 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural 3D Scene Compression via Model Compression
May 07, 2021
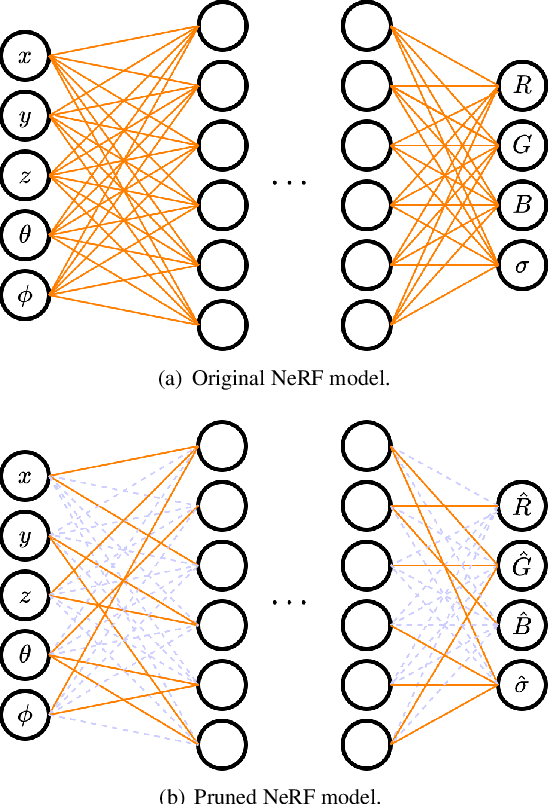
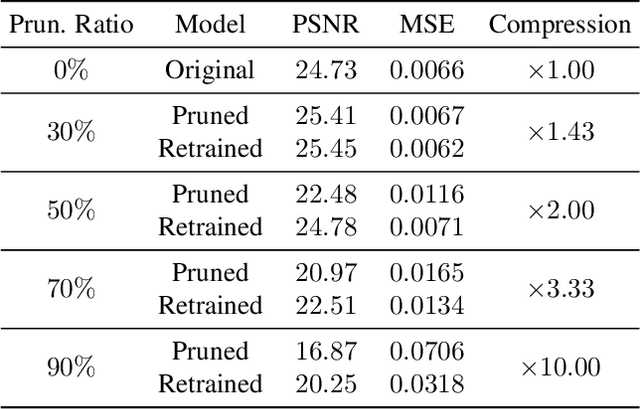
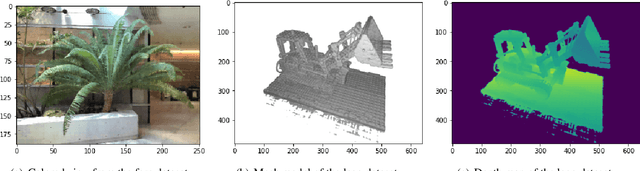
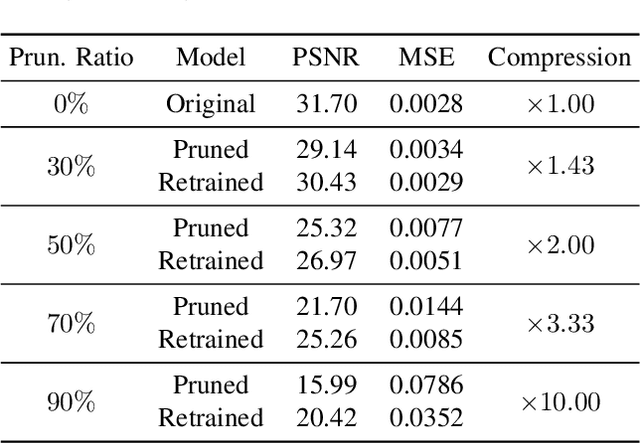
Rendering 3D scenes requires access to arbitrary viewpoints from the scene. Storage of such a 3D scene can be done in two ways; (1) storing 2D images taken from the 3D scene that can reconstruct the scene back through interpolations, or (2) storing a representation of the 3D scene itself that already encodes views from all directions. So far, traditional 3D compression methods have focused on the first type of storage and compressed the original 2D images with image compression techniques. With this approach, the user first decodes the stored 2D images and then renders the 3D scene. However, this separated procedure is inefficient since a large amount of 2D images have to be stored. In this work, we take a different approach and compress a functional representation of 3D scenes. In particular, we introduce a method to compress 3D scenes by compressing the neural networks that represent the scenes as neural radiance fields. Our method provides more efficient storage of 3D scenes since it does not store 2D images -- which are redundant when we render the scene from the neural functional representation.
