 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Preserving Semantic Neighborhoods for Robust Cross-modal Retrieval
Jul 16, 2020

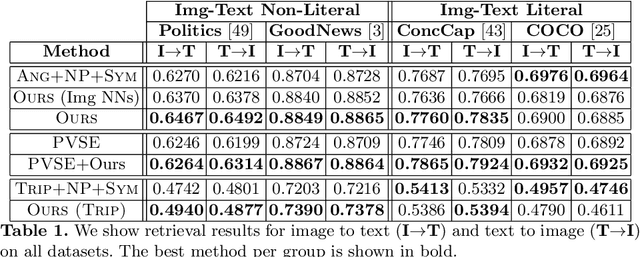
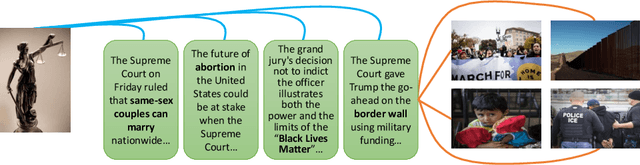

The abundance of multimodal data (e.g. social media posts) has inspired interest in cross-modal retrieval methods. Popular approaches rely on a variety of metric learning losses, which prescribe what the proximity of image and text should be, in the learned space. However, most prior methods have focused on the case where image and text convey redundant information; in contrast, real-world image-text pairs convey complementary information with little overlap. Further, images in news articles and media portray topics in a visually diverse fashion; thus, we need to take special care to ensure a meaningful image representation. We propose novel within-modality losses which encourage semantic coherency in both the text and image subspaces, which does not necessarily align with visual coherency. Our method ensures that not only are paired images and texts close, but the expected image-image and text-text relationships are also observed. Our approach improves the results of cross-modal retrieval on four datasets compared to five baselines.
Deep Learning-based Prediction of Key Performance Indicators for Electrical Machine
Dec 16, 2020
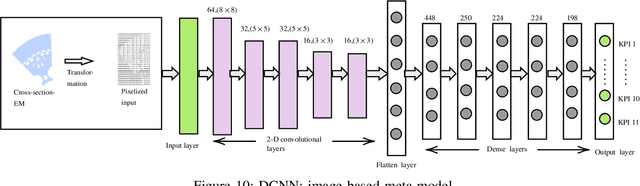
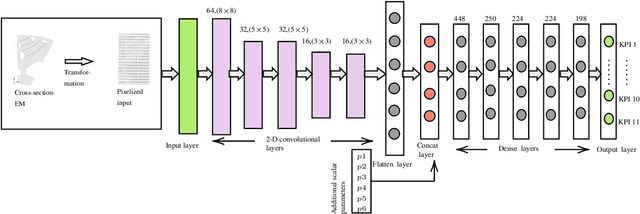
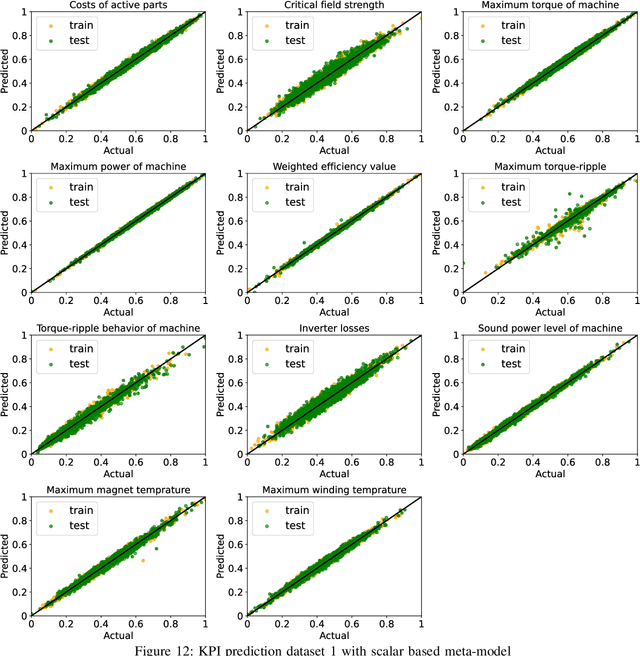
The design of an electrical machine can be quantified and evaluated by Key Performance Indicators (KPIs) such as maximum torque, critical field strength, costs of active parts, sound power, etc. Generally, cross-domain tool-chains are used to optimize all the KPIs from different domains (multi-objective optimization) by varying the given input parameters in the largest possible design space. This optimization process involves magneto-static finite element simulation to obtain these decisive KPIs. It makes the whole process a vehemently time-consuming computational task that counts on the availability of resources with the involvement of high computational cost. In this paper, a data-aided, deep learning-based meta-model is employed to predict the KPIs of an electrical machine quickly and with high accuracy to accelerate the full optimization process and reduce its computational costs. The focus is on analyzing various forms of input data that serve as a geometry representation of the machine. Namely, these are the cross-section image of the electrical machine that allows a very general description of the geometry relating to different topologies and the classical way with scalar parametrization of geometry. The impact of the resolution of the image is studied in detail. The results show a high prediction accuracy and proof that the validity of a deep learning-based meta-model to minimize the optimization time. The results also indicate that the prediction quality of an image-based approach can be made comparable to the classical way based on scalar parameters.
