 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirrorVerse: Pushing Diffusion Models to Realistically Reflect the World
Apr 21, 2025Diffusion models have become central to various image editing tasks, yet they often fail to fully adhere to physical laws, particularly with effects like shadows, reflections, and occlusions. In this work, we address the challenge of generating photorealistic mirror reflections using diffusion-based generative models. Despite extensive training data, existing diffusion models frequently overlook the nuanced details crucial to authentic mirror reflections. Recent approaches have attempted to resolve this by creating synhetic datasets and framing reflection generation as an inpainting task; however, they struggle to generalize across different object orientations and positions relative to the mirror. Our method overcomes these limitations by introducing key augmentations into the synthetic data pipeline: (1) random object positioning, (2) randomized rotations, and (3) grounding of objects, significantly enhancing generalization across poses and placements. To further address spatial relationships and occlusions in scenes with multiple objects, we implement a strategy to pair objects during dataset generation, resulting in a dataset robust enough to handle these complex scenarios. Achieving generalization to real-world scenes remains a challenge, so we introduce a three-stage training curriculum to develop the MirrorFusion 2.0 model to improve real-world performance. We provide extensive qualitative and quantitative evaluations to support our approach. The project page is available at: https://mirror-verse.github.io/.
Turbo-GS: Accelerating 3D Gaussian Fitting for High-Quality Radiance Fields
Dec 18, 2024



Novel-view synthesis is an important problem in computer vision with applications in 3D reconstruction, mixed reality, and robotics. Recent methods like 3D Gaussian Splatting (3DGS) have become the preferred method for this task, providing high-quality novel views in real time. However, the training time of a 3DGS model is slow, often taking 30 minutes for a scene with 200 views. In contrast, our goal is to reduce the optimization time by training for fewer steps while maintaining high rendering quality. Specifically, we combine the guidance from both the position error and the appearance error to achieve a more effective densification. To balance the rate between adding new Gaussians and fitting old Gaussians, we develop a convergence-aware budget control mechanism. Moreover, to make the densification process more reliable, we selectively add new Gaussians from mostly visited regions. With these designs, we reduce the Gaussian optimization steps to one-third of the previous approach while achieving a comparable or even better novel view rendering quality. To further facilitate the rapid fitting of 4K resolution images, we introduce a dilation-based rendering technique. Our method, Turbo-GS, speeds up optimization for typical scenes and scales well to high-resolution (4K) scenarios on standard datasets. Through extensive experiments, we show that our method is significantly faster in optimization than other methods while retaining quality. Project page: https://ivl.cs.brown.edu/research/turbo-gs.
Aligning Non-Causal Factors for Transformer-Based Source-Free Domain Adaptation
Nov 27, 2023



Conventional domain adaptation algorithms aim to achieve better generalization by aligning only the task-discriminative causal factors between a source and target domain. However, we find that retaining the spurious correlation between causal and non-causal factors plays a vital role in bridging the domain gap and improving target adaptation. Therefore, we propose to build a framework that disentangles and supports causal factor alignment by aligning the non-causal factors first. We also investigate and find that the strong shape bias of vision transformers, coupled with its multi-head attention, make it a suitable architecture for realizing our proposed disentanglement. Hence, we propose to build a Causality-enforcing Source-Free Transformer framework (C-SFTrans) to achieve disentanglement via a novel two-stage alignment approach: a) non-causal factor alignment: non-causal factors are aligned using a style classification task which leads to an overall global alignment, b) task-discriminative causal factor alignment: causal factors are aligned via target adaptation. We are the first to investigate the role of vision transformers (ViTs) in a privacy-preserving source-free setting. Our approach achieves state-of-the-art results in several DA benchmarks.
CoRF : Colorizing Radiance Fields using Knowledge Distillation
Sep 14, 2023



Neural radiance field (NeRF) based methods enable high-quality novel-view synthesis for multi-view images. This work presents a method for synthesizing colorized novel views from input grey-scale multi-view images. When we apply image or video-based colorization methods on the generated grey-scale novel views, we observe artifacts due to inconsistency across views. Training a radiance field network on the colorized grey-scale image sequence also does not solve the 3D consistency issue. We propose a distillation based method to transfer color knowledge from the colorization networks trained on natural images to the radiance field network. Specifically, our method uses the radiance field network as a 3D representation and transfers knowledge from existing 2D colorization methods. The experimental results demonstrate that the proposed method produces superior colorized novel views for indoor and outdoor scenes while maintaining cross-view consistency than baselines. Further, we show the efficacy of our method on applications like colorization of radiance field network trained from 1.) Infra-Red (IR) multi-view images and 2.) Old grey-scale multi-view image sequences.
Strata-NeRF : Neural Radiance Fields for Stratified Scenes
Aug 20, 2023



