 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fine-Grained Grounding for Multimodal Speech Recognition
Oct 05, 2020
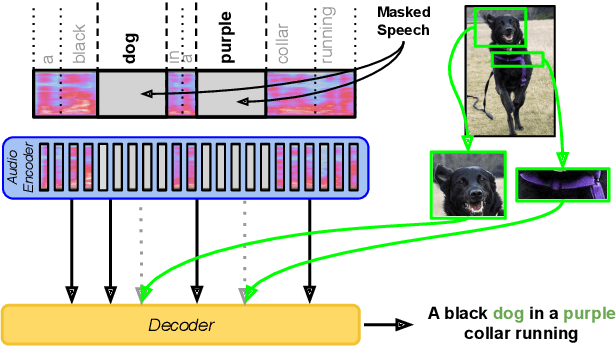
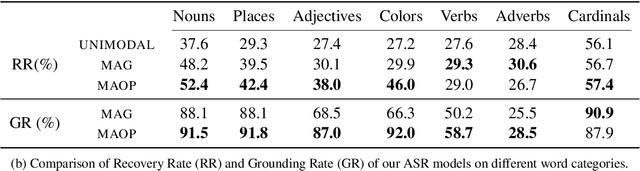
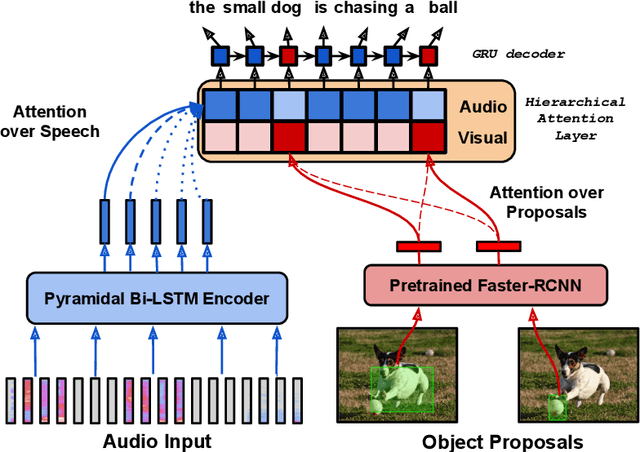
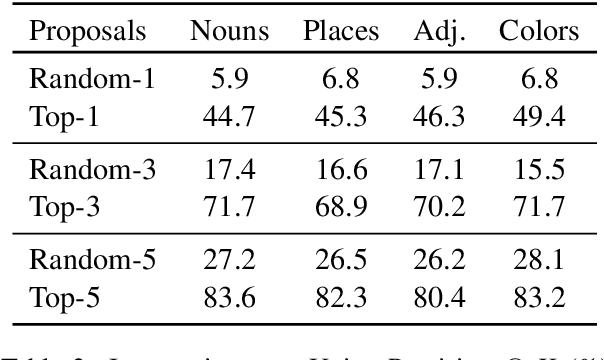
Multimodal automatic speech recognition systems integrate information from images to improve speech recognition quality, by grounding the speech in the visual context. While visual signals have been shown to be useful for recovering entities that have been masked in the audio, these models should be capable of recovering a broader range of word types. Existing systems rely on global visual features that represent the entire image, but localizing the relevant regions of the image will make it possible to recover a larger set of words, such as adjectives and verbs. In this paper, we propose a model that uses finer-grained visual information from different parts of the image, using automatic object proposals. In experiments on the Flickr8K Audio Captions Corpus, we find that our model improves over approaches that use global visual features, that the proposals enable the model to recover entities and other related words, such as adjectives, and that improvements are due to the model's ability to localize the correct proposals.