Current Status and Performance Analysis of Table Recognition in Document Images with Deep Neural Networks
Apr 29, 2021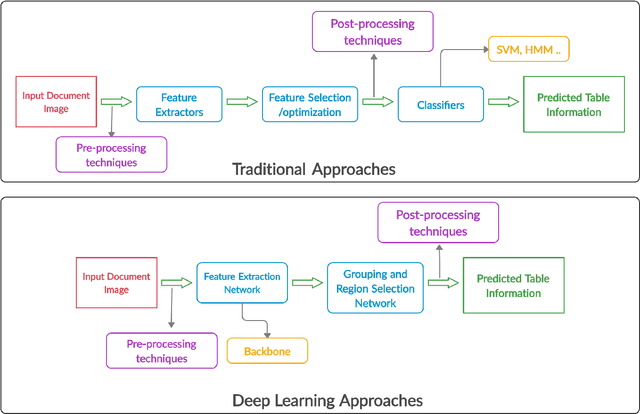
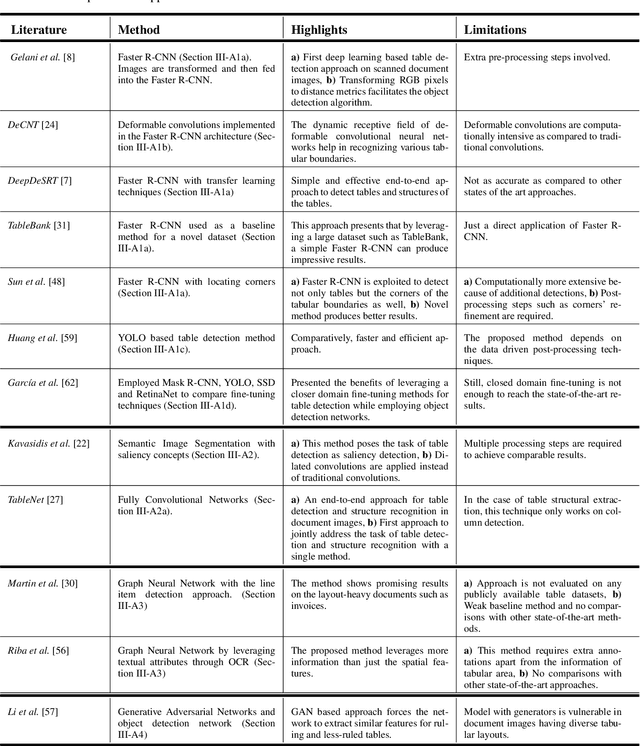
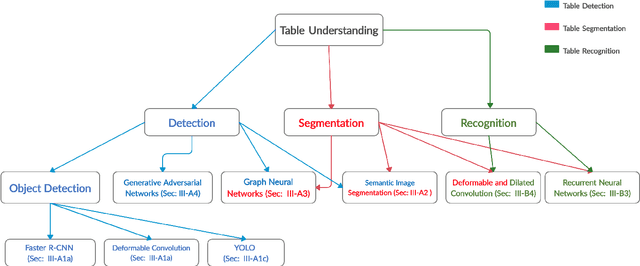
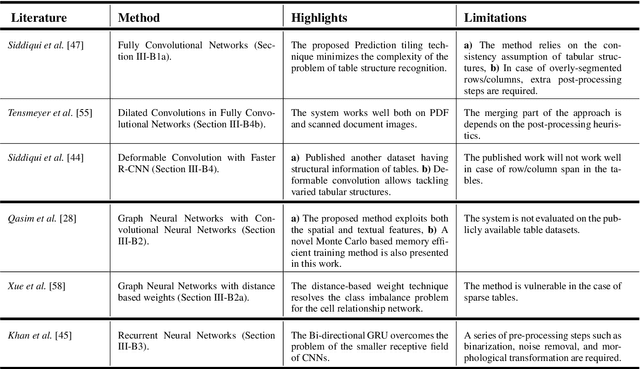
The first phase of table recognition is to detect the tabular area in a document. Subsequently, the tabular structures are recognized in the second phase in order to extract information from the respective cells. Table detection and structural recognition are pivotal problems in the domain of table understanding. However, table analysis is a perplexing task due to the colossal amount of diversity and asymmetry in tables. Therefore, it is an active area of research in document image analysis. Recent advances in the computing capabilities of graphical processing units have enabled deep neural networks to outperform traditional state-of-the-art machine learning methods. Table understanding has substantially benefited from the recent breakthroughs in deep neural networks. However, there has not been a consolidated description of the deep learning methods for table detection and table structure recognition. This review paper provides a thorough analysis of the modern methodologies that utilize deep neural networks. This work provided a thorough understanding of the current state-of-the-art and related challenges of table understanding in document images. Furthermore, the leading datasets and their intricacies have been elaborated along with the quantitative results. Moreover, a brief overview is given regarding the promising directions that can serve as a guide to further improve table analysis in document images.
