 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSleepWalk: A Three-Tier Benchmark for Stress-Testing Instruction-Guided Vision-Language Navigation
May 11, 2026Vision-Language Models (VLMs) have advanced rapidly in multimodal perception and language understanding, yet it remains unclear whether they can reliably ground language into spatially coherent, plausibly executable actions in 3D digital environments. We introduce SleepWalk, a benchmark for evaluating instruction-grounded trajectory prediction in single-scene 3D worlds generated from textual scene descriptions and filtered for navigability. Unlike prior navigation benchmarks centered on long-range exploration across rooms, SleepWalk targets localized, interaction-centric embodied reasoning: given rendered visual observations and a natural-language instruction, a model must predict a trajectory that respects scene geometry, avoids collisions, and terminates at an action-compatible location. The benchmark covers diverse indoor and outdoor environments and organizes tasks into three tiers of spatial and temporal difficulty, enabling fine-grained analysis of grounding under increasing compositional complexity. Using a standardized pointwise judge-based evaluation protocol, we evaluate three frontier VLMs on 2,472 curated 3D environments with nine instructions per scene. Results reveal systematic failures in grounded spatial reasoning, especially under occlusion, interaction constraints, and multi-step instructions: performance drops as the difficulty level of the tasks increase. In general, current VLMs can somewhat produce trajectories that are simultaneously spatially coherent, plausibly executable, and aligned with intended actions. By exposing failures in a controlled yet scalable setting, SleepWalk provides a critical benchmark for advancing grounded multimodal reasoning, embodied planning, vision-language navigation, and action-capable agents in 3D environments.
Conditional Distributional Treatment Effects: Doubly Robust Estimation and Testing
Mar 17, 2026Beyond conditional average treatment effects, treatments may impact the entire outcome distribution in covariate-dependent ways, for example, by altering the variance or tail risks for specific subpopulations. We propose a novel estimand to capture such conditional distributional treatment effects, and develop a doubly robust estimator that is minimax optimal in the local asymptotic sense. Using this, we develop a test for the global homogeneity of conditional potential outcome distributions that accommodates discrepancies beyond the maximum mean discrepancy (MMD), has provably valid type 1 error, and is consistent against fixed alternatives -- the first test, to our knowledge, with such guarantees in this setting. Furthermore, we derive exact closed-form expressions for two natural discrepancies (including the MMD), and provide a computationally efficient, permutation-free algorithm for our test.
Data Impressions: Mining Deep Models to Extract Samples for Data-free Applications