SteganoGAN: Pushing the Limits of Image Steganography
Jan 12, 2019
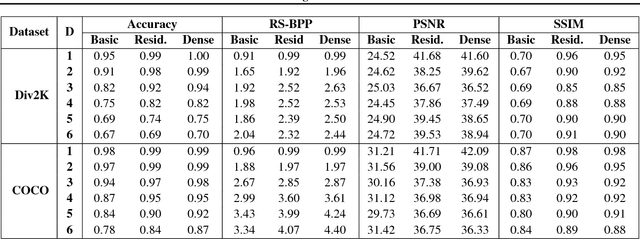
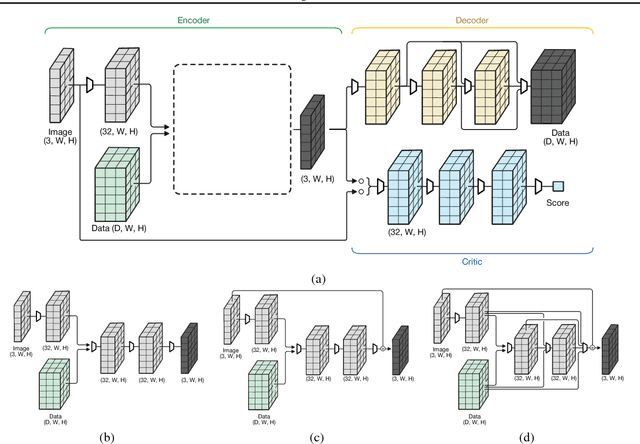

Image steganography is a procedure for hiding messages inside pictures. While other techniques such as cryptography aim to prevent adversaries from reading the secret message, steganography aims to hide the presence of the message itself. In this paper, we propose a novel technique based on generative adversarial networks for hiding arbitrary binary data in images. We show that our approach achieves state-of-the-art payloads of 4.4 bits per pixel, evades detection by steganalysis tools, and is effective on images from multiple datasets. To enable fair comparisons, we have released an open source library that is available online at https://github.com/DAI-Lab/SteganoGAN.
One-shot Representational Learning for Joint Biometric and Device Authentication
Jan 02, 2021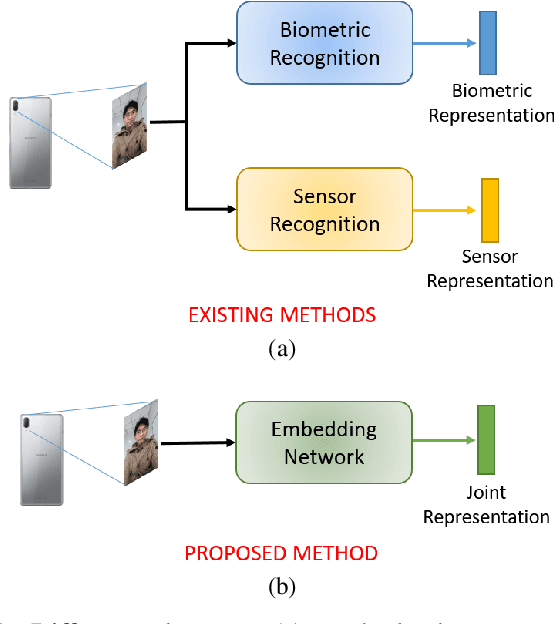
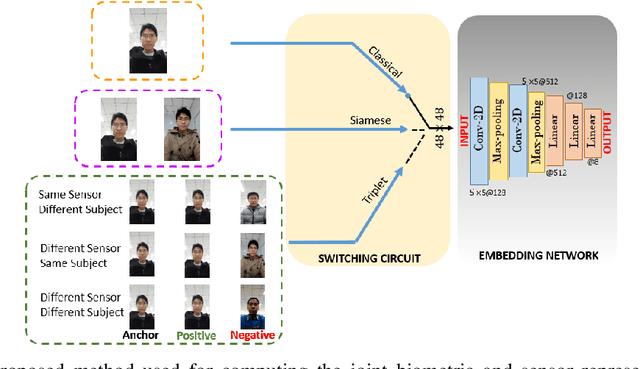
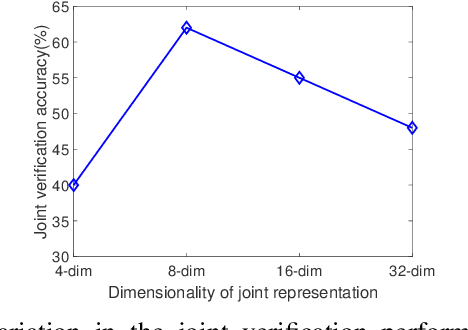
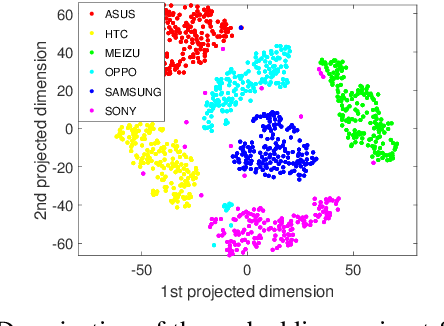
In this work, we propose a method to simultaneously perform (i) biometric recognition (i.e., identify the individual), and (ii) device recognition, (i.e., identify the device) from a single biometric image, say, a face image, using a one-shot schema. Such a joint recognition scheme can be useful in devices such as smartphones for enhancing security as well as privacy. We propose to automatically learn a joint representation that encapsulates both biometric-specific and sensor-specific features. We evaluate the proposed approach using iris, face and periocular images acquired using near-infrared iris sensors and smartphone cameras. Experiments conducted using 14,451 images from 15 sensors resulted in a rank-1 identification accuracy of upto 99.81% and a verification accuracy of upto 100% at a false match rate of 1%.
