 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterizing the Angular Distribution of Emission: A model for TOF-PET low counts reconstruction
May 05, 2021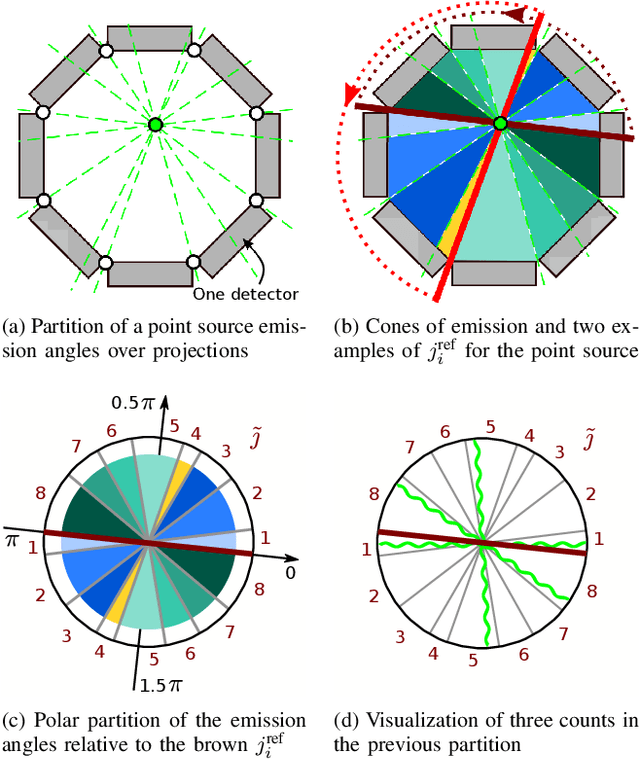
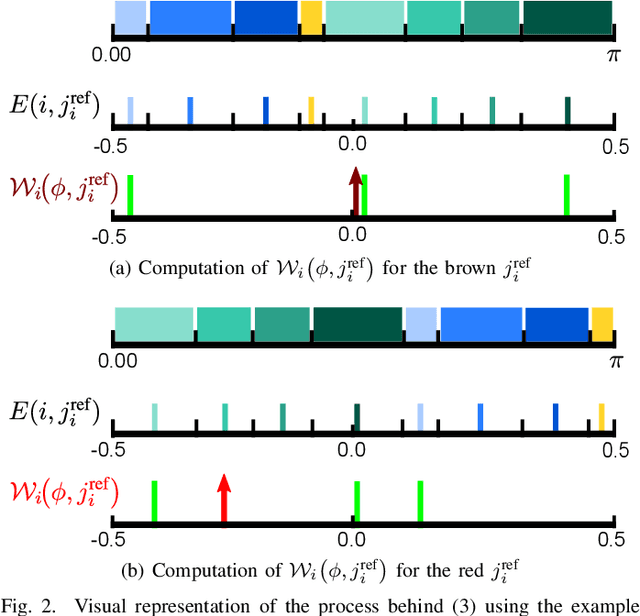

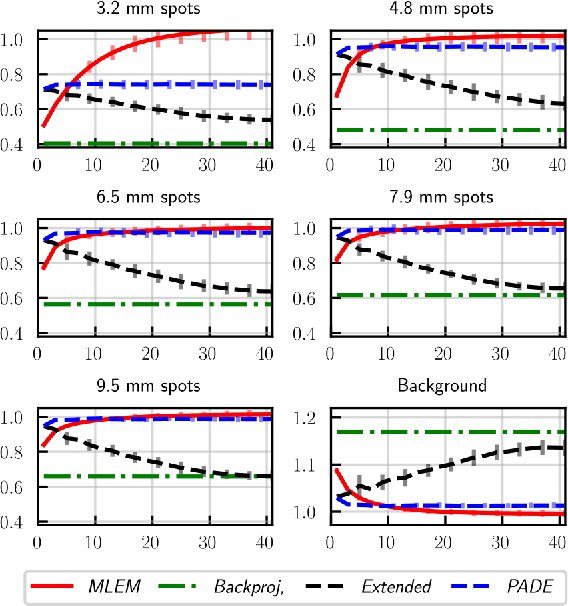
Low counts reconstruction remains a challenge for Positron Emission Tomography (PET) even with the recent progresses in time-of-flight (TOF) resolution. In that setting, the bias between the acquired histogram, composed of low values or zeros, and the expected histogram, obtained from the forward projector, is propagated to the image, resulting in a biased reconstruction. This could be exacerbated with finer resolution of the TOF information, which further sparsify the acquired histogram. We propose a new approach to circumvent this limitation of the classical reconstruction model. It consists of extending the parametrization of the reconstruction scheme to also explicitly include the projection domain. This parametrization has greater degrees of freedom than the log-likelihood model, which can not be harnessed in classical circumstances. We hypothesize that with ultra-fast TOF this new approach would not only be viable for low counts reconstruction but also more adequate than the classical reconstruction model. An implementation of this approach is compared to the log-likelihood model by using two-dimensional simulations of a hot spots phantom. The proposed model achieves similar contrast recovery coefficients as MLEM except for the smallest structures where the low counts nature of the simulations makes it difficult to draw conclusions. Also, this new model seems to converge toward a less noisy solution than the MLEM. These results suggest that this new approach has potential for low counts reconstruction with ultra-fast TOF.
