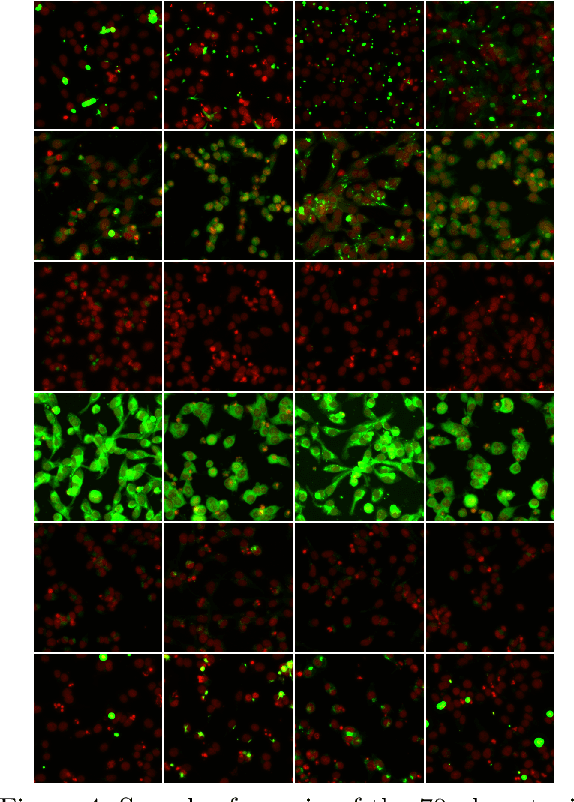
While deep learning has seen many recent applications to drug discovery, most have focused on predicting activity or toxicity directly from chemical structure. Phenotypic changes exhibited in cellular images are also indications of the mechanism of action (MoA) of chemical compounds. In this paper, we show how pre-trained convolutional image features can be used to assist scientists in discovering interesting chemical clusters for further investigation. Our method reduces the dimensionality of raw fluorescent stained images from a high throughput imaging (HTI) screen, producing an embedding space that groups together images with similar cellular phenotypes. Running standard unsupervised clustering on this embedding space yields a set of distinct phenotypic clusters. This allows scientists to further select and focus on interesting clusters for downstream analyses. We validate the consistency of our embedding space qualitatively with t-sne visualizations, and quantitatively by measuring embedding variance among images that are known to be similar. Results suggested the usefulness of our proposed workflow using deep learning and clustering and it can lead to robust HTI screening and compound triage.
2D and 3D Vascular Structures Enhancement via Multiscale Fractional Anisotropy Tensor
Feb 01, 2019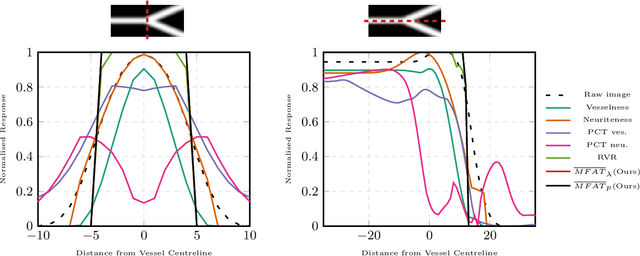
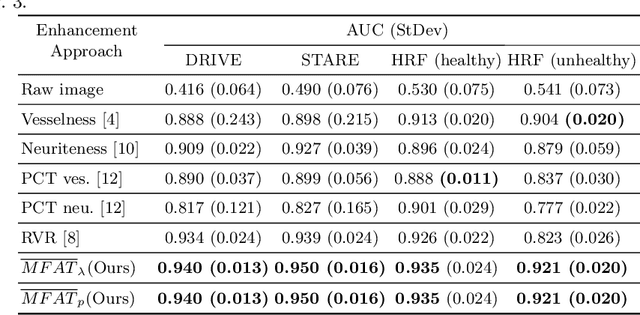
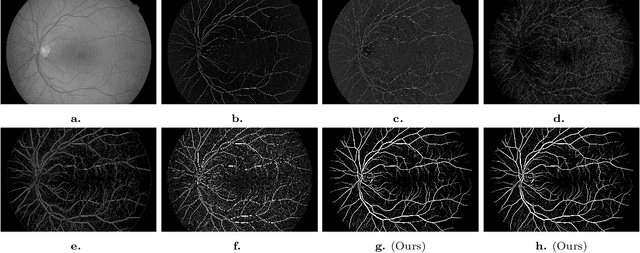
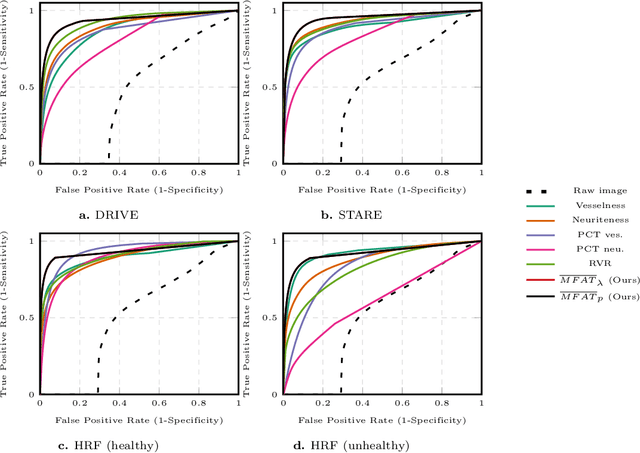
The detection of vascular structures from noisy images is a fundamental process for extracting meaningful information in many applications. Most well-known vascular enhancing techniques often rely on Hessian-based filters. This paper investigates the feasibility and deficiencies of detecting curve-like structures using a Hessian matrix. The main contribution is a novel enhancement function, which overcomes the deficiencies of established methods. Our approach has been evaluated quantitatively and qualitatively using synthetic examples and a wide range of real 2D and 3D biomedical images. Compared with other existing approaches, the experimental results prove that our proposed approach achieves high-quality curvilinear structure enhancement.