Deep Image Set Hashing
Oct 01, 2016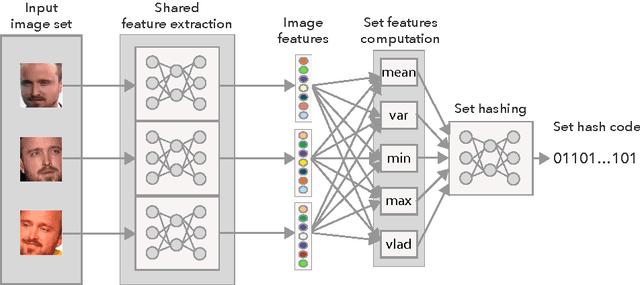
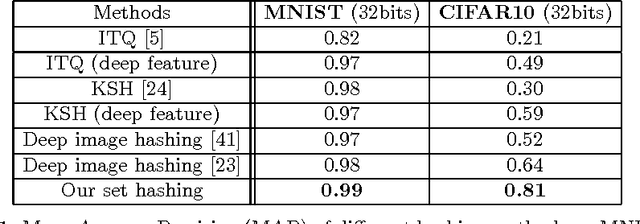
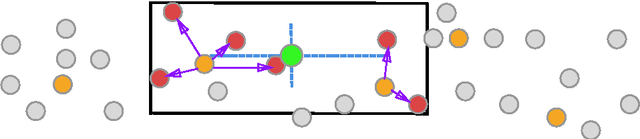

In applications involving matching of image sets, the information from multiple images must be effectively exploited to represent each set. State-of-the-art methods use probabilistic distribution or subspace to model a set and use specific distance measure to compare two sets. These methods are slow to compute and not compact to use in a large scale scenario. Learning-based hashing is often used in large scale image retrieval as they provide a compact representation of each sample and the Hamming distance can be used to efficiently compare two samples. However, most hashing methods encode each image separately and discard knowledge that multiple images in the same set represent the same object or person. We investigate the set hashing problem by combining both set representation and hashing in a single deep neural network. An image set is first passed to a CNN module to extract image features, then these features are aggregated using two types of set feature to capture both set specific and database-wide distribution information. The computed set feature is then fed into a multilayer perceptron to learn a compact binary embedding. Triplet loss is used to train the network by forming set similarity relations using class labels. We extensively evaluate our approach on datasets used for image matching and show highly competitive performance compared to state-of-the-art methods.