Design of optimal illumination patterns in single-pixel imaging using image dictionaries
Jun 04, 2018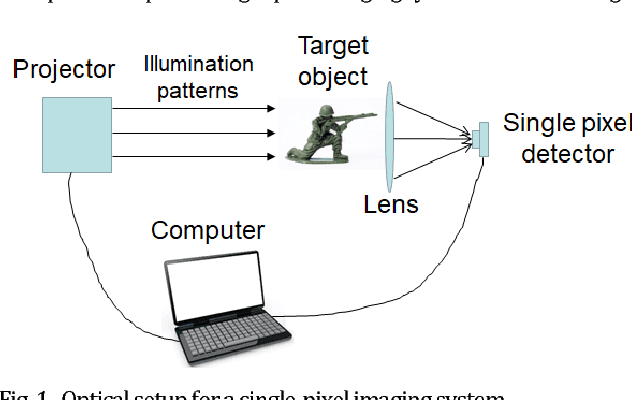
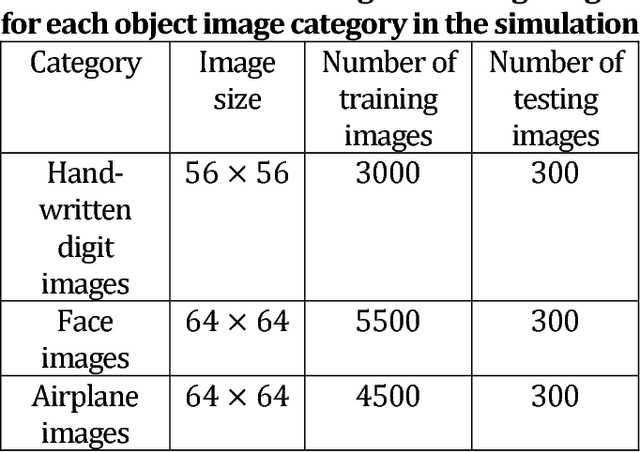


Single-pixel imaging (SPI) has a major drawback that the huge number of sequential illuminations for capturing one single image requires long acquisition time and high cost. Basis illumination patterns such as sinusoidal patterns in Fourier transform and Hadamard patterns are employed to enhance the imaging efficiency. The basis illumination patterns can achieve much better efficiency than random intensity illumination patterns but the performance is still sub-optimal since the basis patterns are fixed and non-adaptive for varying object images. In this work, we propose a novel scheme to design the illumination patterns adaptively when SPI is applied in a specific and pre-known imaging scenario. Exemplar training images belonging to the target specific category of object images are collected and an image dictionary is constructed in advance. Then the optimized illumination patterns are designed by extracting the common image features from the image dictionary using principal component analysis. Simulation results reveal that our proposed scheme outperforms conventional Fourier single-pixel imaging in terms of imaging efficiency.
Block-wise Image Transformation with Secret Key for Adversarially Robust Defense
Oct 02, 2020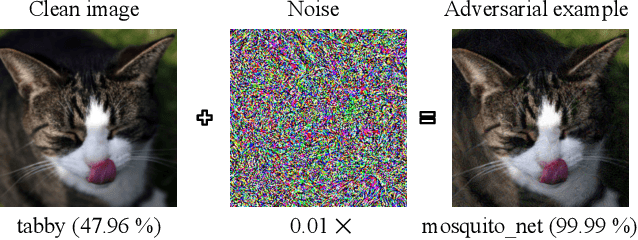
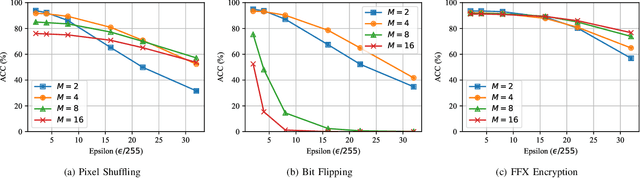
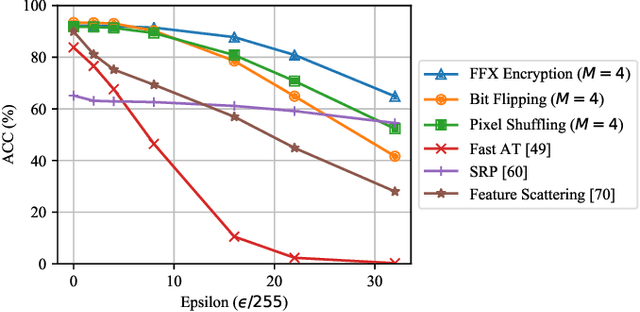
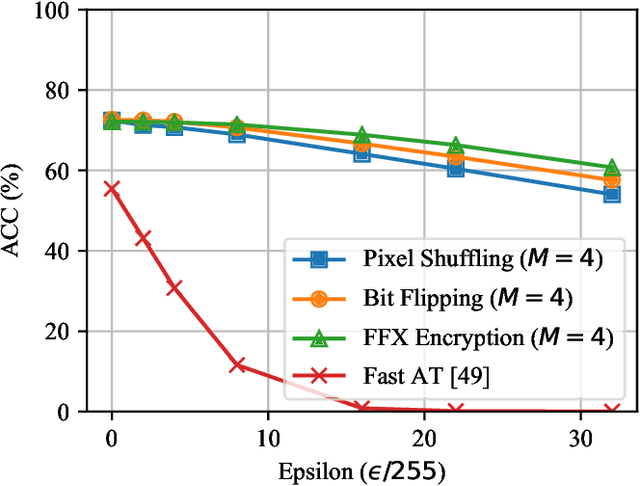
In this paper, we propose a novel defensive transformation that enables us to maintain a high classification accuracy under the use of both clean images and adversarial examples for adversarially robust defense. The proposed transformation is a block-wise preprocessing technique with a