 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Rank Caption Chains for Video-Text Alignment
Mar 26, 2026Direct preference optimization (DPO) is an effective technique to train language models to generate preferred over dispreferred responses. However, this binary "winner-takes-all" approach is suboptimal for vision-language models whose response quality is highly dependent on visual content. In particular, a response may still be faithful to the visual inputs even if it is less preferable than an alternative. The standard Bradley-Terry DPO formulation lacks this nuance, upweighting winning responses without sufficient regard for whether the "losing" response still maintains high visual fidelity. In this work, we investigate ranking optimization as an alternative that more precisely situates responses' faithfulness to visual inputs. We focus on video-text alignment using detailed video captions, proposing a method to generate challenging, totally ordered caption chains at scale through repeated caption degradation. Our results show ranking optimization outperforms binary DPO for long-form content generation and assessment, and importantly, we find that these approaches require finetuning of the vision encoder to be effective, challenging the view of DPO as purely a language-reweighting process.
Narrative Aligned Long Form Video Question Answering
Mar 19, 2026Recent progress in multimodal large language models (MLLMs) has led to a surge of benchmarks for long-video reasoning. However, most existing benchmarks rely on localized cues and fail to capture narrative reasoning, the ability to track intentions, connect distant events, and reconstruct causal chains across an entire movie. We introduce NA-VQA, a benchmark designed to evaluate deep temporal and narrative reasoning in long-form videos. NA-VQA contains 88 full-length movies and 4.4K open-ended question-answer pairs, each grounded in multiple evidence spans labeled as Short, Medium, or Far to assess long-range dependencies. By requiring generative, multi-scene answers, NA-VQA tests whether models can integrate dispersed narrative information rather than rely on shallow pattern matching. To address the limitations of existing approaches, we propose Video-NaRA, a narrative-centric framework that builds event-level chains and stores them in a structured memory for retrieval during reasoning. Extensive experiments show that state-of-the-art MLLMs perform poorly on questions requiring far-range evidence, highlighting the need for explicit narrative modeling. Video-NaRA improves long-range reasoning performance by up to 3 percent, demonstrating its effectiveness in handling complex narrative structures. We will release NA-VQA upon publication.
CounterVid: Counterfactual Video Generation for Mitigating Action and Temporal Hallucinations in Video-Language Models
Jan 08, 2026Video-language models (VLMs) achieve strong multimodal understanding but remain prone to hallucinations, especially when reasoning about actions and temporal order. Existing mitigation strategies, such as textual filtering or random video perturbations, often fail to address the root cause: over-reliance on language priors rather than fine-grained visual dynamics. We propose a scalable framework for counterfactual video generation that synthesizes videos differing only in actions or temporal structure while preserving scene context. Our pipeline combines multimodal LLMs for action proposal and editing guidance with diffusion-based image and video models to generate semantic hard negatives at scale. Using this framework, we build CounterVid, a synthetic dataset of ~26k preference pairs targeting action recognition and temporal reasoning. We further introduce MixDPO, a unified Direct Preference Optimization approach that jointly leverages textual and visual preferences. Fine-tuning Qwen2.5-VL with MixDPO yields consistent improvements, notably in temporal ordering, and transfers effectively to standard video hallucination benchmarks. Code and models will be made publicly available.
From Frames to Clips: Efficient Key Clip Selection for Long-Form Video Understanding
Oct 02, 2025Video Large Language Models (VLMs) have achieved remarkable results on a variety of vision language tasks, yet their practical use is limited by the "needle in a haystack" problem: the massive number of visual tokens produced from raw video frames exhausts the model's context window. Existing solutions alleviate this issue by selecting a sparse set of frames, thereby reducing token count, but such frame-wise selection discards essential temporal dynamics, leading to suboptimal reasoning about motion and event continuity. In this work we systematically explore the impact of temporal information and demonstrate that extending selection from isolated key frames to key clips, which are short, temporally coherent segments, improves video understanding. To maintain a fixed computational budget while accommodating the larger token footprint of clips, we propose an adaptive resolution strategy that dynamically balances spatial resolution and clip length, ensuring a constant token count per video. Experiments on three long-form video benchmarks demonstrate that our training-free approach, F2C, outperforms uniform sampling up to 8.1%, 5.6%, and 10.3% on Video-MME, LongVideoBench and MLVU benchmarks, respectively. These results highlight the importance of preserving temporal coherence in frame selection and provide a practical pathway for scaling Video LLMs to real world video understanding applications. Project webpage is available at https://guangyusun.com/f2c .