Resolution enhancement in the recovery of underdrawings via style transfer by generative adversarial deep neural networks
Jan 30, 2021



We apply generative adversarial convolutional neural networks to the problem of style transfer to underdrawings and ghost-images in x-rays of fine art paintings with a special focus on enhancing their spatial resolution. We build upon a neural architecture developed for the related problem of synthesizing high-resolution photo-realistic image from semantic label maps. Our neural architecture achieves high resolution through a hierarchy of generators and discriminator sub-networks, working throughout a range of spatial resolutions. This coarse-to-fine generator architecture can increase the effective resolution by a factor of eight in each spatial direction, or an overall increase in number of pixels by a factor of 64. We also show that even just a few examples of human-generated image segmentations can greatly improve -- qualitatively and quantitatively -- the generated images. We demonstrate our method on works such as Leonardo's Madonna of the carnation and the underdrawing in his Virgin of the rocks, which pose several special problems in style transfer, including the paucity of representative works from which to learn and transfer style information.
RankSRGAN: Generative Adversarial Networks with Ranker for Image Super-Resolution
Aug 26, 2019
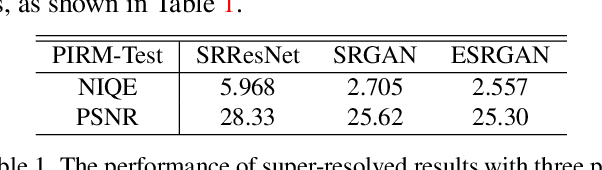
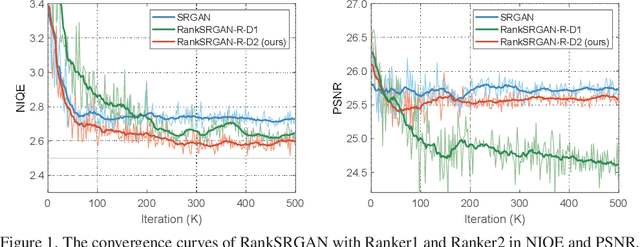
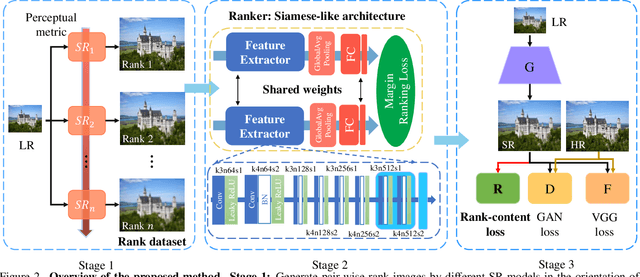
Generative Adversarial Networks (GAN) have demonstrated the potential to recover realistic details for single image super-resolution (SISR). To further improve the visual quality of super-resolved results, PIRM2018-SR Challenge employed perceptual metrics to assess the perceptual quality, such as PI, NIQE, and Ma. However, existing methods cannot directly optimize these indifferentiable perceptual metrics, which are shown to be highly correlated with human ratings. To address the problem, we propose Super-Resolution Generative Adversarial Networks with Ranker (RankSRGAN) to optimize generator in the direction of perceptual metrics. Specifically, we first train a Ranker which can learn the behavior of perceptual metrics and then introduce a novel rank-content loss to optimize the perceptual quality. The most appealing part is that the proposed method can combine the strengths of different SR methods to generate better results. Extensive experiments show that RankSRGAN achieves visually pleasing results and reaches state-of-the-art performance in perceptual metrics. Project page: https://wenlongzhang0724.github.io/Projects/RankSRGAN
Learning to Efficiently Sample from Diffusion Probabilistic Models
Jun 07, 2021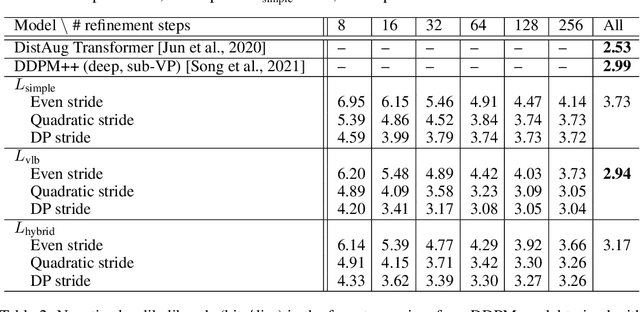
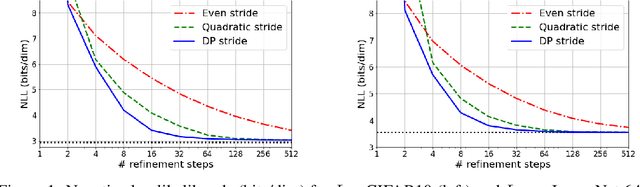
