 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CoIL: Coordinate-based Internal Learning for Imaging Inverse Problems
Feb 09, 2021

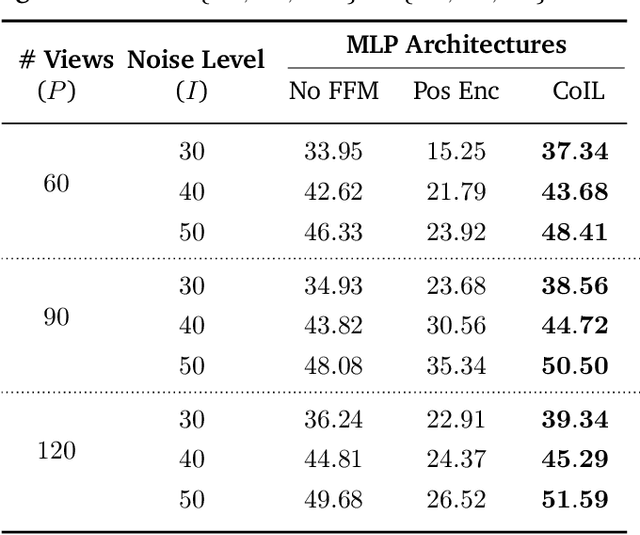
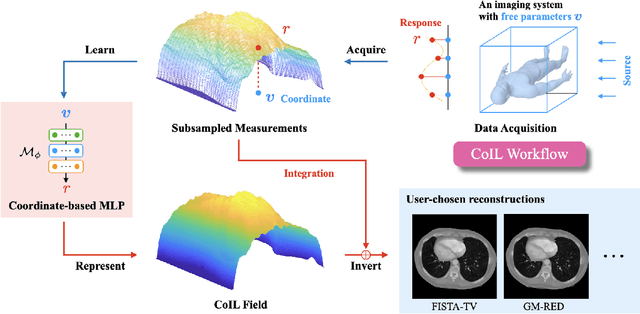
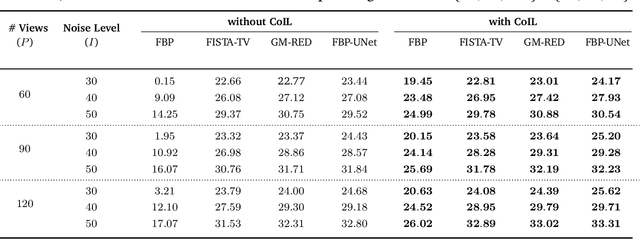
We propose Coordinate-based Internal Learning (CoIL) as a new deep-learning (DL) methodology for the continuous representation of measurements. Unlike traditional DL methods that learn a mapping from the measurements to the desired image, CoIL trains a multilayer perceptron (MLP) to encode the complete measurement field by mapping the coordinates of the measurements to their responses. CoIL is a self-supervised method that requires no training examples besides the measurements of the test object itself. Once the MLP is trained, CoIL generates new measurements that can be used within a majority of image reconstruction methods. We validate CoIL on sparse-view computed tomography using several widely-used reconstruction methods, including purely model-based methods and those based on DL. Our results demonstrate the ability of CoIL to consistently improve the performance of all the considered methods by providing high-fidelity measurement fields.