Augment the Pairs: Semantics-Preserving Image-Caption Pair Augmentation for Grounding-Based Vision and Language Models
Nov 05, 2023Grounding-based vision and language models have been successfully applied to low-level vision tasks, aiming to precisely locate objects referred in captions. The effectiveness of grounding representation learning heavily relies on the scale of the training dataset. Despite being a useful data enrichment strategy, data augmentation has received minimal attention in existing vision and language tasks as augmentation for image-caption pairs is non-trivial. In this study, we propose a robust phrase grounding model trained with text-conditioned and text-unconditioned data augmentations. Specifically, we apply text-conditioned color jittering and horizontal flipping to ensure semantic consistency between images and captions. To guarantee image-caption correspondence in the training samples, we modify the captions according to pre-defined keywords when applying horizontal flipping. Additionally, inspired by recent masked signal reconstruction, we propose to use pixel-level masking as a novel form of data augmentation. While we demonstrate our data augmentation method with MDETR framework, the proposed approach is applicable to common grounding-based vision and language tasks with other frameworks. Finally, we show that image encoder pretrained on large-scale image and language datasets (such as CLIP) can further improve the results. Through extensive experiments on three commonly applied datasets: Flickr30k, referring expressions and GQA, our method demonstrates advanced performance over the state-of-the-arts with various metrics. Code can be found in https://github.com/amzn/augment-the-pairs-wacv2024.
GOHSP: A Unified Framework of Graph and Optimization-based Heterogeneous Structured Pruning for Vision Transformer
Jan 13, 2023The recently proposed Vision transformers (ViTs) have shown very impressive empirical performance in various computer vision tasks, and they are viewed as an important type of foundation model. However, ViTs are typically constructed with large-scale sizes, which then severely hinder their potential deployment in many practical resources-constrained applications. To mitigate this challenging problem, structured pruning is a promising solution to compress model size and enable practical efficiency. However, unlike its current popularity for CNNs and RNNs, structured pruning for ViT models is little explored. In this paper, we propose GOHSP, a unified framework of Graph and Optimization-based Structured Pruning for ViT models. We first develop a graph-based ranking for measuring the importance of attention heads, and the extracted importance information is further integrated to an optimization-based procedure to impose the heterogeneous structured sparsity patterns on the ViT models. Experimental results show that our proposed GOHSP demonstrates excellent compression performance. On CIFAR-10 dataset, our approach can bring 40% parameters reduction with no accuracy loss for ViT-Small model. On ImageNet dataset, with 30% and 35% sparsity ratio for DeiT-Tiny and DeiT-Small models, our approach achieves 1.65% and 0.76% accuracy increase over the existing structured pruning methods, respectively.
Negative Data Augmentation
Feb 09, 2021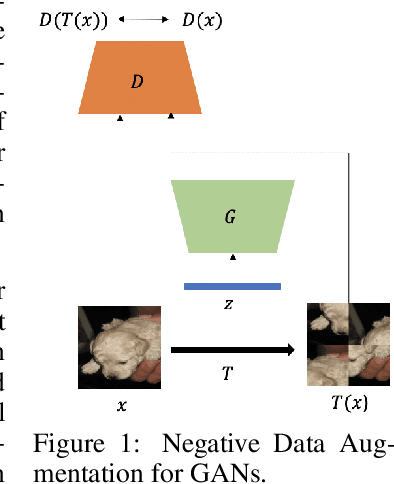



Data augmentation is often used to enlarge datasets with synthetic samples generated in accordance with the underlying data distribution. To enable a wider range of augmentations, we explore negative data augmentation strategies (NDA)that intentionally create out-of-distribution samples. We show that such negative out-of-distribution samples provide information on the support of the data distribution, and can be leveraged for generative modeling and representation learning. We introduce a new GAN training objective where we use NDA as an additional source of synthetic data for the discriminator. We prove that under suitable conditions, optimizing the resulting objective still recovers the true data distribution but can directly bias the generator towards avoiding samples that lack the desired structure. Empirically, models trained with our method achieve improved conditional/unconditional image generation along with improved anomaly detection capabilities. Further, we incorporate the same negative data augmentation strategy in a contrastive learning framework for self-supervised representation learning on images and videos, achieving improved performance on downstream image classification, object detection, and action recognition tasks. These results suggest that prior knowledge on what does not constitute valid data is an effective form of weak supervision across a range of unsupervised learning tasks.