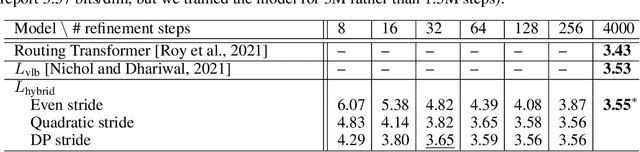
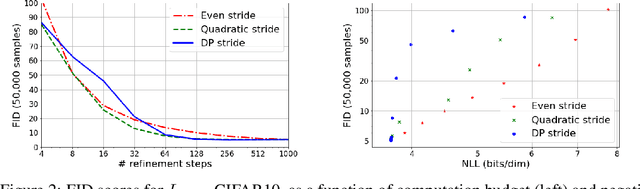
Denoising Diffusion Probabilistic Models (DDPMs) have emerged as a powerful family of generative models that can yield high-fidelity samples and competitive log-likelihoods across a range of domains, including image and speech synthesis. Key advantages of DDPMs include ease of training, in contrast to generative adversarial networks, and speed of generation, in contrast to autoregressive models. However, DDPMs typically require hundreds-to-thousands of steps to generate a high fidelity sample, making them prohibitively expensive for high dimensional problems. Fortunately, DDPMs allow trading generation speed for sample quality through adjusting the number of refinement steps as a post process. Prior work has been successful in improving generation speed through handcrafting the time schedule by trial and error. We instead view the selection of the inference time schedules as an optimization problem, and introduce an exact dynamic programming algorithm that finds the optimal discrete time schedules for any pre-trained DDPM. Our method exploits the fact that ELBO can be decomposed into separate KL terms, and given any computation budget, discovers the time schedule that maximizes the training ELBO exactly. Our method is efficient, has no hyper-parameters of its own, and can be applied to any pre-trained DDPM with no retraining. We discover inference time schedules requiring as few as 32 refinement steps, while sacrificing less than 0.1 bits per dimension compared to the default 4,000 steps used on ImageNet 64x64 [Ho et al., 2020; Nichol and Dhariwal, 2021].
Fisheye Lens Camera based Autonomous Valet Parking System
Apr 27, 2021



This paper proposes an efficient autonomous valet parking system utilizing only cameras which are the most widely used sensor. To capture more information instantaneously and respond rapidly to changes in the surrounding environment, fisheye cameras which have a wider angle of view compared to pinhole cameras are used. Accordingly, visual simultaneous localization and mapping is used to identify the layout of the parking lot and track the location of the vehicle. In addition, the input image frames are converted into around view monitor images to resolve the distortion of fisheye lens because the algorithm to detect edges are supposed to be applied to images taken with pinhole cameras. The proposed system adopts a look up table for real time operation by minimizing the computational complexity encountered when processing AVM images. The detection rate of each process and the success rate of autonomous parking were measured to evaluate performance. The experimental results confirm that autonomous parking can be achieved using only visual sensors.