Jan 15, 2021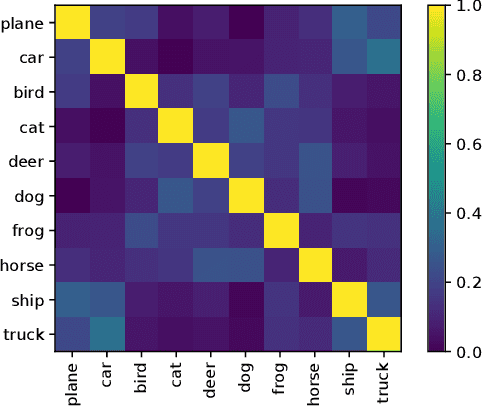
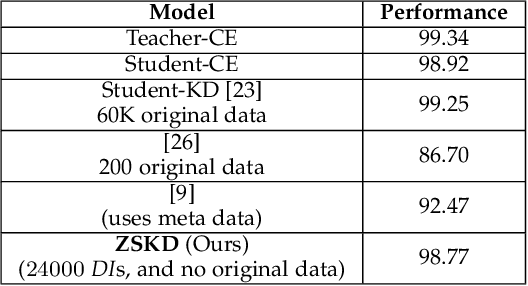

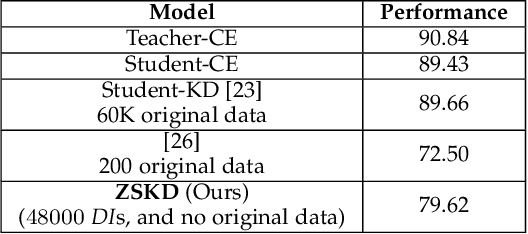
Pretrained deep models hold their learnt knowledge in the form of the model parameters. These parameters act as memory for the trained models and help them generalize well on unseen data. However, in absence of training data, the utility of a trained model is merely limited to either inference or better initialization towards a target task. In this paper, we go further and extract synthetic data by leveraging the learnt model parameters. We dub them "Data Impressions", which act as proxy to the training data and can be used to realize a variety of tasks. These are useful in scenarios where only the pretrained models are available and the training data is not shared (e.g., due to privacy or sensitivity concerns). We show the applicability of data impressions in solving several computer vision tasks such as unsupervised domain adaptation, continual learning as well as knowledge distillation. We also study the adversarial robustness of the lightweight models trained via knowledge distillation using these data impressions. Further, we demonstrate the efficacy of data impressions in generating UAPs with better fooling rates. Extensive experiments performed on several benchmark datasets demonstrate competitive performance achieved using data impressions in absence of the original training data.
Fusion of Deep and Non-Deep Methods for Fast Super-Resolution of Satellite Images
Aug 03, 2020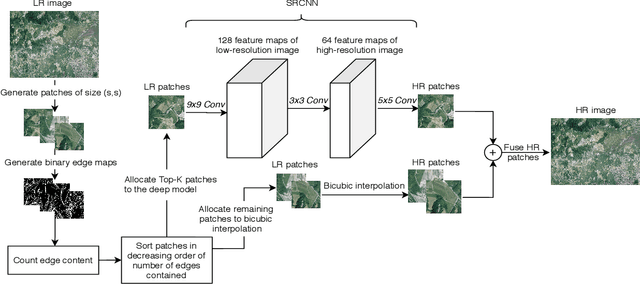
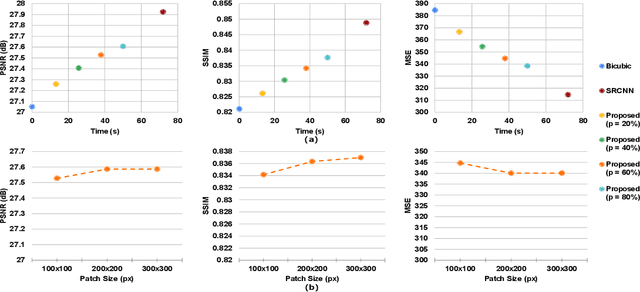

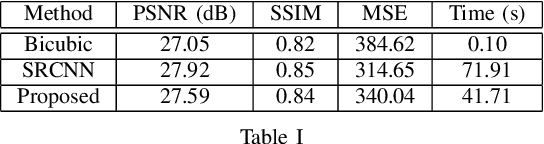
In the emerging commercial space industry there is a drastic increase in access to low cost satellite imagery. The price for satellite images depends on the sensor quality and revisit rate. This work proposes to bridge the gap between image quality and the price by improving the image quality via super-resolution (SR). Recently, a number of deep SR techniques have been proposed to enhance satellite images. However, none of these methods utilize the region-level context information, giving equal importance to each region in the image. This, along with the fact that most state-of-the-art SR methods are complex and cumbersome deep models, the time taken to process very large satellite images can be impractically high. We, propose to handle this challenge by designing an SR framework that analyzes the regional information content on each patch of the low-resolution image and judiciously chooses to use more computationally complex deep models to super-resolve more structure-rich regions on the image, while using less resource-intensive non-deep methods on non-salient regions. Through extensive experiments on a large satellite image, we show substantial decrease in inference time while achieving similar performance to that of existing deep SR methods over several evaluation measures like PSNR, MSE and SSIM.