Efficient Conditional Pre-training for Transfer Learning
Dec 10, 2020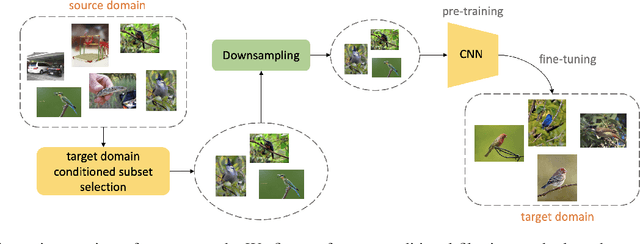
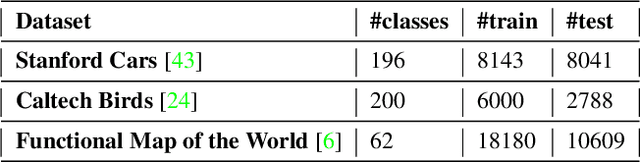
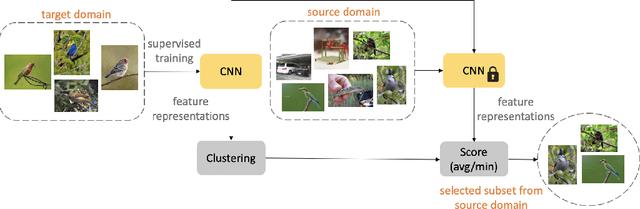
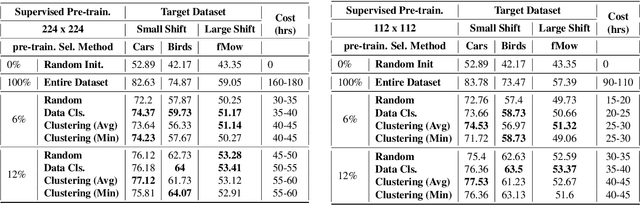
Almost all the state-of-the-art neural networks for computer vision tasks are trained by (1) Pre-training on a large scale dataset and (2) finetuning on the target dataset. This strategy helps reduce the dependency on the target dataset and improves convergence rate and generalization on the target task. Although pre-training on large scale datasets is very useful, its foremost disadvantage is high training cost. To address this, we propose efficient target dataset conditioned filtering methods to remove less relevant samples from the pre-training dataset. Unlike prior work, we focus on efficiency, adaptability, and flexibility in addition to performance. Additionally, we discover that lowering image resolutions in the pre-training step offers a great trade-off between cost and performance. We validate our techniques by pre-training on ImageNet in both the unsupervised and supervised settings and finetuning on a diverse collection of target datasets and tasks. Our proposed methods drastically reduce pre-training cost and provide strong performance boosts.
Geography-Aware Self-Supervised Learning
Dec 02, 2020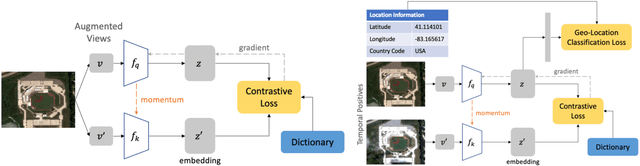
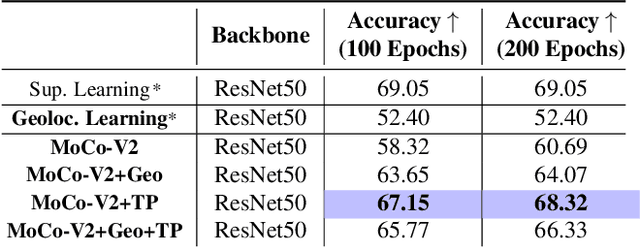

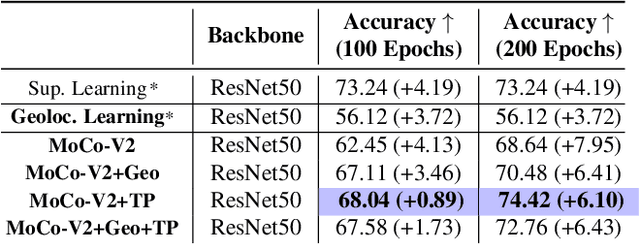
Contrastive learning methods have significantly narrowed the gap between supervised and unsupervised learning on computer vision tasks. In this paper, we explore their application to remote sensing, where unlabeled data is often abundant but labeled data is scarce. We first show that due to their different characteristics, a non-trivial gap persists between contrastive and supervised learning on standard benchmarks. To close the gap, we propose novel training methods that exploit the spatiotemporal structure of remote sensing data. We leverage spatially aligned images over time to construct temporal positive pairs in contrastive learning and geo-location to design pre-text tasks. Our experiments show that our proposed method closes the gap between contrastive and supervised learning on image classification, object detection and semantic segmentation for remote sensing and other geo-tagged image datasets.