secret key to input images. We developed three algorithms to realize the proposed transformation: Pixel Shuffling, Bit Flipping, and FFX Encryption. Experiments were carried out on the CIFAR-10 and ImageNet datasets by using both black-box and white-box attacks with various metrics including adaptive ones. The results show that the proposed defense achieves high accuracy close to that of using clean images even under adaptive attacks for the first time. In the best-case scenario, a model trained by using images transformed by FFX Encryption (block size of 4) yielded an accuracy of 92.30% on clean images and 91.48% under PGD attack with a noise distance of 8/255, which is close to the non-robust accuracy (95.45%) for the CIFAR-10 dataset, and it yielded an accuracy of 72.18% on clean images and 71.43% under the same attack, which is also close to the standard accuracy (73.70%) for the ImageNet dataset. Overall, all three proposed algorithms are demonstrated to outperform state-of-the-art defenses including adversarial training whether or not a model is under attack.
Fine-tuning Handwriting Recognition systems with Temporal Dropout
Jan 31, 2021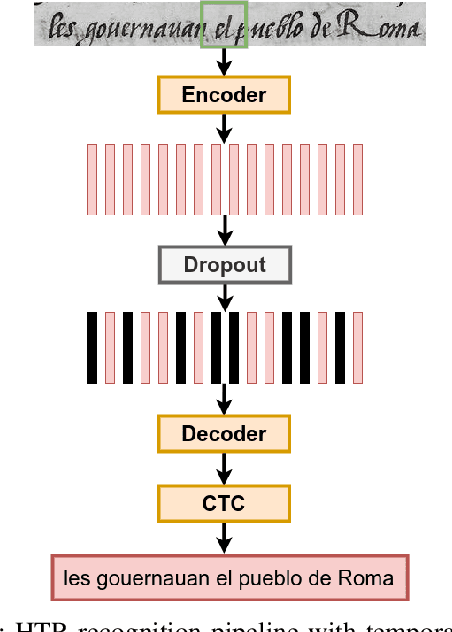
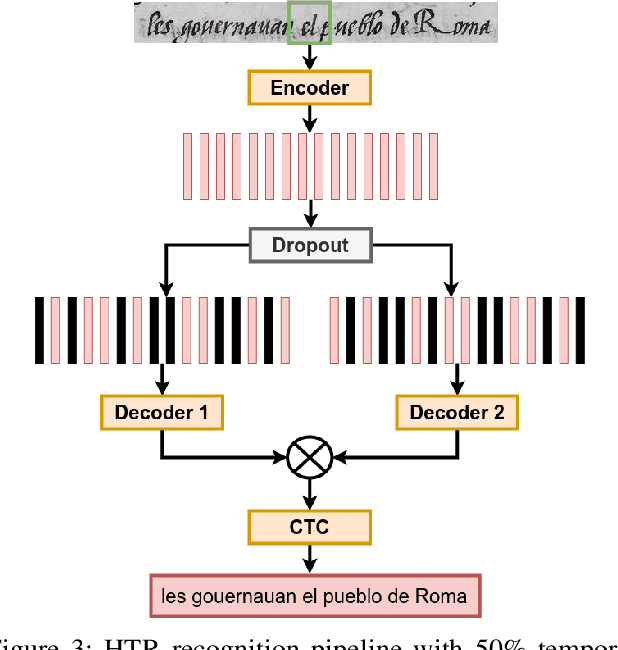
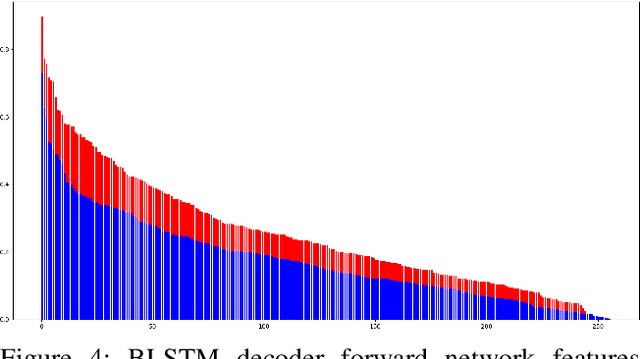
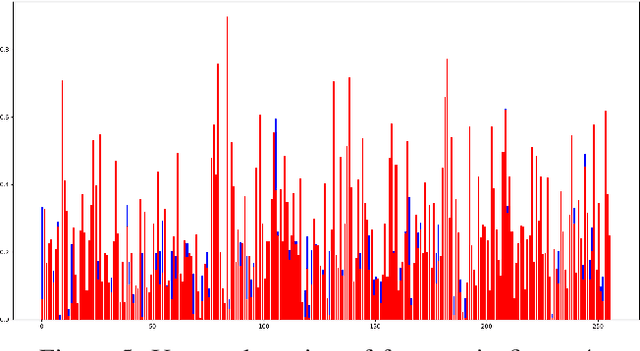
This paper introduces a novel method to fine-tune handwriting recognition systems based on Recurrent Neural Networks (RNN). Long Short-Term Memory (LSTM) networks are good at modeling long sequences but they tend to overfit over time. To improve the system's ability to model sequences, we propose to drop information at random positions in the sequence. We call our approach Temporal Dropout (TD). We apply TD at the image level as well to internal network representation. We show that TD improves the results on two different datasets. Our method outperforms previous state-of-the-art on Rodrigo dataset.
