 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeepOpht: Medical Report Generation for Retinal Images via Deep Models and Visual Explanation
Nov 01, 2020
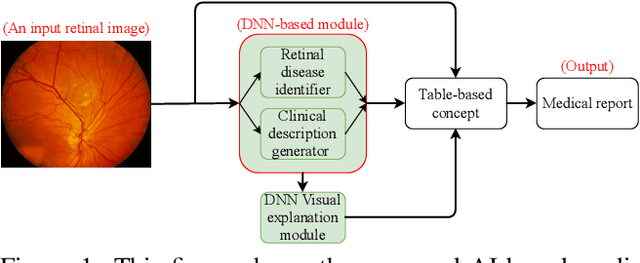
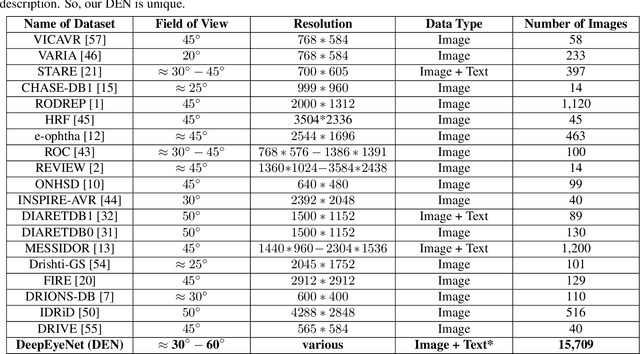
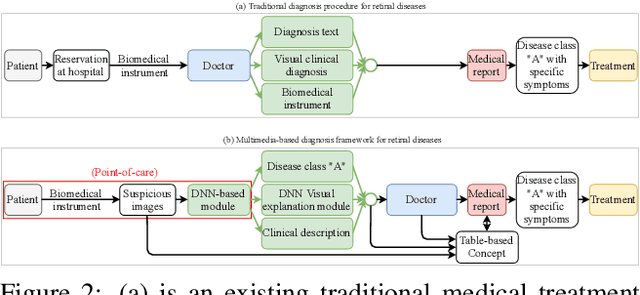
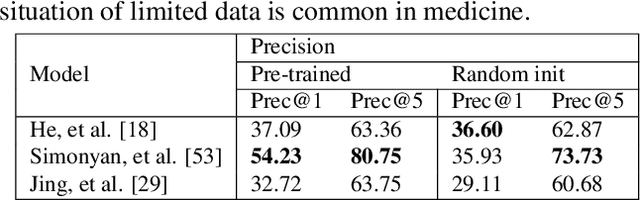
In this work, we propose an AI-based method that intends to improve the conventional retinal disease treatment procedure and help ophthalmologists increase diagnosis efficiency and accuracy. The proposed method is composed of a deep neural networks-based (DNN-based) module, including a retinal disease identifier and clinical description generator, and a DNN visual explanation module. To train and validate the effectiveness of our DNN-based module, we propose a large-scale retinal disease image dataset. Also, as ground truth, we provide a retinal image dataset manually labeled by ophthalmologists to qualitatively show, the proposed AI-based method is effective. With our experimental results, we show that the proposed method is quantitatively and qualitatively effective. Our method is capable of creating meaningful retinal image descriptions and visual explanations that are clinically relevant.