Unsupervised Foreground-Background Segmentation with Equivariant Layered GANs
Apr 01, 2021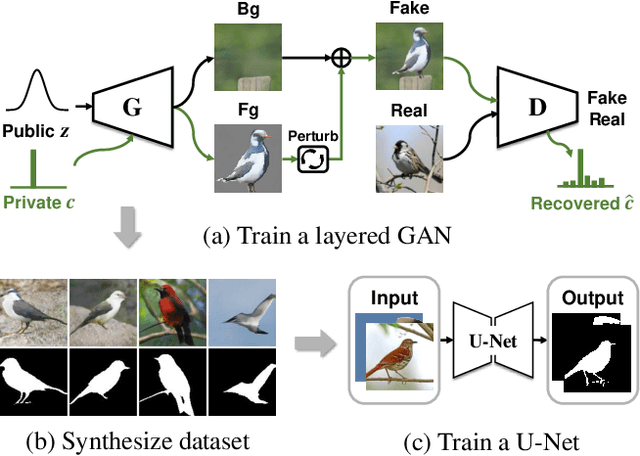
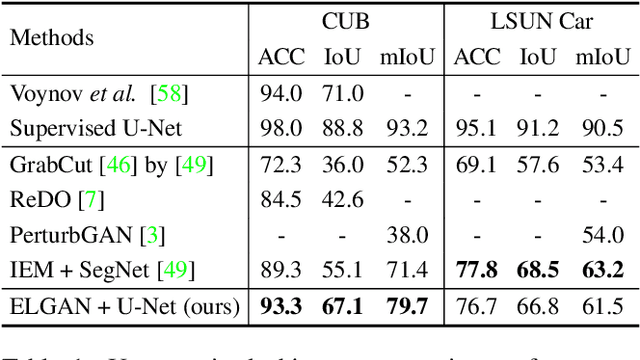
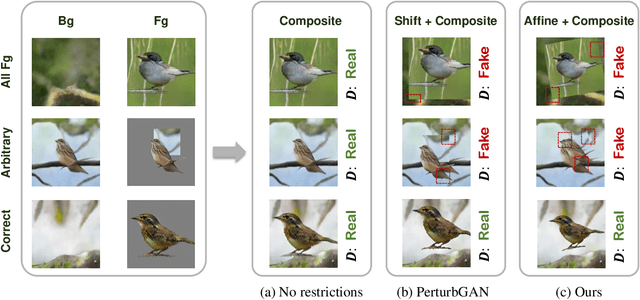
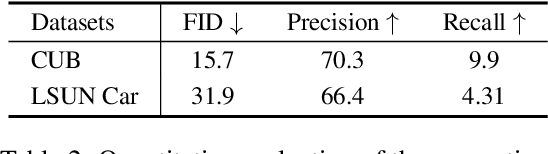
We propose an unsupervised foreground-background segmentation method via training a segmentation network on the synthetic pseudo segmentation dataset generated from GANs, which are trained from a collection of images without annotations to explicitly disentangle foreground and background. To efficiently generate foreground and background layers and overlay them to compose novel images, the construction of such GANs is fulfilled by our proposed Equivariant Layered GAN, whose improvement, compared to the precedented layered GAN, is embodied in the following two aspects. (1) The disentanglement of foreground and background is improved by extending the previous perturbation strategy and introducing private code recovery that reconstructs the private code of foreground from the composite image. (2) The latent space of the layered GANs is regularized by minimizing our proposed equivariance loss, resulting in interpretable latent codes and better disentanglement of foreground and background. Our methods are evaluated on unsupervised object segmentation datasets including Caltech-UCSD Birds and LSUN Car, achieving state-of-the-art performance.
U-Net Fixed-Point Quantization for Medical Image Segmentation
Sep 09, 2019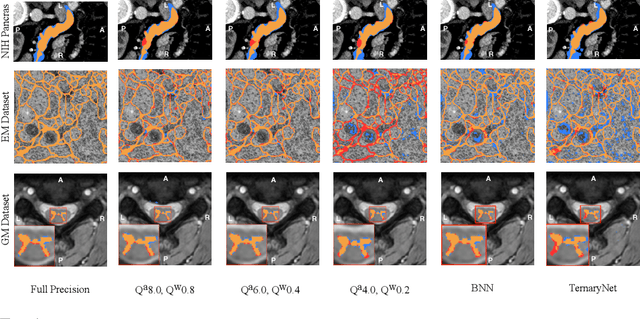
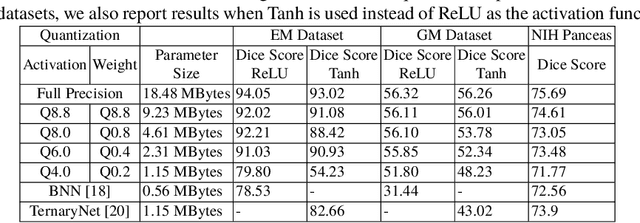