A Review on Deep Learning in UAV Remote Sensing
Jan 22, 2021

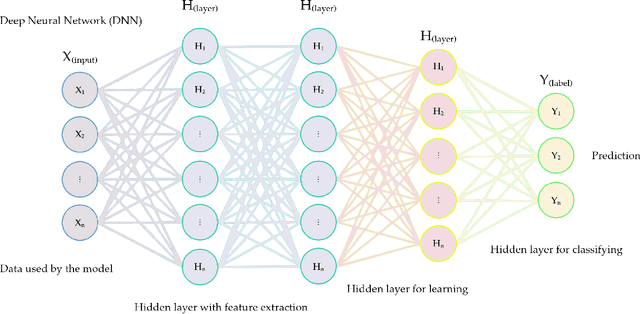
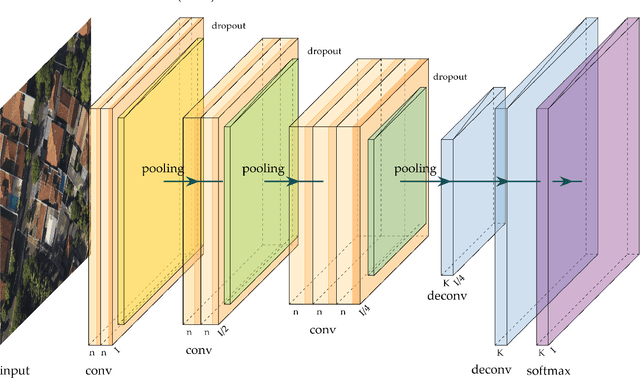
Deep Neural Networks (DNNs) learn representation from data with an impressive capability, and brought important breakthroughs for processing images, time-series, natural language, audio, video, and many others. In the remote sensing field, surveys and literature revisions specifically involving DNNs algorithms' applications have been conducted in an attempt to summarize the amount of information produced in its subfields. Recently, Unmanned Aerial Vehicles (UAV) based applications have dominated aerial sensing research. However, a literature revision that combines both "deep learning" and "UAV remote sensing" thematics has not yet been conducted. The motivation for our work was to present a comprehensive review of the fundamentals of Deep Learning (DL) applied in UAV-based imagery. We focused mainly on describing classification and regression techniques used in recent applications with UAV-acquired data. For that, a total of 232 papers published in international scientific journal databases was examined. We gathered the published material and evaluated their characteristics regarding application, sensor, and technique used. We relate how DL presents promising results and has the potential for processing tasks associated with UAV-based image data. Lastly, we project future perspectives, commentating on prominent DL paths to be explored in the UAV remote sensing field. Our revision consists of a friendly-approach to introduce, commentate, and summarize the state-of-the-art in UAV-based image applications with DNNs algorithms in diverse subfields of remote sensing, grouping it in the environmental, urban, and agricultural contexts.
