 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SimPoE: Simulated Character Control for 3D Human Pose Estimation
Apr 01, 2021
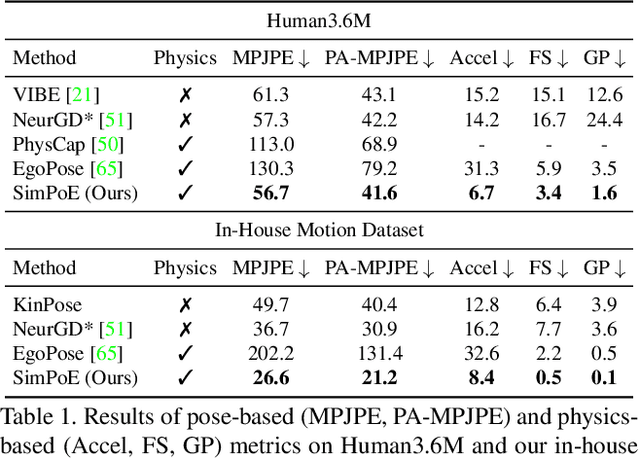
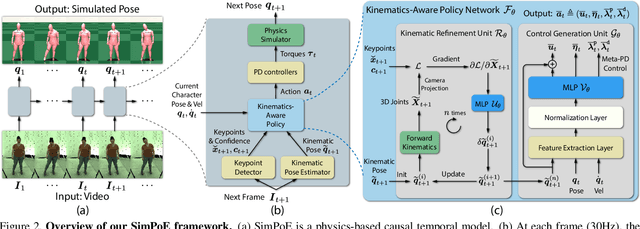
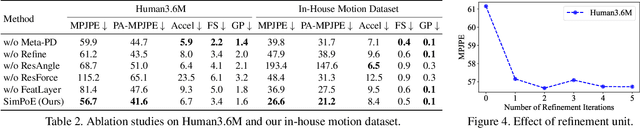
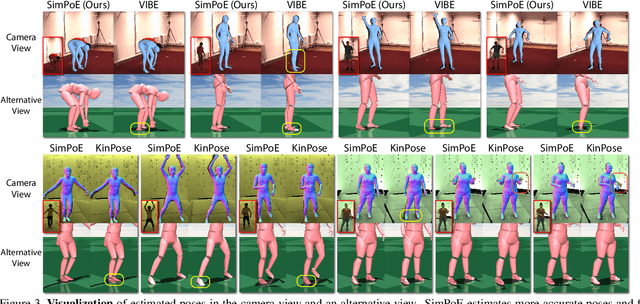
Accurate estimation of 3D human motion from monocular video requires modeling both kinematics (body motion without physical forces) and dynamics (motion with physical forces). To demonstrate this, we present SimPoE, a Simulation-based approach for 3D human Pose Estimation, which integrates image-based kinematic inference and physics-based dynamics modeling. SimPoE learns a policy that takes as input the current-frame pose estimate and the next image frame to control a physically-simulated character to output the next-frame pose estimate. The policy contains a learnable kinematic pose refinement unit that uses 2D keypoints to iteratively refine its kinematic pose estimate of the next frame. Based on this refined kinematic pose, the policy learns to compute dynamics-based control (e.g., joint torques) of the character to advance the current-frame pose estimate to the pose estimate of the next frame. This design couples the kinematic pose refinement unit with the dynamics-based control generation unit, which are learned jointly with reinforcement learning to achieve accurate and physically-plausible pose estimation. Furthermore, we propose a meta-control mechanism that dynamically adjusts the character's dynamics parameters based on the character state to attain more accurate pose estimates. Experiments on large-scale motion datasets demonstrate that our approach establishes the new state of the art in pose accuracy while ensuring physical plausibility.
