 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing the Gap in Human and VLM Scene Perception through Counterfactual Semantic Saliency
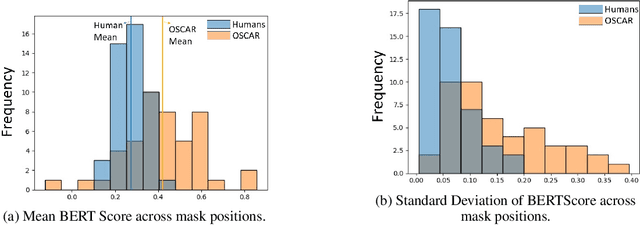
May 13, 2026Evaluating whether large vision-language models (VLMs) align with human perception for high-level semantic scene comprehension remains a challenge. Traditional white-box interpretability methods are inapplicable to closed-source architectures and passive metrics fail to isolate causal features. We introduce Counterfactual Semantic Saliency (CSS). This black-box, model-agnostic framework quantifies the importance of objects by measuring the semantic shift induced by their causal ablation from a scene. To evaluate AI-human semantic alignment, we tested prominent VLMs against a human psychophysics baseline comprising 16,289 valid responses across 307 complex natural scenes and 1,306 high-fidelity counterfactual variants. Our analysis reveals a pervasive scene comprehension gap: models exhibit an overreliance (relative to humans) on large objects (size bias), objects at the center of the image (center bias), and high saliency objects. In contrast, models rely less on people in the scenes than our human participants to describe the images. A model's size bias is a primary driver explaining variations in model-human semantic divergence. Code and data will be available at https://github.com/starsky77/Counterfactual-Semantic-Saliency.
IRIS: Intent Resolution via Inference-time Saccades for Open-Ended VQA in Large Vision-Language Models
Feb 18, 2026We introduce IRIS (Intent Resolution via Inference-time Saccades), a novel training-free approach that uses eye-tracking data in real-time to resolve ambiguity in open-ended VQA. Through a comprehensive user study with 500 unique image-question pairs, we demonstrate that fixations closest to the time participants start verbally asking their questions are the most informative for disambiguation in Large VLMs, more than doubling the accuracy of responses on ambiguous questions (from 35.2% to 77.2%) while maintaining performance on unambiguous queries. We evaluate our approach across state-of-the-art VLMs, showing consistent improvements when gaze data is incorporated in ambiguous image-question pairs, regardless of architectural differences. We release a new benchmark dataset to use eye movement data for disambiguated VQA, a novel real-time interactive protocol, and an evaluation suite.
Predicting Reaction Time to Comprehend Scenes with Foveated Scene Understanding Maps
May 19, 2025



Although models exist that predict human response times (RTs) in tasks such as target search and visual discrimination, the development of image-computable predictors for scene understanding time remains an open challenge. Recent advances in vision-language models (VLMs), which can generate scene descriptions for arbitrary images, combined with the availability of quantitative metrics for comparing linguistic descriptions, offer a new opportunity to model human scene understanding. We hypothesize that the primary bottleneck in human scene understanding and the driving source of variability in response times across scenes is the interaction between the foveated nature of the human visual system and the spatial distribution of task-relevant visual information within an image. Based on this assumption, we propose a novel image-computable model that integrates foveated vision with VLMs to produce a spatially resolved map of scene understanding as a function of fixation location (Foveated Scene Understanding Map, or F-SUM), along with an aggregate F-SUM score. This metric correlates with average (N=17) human RTs (r=0.47) and number of saccades (r=0.51) required to comprehend a scene (across 277 scenes). The F-SUM score also correlates with average (N=16) human description accuracy (r=-0.56) in time-limited presentations. These correlations significantly exceed those of standard image-based metrics such as clutter, visual complexity, and scene ambiguity based on language entropy. Together, our work introduces a new image-computable metric for predicting human response times in scene understanding and demonstrates the importance of foveated visual processing in shaping comprehension difficulty.