I2T2I: Learning Text to Image Synthesis with Textual Data Augmentation
Jun 03, 2017
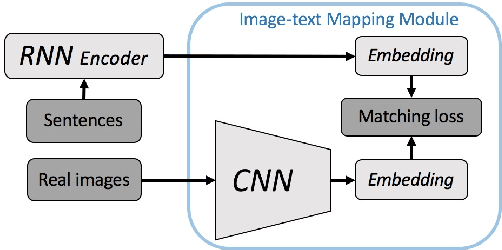
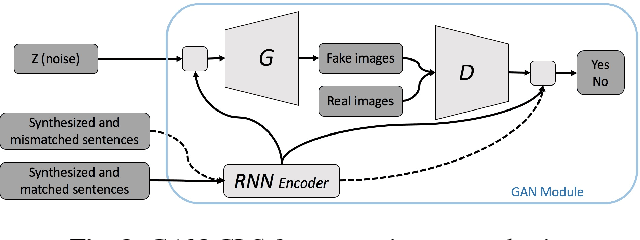
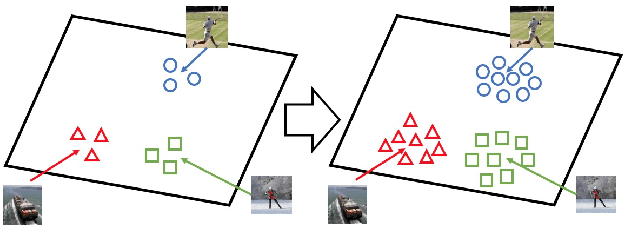
Translating information between text and image is a fundamental problem in artificial intelligence that connects natural language processing and computer vision. In the past few years, performance in image caption generation has seen significant improvement through the adoption of recurrent neural networks (RNN). Meanwhile, text-to-image generation begun to generate plausible images using datasets of specific categories like birds and flowers. We've even seen image generation from multi-category datasets such as the Microsoft Common Objects in Context (MSCOCO) through the use of generative adversarial networks (GANs). Synthesizing objects with a complex shape, however, is still challenging. For example, animals and humans have many degrees of freedom, which means that they can take on many complex shapes. We propose a new training method called Image-Text-Image (I2T2I) which integrates text-to-image and image-to-text (image captioning) synthesis to improve the performance of text-to-image synthesis. We demonstrate that %the capability of our method to understand the sentence descriptions, so as to I2T2I can generate better multi-categories images using MSCOCO than the state-of-the-art. We also demonstrate that I2T2I can achieve transfer learning by using a pre-trained image captioning module to generate human images on the MPII Human Pose
Fusion of Deep and Non-Deep Methods for Fast Super-Resolution of Satellite Images
Aug 03, 2020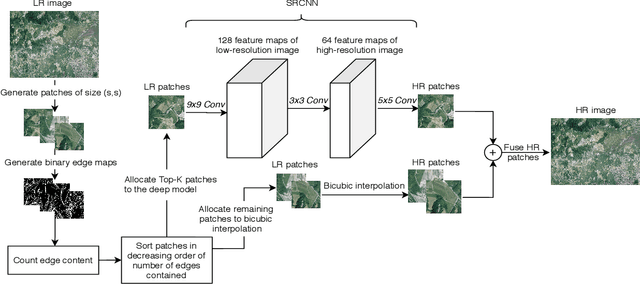
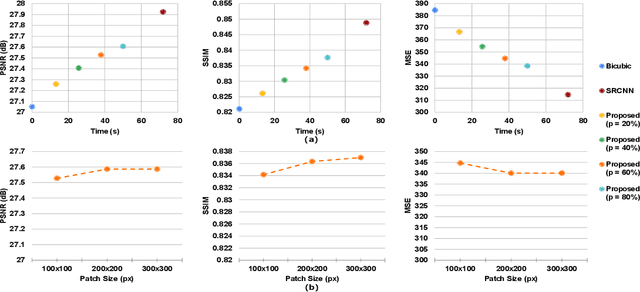

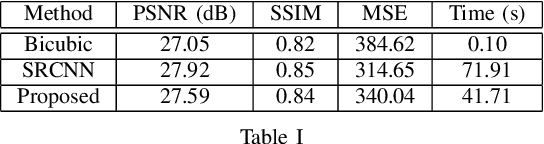
