 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Two-layer clustering-based sparsifying transform learning for low-dose CT reconstruction
Nov 01, 2020
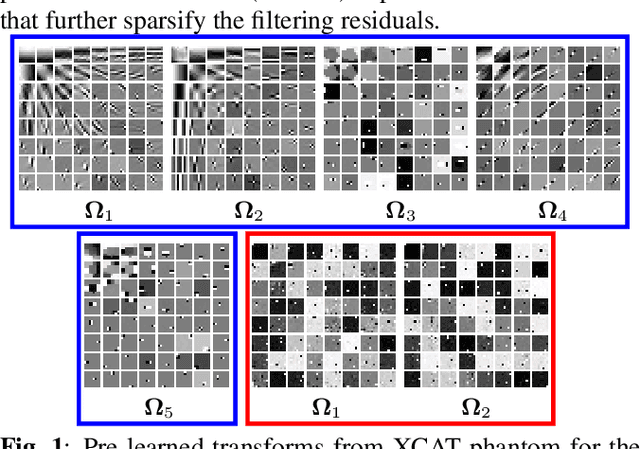
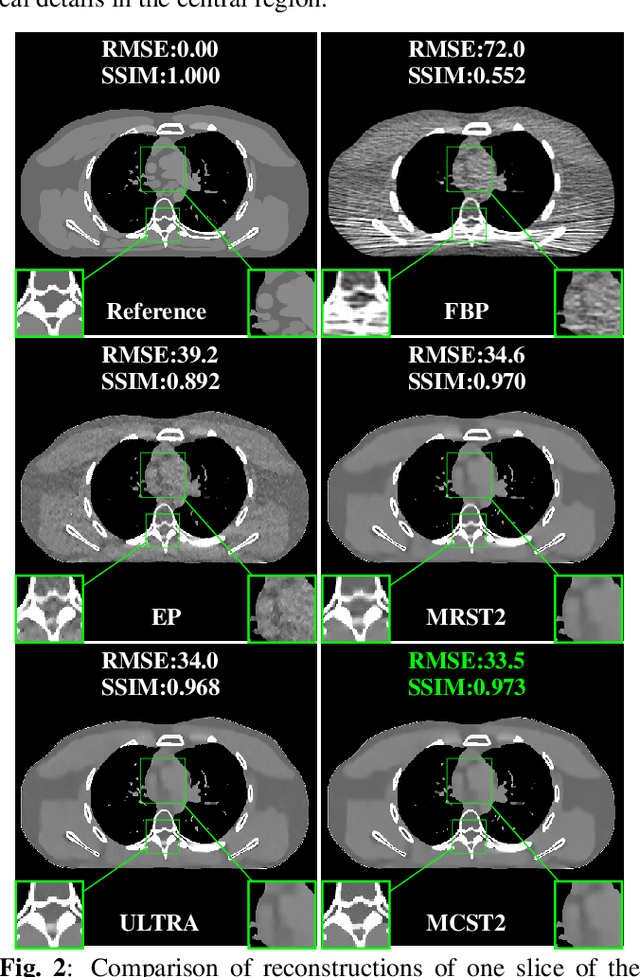
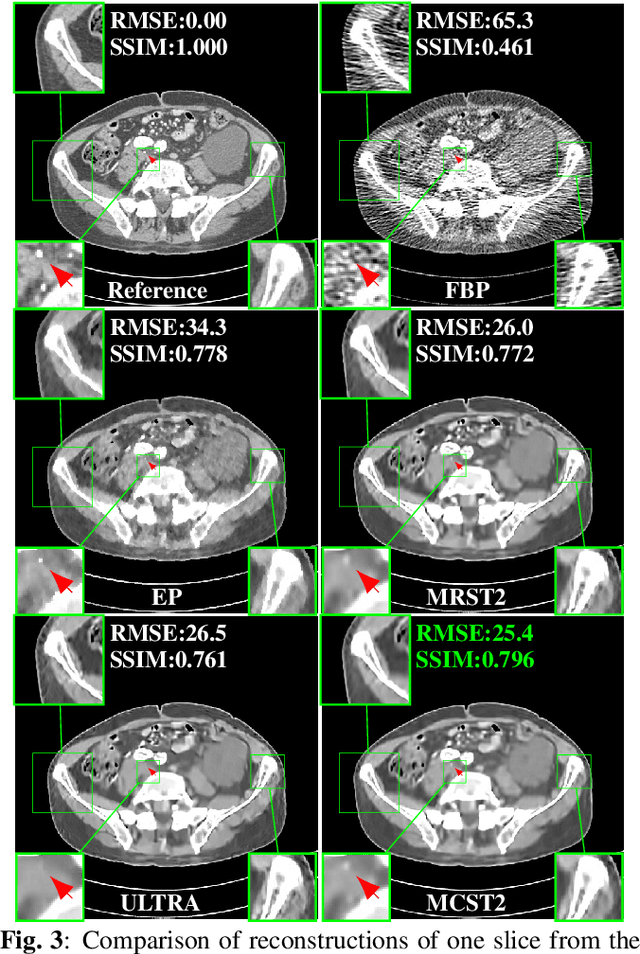
Achieving high-quality reconstructions from low-dose computed tomography (LDCT) measurements is of much importance in clinical settings. Model-based image reconstruction methods have been proven to be effective in removing artifacts in LDCT. In this work, we propose an approach to learn a rich two-layer clustering-based sparsifying transform model (MCST2), where image patches and their subsequent feature maps (filter residuals) are clustered into groups with different learned sparsifying filters per group. We investigate a penalized weighted least squares (PWLS) approach for LDCT reconstruction incorporating learned MCST2 priors. Experimental results show the superior performance of the proposed PWLS-MCST2 approach compared to other related recent schemes.
Restoring Spatially-Heterogeneous Distortions using Mixture of Experts Network
Sep 30, 2020
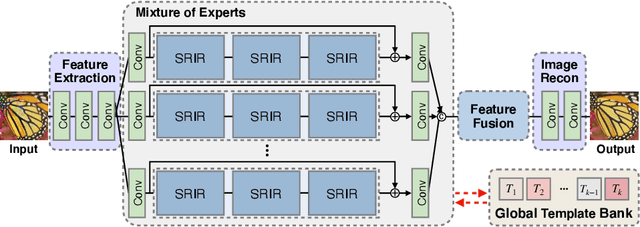

In recent years, deep learning-based methods have been successfully applied to the image distortion restoration tasks. However, scenarios that assume a single distortion only may not be suitable for many real-world applications. To deal with such cases, some studies have proposed sequentially combined distortions datasets. Viewing in a different point of combining, we introduce a spatially-heterogeneous distortion dataset in which multiple corruptions are applied to the different locations of each image. In addition, we also propose a mixture of experts network to effectively restore a multi-distortion