Learning Single-Image Depth from Videos using Quality Assessment Networks
Jun 25, 2018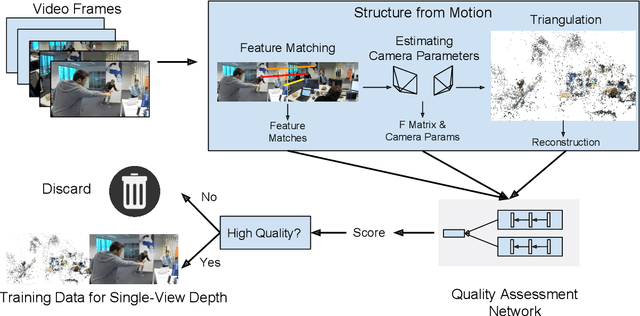
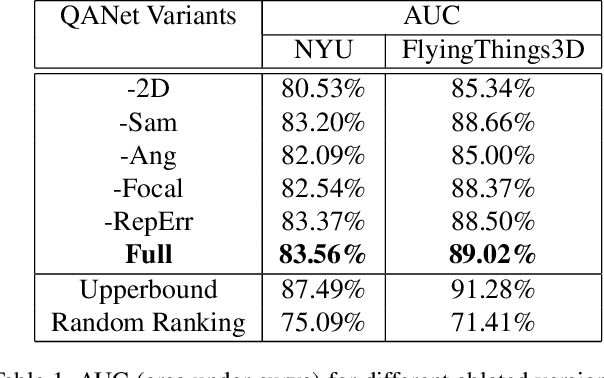
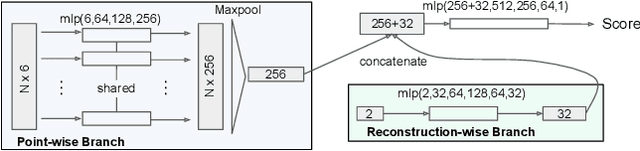
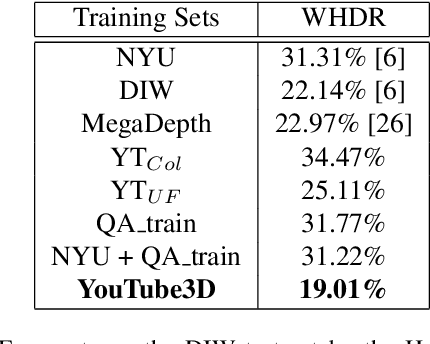
Although significant progress has been made in recent years, depth estimation from a single image in the wild is still a very challenging problem. One reason is the lack of high-quality image-depth data in the wild. In this paper we propose a fully automatic pipeline based on Structure-from-Motion (SfM) to generate such data from arbitrary videos. The core of this pipeline is a Quality Assessment Network that can distinguish correct and incorrect reconstructions obtained from SfM. With the proposed pipeline, we generate image-depth data from the NYU Depth dataset and random YouTube videos. We show that depth-prediction networks trained on such data can achieve competitive performance on the NYU Depth and the Depth-in-the-Wild benchmarks.
Camera-based Image Forgery Localization using Convolutional Neural Networks
Aug 29, 2018
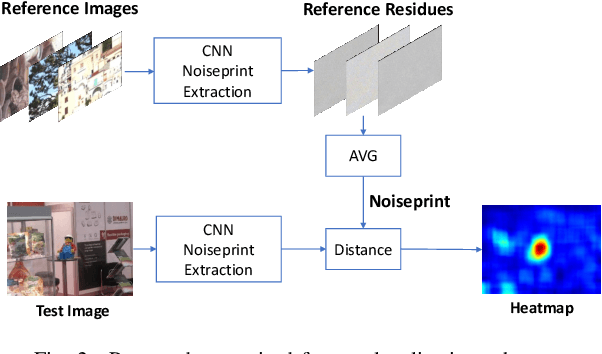
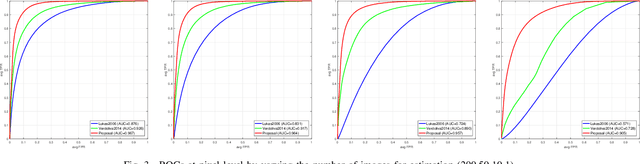
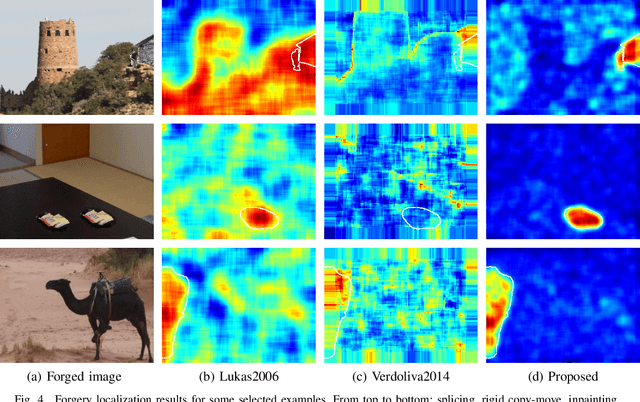
Camera fingerprints are precious tools for a number of image forensics tasks. A well-known example is the photo response non-uniformity (PRNU) noise pattern, a powerful device fingerprint. Here, to address the image forgery localization problem, we rely on noiseprint, a recently proposed CNN-based camera model fingerprint. The CNN is trained to minimize the distance between same-model patches, and maximize the distance otherwise. As a result, the noiseprint accounts for model-related artifacts just like the PRNU accounts for device-related non-uniformities. However, unlike the PRNU, it is only mildly affected by residuals of high-level scene content. The experiments show that the proposed noiseprint-based forgery localization method improves over the PRNU-based reference.