Non-Adversarial Image Synthesis with Generative Latent Nearest Neighbors
Dec 21, 2018

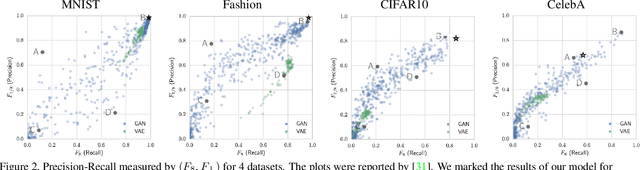

Unconditional image generation has recently been dominated by generative adversarial networks (GANs). GAN methods train a generator which regresses images from random noise vectors, as well as a discriminator that attempts to differentiate between the generated images and a training set of real images. GANs have shown amazing results at generating realistic looking images. Despite their success, GANs suffer from critical drawbacks including: unstable training and mode-dropping. The weaknesses in GANs have motivated research into alternatives including: variational auto-encoders (VAEs), latent embedding learning methods (e.g. GLO) and nearest-neighbor based implicit maximum likelihood estimation (IMLE). Unfortunately at the moment, GANs still significantly outperform the alternative methods for image generation. In this work, we present a novel method - Generative Latent Nearest Neighbors (GLANN) - for training generative models without adversarial training. GLANN combines the strengths of IMLE and GLO in a way that overcomes the main drawbacks of each method. Consequently, GLANN generates images that are far better than GLO and IMLE. Our method does not suffer from mode collapse which plagues GAN training and is much more stable. Qualitative results show that GLANN outperforms a baseline consisting of 800 GANs and VAEs on commonly used datasets. Our models are also shown to be effective for training truly non-adversarial unsupervised image translation.
Analysis of Information Flow Through U-Nets
Jan 21, 2021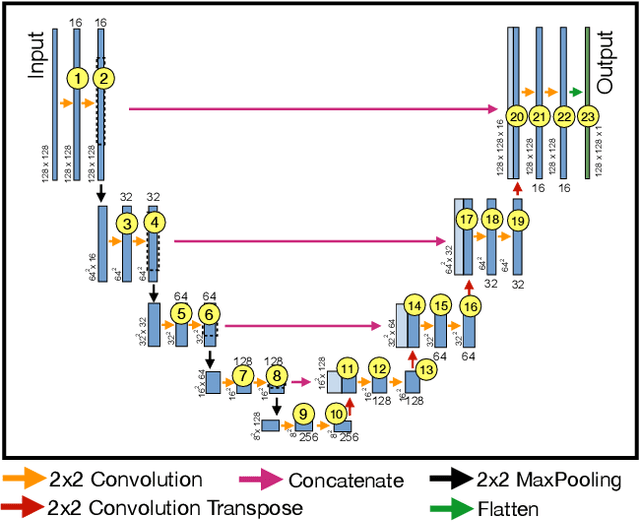

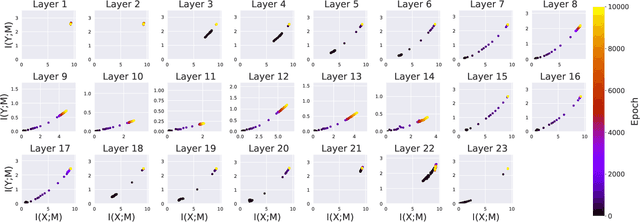
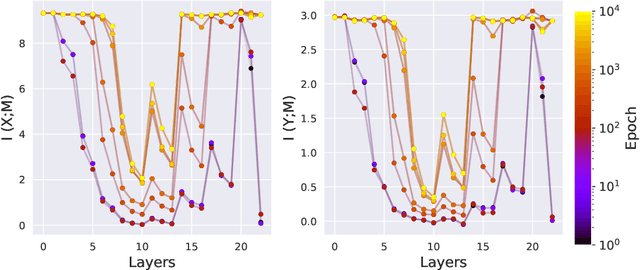
Deep Neural Networks (DNNs) have become ubiquitous in medical image processing and analysis. Among them, U-Nets are very popular in various image segmentation tasks. Yet, little is known about how information flows through these networks and whether they are indeed properly designed for the tasks they are being proposed for. In this paper, we employ information-theoretic tools in order to gain insight into information flow through U-Nets. In particular, we show how mutual information between input/output and an intermediate layer can be a useful tool to understand information flow through various portions of a U-Net, assess its architectural efficiency, and even propose more efficient designs.