image. Motivated by the multi-task learning, we design our network to have multiple paths that learn both common and distortion-specific representations. Our model is effective for restoring real-world distortions and we experimentally verify that our method outperforms other models designed to manage both single distortion and multiple distortions.
A Plug-and-Play Priors Framework for Hyperspectral Unmixing
Dec 31, 2020



Spectral unmixing is a widely used technique in hyperspectral image processing and analysis. It aims to separate mixed pixels into the component materials and their corresponding abundances. Early solutions to spectral unmixing are performed independently on each pixel. Nowadays, investigating proper priors into the unmixing problem has been popular as it can significantly enhance the unmixing performance. However, it is non-trivial to handcraft a powerful regularizer, and complex regularizers may introduce extra difficulties in solving optimization problems in which they are involved. To address this issue, we present a plug-and-play (PnP) priors framework for hyperspectral unmixing. More specifically, we use the alternating direction method of multipliers (ADMM) to decompose the optimization problem into two iterative subproblems. One is a regular optimization problem depending on the forward model, and the other is a proximity operator related to the prior model and can be regarded as an image denoising problem. Our framework is flexible and extendable which allows a wide range of denoisers to replace prior models and avoids handcrafting regularizers. Experiments conducted on both synthetic data and real airborne data illustrate the superiority of the proposed strategy compared with other state-of-the-art hyperspectral unmixing methods.