Measuring economic activity from space: a case study using flying airplanes and COVID-19
Apr 21, 2021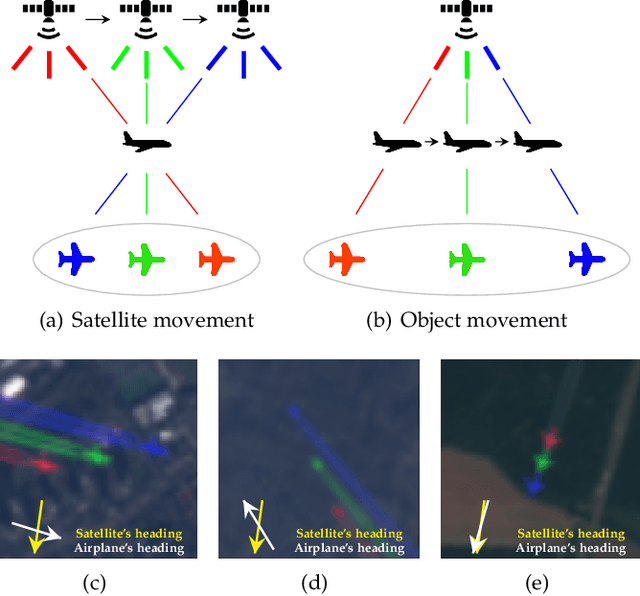
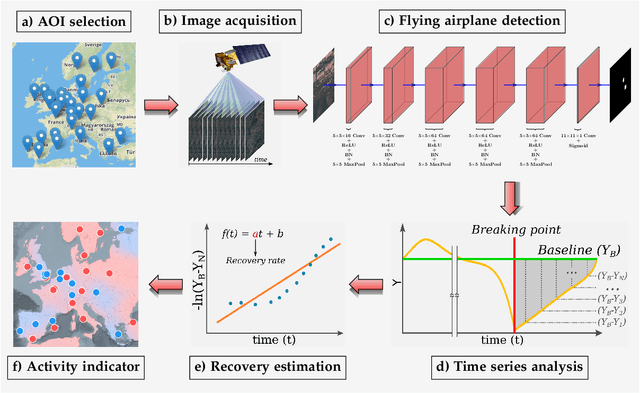
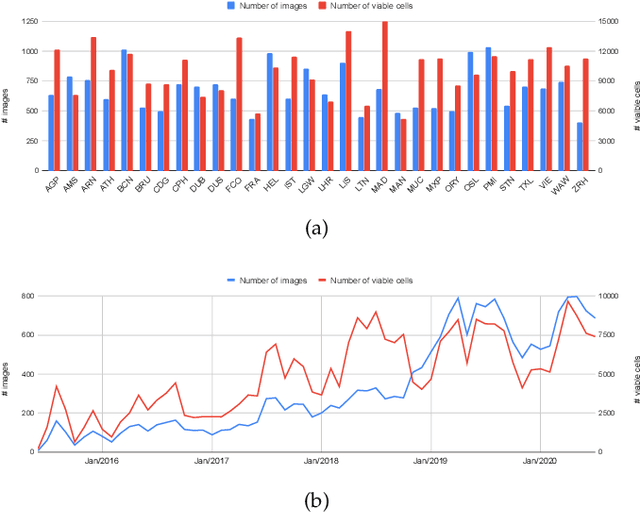
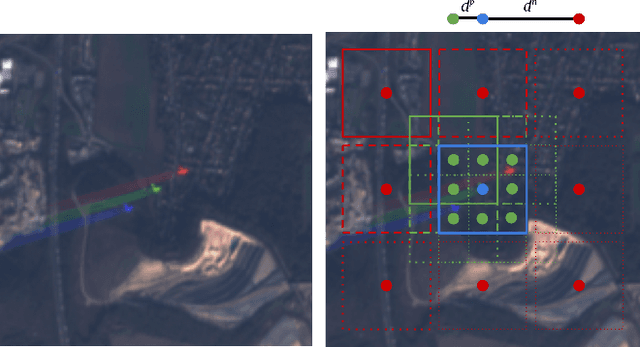
This work introduces a novel solution to measure economic activity through remote sensing for a wide range of spatial areas. We hypothesized that disturbances in human behavior caused by major life-changing events leave signatures in satellite imagery that allows devising relevant image-based indicators to estimate their impacts and support decision-makers. We present a case study for the COVID-19 coronavirus outbreak, which imposed severe mobility restrictions and caused worldwide disruptions, using flying airplane detection around the 30 busiest airports in Europe to quantify and analyze the lockdown's effects and post-lockdown recovery. Our solution won the Rapid Action Coronavirus Earth observation (RACE) upscaling challenge, sponsored by the European Space Agency and the European Commission, and now integrates the RACE dashboard. This platform combines satellite data and artificial intelligence to promote a progressive and safe reopening of essential activities. Code and CNN models are available at https://github.com/maups/covid19-custom-script-contest