Generative Adversarial Networks for Automatic Polyp Segmentation
Dec 12, 2020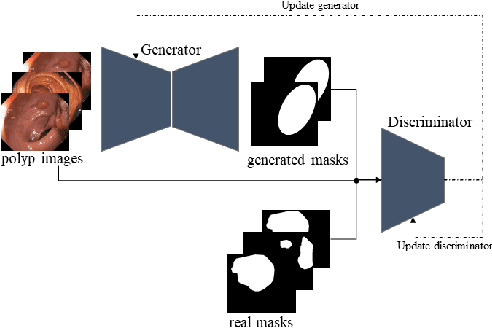
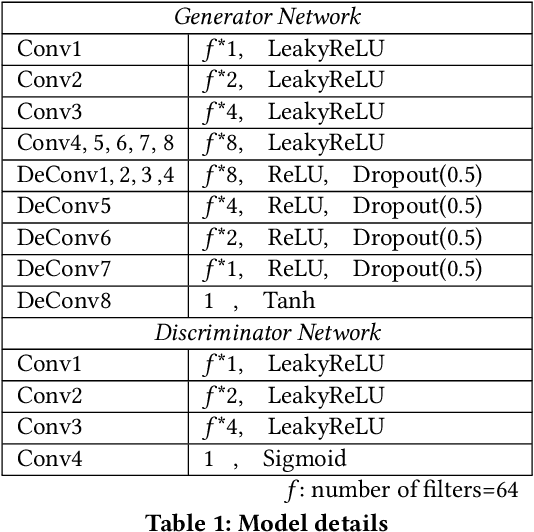

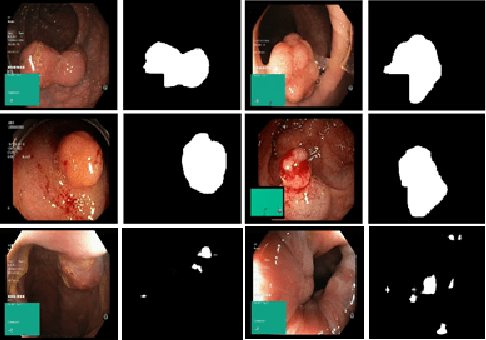
This paper aims to contribute in bench-marking the automatic polyp segmentation problem using generative adversarial networks framework. Perceiving the problem as an image-to-image translation task, conditional generative adversarial networks are utilized to generate masks conditioned by the images as inputs. Both generator and discriminator are convolution neural networks based. The model achieved 0.4382 on Jaccard index and 0.611 as F2 score.
Learning to Jointly Deblur, Demosaick and Denoise Raw Images
Apr 13, 2021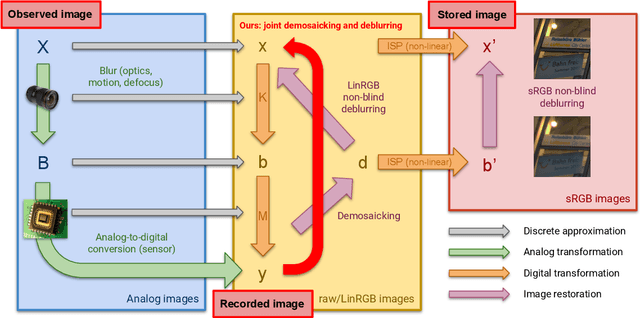
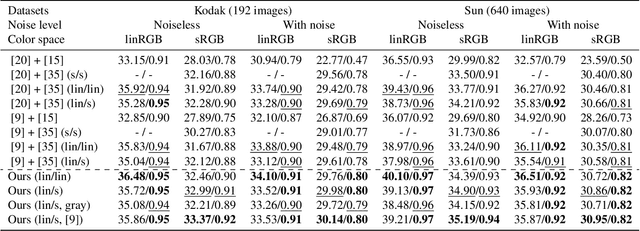
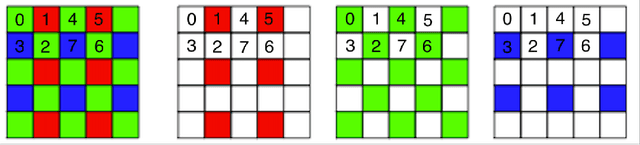
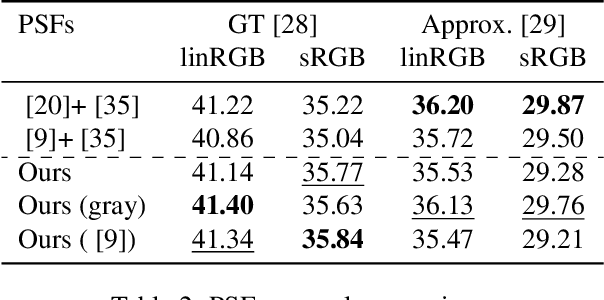
We address the problem of non-blind deblurring and demosaicking of noisy raw images. We adapt an existing learning-based approach to RGB image deblurring to handle raw images by introducing a new interpretable module that jointly demosaicks and deblurs them. We train this model on RGB images converted into raw ones following a realistic invertible camera pipeline. We demonstrate the effectiveness of this model over two-stage approaches stacking demosaicking and deblurring modules on quantitive benchmarks. We also apply our approach to remove a camera's inherent blur (its color-dependent point-spread function) from real images, in essence deblurring sharp images.