Model quantization is leveraged to reduce the memory consumption and the computation time of deep neural networks. This is achieved by representing weights and activations with a lower bit resolution when compared to their high precision floating point counterparts. The suitable level of quantization is directly related to the model performance. Lowering the quantization precision (e.g. 2 bits), reduces the amount of memory required to store model parameters and the amount of logic required to implement computational blocks, which contributes to reducing the power consumption of the entire system. These benefits typically come at the cost of reduced accuracy. The main challenge is to quantize a network as much as possible, while maintaining the performance accuracy. In this work, we present a quantization method for the U-Net architecture, a popular model in medical image segmentation. We then apply our quantization algorithm to three datasets: (1) the Spinal Cord Gray Matter Segmentation (GM), (2) the ISBI challenge for segmentation of neuronal structures in Electron Microscopic (EM), and (3) the public National Institute of Health (NIH) dataset for pancreas segmentation in abdominal CT scans. The reported results demonstrate that with only 4 bits for weights and 6 bits for activations, we obtain 8 fold reduction in memory requirements while loosing only 2.21%, 0.57% and 2.09% dice overlap score for EM, GM and NIH datasets respectively. Our fixed point quantization provides a flexible trade off between accuracy and memory requirement which is not provided by previous quantization methods for U-Net such as TernaryNet.
