 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UMLE: Unsupervised Multi-discriminator Network for Low Light Enhancement
Dec 24, 2020



Low-light image enhancement, such as recovering color and texture details from low-light images, is a complex and vital task. For automated driving, low-light scenarios will have serious implications for vision-based applications. To address this problem, we propose a real-time unsupervised generative adversarial network (GAN) containing multiple discriminators, i.e. a multi-scale discriminator, a texture discriminator, and a color discriminator. These distinct discriminators allow the evaluation of images from different perspectives. Further, considering that different channel features contain different information and the illumination is uneven in the image, we propose a feature fusion attention module. This module combines channel attention with pixel attention mechanisms to extract image features. Additionally, to reduce training time, we adopt a shared encoder for the generator and the discriminator. This makes the structure of the model more compact and the training more stable. Experiments indicate that our method is superior to the state-of-the-art methods in qualitative and quantitative evaluations, and significant improvements are achieved for both autopilot positioning and detection results.
PolSAR Image Classification Based on Dilated Convolution and Pixel-Refining Parallel Mapping network in the Complex Domain
Sep 24, 2019
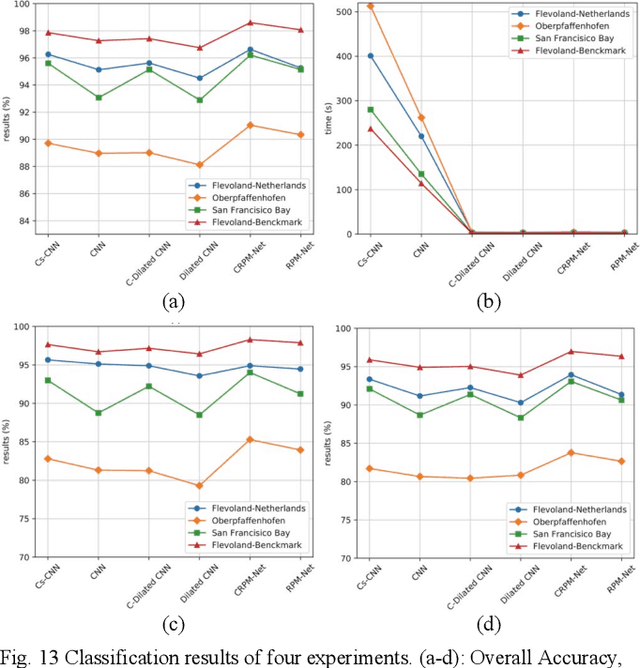
Efficient and accurate polarimetric synthetic aperture radar (PolSAR) image classification with a limited number of prior labels is always full of challenges. For general supervised deep learning classification algorithms, the pixel-by-pixel algorithm achieves precise yet inefficient classification with a small number of labeled pixels, whereas the pixel mapping algorithm achieves efficient yet edge-rough classification with more prior labels required. To take efficiency, accuracy and prior labels into account, we propose a novel pixel-refining parallel mapping network in the complex domain named CRPM-Net and the corresponding training algorithm for PolSAR image classification. CRPM-Net consists of two parallel sub-networks: a) A transfer dilated convolution mapping network in the complex domain (C-Dilated CNN) activated by a complex cross-convolution neural network (Cs-CNN), which is aiming at precise localization, high efficiency and the full use of phase information; b) A complex domain encoder-decoder network connected parallelly with C-Dilated CNN, which is to extract more contextual semantic features. Finally, we design a two-step algorithm to train the Cs-CNN and CRPM-Net with a small number of labeled pixels for higher accuracy by refining misclassified labeled pixels. We verify the proposed method on AIRSAR and E-SAR datasets. The experimental results demonstrate that CRPM-Net achieves the best classification results and substantially outperforms some latest state-of-the-art approaches in both efficiency and accuracy for PolSAR image classification. The source code and trained models for CRPM-Net is available at: https://github.com/PROoshio/CRPM-Net.