A Comprehensive Study of ImageNet Pre-Training for Historical Document Image Analysis
May 22, 2019


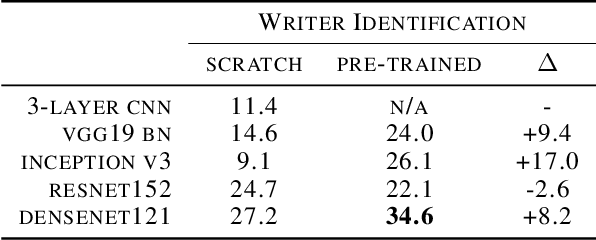
Automatic analysis of scanned historical documents comprises a wide range of image analysis tasks, which are often challenging for machine learning due to a lack of human-annotated learning samples. With the advent of deep neural networks, a promising way to cope with the lack of training data is to pre-train models on images from a different domain and then fine-tune them on historical documents. In the current research, a typical example of such cross-domain transfer learning is the use of neural networks that have been pre-trained on the ImageNet database for object recognition. It remains a mostly open question whether or not this pre-training helps to analyse historical documents, which have fundamentally different image properties when compared with ImageNet. In this paper, we present a comprehensive empirical survey on the effect of ImageNet pre-training for diverse historical document analysis tasks, including character recognition, style classification, manuscript dating, semantic segmentation, and content-based retrieval. While we obtain mixed results for semantic segmentation at pixel-level, we observe a clear trend across different network architectures that ImageNet pre-training has a positive effect on classification as well as content-based retrieval.
Joint Representation Learning and Novel Category Discovery on Single- and Multi-modal Data
Apr 27, 2021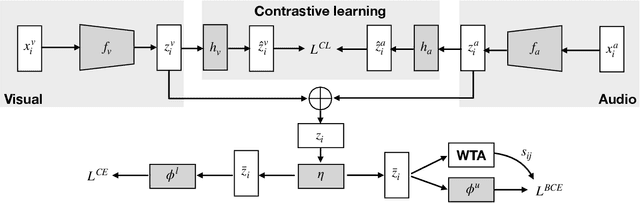
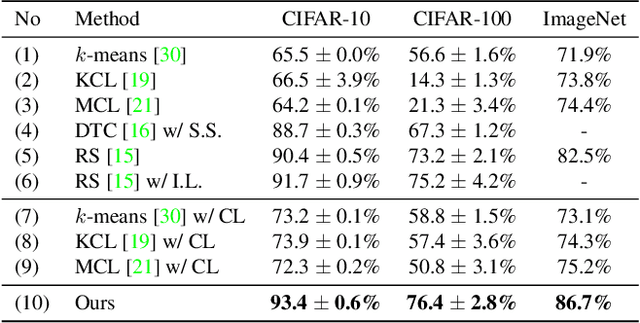
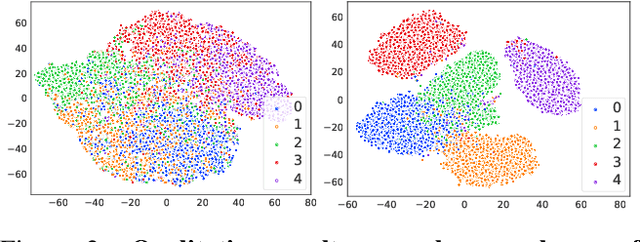
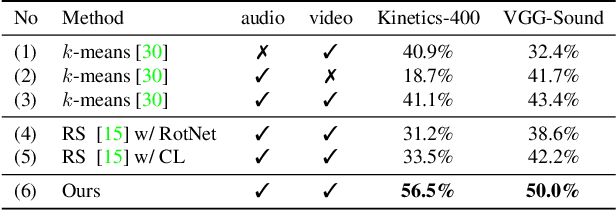
This paper studies the problem of novel category discovery on single- and multi-modal data with labels from different but relevant categories. We present a generic, end-to-end framework to jointly learn a reliable representation and assign clusters to unlabelled data. To avoid over-fitting the learnt embedding to labelled data, we take inspiration from self-supervised representation learning by noise-contrastive estimation and extend it to jointly handle labelled and unlabelled data. In particular, we propose using category discrimination on labelled data and cross-modal discrimination on multi-modal data to augment instance discrimination used in conventional contrastive learning approaches. We further employ Winner-Take-All (WTA) hashing algorithm on the shared representation space to generate pairwise pseudo labels for unlabelled data to better predict cluster assignments. We thoroughly evaluate our framework on large-scale multi-modal video benchmarks Kinetics-400 and VGG-Sound, and image benchmarks CIFAR10, CIFAR100 and ImageNet, obtaining state-of-the-art results.