Condensation-Net: Memory-Efficient Network Architecture with Cross-Channel Pooling Layers and Virtual Feature Maps
Apr 29, 2021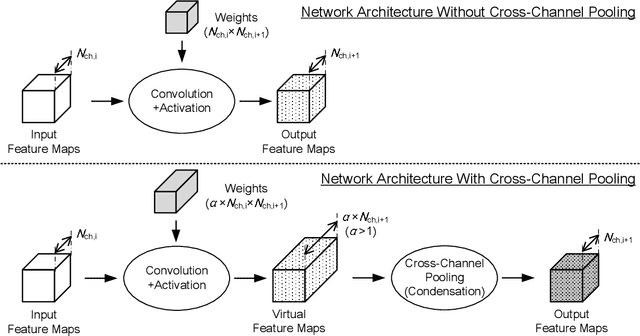

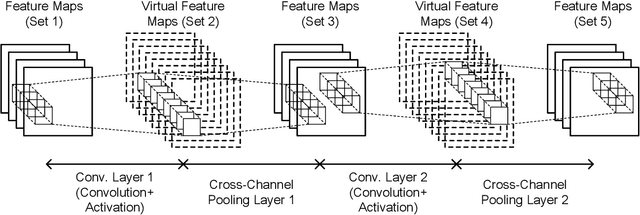
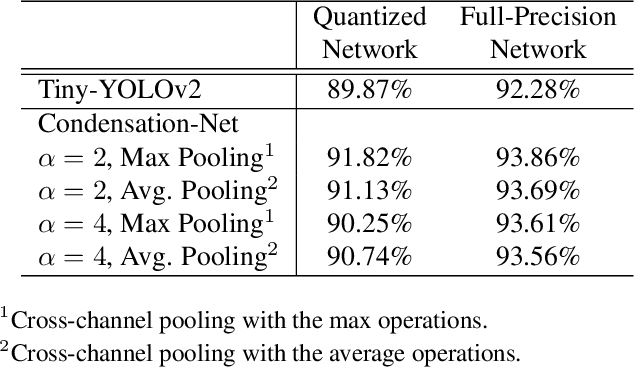
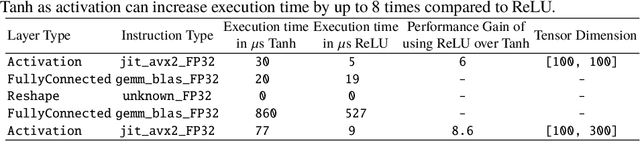
"Lightweight convolutional neural networks" is an important research topic in the field of embedded vision. To implement image recognition tasks on a resource-limited hardware platform, it is necessary to reduce the memory size and the computational cost. The contribution of this paper is stated as follows. First, we propose an algorithm to process a specific network architecture (Condensation-Net) without increasing the maximum memory storage for feature maps. The architecture for virtual feature maps saves 26.5% of memory bandwidth by calculating the results of cross-channel pooling before storing the feature map into the memory. Second, we show that cross-channel pooling can improve the accuracy of object detection tasks, such as face detection, because it increases the number of filter weights. Compared with Tiny-YOLOv2, the improvement of accuracy is 2.0% for quantized networks and 1.5% for full-precision networks when the false-positive rate is 0.1. Last but not the least, the analysis results show that the overhead to support the cross-channel pooling with the proposed hardware architecture is negligible small. The extra memory cost to support Condensation-Net is 0.2% of the total size, and the extra gate count is only 1.0% of the total size.