Learning Debiased Representation via Disentangled Feature Augmentation
Jul 03, 2021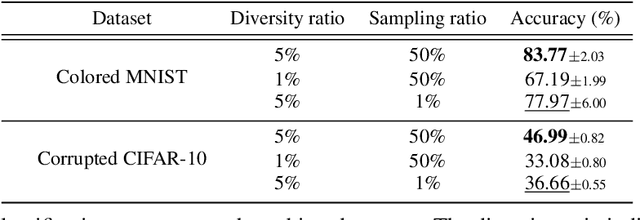
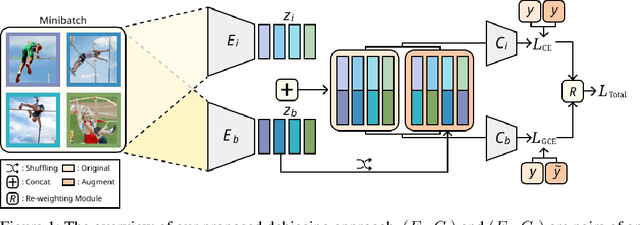

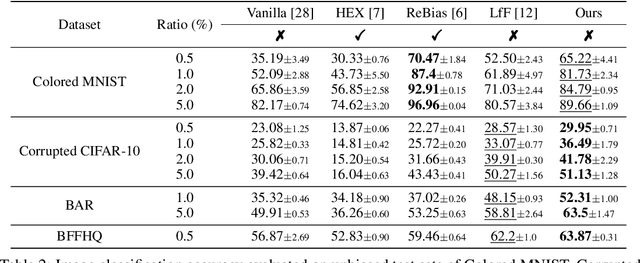
Image classification models tend to make decisions based on peripheral attributes of data items that have strong correlation with a target variable (i.e., dataset bias). These biased models suffer from the poor generalization capability when evaluated on unbiased datasets. Existing approaches for debiasing often identify and emphasize those samples with no such correlation (i.e., bias-conflicting) without defining the bias type in advance. However, such bias-conflicting samples are significantly scarce in biased datasets, limiting the debiasing capability of these approaches. This paper first presents an empirical analysis revealing that training with "diverse" bias-conflicting samples beyond a given training set is crucial for debiasing as well as the generalization capability. Based on this observation, we propose a novel feature-level data augmentation technique in order to synthesize diverse bias-conflicting samples. To this end, our method learns the disentangled representation of (1) the intrinsic attributes (i.e., those inherently defining a certain class) and (2) bias attributes (i.e., peripheral attributes causing the bias), from a large number of bias-aligned samples, the bias attributes of which have strong correlation with the target variable. Using the disentangled representation, we synthesize bias-conflicting samples that contain the diverse intrinsic attributes of bias-aligned samples by swapping their latent features. By utilizing these diversified bias-conflicting features during the training, our approach achieves superior classification accuracy and debiasing results against the existing baselines on both synthetic as well as real-world datasets.