Learning to Inpaint for Image Compression
Nov 10, 2017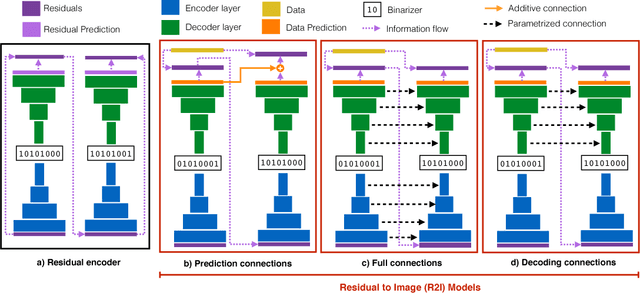

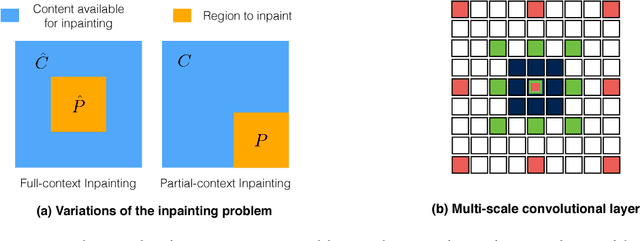
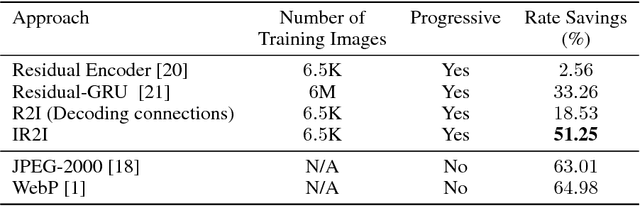
We study the design of deep architectures for lossy image compression. We present two architectural recipes in the context of multi-stage progressive encoders and empirically demonstrate their importance on compression performance. Specifically, we show that: (a) predicting the original image data from residuals in a multi-stage progressive architecture facilitates learning and leads to improved performance at approximating the original content and (b) learning to inpaint (from neighboring image pixels) before performing compression reduces the amount of information that must be stored to achieve a high-quality approximation. Incorporating these design choices in a baseline progressive encoder yields an average reduction of over $60\%$ in file size with similar quality compared to the original residual encoder.
Effect of Deep Learning Feature Inference Techniques on Respiratory Sounds
Jan 21, 2021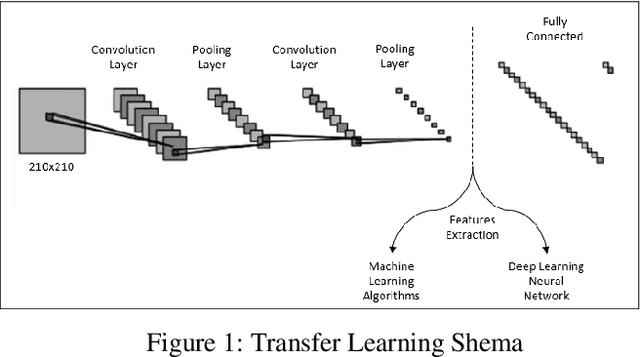
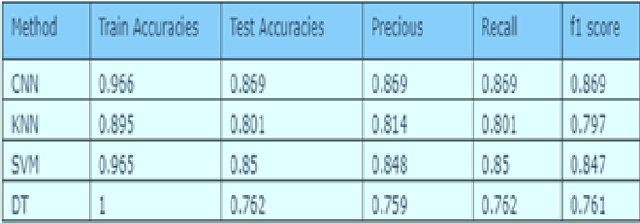
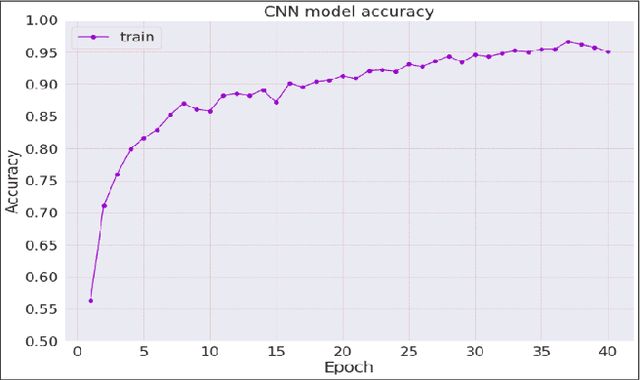
Analysis of respiratory sounds increases its importance every day. Many different methods are available in the analysis, and new techniques are continuing to be developed to further improve these methods. Features are extracted from audio signals and trained using different machine learning techniques. The use of deep learning, which is a different method and has increased in recent years, also shows its influence in this field. Deep learning techniques applied to the image of audio signals give good results and continue to be developed. In this study, image filters were applied to the values obtained from audio signals and the results of the features formed from this were examined in machine learning and deep learning techniques. Their results were compared with the results of methods that had previously achieved good results.