OAAE: Adversarial Autoencoders for Novelty Detection in Multi-modal Normality Case via Orthogonalized Latent Space
Jan 07, 2021
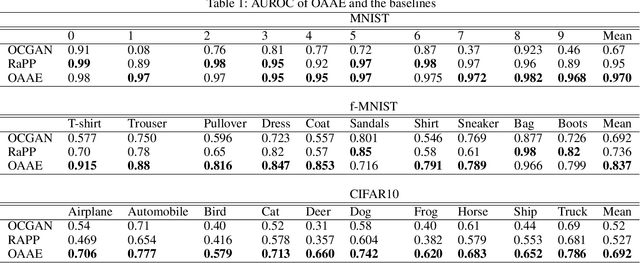
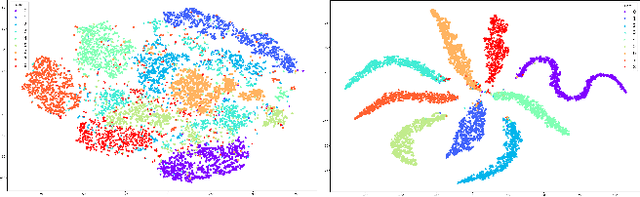
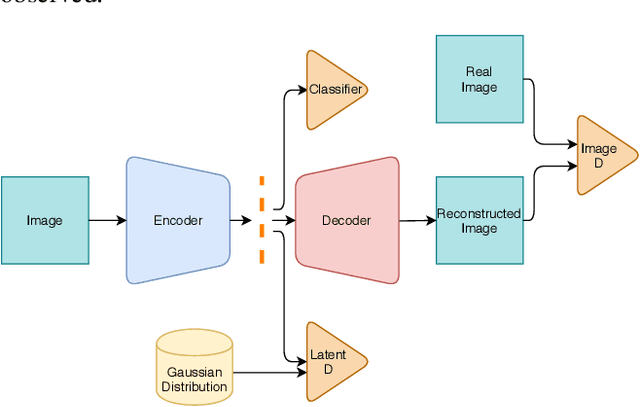
Novelty detection using deep generative models such as autoencoder, generative adversarial networks mostly takes image reconstruction error as novelty score function. However, image data, high dimensional as it is, contains a lot of different features other than class information which makes models hard to detect novelty data. The problem gets harder in multi-modal normality case. To address this challenge, we propose a new way of measuring novelty score in multi-modal normality cases using orthogonalized latent space. Specifically, we employ orthogonal low-rank embedding in the latent space to disentangle the features in the latent space using mutual class information. With the orthogonalized latent space, novelty score is defined by the change of each latent vector. Proposed algorithm was compared to state-of-the-art novelty detection algorithms using GAN such as RaPP and OCGAN, and experimental results show that ours outperforms those algorithms.