Use of Transfer Learning and Wavelet Transform for Breast Cancer Detection
Mar 05, 2021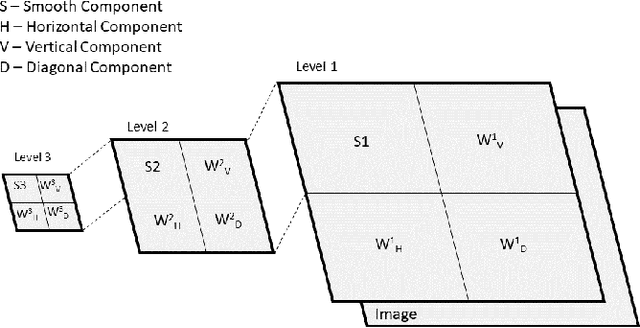
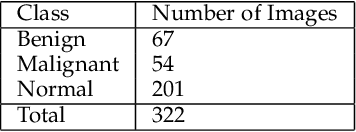
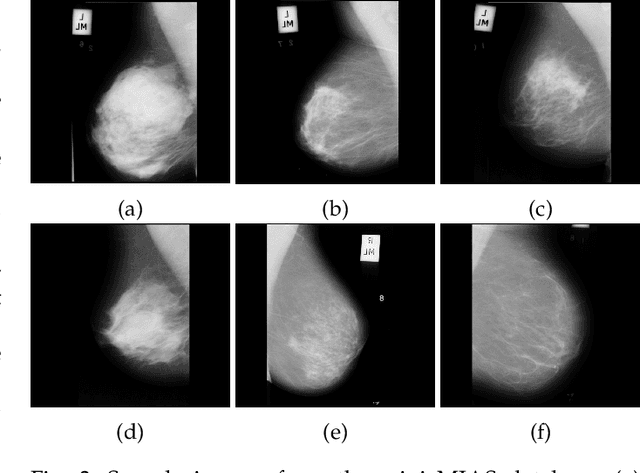
Breast cancer is one of the most common cause of deaths among women. Mammography is a widely used imaging modality that can be used for cancer detection in its early stages. Deep learning is widely used for the detection of cancerous masses in the images obtained via mammography. The need to improve accuracy remains constant due to the sensitive nature of the datasets so we introduce segmentation and wavelet transform to enhance the important features in the image scans. Our proposed system aids the radiologist in the screening phase of cancer detection by using a combination of segmentation and wavelet transforms as pre-processing augmentation that leads to transfer learning in neural networks. The proposed system with these pre-processing techniques significantly increases the accuracy of detection on Mini-MIAS.
Writer Identification and Writer Retrieval Based on NetVLAD with Re-ranking
Dec 20, 2020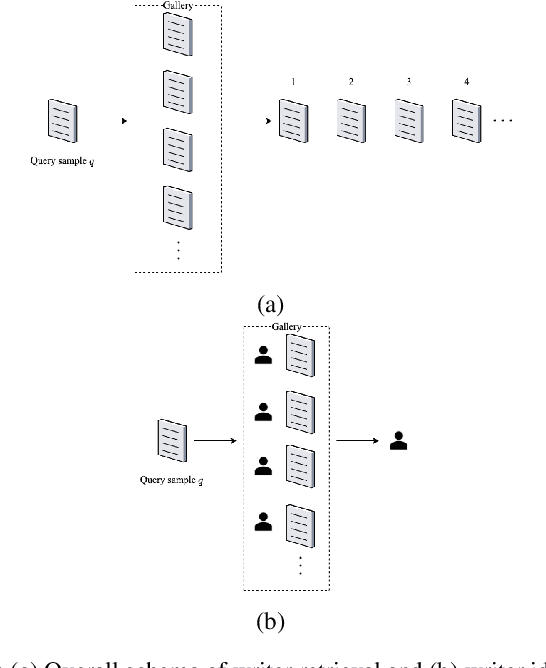

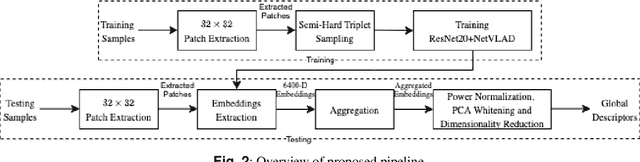
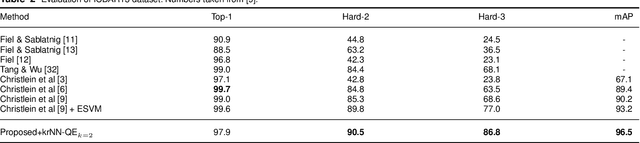
This paper addresses writer identification and retrieval which is a challenging problem in the document analysis field. In this work, a novel pipeline is proposed for the problem by employing a unified neural network architecture consisting of the ResNet-20 as a feature extractor and an integrated NetVLAD layer, inspired by the vectors of locally aggregated descriptors (VLAD), in the head of the latter part. Having defined this architecture, triplet semi-hard loss function is used to directly learn an embedding for