* 4 pages, journal of intelligent systems with applications
Rotating spiders and reflecting dogs: a class conditional approach to learning data augmentation distributions
Jun 07, 2021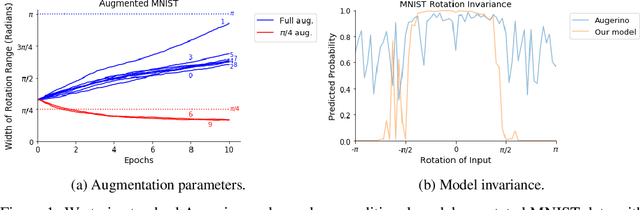
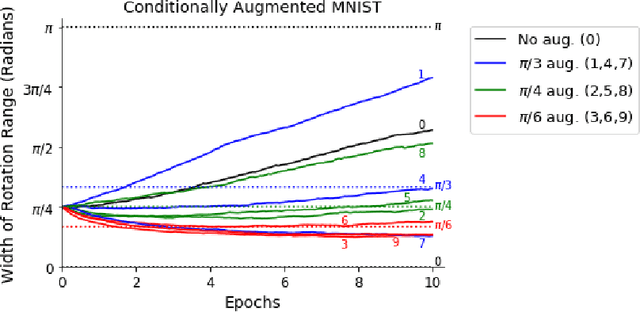
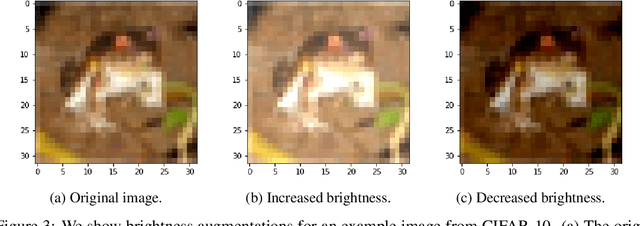
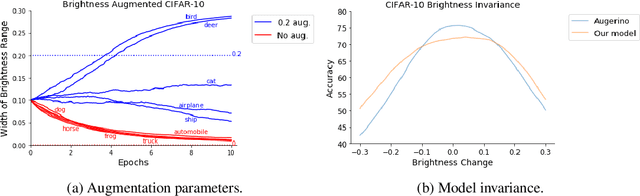
Building invariance to non-meaningful transformations is essential to building efficient and generalizable machine learning models. In practice, the most common way to learn invariance is through data augmentation. There has been recent interest in the development of methods that learn distributions on augmentation transformations from the training data itself. While such approaches are beneficial since they are responsive to the data, they ignore the fact that in many situations the range of transformations to which a model needs to be invariant changes depending on the particular class input belongs to. For example, if a model needs to be able to predict whether an image contains a starfish or a dog, we may want to apply random rotations to starfish images during training (since these do not have a preferred orientation), but we would not want to do this to images of dogs. In this work we introduce a method by which we can learn class conditional distributions on augmentation transformations. We give a number of examples where our methods learn different non-meaningful transformations depending on class and further show how our method can be used as a tool to probe the symmetries intrinsic to a potentially complex dataset.