Vision Transformers are Robust Learners
May 18, 2021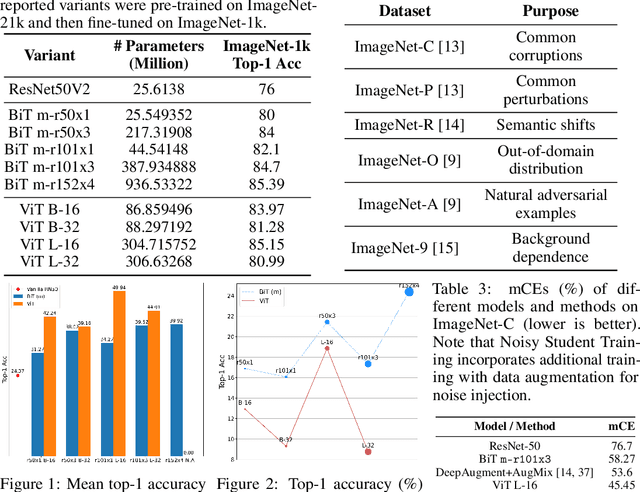
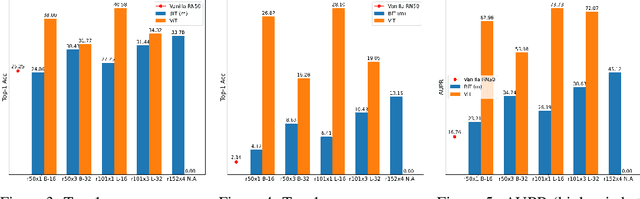
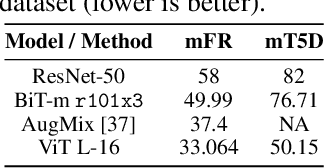

Transformers, composed of multiple self-attention layers, hold strong promises toward a generic learning primitive applicable to different data modalities, including the recent breakthroughs in computer vision achieving state-of-the-art (SOTA) standard accuracy with better parameter efficiency. Since self-attention helps a model systematically align different components present inside the input data, it leaves grounds to investigate its performance under model robustness benchmarks. In this work, we study the robustness of the Vision Transformer (ViT) against common corruptions and perturbations, distribution shifts, and natural adversarial examples. We use six different diverse ImageNet datasets concerning robust classification to conduct a comprehensive performance comparison of ViT models and SOTA convolutional neural networks (CNNs), Big-Transfer. Through a series of six systematically designed experiments, we then present analyses that provide both quantitative and qualitative indications to explain why ViTs are indeed more robust learners. For example, with fewer parameters and similar dataset and pre-training combinations, ViT gives a top-1 accuracy of 28.10% on ImageNet-A which is 4.3x higher than a comparable variant of BiT. Our analyses on image masking, Fourier spectrum sensitivity, and spread on discrete cosine energy spectrum reveal intriguing properties of ViT attributing to improved robustness. Code for reproducing our experiments is available here: https://git.io/J3VO0.