Provident Vehicle Detection at Night for Advanced Driver Assistance Systems
Jul 23, 2021

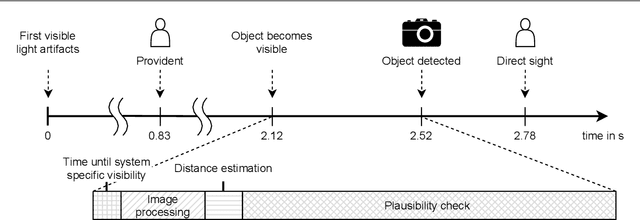

In recent years, computer vision algorithms have become more and more powerful, which enabled technologies such as autonomous driving to evolve with rapid pace. However, current algorithms mainly share one limitation: They rely on directly visible objects. This is a major drawback compared to human behavior, where indirect visual cues caused by the actual object (e.g., shadows) are already used intuitively to retrieve information or anticipate occurring objects. While driving at night, this performance deficit becomes even more obvious: Humans already process the light artifacts caused by oncoming vehicles to assume their future appearance, whereas current object detection systems rely on the oncoming vehicle's direct visibility. Based on previous work in this subject, we present with this paper a complete system capable of solving the task to providently detect oncoming vehicles at nighttime based on their caused light artifacts. For that, we outline the full algorithm architecture ranging from the detection of light artifacts in the image space, localizing the objects in the three-dimensional space, and verifying the objects over time. To demonstrate the applicability, we deploy the system in a test vehicle and use the information of providently detected vehicles to control the glare-free high beam system proactively. Using this experimental setting, we quantify the time benefit that the provident vehicle detection system provides compared to an in-production computer vision system. Additionally, the glare-free high beam use case provides a real-time and real-world visualization interface of the detection results. With this contribution, we want to put awareness on the unconventional sensing task of provident object detection and further close the performance gap between human behavior and computer vision algorithms in order to bring autonomous and automated driving a step forward.
Areas of Attention for Image Captioning
Aug 25, 2017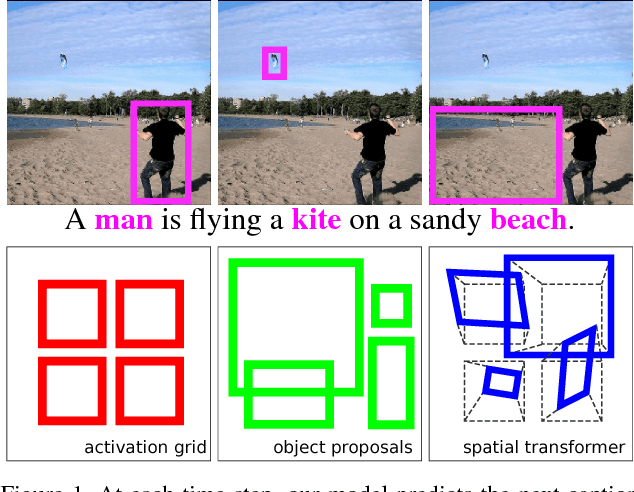
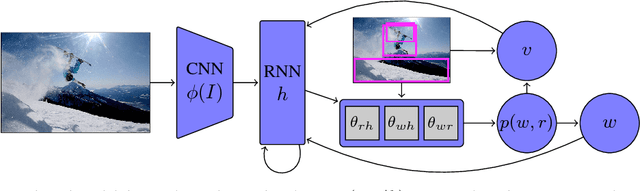
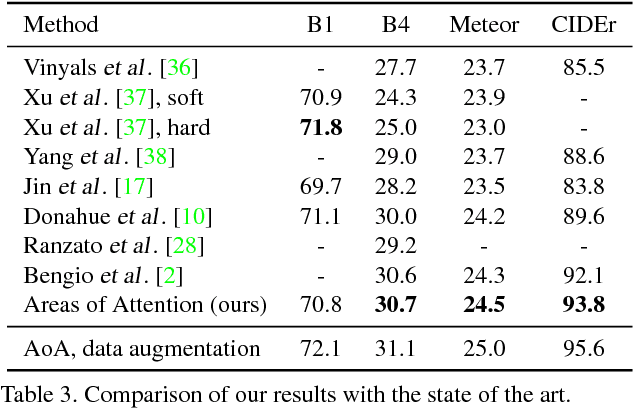

We propose "Areas of Attention", a novel attention-based model for automatic image captioning. Our approach models the dependencies between image regions, caption words, and the state of an RNN language model, using three pairwise interactions. In contrast to previous attention-based approaches that associate image regions only to the RNN state, our method allows a direct association between caption words and image regions. During training these associations are inferred from image-level captions, akin to weakly-supervised object detector training. These associations help to improve captioning by localizing the corresponding regions during testing. We also propose and compare different ways of generating attention areas: CNN activation grids, object proposals, and spatial transformers nets applied in a convolutional fashion. Spatial transformers give the best results. They allow for image specific attention areas, and can be trained jointly with the rest of the network. Our attention mechanism and spatial transformer attention areas together yield state-of-the-art results on the MSCOCO dataset.o meaningful latent semantic structure in the generated captions.