In the emerging commercial space industry there is a drastic increase in access to low cost satellite imagery. The price for satellite images depends on the sensor quality and revisit rate. This work proposes to bridge the gap between image quality and the price by improving the image quality via super-resolution (SR). Recently, a number of deep SR techniques have been proposed to enhance satellite images. However, none of these methods utilize the region-level context information, giving equal importance to each region in the image. This, along with the fact that most state-of-the-art SR methods are complex and cumbersome deep models, the time taken to process very large satellite images can be impractically high. We, propose to handle this challenge by designing an SR framework that analyzes the regional information content on each patch of the low-resolution image and judiciously chooses to use more computationally complex deep models to super-resolve more structure-rich regions on the image, while using less resource-intensive non-deep methods on non-salient regions. Through extensive experiments on a large satellite image, we show substantial decrease in inference time while achieving similar performance to that of existing deep SR methods over several evaluation measures like PSNR, MSE and SSIM.
Self-Supervised Adaptation for Video Super-Resolution
Mar 18, 2021
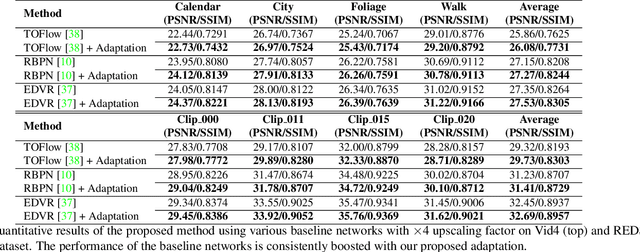
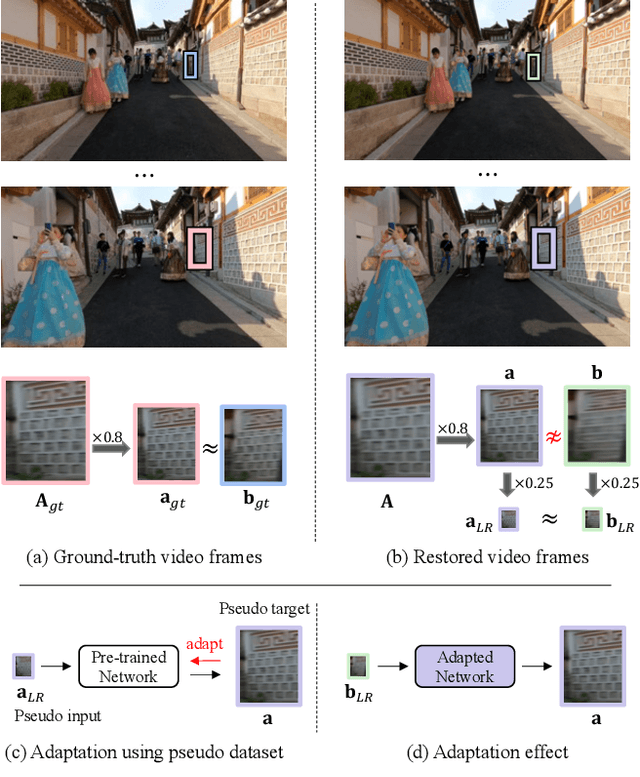
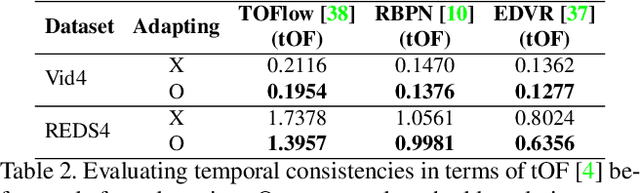
Recent single-image super-resolution (SISR) networks, which can adapt their network parameters to specific input images, have shown promising results by exploiting the information available within the input data as well as large external datasets. However, the extension of these self-supervised SISR approaches to video handling has yet to be studied. Thus, we present a new learning algorithm that allows conventional video super-resolution (VSR) networks to adapt