ScaleCom: Scalable Sparsified Gradient Compression for Communication-Efficient Distributed Training
Apr 21, 2021
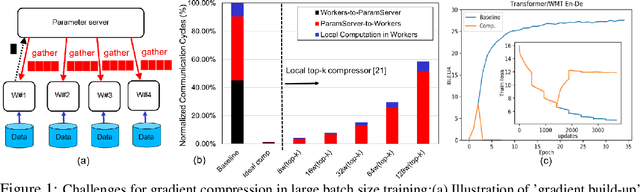
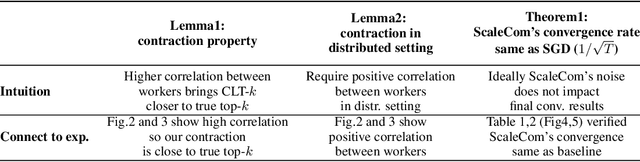
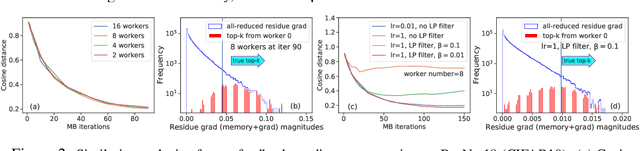
Large-scale distributed training of Deep Neural Networks (DNNs) on state-of-the-art platforms is expected to be severely communication constrained. To overcome this limitation, numerous gradient compression techniques have been proposed and have demonstrated high compression ratios. However, most existing methods do not scale well to large scale distributed systems (due to gradient build-up) and/or fail to evaluate model fidelity (test accuracy) on large datasets. To mitigate these issues, we propose a new compression technique, Scalable Sparsified Gradient Compression (ScaleCom), that leverages similarity in the gradient distribution amongst learners to provide significantly improved scalability. Using theoretical analysis, we show that ScaleCom provides favorable convergence guarantees and is compatible with gradient all-reduce techniques. Furthermore, we experimentally demonstrate that ScaleCom has small overheads, directly reduces gradient traffic and provides high compression rates (65-400X) and excellent scalability (up to 64 learners and 8-12X larger batch sizes over standard training) across a wide range of applications (image, language, and speech) without significant accuracy loss.
Finding a Needle in a Haystack: Tiny Flying Object Detection in 4K Videos using a Joint Detection-and-Tracking Approach
May 18, 2021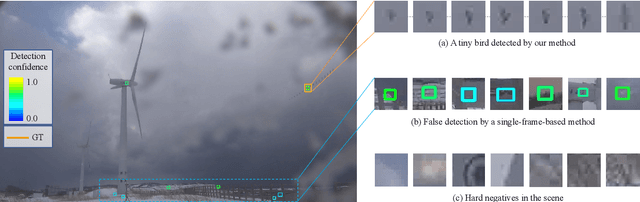
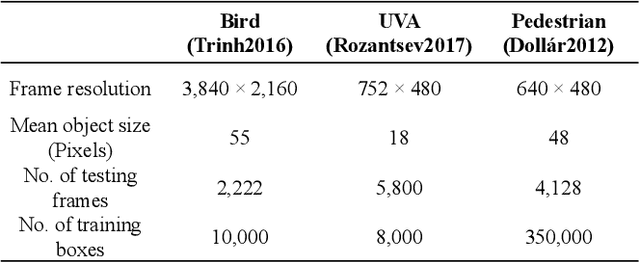

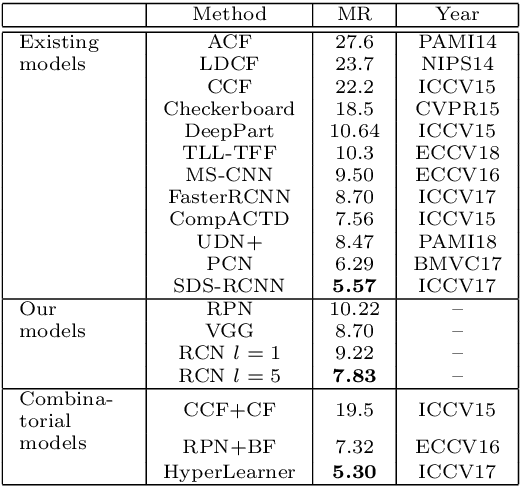
Detecting tiny objects in a high-resolution video is challenging because the visual information is little and unreliable. Specifically, the challenge includes very low resolution of the objects, MPEG artifacts due to compression and a large searching area with many hard negatives. Tracking is equally difficult because of the unreliable appearance, and the unreliable motion estimation. Luckily, we found that by combining this two challenging tasks together, there will be mutual benefits. Following the idea, in this paper, we present a neural network model called the Recurrent Correlational Network, where detection and tracking are jointly performed over a multi-frame representation learned through a single, trainable, and end-to-end network. The framework exploits a convolutional long short-term memory network for learning informative appearance changes for detection, while the learned representation is shared in tracking for enhancing its performance. In experiments with datasets containing images of scenes with small flying objects, such as birds and unmanned aerial vehicles, the proposed method yielded consistent improvements in detection performance over deep single-frame detectors and existing motion-based detectors. Furthermore, our network performs as well as state-of-the-art generic object trackers when it was evaluated as a tracker on a bird image dataset.