* Camera-ready version for CVPR 2019 workshop (Embedded Vision Workshop)
Geography-Aware Self-Supervised Learning
Dec 02, 2020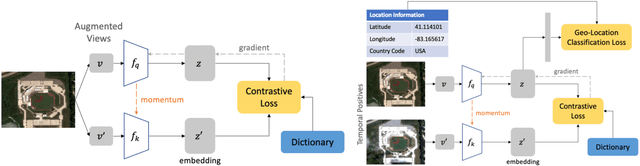
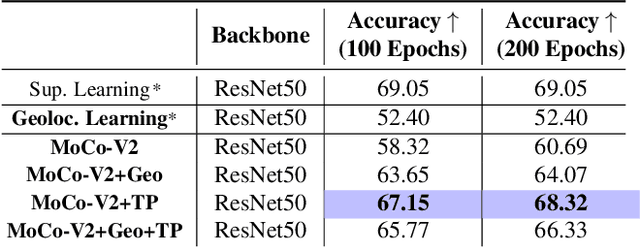

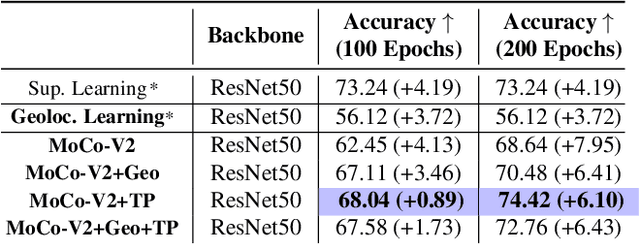
Contrastive learning methods have significantly narrowed the gap between supervised and unsupervised learning on computer vision tasks. In this paper, we explore their application to remote sensing, where unlabeled data is often abundant but labeled data is scarce. We first show that due to their different characteristics, a non-trivial gap persists between contrastive and supervised learning on standard benchmarks. To close the gap, we propose novel training methods that exploit the spatiotemporal structure of remote sensing data. We leverage spatially aligned images over time to construct temporal positive pairs in contrastive learning and geo-location to design pre-text tasks. Our experiments show that our proposed method closes the gap between contrastive and supervised learning on image classification, object detection and semantic segmentation for remote sensing and other geo-tagged image datasets.
Understanding Synonymous Referring Expressions via Contrastive Features
Apr 20, 2021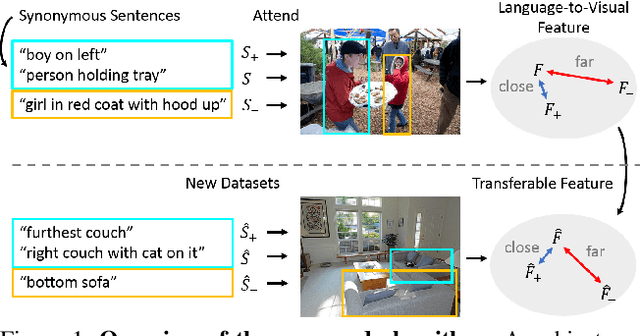
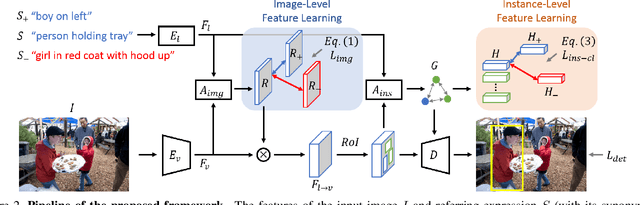
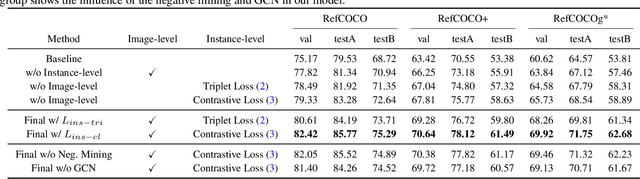
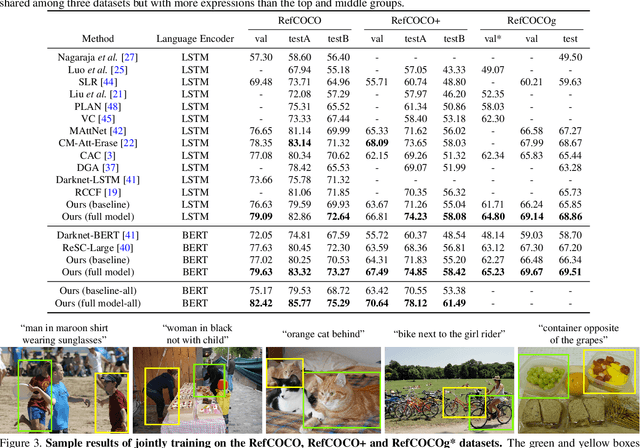
Referring expression comprehension aims to localize objects identified by natural language descriptions. This is a challenging task as it requires understanding of both visual and language domains. One nature is that each object can be described by synonymous sentences with paraphrases, and such varieties in languages have critical impact on learning a comprehension model. While prior work usually treats each sentence and attends it to an object separately, we focus on learning a referring expression comprehension model that considers the property in synonymous sentences. To this end, we develop an end-to-end trainable framework to learn contrastive features on the image and object instance levels, where features extracted from synonymous sentences to describe the same object should be closer to each other after mapping to the visual domain. We conduct extensive experiments to evaluate the proposed algorithm on several benchmark datasets, and demonstrate that our method performs favorably against the state-of-the-art approaches. Furthermore, since the varieties in expressions become larger across datasets when they describe objects in different ways, we present the cross-dataset and transfer learning settings to validate the ability of our learned transferable features.