individual input image patches. Generalised max-pooling is used for the aggregation of embedded descriptors of each handwritten image. In the evaluation part, for identification and retrieval, re-ranking has been done based on query expansion and $k$-reciprocal nearest neighbours, and it is shown that the pipeline can benefit tremendously from this step. Experimental evaluation shows that our writer identification and writer retrieval pipeline is superior compared to the state-of-the-art pipelines, as our results on the publicly available ICDAR13 and CVL datasets set new standards by achieving 96.5% and 98.4% mAP, respectively.
An Attention-Based Approach for Single Image Super Resolution
Jul 18, 2018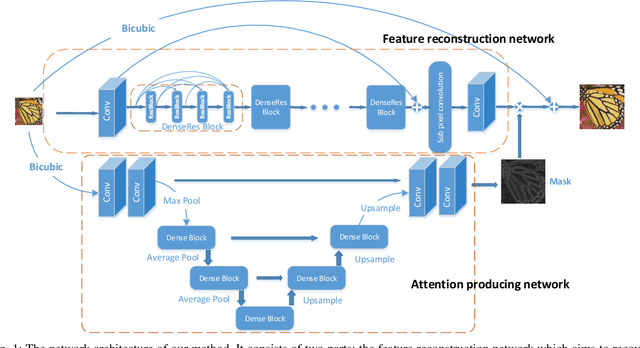
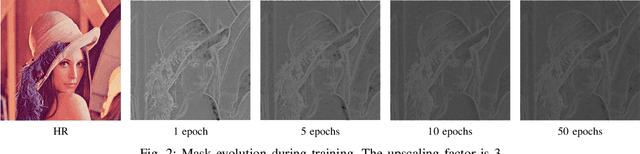

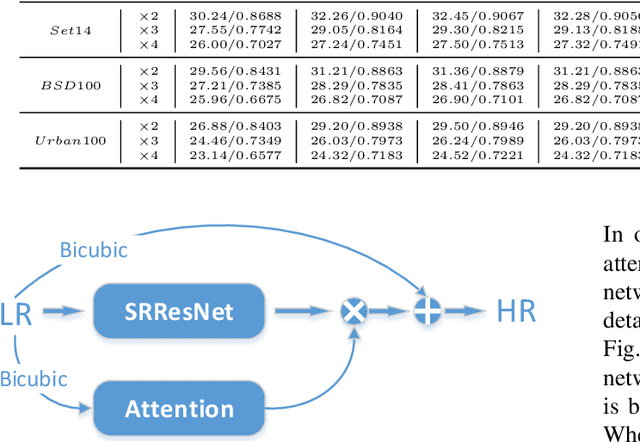
The main challenge of single image super resolution (SISR) is the recovery of high frequency details such as tiny textures. However, most of the state-of-the-art methods lack specific modules to identify high frequency areas, causing the output image to be blurred. We propose an attention-based approach to give a discrimination between texture areas and smooth areas. After the positions of high frequency details are located, high frequency compensation is carried out. This approach can incorporate with previously proposed SISR networks. By providing high frequency enhancement, better performance and visual effect are achieved. We also propose our own SISR network composed of DenseRes blocks. The block provides an effective way to combine the low level features and high level features. Extensive benchmark evaluation shows that our proposed method achieves significant improvement over the state-of-the-art works in SISR.