Full-Glow: Fully conditional Glow for more realistic image generation
Dec 10, 2020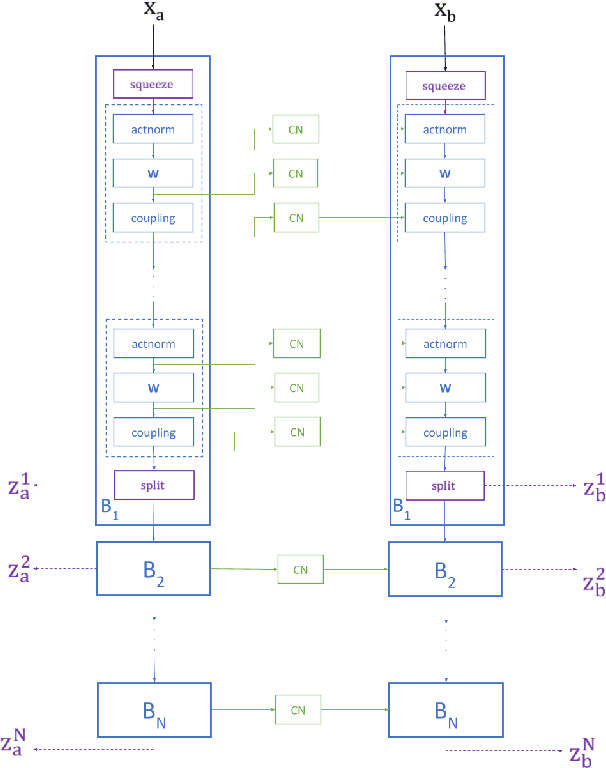
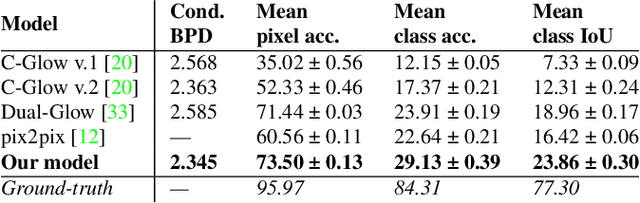


Autonomous agents, such as driverless cars, require large amounts of labeled visual data for their training. A viable approach for acquiring such data is training a generative model with collected real data, and then augmenting the collected real dataset with synthetic images from the model, generated with control of the scene layout and ground truth labeling. In this paper we propose Full-Glow, a fully conditional Glow-based architecture for generating plausible and realistic images of novel street scenes given a semantic segmentation map indicating the scene layout. Benchmark comparisons show our model to outperform recent works in terms of the semantic segmentation performance of a pretrained PSPNet. This indicates that images from our model are, to a higher degree than from other models, similar to real images of the same kinds of scenes and objects, making them suitable as training data for a visual semantic segmentation or object recognition system.