SAG-GAN: Semi-Supervised Attention-Guided GANs for Data Augmentation on Medical Images
Nov 15, 2020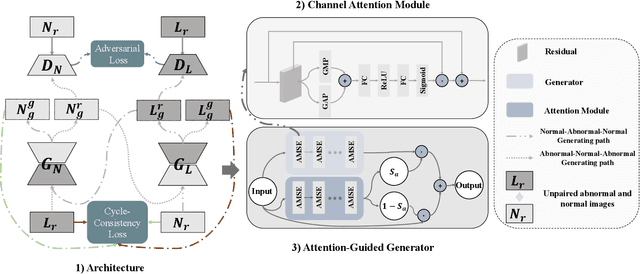
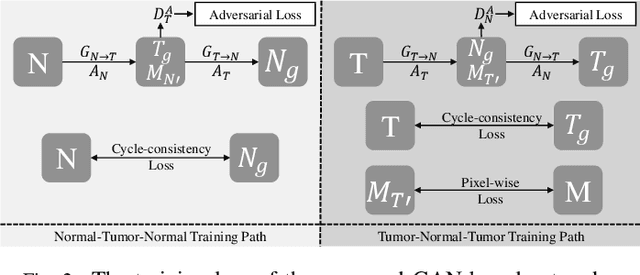
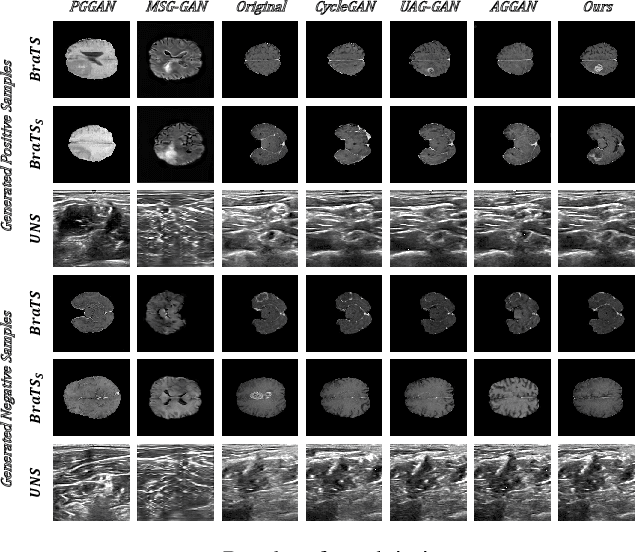
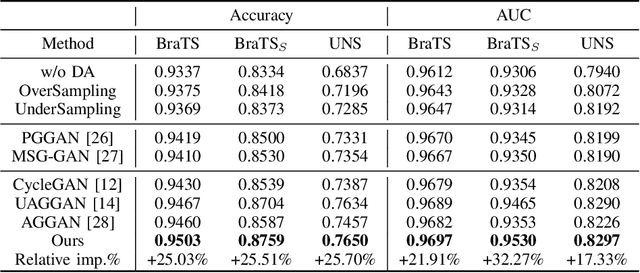
Recently deep learning methods, in particular, convolutional neural networks (CNNs), have led to a massive breakthrough in the range of computer vision. Also, the large-scale annotated dataset is the essential key to a successful training procedure. However, it is a huge challenge to get such datasets in the medical domain. Towards this, we present a data augmentation method for generating synthetic medical images using cycle-consistency Generative Adversarial Networks (GANs). We add semi-supervised attention modules to generate images with convincing details. We treat tumor images and normal images as two domains. The proposed GANs-based model can generate a tumor image from a normal image, and in turn, it can also generate a normal image from a tumor image. Furthermore, we show that generated medical images can be used for improving the performance of ResNet18 for medical image classification. Our model is applied to three limited datasets of tumor MRI images. We first generate MRI images on limited datasets, then we trained three popular classification models to get the best model for tumor classification. Finally, we train the classification model using real images with classic data augmentation methods and classification models using synthetic images. The classification results between those trained models showed that the proposed SAG-GAN data augmentation method can boost Accuracy and AUC compare with classic data augmentation methods. We believe the proposed data augmentation method can apply to other medical image domains, and improve the accuracy of computer-assisted diagnosis.