Real-time Monocular Depth Estimation with Sparse Supervision on Mobile
May 25, 2021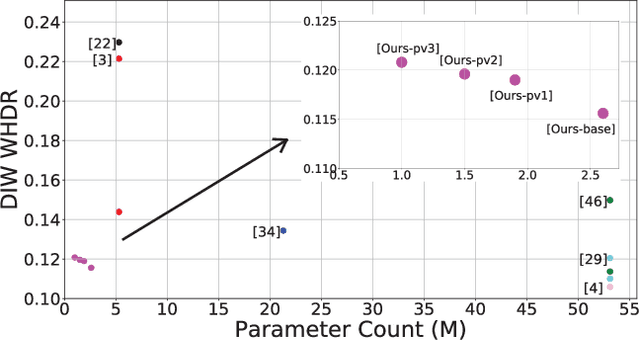
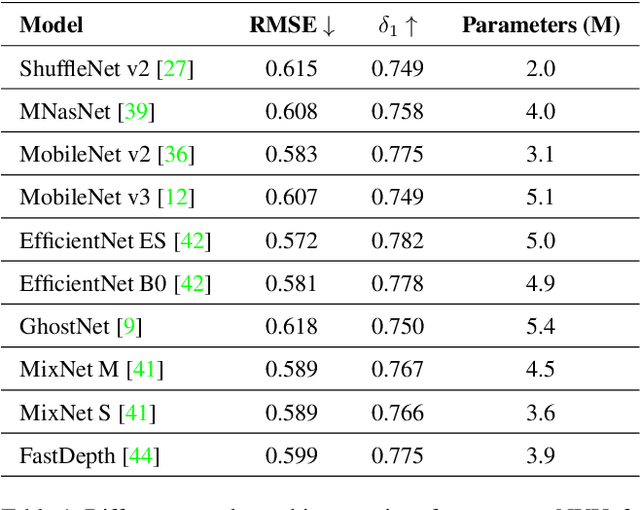
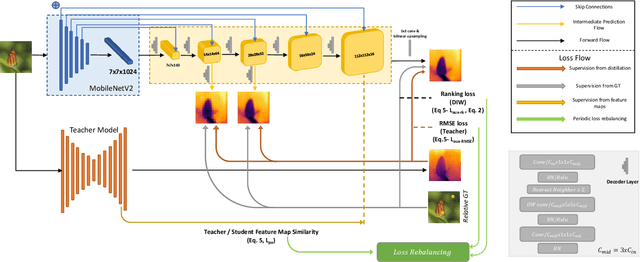
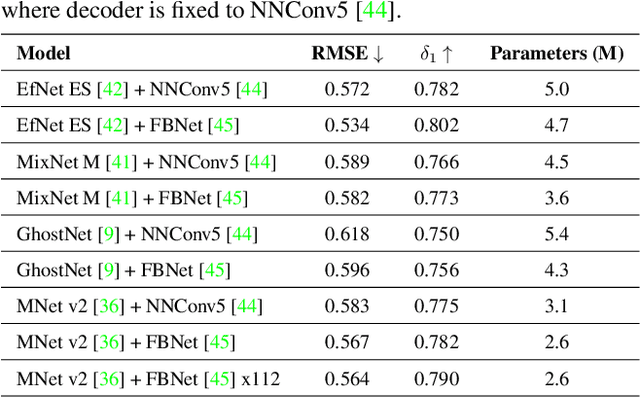
Monocular (relative or metric) depth estimation is a critical task for various applications, such as autonomous vehicles, augmented reality and image editing. In recent years, with the increasing availability of mobile devices, accurate and mobile-friendly depth models have gained importance. Increasingly accurate models typically require more computational resources, which inhibits the use of such models on mobile devices. The mobile use case is arguably the most unrestricted one, which requires highly accurate yet mobile-friendly architectures. Therefore, we try to answer the following question: How can we improve a model without adding further complexity (i.e. parameters)? Towards this end, we systematically explore the design space of a relative depth estimation model from various dimensions and we show, with key design choices and ablation studies, even an existing architecture can reach highly competitive performance to the state of the art, with a fraction of the complexity. Our study spans an in-depth backbone model selection process, knowledge distillation, intermediate predictions, model pruning and loss rebalancing. We show that our model, using only DIW as the supervisory dataset, achieves 0.1156 WHDR on DIW with 2.6M parameters and reaches 37 FPS on a mobile GPU, without pruning or hardware-specific optimization. A pruned version of our model achieves 0.1208 WHDR on DIW with 1M parameters and reaches 44 FPS on a mobile GPU.