Priority prediction of Asian Hornet sighting report using machine learning methods
Jun 28, 2021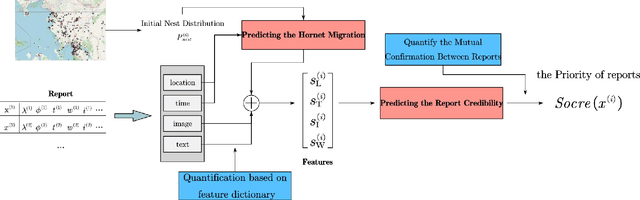
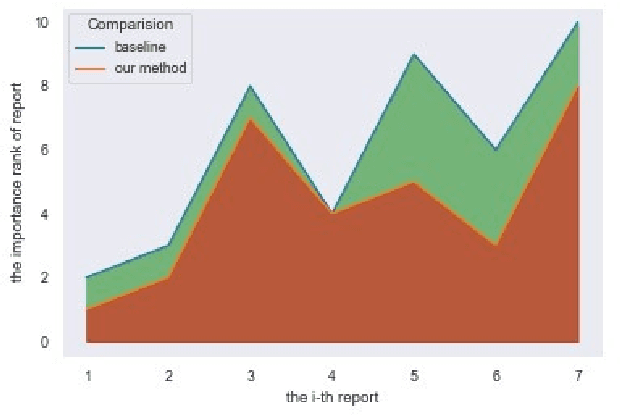
As infamous invaders to the North American ecosystem, the Asian giant hornet (Vespa mandarinia) is devastating not only to native bee colonies, but also to local apiculture. One of the most effective way to combat the harmful species is to locate and destroy their nests. By mobilizing the public to actively report possible sightings of the Asian giant hornet, the governmentcould timely send inspectors to confirm and possibly destroy the nests. However, such confirmation requires lab expertise, where manually checking the reports one by one is extremely consuming of human resources. Further given the limited knowledge of the public about the Asian giant hornet and the randomness of report submission, only few of the numerous reports proved positive, i.e. existing nests. How to classify or prioritize the reports efficiently and automatically, so as to determine the dispatch of personnel, is of great significance to the control of the Asian giant hornet. In this paper, we propose a method to predict the priority of sighting reports based on machine learning. We model the problem of optimal prioritization of sighting reports as a problem of classification and prediction. We extracted a variety of rich features in the report: location, time, image(s), and textual description. Based on these characteristics, we propose a classification model based on logistic regression to predict the credibility of a certain report. Furthermore, our model quantifies the impact between reports to get the priority ranking of the reports. Extensive experiments on the public dataset from the WSDA (the Washington State Department of Agriculture) have proved the effectiveness of our method.
Deep Semi-Supervised Learning for Time Series Classification
Feb 06, 2021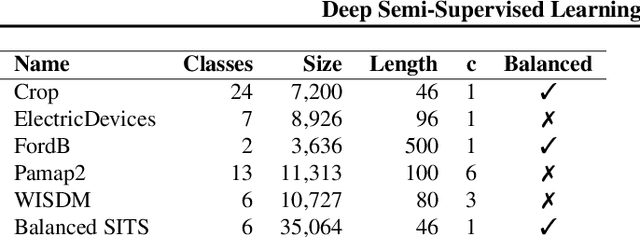
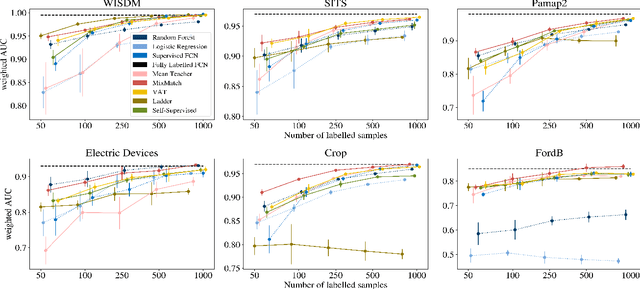
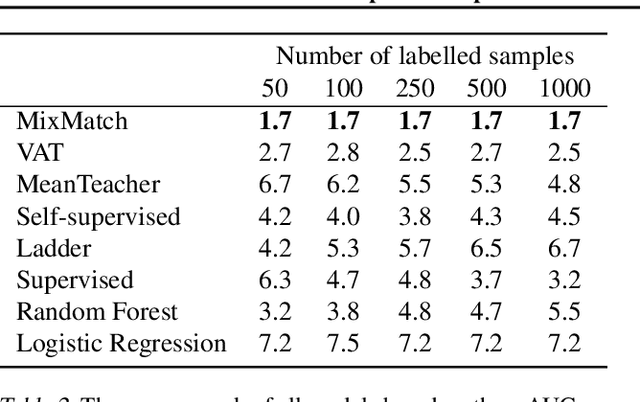
While Semi-supervised learning has gained much attention in computer vision on image data, yet limited research exists on its applicability in the time series domain. In this work, we investigate the transferability of state-of-the-art deep semi-supervised models from image to time series classification. We discuss the necessary model adaptations, in particular an appropriate model backbone architecture and the use of tailored data augmentation strategies. Based on these adaptations, we explore the potential of deep semi-supervised learning in the context of time series classification by evaluating our methods on large public time series classification problems with varying amounts of labelled samples. We perform extensive comparisons under a decidedly realistic and appropriate evaluation scheme with a unified reimplementation of all algorithms considered, which is yet lacking in the field. We find that these transferred semi-supervised models show significant performance gains over strong supervised, semi-supervised and self-supervised alternatives, especially for scenarios with very few labelled samples.