their parameters to test video frames without using the ground-truth datasets. By utilizing many self-similar patches across space and time, we improve the performance of fully pre-trained VSR networks and produce temporally consistent video frames. Moreover, we present a test-time knowledge distillation technique that accelerates the adaptation speed with less hardware resources. In our experiments, we demonstrate that our novel learning algorithm can fine-tune state-of-the-art VSR networks and substantially elevate performance on numerous benchmark datasets.
Learning Discriminative Multilevel Structured Dictionaries for Supervised Image Classification
Feb 28, 2018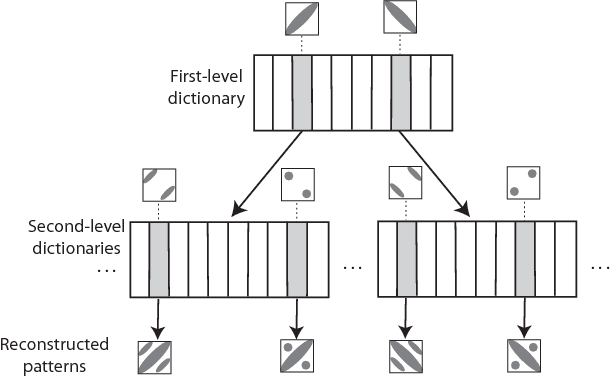


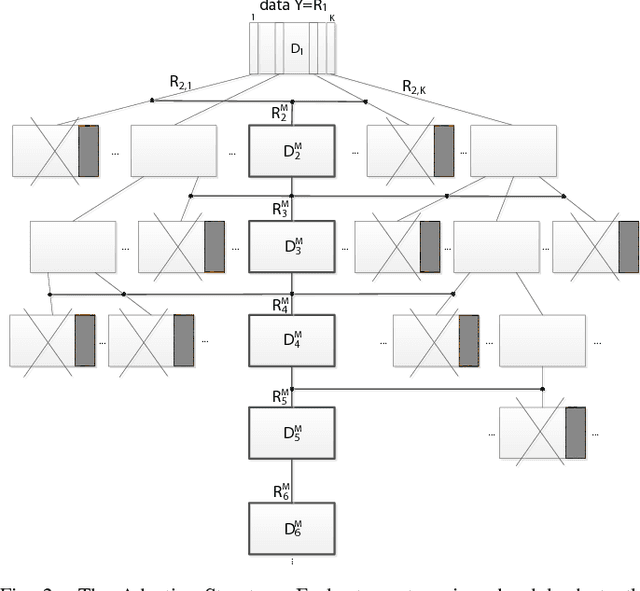
Sparse representations using overcomplete dictionaries have proved to be a powerful tool in many signal processing applications such as denoising, super-resolution, inpainting, compression or classification. The sparsity of the representation very much depends on how well the dictionary is adapted to the data at hand. In this paper, we propose a method for learning structured multilevel dictionaries with discriminative constraints to make them well suited for the supervised pixelwise classification of images. A multilevel tree-structured discriminative dictionary is learnt for each class, with a learning objective concerning the reconstruction errors of the image patches around the pixels over each class-representative dictionary. After the initial assignment of the class labels to image pixels based on their sparse representations over the learnt dictionaries, the final classification is achieved by smoothing the label image with a graph cut method and an erosion method. Applied to a common set of texture images, our supervised classification method shows competitive results with the state of the art.