CloudifierNet -- Deep Vision Models for Artificial Image Processing
Nov 04, 2019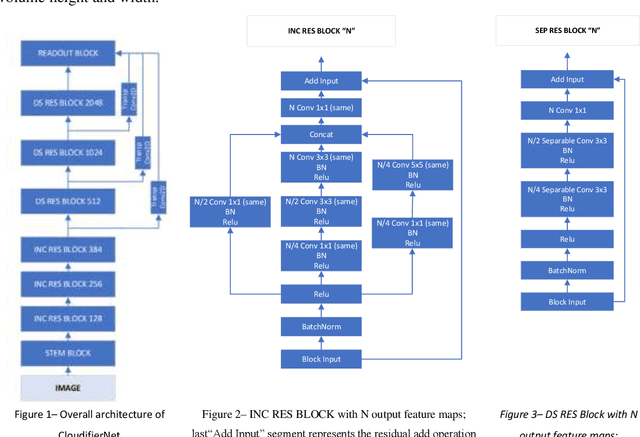
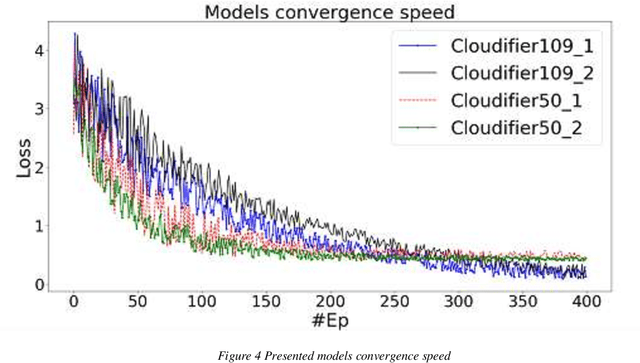
Today, more and more, it is necessary that most applications and documents developed in previous or current technologies to be accessible online on cloud-based infrastructures. That is why the migration of legacy systems including their hosts of documents to new technologies and online infrastructures, using modern Artificial Intelligence techniques, is absolutely necessary. With the advancement of Artificial Intelligence and Deep Learning with its multitude of applications, a new area of research is emerging - that of automated systems development and maintenance. The underlying work objective that led to this paper aims to research and develop truly intelligent systems able to analyze user interfaces from various sources and generate real and usable inferences ranging from architecture analysis to actual code generation. One key element of such systems is that of artificial scene detection and analysis based on deep learning computer vision systems. Computer vision models and particularly deep directed acyclic graphs based on convolutional modules are generally constructed and trained based on natural images datasets. Due to this fact, the models will develop during the training process natural image feature detectors apart from the base graph modules that will learn basic primitive features. In the current paper, we will present the base principles of a deep neural pipeline for computer vision applied to artificial scenes (scenes generated by user interfaces or similar). Finally, we will present the conclusions based on experimental development and benchmarking against state-of-the-art transfer-learning implemented deep vision models.
Bridging In- and Out-of-distribution Samples for Their Better Discriminability
Jan 07, 2021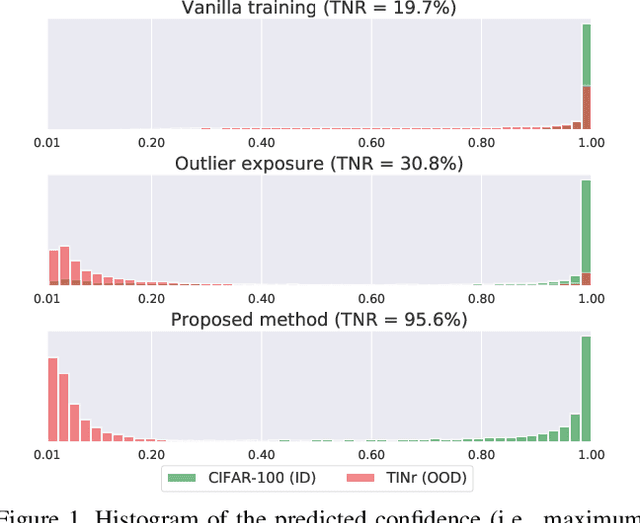
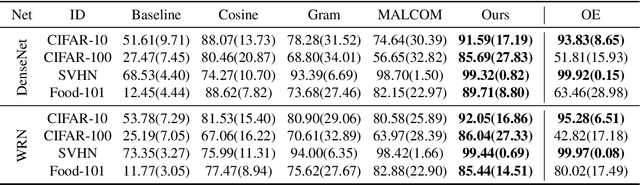

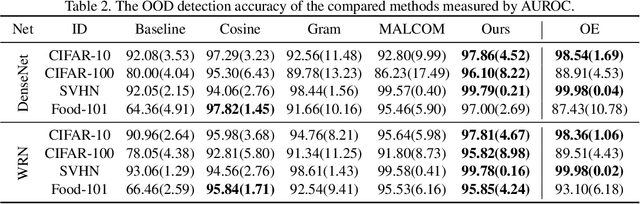
This paper proposes a method for OOD detection. Questioning the premise of previous studies that ID and OOD samples are separated distinctly, we consider samples lying in the intermediate of the two and use them for training a network. We generate such samples using multiple image transformations that corrupt inputs in various ways and with different severity levels. We estimate where the generated samples by a single image transformation lie between ID and OOD using a