Which K-Space Sampling Schemes is good for Motion Artifact Detection in Magnetic Resonance Imaging?
Mar 15, 2021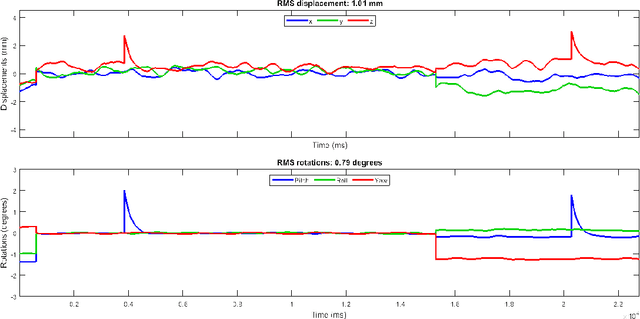
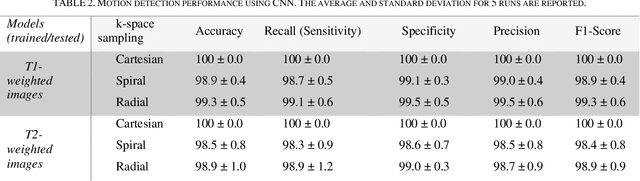
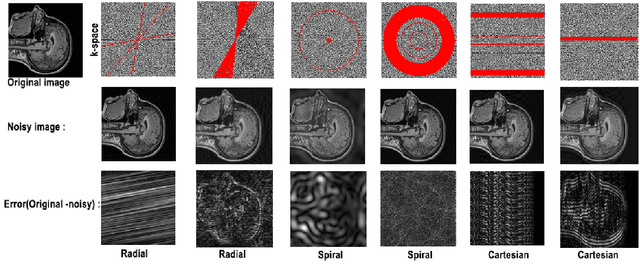
Motion artifacts are a common occurrence in the Magnetic Resonance Imaging (MRI) exam. Motion during acquisition has a profound impact on workflow efficiency, often requiring a repeat of sequences. Furthermore, motion artifacts may escape notice by technologists, only to be revealed at the time of reading by the radiologists, affecting their diagnostic quality. Designing a computer-aided tool for automatic motion detection and elimination can improve the diagnosis, however, it needs a deep understanding of motion characteristics. Motion artifacts in MRI have a complex nature and it is directly related to the k-space sampling scheme. In this study we investigate the effect of three conventional k-space samplers, including Cartesian, Uniform Spiral and Radial on motion induced image distortion. In this regard, various synthetic motions with different trajectories of displacement and rotation are applied to T1 and T2-weighted MRI images, and a convolutional neural network is trained to show the difficulty of motion classification. The results show that the spiral k-space sampling method get less effect of motion artifact in image space as compared to radial k-space sampled images, and radial k-space sampled images are more robust than Cartesian ones. Cartesian samplers, on the other hand, are the best in terms of deep learning motion detection because they can better reflect motion.