Improving Generation and Evaluation of Visual Stories via Semantic Consistency
May 20, 2021
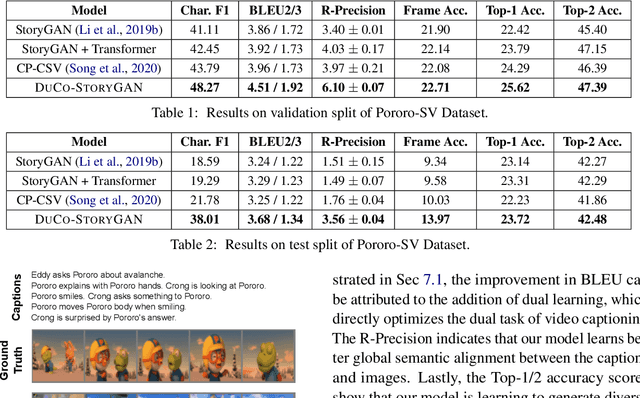
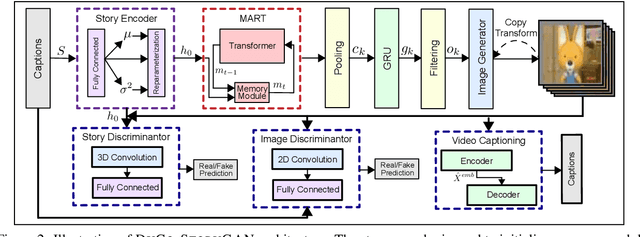
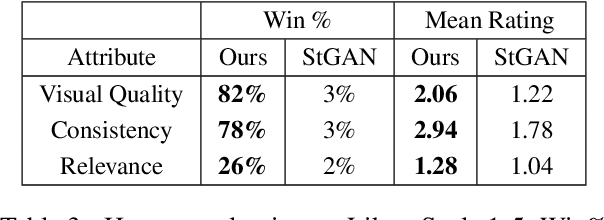
Story visualization is an under-explored task that falls at the intersection of many important research directions in both computer vision and natural language processing. In this task, given a series of natural language captions which compose a story, an agent must generate a sequence of images that correspond to the captions. Prior work has introduced recurrent generative models which outperform text-to-image synthesis models on this task. However, there is room for improvement of generated images in terms of visual quality, coherence and relevance. We present a number of improvements to prior modeling approaches, including (1) the addition of a dual learning framework that utilizes video captioning to reinforce the semantic alignment between the story and generated images, (2) a copy-transform mechanism for sequentially-consistent story visualization, and (3) MART-based transformers to model complex interactions between frames. We present ablation studies to demonstrate the effect of each of these techniques on the generative power of the model for both individual images as well as the entire narrative. Furthermore, due to the complexity and generative nature of the task, standard evaluation metrics do not accurately reflect performance. Therefore, we also provide an exploration of evaluation metrics for the