Privacy-Preserving Pose Estimation for Human-Robot Interaction
Nov 14, 2020


Pose estimation is an important technique for nonverbal human-robot interaction. That said, the presence of a camera in a person's space raises privacy concerns and could lead to distrust of the robot. In this paper, we propose a privacy-preserving camera-based pose estimation method. The proposed system consists of a user-controlled translucent filter that covers the camera and an image enhancement module designed to facilitate pose estimation from the filtered (shadow) images, while never capturing clear images of the user. We evaluate the system's performance on a new filtered image dataset, considering the effects of distance from the camera, background clutter, and film thickness. Based on our findings, we conclude that our system can protect humans' privacy while detecting humans' pose information effectively.
Unsupervised image segmentation via maximum a posteriori estimation of continuous max-flow
Nov 01, 2018



Recent thrust in imaging capabilities in medical as well as emerging areas of manufacturing systems creates unique opportunities and challenges for on-the-fly, unsupervised estimation of anomalies and other regions of interest. With the ever-growing image database, it is remarkably costly to create annotations and atlases associated with different combinations of imaging capabilities and regions of interest. To address this issue, we present an unsupervised learning approach to a continuous max-flow problem. We show that the maximum a posteriori estimation of the image labels can be formulated as a capacitated max-flow problem over a continuous domain with unknown flow capacities. The flow capacities are then iteratively obtained by considering a Markov random field prior over the neighborhood structure in the image. We also present results to establish the consistency of the proposed approach. We establish the performance of our approach on two real-world datasets including, brain tumor segmentation and defect identification in additively manufactured surfaces as gathered from electron microscopic images. We also present an exhaustive comparison with other state-of-the-art supervised as well as unsupervised algorithms. Results suggest that the method is able to perform almost comparable to other supervised approaches, but more 90% improvement in terms of Dice score as compared to other unsupervised methods.
Artificial intelligence for detection and quantification of rust and leaf miner in coffee crop
Apr 01, 2021