Recurrent neural networks for aortic image sequence segmentation with sparse annotations
Aug 01, 2018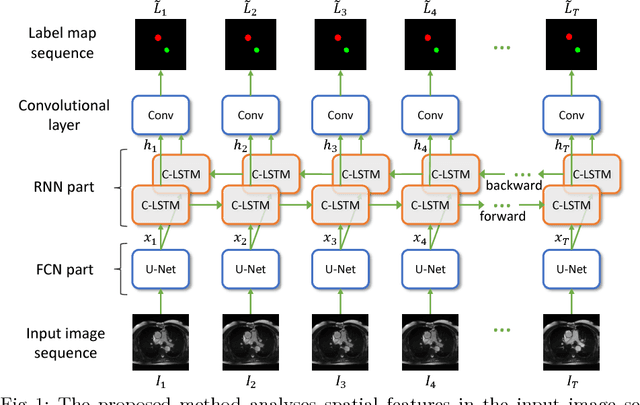
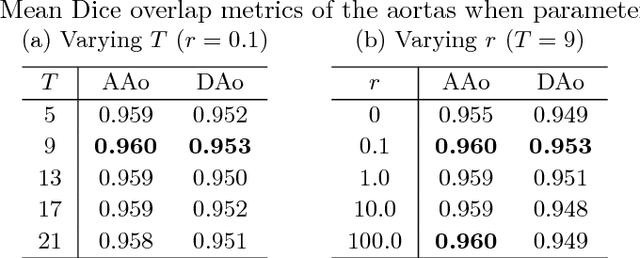
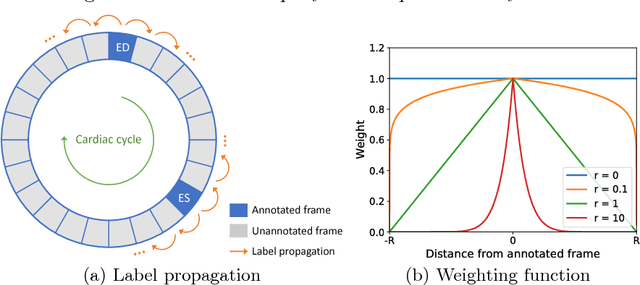

Segmentation of image sequences is an important task in medical image analysis, which enables clinicians to assess the anatomy and function of moving organs. However, direct application of a segmentation algorithm to each time frame of a sequence may ignore the temporal continuity inherent in the sequence. In this work, we propose an image sequence segmentation algorithm by combining a fully convolutional network with a recurrent neural network, which incorporates both spatial and temporal information into the segmentation task. A key challenge in training this network is that the available manual annotations are temporally sparse, which forbids end-to-end training. We address this challenge by performing non-rigid label propagation on the annotations and introducing an exponentially weighted loss function for training. Experiments on aortic MR image sequences demonstrate that the proposed method significantly improves both accuracy and temporal smoothness of segmentation, compared to a baseline method that utilises spatial information only. It achieves an average Dice metric of 0.960 for the ascending aorta and 0.953 for the descending aorta.