AGORA: Avatars in Geography Optimized for Regression Analysis
Apr 29, 2021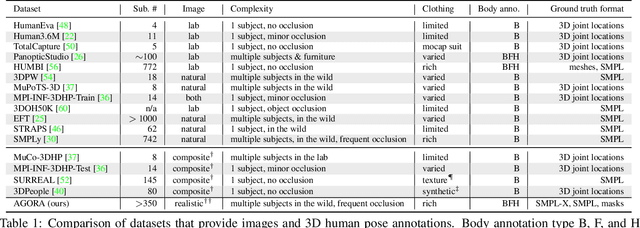
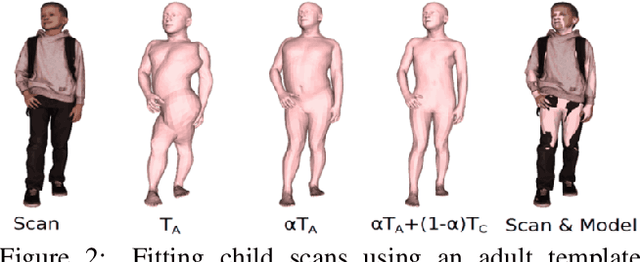
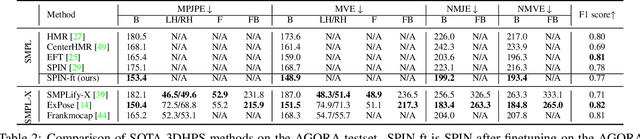
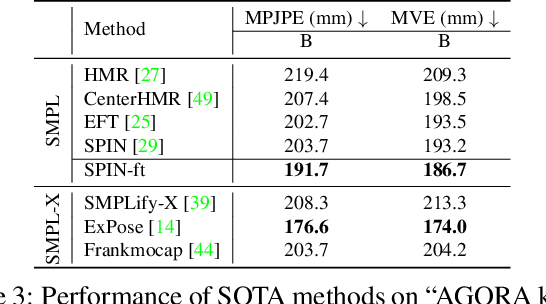
While the accuracy of 3D human pose estimation from images has steadily improved on benchmark datasets, the best methods still fail in many real-world scenarios. This suggests that there is a domain gap between current datasets and common scenes containing people. To obtain ground-truth 3D pose, current datasets limit the complexity of clothing, environmental conditions, number of subjects, and occlusion. Moreover, current datasets evaluate sparse 3D joint locations corresponding to the major joints of the body, ignoring the hand pose and the face shape. To evaluate the current state-of-the-art methods on more challenging images, and to drive the field to address new problems, we introduce AGORA, a synthetic dataset with high realism and highly accurate ground truth. Here we use 4240 commercially-available, high-quality, textured human scans in diverse poses and natural clothing; this includes 257 scans of children. We create reference 3D poses and body shapes by fitting the SMPL-X body model (with face and hands) to the 3D scans, taking into account clothing. We create around 14K training and 3K test images by rendering between 5 and 15 people per image using either image-based lighting or rendered 3D environments, taking care to make the images physically plausible and photoreal. In total, AGORA consists of 173K individual person crops. We evaluate existing state-of-the-art methods for 3D human pose estimation on this dataset and find that most methods perform poorly on images of children. Hence, we extend the SMPL-X model to better capture the shape of children. Additionally, we fine-tune methods on AGORA and show improved performance on both AGORA and 3DPW, confirming the realism of the dataset. We provide all the registered 3D reference training data, rendered images, and a web-based evaluation site at https://agora.is.tue.mpg.de/.
Fused Deep Features Based Classification Framework for COVID-19 Classification with Optimized MLP
Mar 15, 2021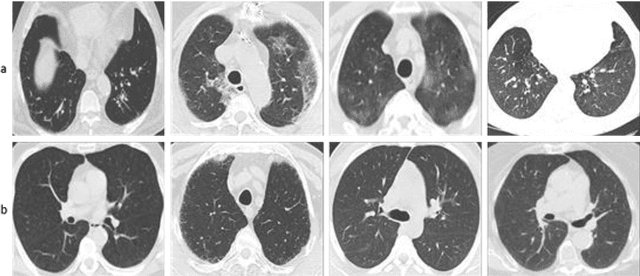