Systematic Ensemble Learning for Regression
Mar 28, 2014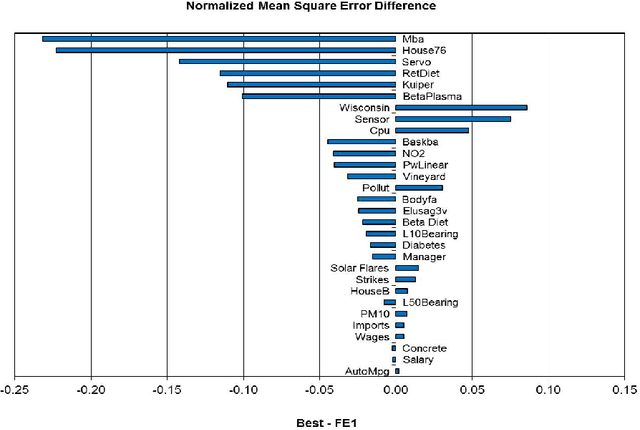
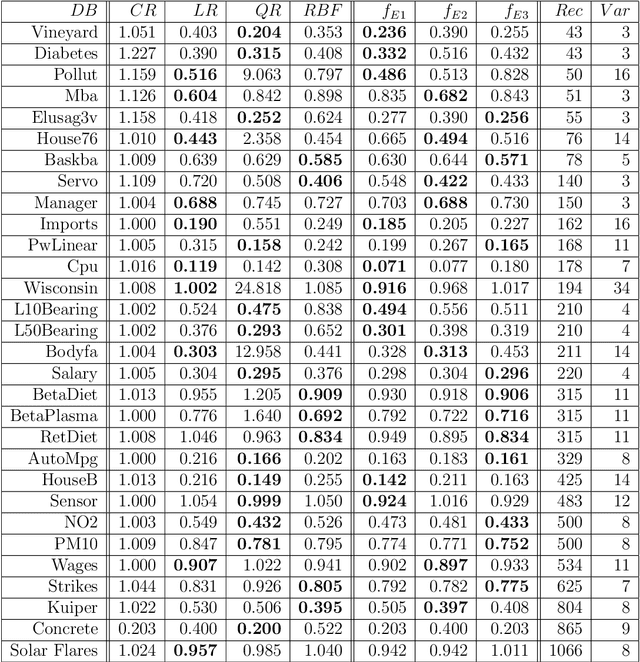
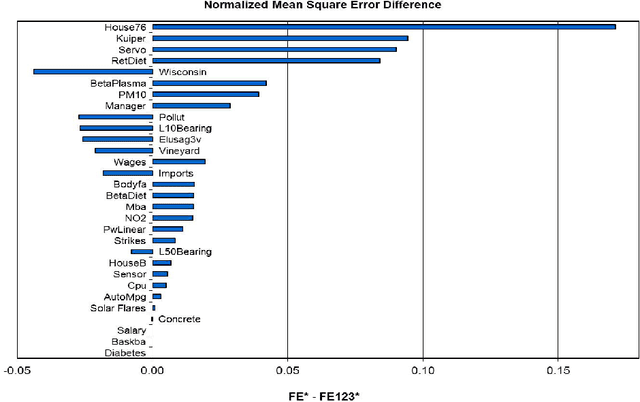
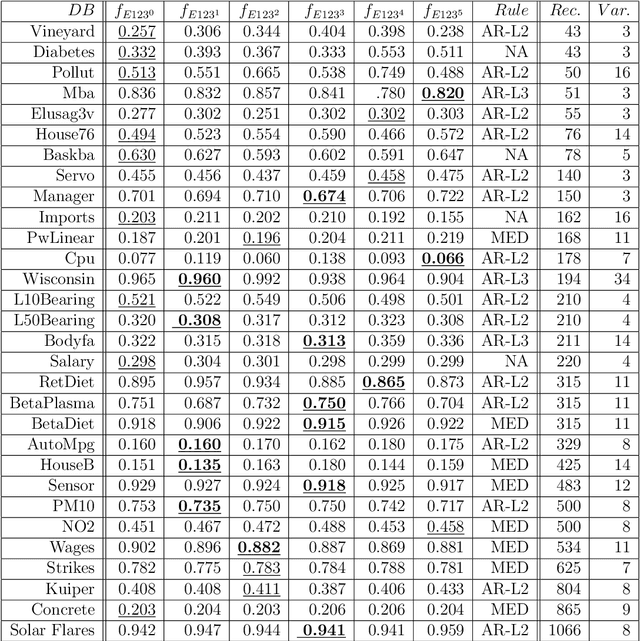
The motivation of this work is to improve the performance of standard stacking approaches or ensembles, which are composed of simple, heterogeneous base models, through the integration of the generation and selection stages for regression problems. We propose two extensions to the standard stacking approach. In the first extension we combine a set of standard stacking approaches into an ensemble of ensembles using a two-step ensemble learning in the regression setting. The second extension consists of two parts. In the initial part a diversity mechanism is injected into the original training data set, systematically generating different training subsets or partitions, and corresponding ensembles of ensembles. In the final part after measuring the quality of the different partitions or ensembles, a max-min rule-based selection algorithm is used to select the most appropriate ensemble/partition on which to make the final prediction. We show, based on experiments over a broad range of data sets, that the second extension performs better than the best of the standard stacking approaches, and is as good as the oracle of databases, which has the best base model selected by cross-validation for each data set. In addition to that, the second extension performs better than two state-of-the-art ensemble methods for regression, and it is as good as a third state-of-the-art ensemble method.