Predicting Livelihood Indicators from Crowdsourced Street Level Images
Jun 27, 2020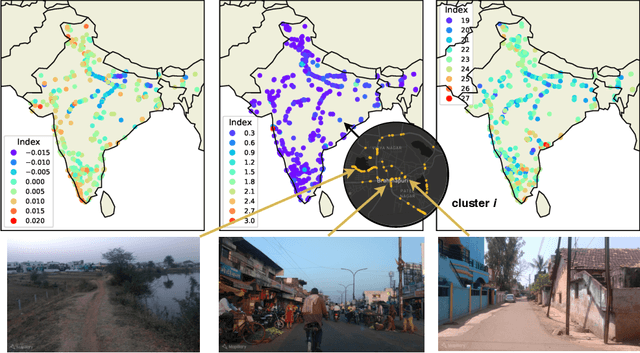
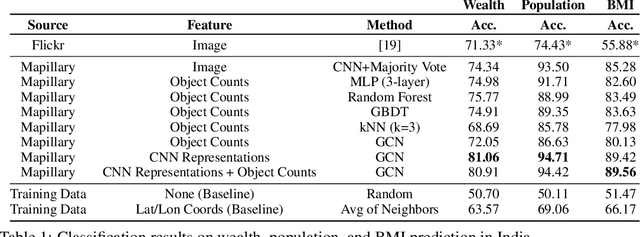
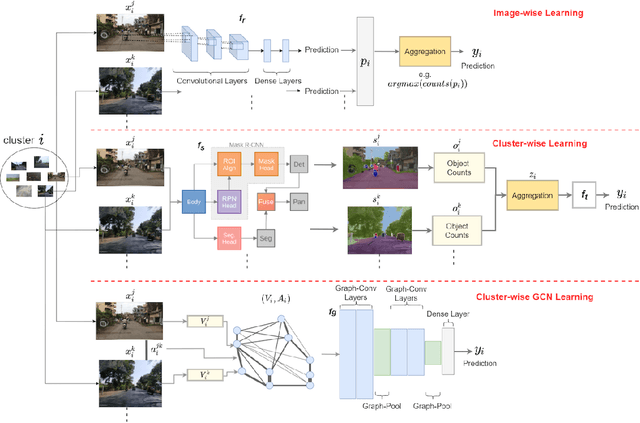
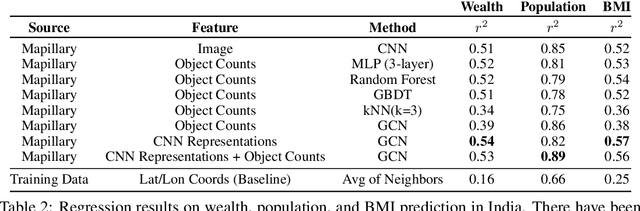
Major decisions from governments and other large organizations rely on measurements of the populace's well-being, but making such measurements at a broad scale is expensive and thus infrequent in much of the developing world. We propose an inexpensive, scalable, and interpretable approach to predict key livelihood indicators from public crowd-sourced street-level imagery. Such imagery can be cheaply collected and more frequently updated compared to traditional surveying methods, while containing plausibly relevant information for a range of livelihood indicators. We propose two approaches to learn from the street-level imagery. First method creates multihousehold cluster representations by detecting informative objects and the second method uses a graph-based approach that leverages the inherent structure between images. By visualizing what features are important to a model and how they are used, we can help end-user organizations understand the models and offer an alternate approach for index estimation that uses cheaply obtained roadway features. By comparing our results against ground data collected in nationally-representative household surveys, we show our approach can be used to accurately predict indicators of poverty, population, and health across India.