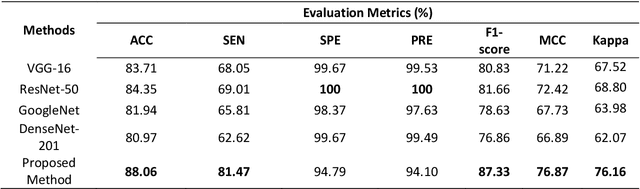
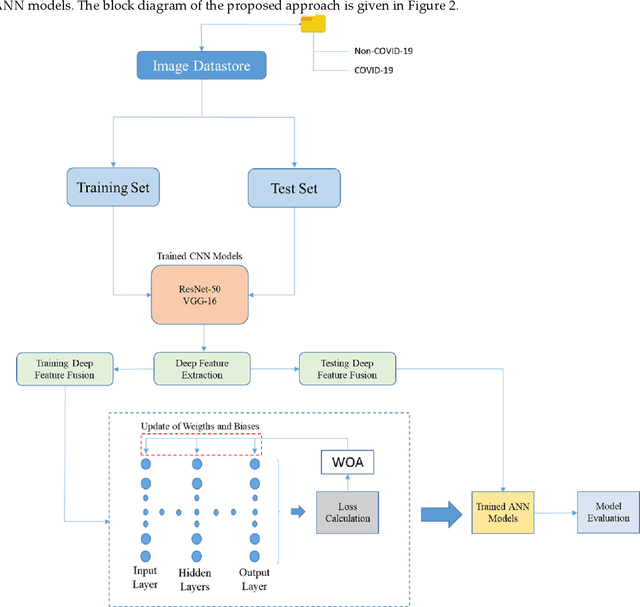
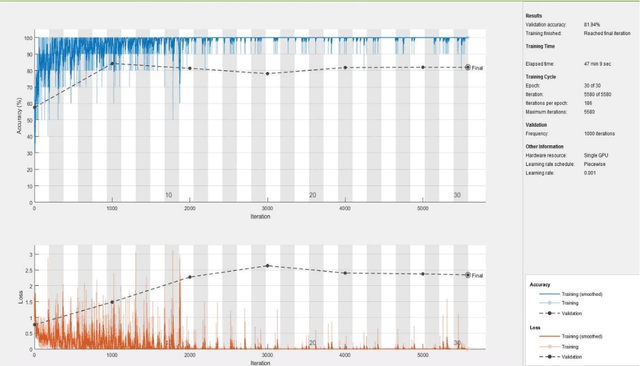
The new type of Coronavirus disease called COVID-19 continues to spread quite rapidly. Although it shows some specific symptoms, this disease, which can show different symptoms in almost every individual, has caused hundreds of thousands of patients to die. Although healthcare professionals work hard to prevent further loss of life, the rate of disease spread is very high. For this reason, the help of computer aided diagnosis (CAD) and artificial intelligence (AI) algorithms is vital. In this study, a method based on optimization of convolutional neural network (CNN) architecture, which is the most effective image analysis method of today, is proposed to fulfill the mentioned COVID-19 detection needs. First, COVID-19 images are trained using ResNet-50 and VGG-16 architectures. Then, features in the last layer of these two architectures are combined with feature fusion. These new image features matrices obtained with feature fusion are classified for COVID detection. A multi-layer perceptron (MLP) structure optimized by the whale optimization algorithm is used for the classification process. The obtained results show that the performance of the proposed framework is almost 4.5% higher than VGG-16 performance and almost 3.5% higher than ResNet-50 performance.
Gaze Perception in Humans and CNN-Based Model
Apr 17, 2021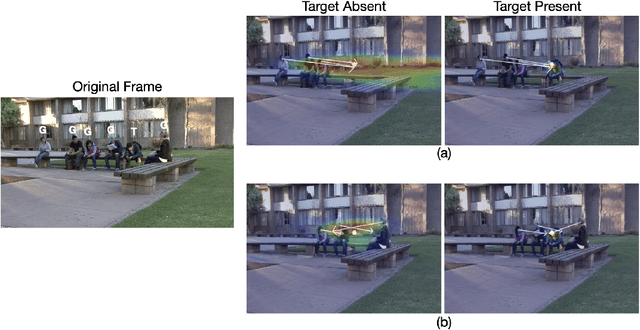
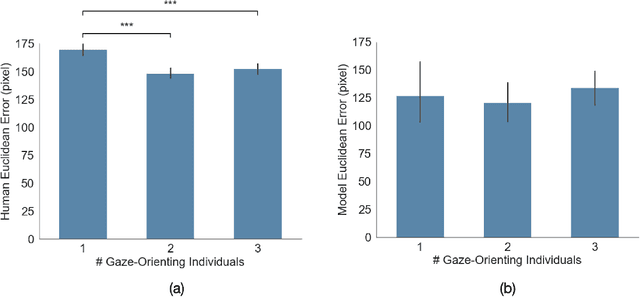
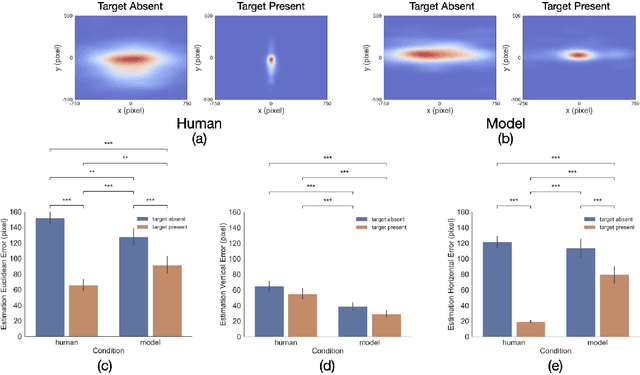
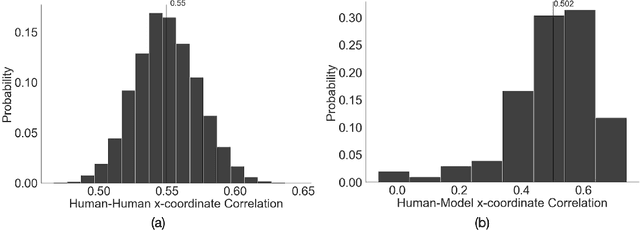
Making accurate inferences about other individuals' locus of attention is essential for human social interactions and will be important for AI to effectively interact with humans. In this study, we compare how a CNN (convolutional neural network) based model of gaze and humans infer the locus of attention in images of real-world scenes with a number of individuals looking at a common location. We show that compared to the model, humans' estimates of the locus of attention are more influenced by the context of the scene, such as the presence of the attended target and the number of individuals in the image.