Neural Radiance Field (NeRF) approaches learn the underlying 3D representation of a scene and generate photo-realistic novel views with high fidelity. However, most proposed settings concentrate on modelling a single object or a single level of a scene. However, in the real world, we may capture a scene at multiple levels, resulting in a layered capture. For example, tourists usually capture a monument's exterior structure before capturing the inner structure. Modelling such scenes in 3D with seamless switching between levels can drastically improve immersive experiences. However, most existing techniques struggle in modelling such scenes. We propose Strata-NeRF, a single neural radiance field that implicitly captures a scene with multiple levels. Strata-NeRF achieves this by conditioning the NeRFs on Vector Quantized (VQ) latent representations which allow sudden changes in scene structure. We evaluate the effectiveness of our approach in multi-layered synthetic dataset comprising diverse scenes and then further validate its generalization on the real-world RealEstate10K dataset. We find that Strata-NeRF effectively captures stratified scenes, minimizes artifacts, and synthesizes high-fidelity views compared to existing approaches.
CapsFlow: Optical Flow Estimation with Capsule Networks
Apr 01, 2023



We present a framework to use recently introduced Capsule Networks for solving the problem of Optical Flow, one of the fundamental computer vision tasks. Most of the existing state of the art deep architectures either uses a correlation oepration to match features from them. While correlation layer is sensitive to the choice of hyperparameters and does not put a prior on the underlying structure of the object, spatio temporal features will be limited by the network's receptive field. Also, we as humans look at moving objects as whole, something which cannot be encoded by correlation or spatio temporal features. Capsules, on the other hand, are specialized to model seperate entities and their pose as a continuous matrix. Thus, we show that a simpler linear operation over poses of the objects detected by the capsules in enough to model flow. We show reslts on a small toy dataset where we outperform FlowNetC and PWC-Net models.
Fusion of Deep and Non-Deep Methods for Fast Super-Resolution of Satellite Images
Aug 03, 2020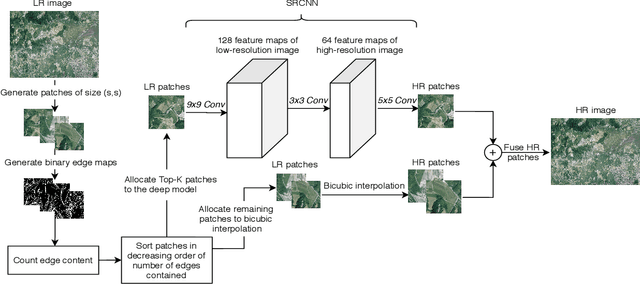
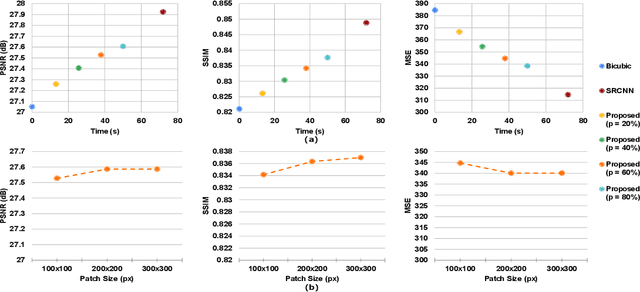

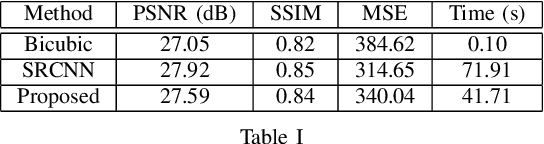
In the emerging commercial space industry there is a drastic increase in access to low cost satellite imagery. The price for satellite images depends on the sensor quality and revisit rate. This work proposes to bridge the gap between image quality and the price by improving the image quality via super-resolution (SR). Recently, a number of deep SR techniques have been proposed to enhance satellite images. However, none of these methods utilize the region-level context information, giving equal importance to each region in the image. This, along with the fact that most state-of-the-art SR methods are complex and cumbersome deep models, the time taken to process very large satellite images can be impractically high. We, propose to handle this challenge by designing an SR framework that analyzes the regional information content on each patch of the low-resolution image and judiciously chooses to use more computationally complex deep models to super-resolve more structure-rich regions on the image, while using less resource-intensive non-deep methods on non-salient regions. Through extensive experiments on a large satellite image, we show substantial decrease in inference time while achieving similar performance to that of existing deep SR methods over several evaluation measures like PSNR, MSE and SSIM.