A Hybrid mmWave and Camera System for Long-Range Depth Imaging
Jun 15, 2021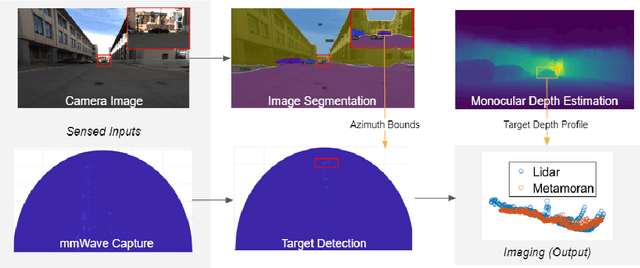
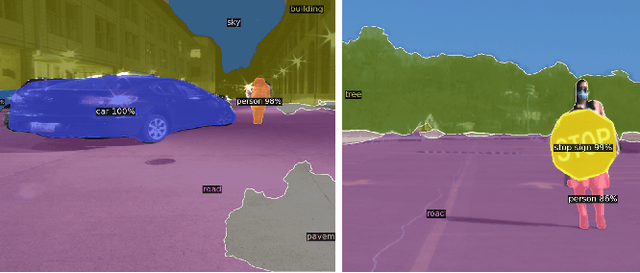
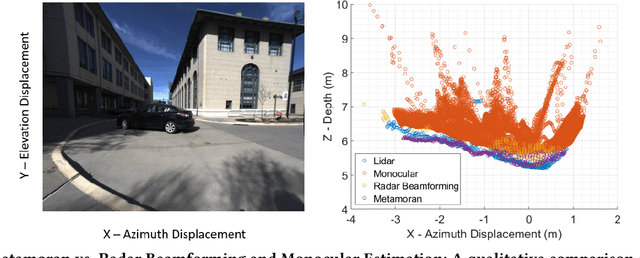

mmWave radars offer excellent depth resolution owing to their high bandwidth at mmWave radio frequencies. Yet, they suffer intrinsically from poor angular resolution, that is an order-of-magnitude worse than camera systems, and are therefore not a capable 3-D imaging solution in isolation. We propose Metamoran, a system that combines the complimentary strengths of radar and camera systems to obtain depth images at high azimuthal resolutions at distances of several tens of meters with high accuracy, all from a single fixed vantage point. Metamoran enables rich long-range depth imaging outdoors with applications to roadside safety infrastructure, surveillance and wide-area mapping. Our key insight is to use the high azimuth resolution from cameras using computer vision techniques, including image segmentation and monocular depth estimation, to obtain object shapes and use these as priors for our novel specular beamforming algorithm. We also design this algorithm to work in cluttered environments with weak reflections and in partially occluded scenarios. We perform a detailed evaluation of Metamoran's depth imaging and sensing capabilities in 200 diverse scenes at a