Pest and disease control plays a key role in agriculture since the damage caused by these agents are responsible for a huge economic loss every year. Based on this assumption, we create an algorithm capable of detecting rust (Hemileia vastatrix) and leaf miner (Leucoptera coffeella) in coffee leaves (Coffea arabica) and quantify disease severity using a mobile application as a high-level interface for the model inferences. We used different convolutional neural network architectures to create the object detector, besides the OpenCV library, k-means, and three treatments: the RGB and value to quantification, and the AFSoft software, in addition to the analysis of variance, where we compare the three methods. The results show an average precision of 81,5% in the detection and that there was no significant statistical difference between treatments to quantify the severity of coffee leaves, proposing a computationally less costly method. The application, together with the trained model, can detect the pest and disease over different image conditions and infection stages and also estimate the disease infection stage.
Parameterizing the Angular Distribution of Emission: A model for TOF-PET low counts reconstruction
May 05, 2021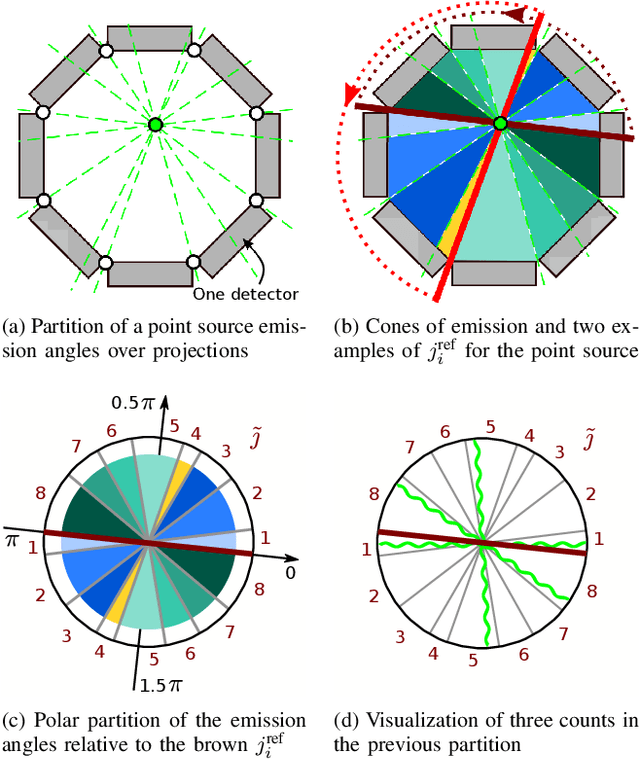
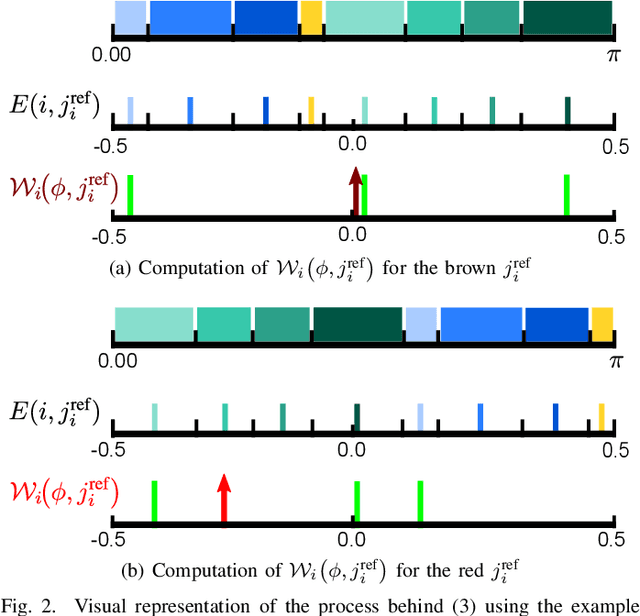

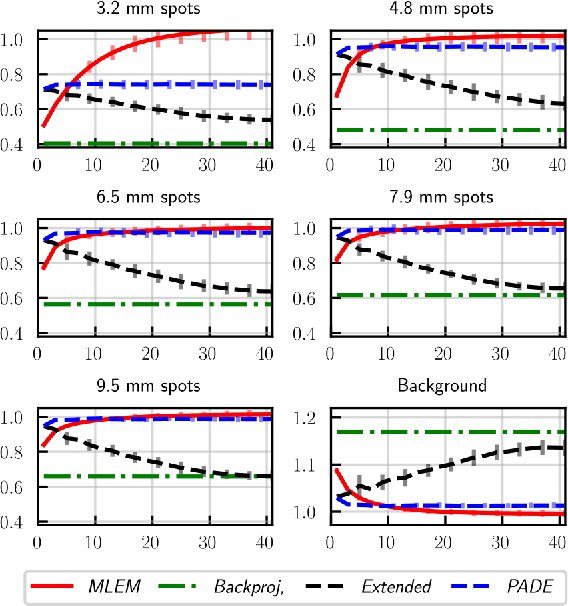
Low counts reconstruction remains a challenge for Positron Emission Tomography (PET) even with the recent progresses in time-of-flight (TOF) resolution. In that setting, the bias between the acquired histogram, composed of low values or zeros, and the expected histogram, obtained from the forward projector, is propagated to the image, resulting in a biased reconstruction. This could be exacerbated with finer resolution of the TOF information, which further sparsify the acquired histogram. We propose a new approach to circumvent this limitation of the classical reconstruction model. It consists of extending the parametrization of the reconstruction scheme to also explicitly include the projection domain. This parametrization has greater degrees of freedom than the log-likelihood model, which can not be harnessed in classical circumstances. We hypothesize that with ultra-fast TOF this new approach would not only be viable for low counts reconstruction but also more adequate than the classical reconstruction model. An implementation of this approach is compared to the log-likelihood model by using two-dimensional simulations of a hot spots phantom. The proposed model achieves similar contrast recovery coefficients as MLEM except for the smallest structures where the low counts nature of the simulations makes it difficult to draw conclusions. Also, this new model seems to converge toward a less noisy solution than the MLEM. These results suggest that this new approach has potential for low counts reconstruction with ultra-fast TOF.