Segmentation with Multiple Acceptable Annotations: A Case Study of Myocardial Segmentation in Contrast Echocardiography
Jun 29, 2021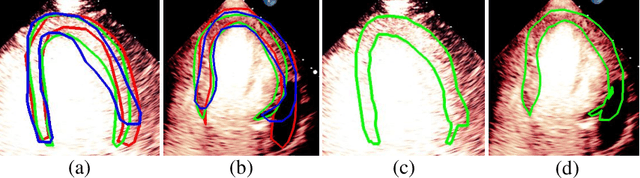
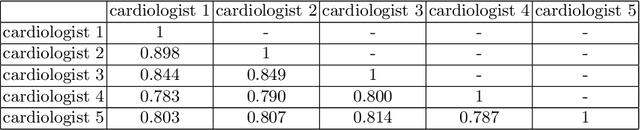
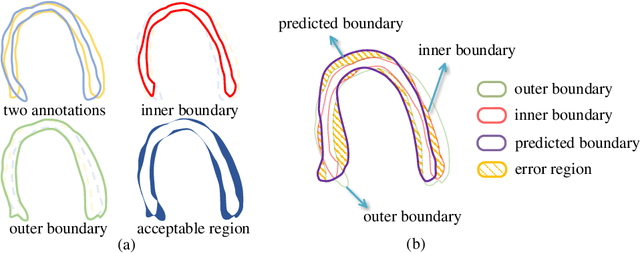
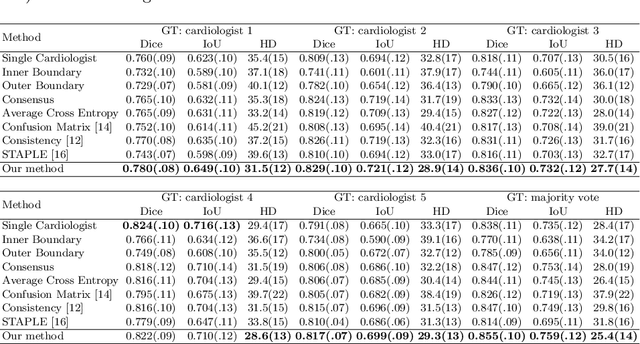
Most existing deep learning-based frameworks for image segmentation assume that a unique ground truth is known and can be used for performance evaluation. This is true for many applications, but not all. Myocardial segmentation of Myocardial Contrast Echocardiography (MCE), a critical task in automatic myocardial perfusion analysis, is an example. Due to the low resolution and serious artifacts in MCE data, annotations from different cardiologists can vary significantly, and it is hard to tell which one is the best. In this case, how can we find a good way to evaluate segmentation performance and how do we train the neural network? In this paper, we address the first problem by proposing a new extended Dice to effectively evaluate the segmentation performance when multiple accepted ground truth is available. Then based on our proposed metric, we solve the second problem by further incorporating the new metric into a loss function that enables neural networks to flexibly learn general features of myocardium. Experiment results on our clinical MCE data set demonstrate that the neural network trained with the proposed loss function outperforms those existing ones that try to obtain a unique ground truth from multiple annotations, both quantitatively and qualitatively. Finally, our grading study shows that using extended Dice as an evaluation metric can better identify segmentation results that need manual correction compared with using Dice.