major U.S. city. Our evaluation shows that Metamoran estimates the depth of an object up to 60~m away with a median error of 28~cm, an improvement of 13$\times$ compared to a naive radar+camera baseline and 23$\times$ compared to monocular depth estimation.
Application of the Neural Network Dependability Kit in Real-World Environments
Dec 14, 2020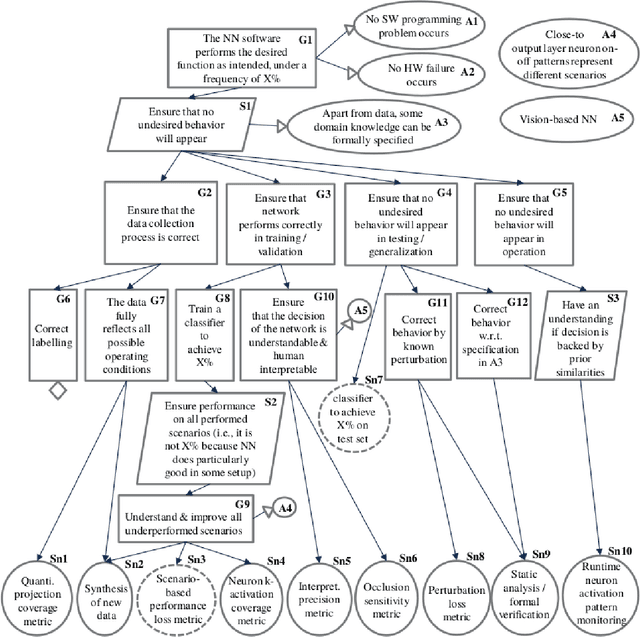
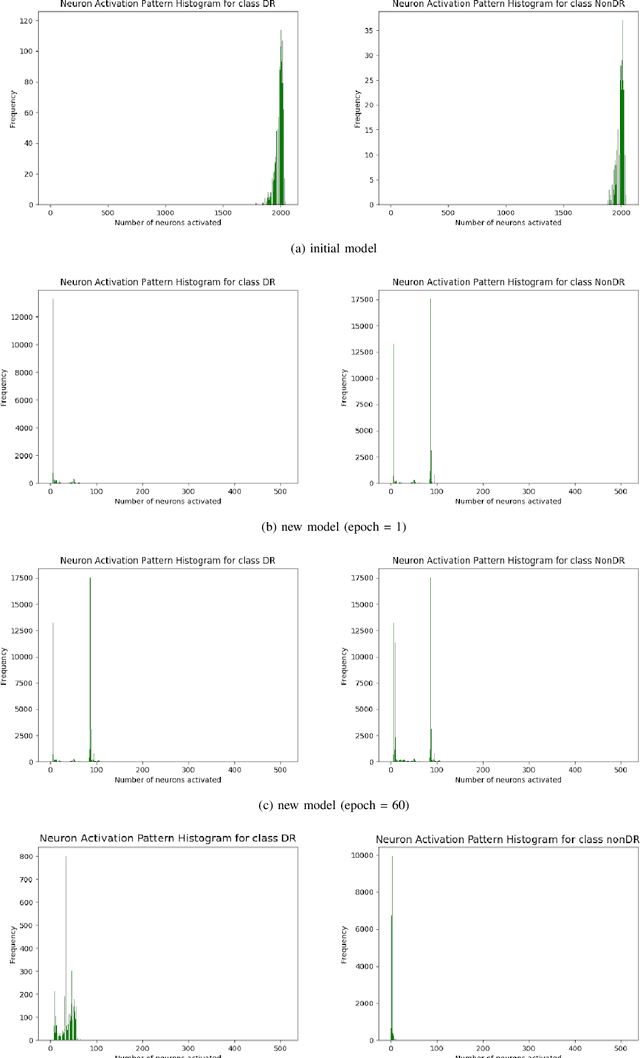
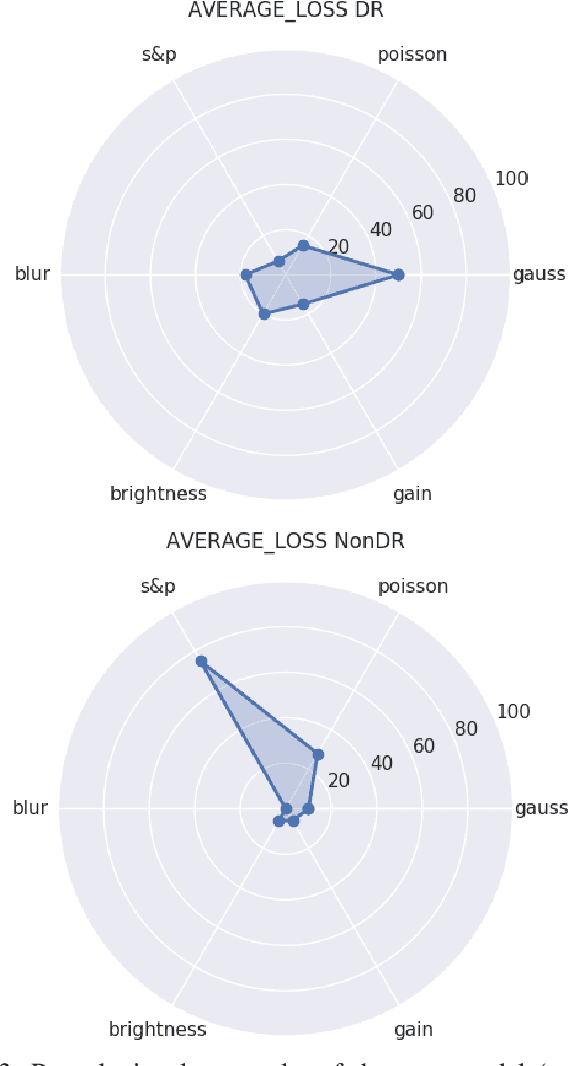
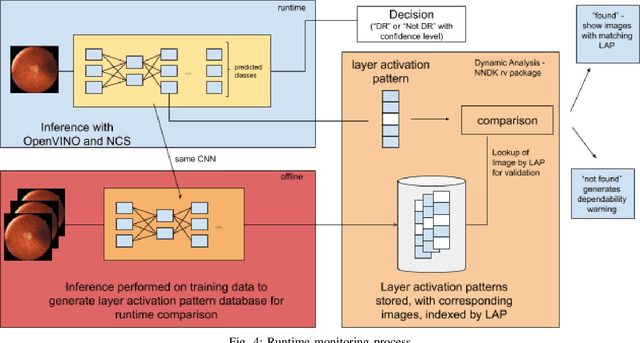
In this paper, we provide a guideline for using the Neural Network Dependability Kit (NNDK) during the development process of NN models, and show how the algorithm is applied in two image classification use cases. The case studies demonstrate the usage of the dependability kit to obtain insights about the NN model and how they informed the development process of the neural network model. After interpreting neural networks via the different metrics available in the NNDK, the developers were able to increase the NNs' accuracy, trust the developed networks, and make them more robust. In addition, we obtained a novel application-oriented technique to provide supporting evidence for an NN's classification result to the user. In the medical image classification use case, it was used to retrieve case images from the training dataset that were similar to the current patient's image and could therefore act as a support for the NN model's decision and aid doctors in interpreting the results.