network trained on clean ID samples. To be specific, we make the network classify the generated samples and calculate their mean classification accuracy, using which we create a soft target label for them. We train the same network from scratch using the original ID samples and the generated samples with the soft labels created for them. We detect OOD samples by thresholding the entropy of the predicted softmax probability. The experimental results show that our method outperforms the previous state-of-the-art in the standard benchmark tests. We also analyze the effect of the number and particular combinations of image corrupting transformations on the performance.
Sensor-invariant Fingerprint ROI Segmentation Using Recurrent Adversarial Learning
Jul 03, 2021
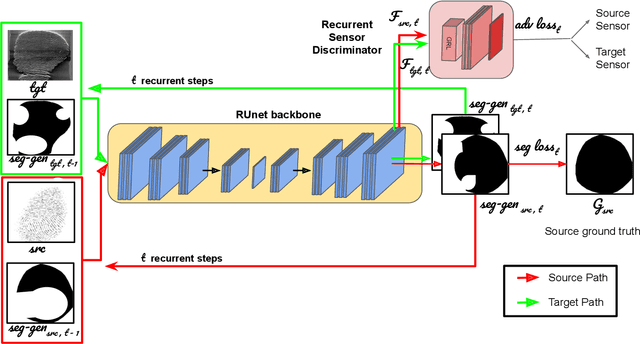

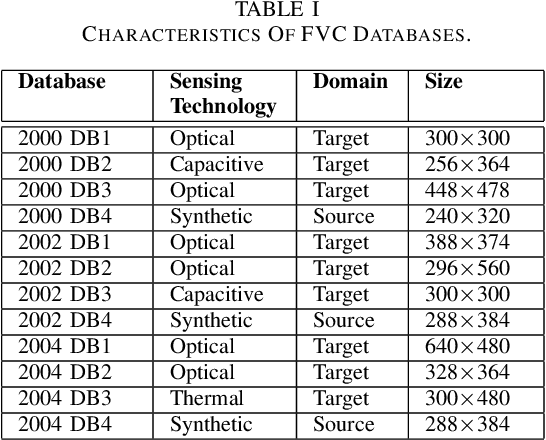
A fingerprint region of interest (roi) segmentation algorithm is designed to separate the foreground fingerprint from the background noise. All the learning based state-of-the-art fingerprint roi segmentation algorithms proposed in the literature are benchmarked on scenarios when both training and testing databases consist of fingerprint images acquired from the same sensors. However, when testing is conducted on a different sensor, the segmentation performance obtained is often unsatisfactory. As a result, every time a new fingerprint sensor is used for testing, the fingerprint roi segmentation model needs to be re-trained with the fingerprint image acquired from the new sensor and its corresponding manually marked ROI. Manually marking fingerprint ROI is expensive because firstly, it is time consuming and more importantly, requires domain expertise. In order to save the human effort in generating annotations required by state-of-the-art, we propose a fingerprint roi segmentation model which aligns the features of fingerprint images derived from the unseen sensor such that they are similar to the ones obtained from the fingerprints whose ground truth roi masks are available for training. Specifically, we propose a recurrent adversarial learning based feature alignment network that helps the fingerprint roi segmentation model to learn sensor-invariant features. Consequently, sensor-invariant features learnt by the proposed roi segmentation model help it to achieve improved segmentation performance on fingerprints acquired from the new sensor. Experiments on publicly available FVC databases demonstrate the efficacy of the proposed work.