Meta Faster R-CNN: Towards Accurate Few-Shot Object Detection with Attentive Feature Alignment
Apr 15, 2021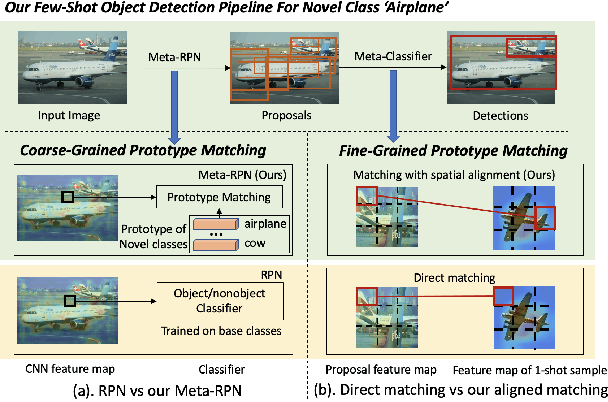
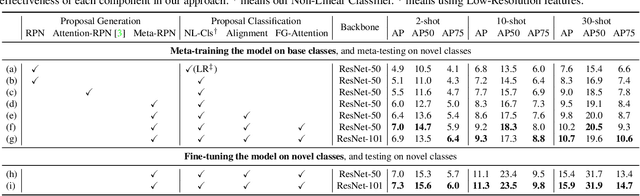
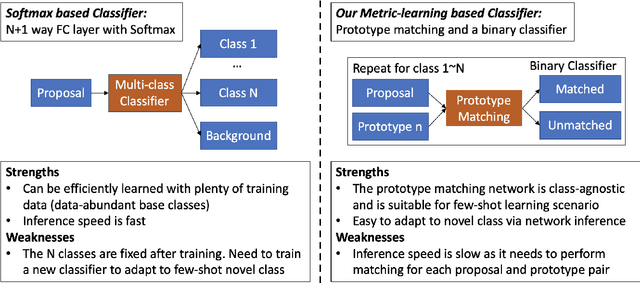
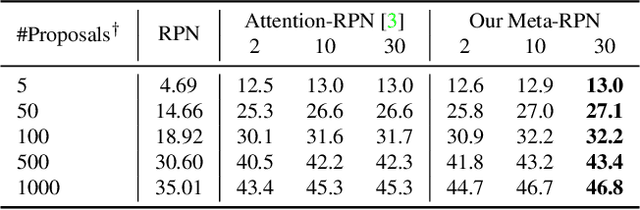
Few-shot object detection (FSOD) aims to detect objects using only few examples. It's critically needed for many practical applications but so far remains challenging. We propose a meta-learning based few-shot object detection method by transferring meta-knowledge learned from data-abundant base classes to data-scarce novel classes. Our method incorporates a coarse-to-fine approach into the proposal based object detection framework and integrates prototype based classifiers into both the proposal generation and classification stages. To improve proposal generation for few-shot novel classes, we propose to learn a lightweight matching network to measure the similarity between each spatial position in the query image feature map and spatially-pooled class features, instead of the traditional object/nonobject classifier, thus generating category-specific proposals and improving proposal recall for novel classes. To address the spatial misalignment between generated proposals and few-shot class examples, we propose a novel attentive feature alignment method, thus improving the performance of few-shot object detection. Meanwhile we jointly learn a Faster R-CNN detection head for base classes. Extensive experiments conducted on multiple FSOD benchmarks show our proposed approach achieves state of the art results under (incremental) few-shot learning settings.