model, focused on aspects of the generated frames such as the presence/quality of generated characters, the relevance to captions, and the diversity of the generated images. We also present correlation experiments of our proposed automated metrics with human evaluations. Code and data available at: https://github.com/adymaharana/StoryViz
Thickened 2D Networks for 3D Medical Image Segmentation
Apr 02, 2019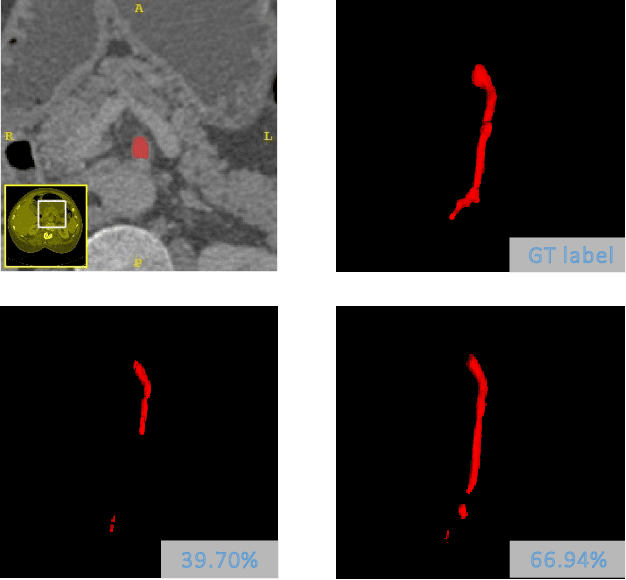
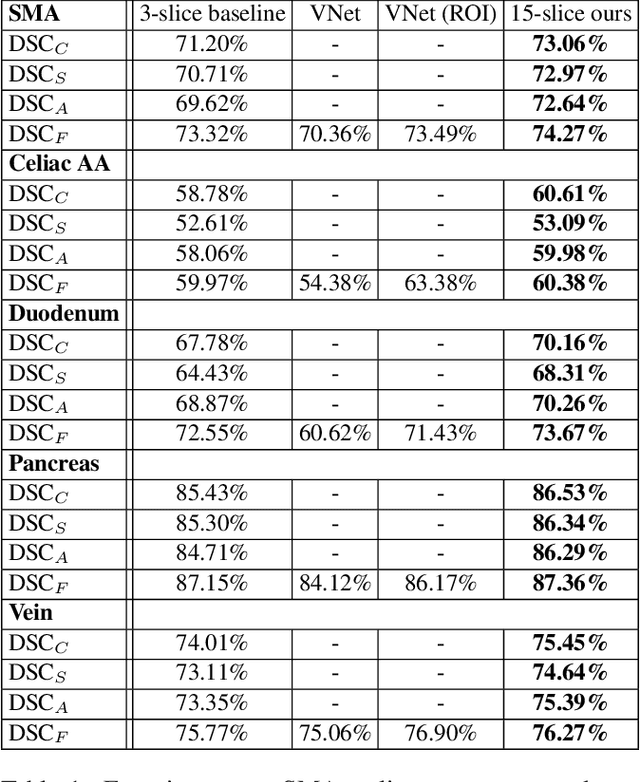
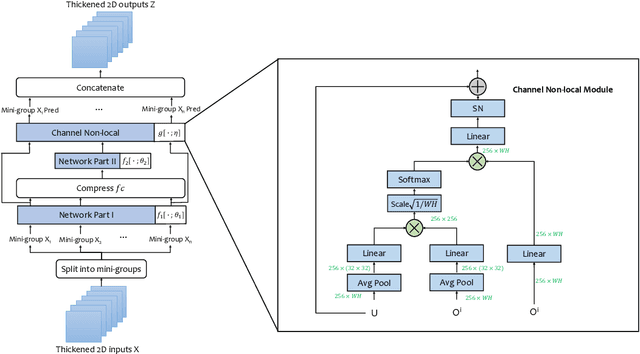
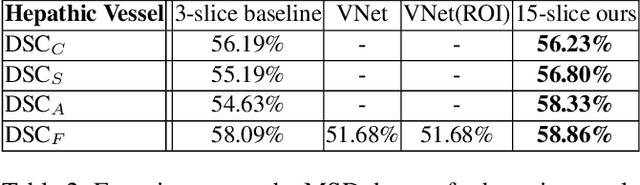
There has been a debate in medical image segmentation on whether to use 2D or 3D networks, where both pipelines have advantages and disadvantages. This paper presents a novel approach which thickens the input of a 2D network, so that the model is expected to enjoy both the stability and efficiency of 2D networks as well as the ability of 3D networks in modeling volumetric contexts. A major information loss happens when a large number of 2D slices are fused at the first convolutional layer, resulting in a relatively weak ability of the network in distinguishing the difference among slices. To alleviate this drawback, we propose an effective framework which (i) postpones slice fusion and (ii) adds highway connections from the pre-fusion layer so that the prediction layer receives slice-sensitive auxiliary cues. Experiments on segmenting a few abdominal targets in particular blood vessels which require strong 3D contexts demonstrate the effectiveness of our approach.