* IJCNN 2021 (Accepted)
Emerging Properties in Self-Supervised Vision Transformers
May 24, 2021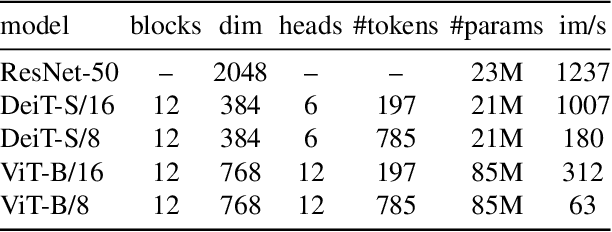
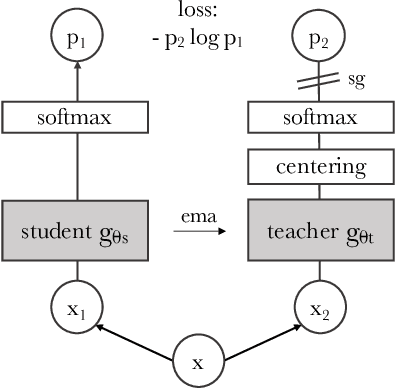
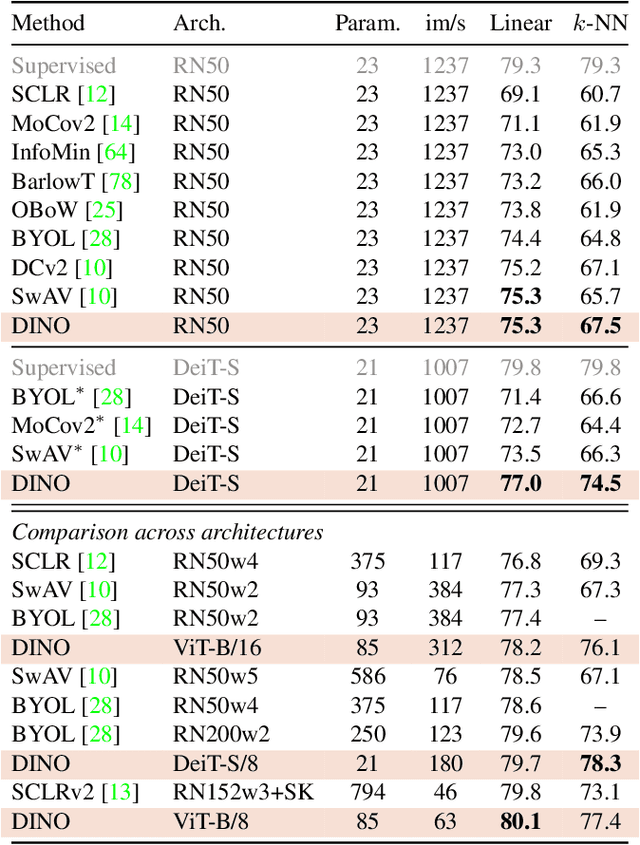
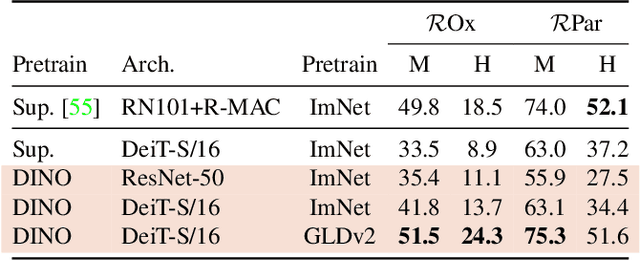
In this paper, we question if self-supervised learning provides new properties to Vision Transformer (ViT) that stand out compared to convolutional networks (convnets). Beyond the fact that adapting self-supervised methods to this architecture works particularly well, we make the following observations: first, self-supervised ViT features contain explicit information about the semantic segmentation of an image, which does not emerge as clearly with supervised ViTs, nor with convnets. Second, these features are also excellent k-NN classifiers, reaching 78.3% top-1 on ImageNet with a small ViT. Our study also underlines the importance of momentum encoder, multi-crop training, and the use of small patches with ViTs. We implement our findings into a simple self-supervised method, called DINO, which we interpret as a form of self-distillation with no labels. We show the synergy between DINO and ViTs by achieving 80.1% top-1 on ImageNet in linear evaluation with ViT-Base.
StainNet: a fast and robust stain normalization network
Jan 16, 2021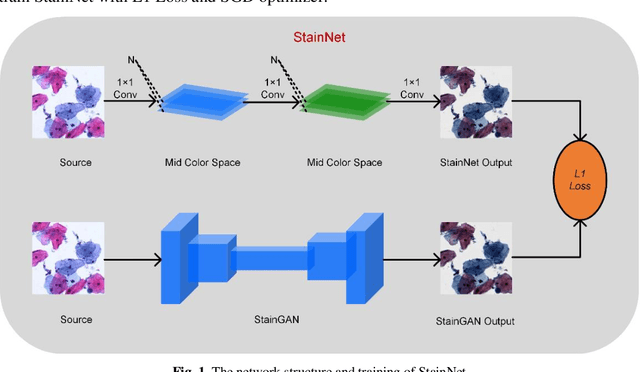
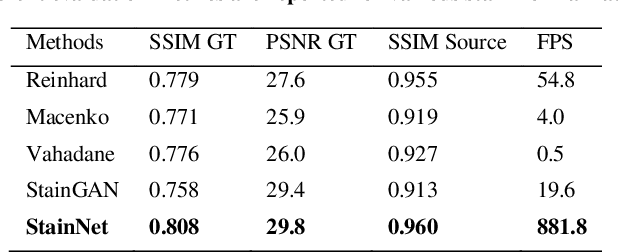
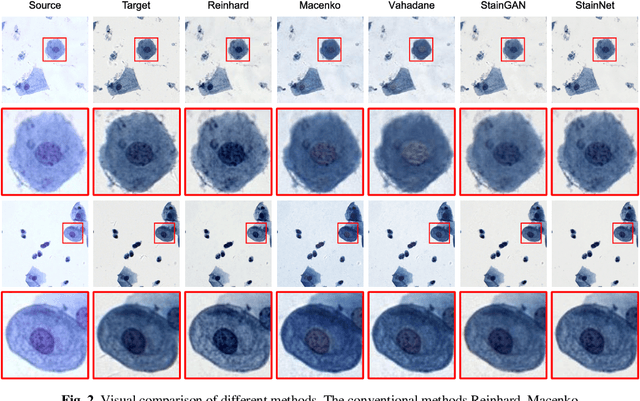
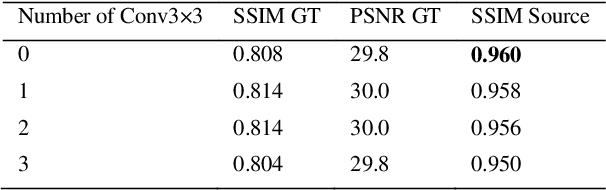
Due to a variety of factors, pathological images have large color variabilities, which hamper the performance of computer-aided diagnosis (CAD) systems. Stain normalization has been used to reduce the color variability and increase the accuracy of CAD systems. Among them, the conventional methods perform stain normalization on a pixel-by-pixel basis, but estimate stain parameters just relying on one single reference image and thus would incur some inaccurate normalization results. As for the current deep learning-based methods, it can automatically extract the color distribution and need not pick a representative reference image. While the deep learning-based methods have a complex structure with millions of parameters, and a relatively low computational efficiency and a risk to introduce artifacts. In this paper, a fast and robust stain normalization network with only 1.28K parameters named StainNet is proposed. StainNet can learn the color mapping relationship from a whole dataset and adjust the color value in a pixel-to-pixel manner. The proposed method performs well in stain normalization and achieves a better accuracy and image quality. Application results show the cervical cytology classification achieved a higher accuracy when after stain normalization of StainNet.