Convolutional Neural Network Model Observers Discount Signal-like Anatomical Structures During Search in Virtual Digital Breast Tomosynthesis Phantoms
May 23, 2024Model observers are computational tools to evaluate and optimize task-based medical image quality. Linear model observers, such as the Channelized Hotelling Observer (CHO), predict human accuracy in detection tasks with a few possible signal locations in clinical phantoms or real anatomic backgrounds. In recent years, Convolutional Neural Networks (CNNs) have been proposed as a new type of model observer. What is not well understood is what CNNs add over the more common linear model observer approaches. We compare the CHO and CNN detection accuracy to the radiologist's accuracy in searching for two types of signals (mass and microcalcification) embedded in 2D/3D breast tomosynthesis phantoms (DBT). We show that the CHO model's accuracy is comparable to the CNN's performance for a location-known-exactly detection task. However, for the search task with 2D/3D DBT phantoms, the CHO's detection accuracy was significantly lower than the CNN accuracy. A comparison to the radiologist's accuracy showed that the CNN but not the CHO could match or exceed the radiologist's accuracy in the 2D microcalcification and 3D mass search conditions. An analysis of the eye position showed that radiologists fixated more often and longer at the locations corresponding to CNN false positives. Most CHO false positives were the phantom's normal anatomy and were not fixated by radiologists. In conclusion, we show that CNNs can be used as an anthropomorphic model observer for the search task for which traditional linear model observers fail due to their inability to discount false positives arising from the anatomical backgrounds.
A deep Q-learning method for optimizing visual search strategies in backgrounds of dynamic noise
Jan 28, 2022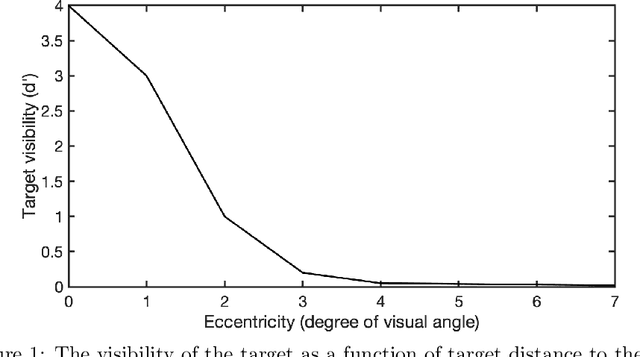
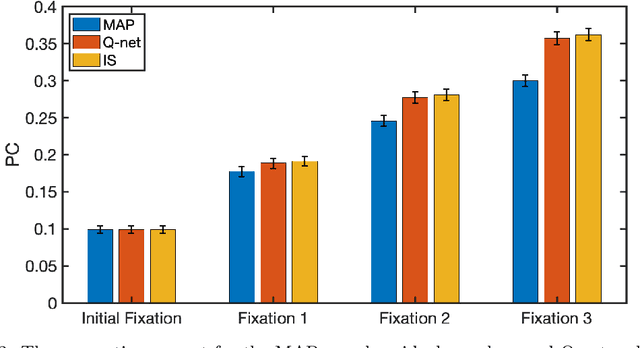
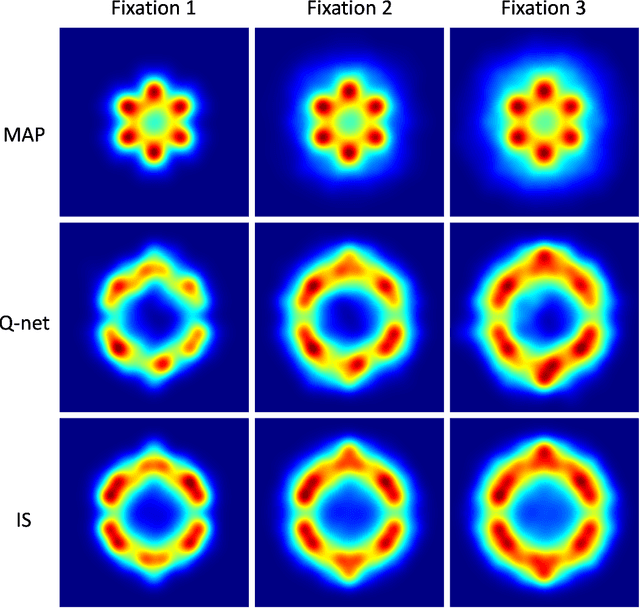
Humans process visual information with varying resolution (foveated visual system) and explore images by orienting through eye movements the high-resolution fovea to points of interest. The Bayesian ideal searcher (IS) that employs complete knowledge of task-relevant information optimizes eye movement strategy and achieves the optimal search performance. The IS can be employed as an important tool to evaluate the optimality of human eye movements, and potentially provide guidance to improve human observer visual search strategies. Najemnik and Geisler (2005) derived an IS for backgrounds of spatial 1/f noise. The corresponding template responses follow Gaussian distributions and the optimal search strategy can be analytically determined. However, the computation of the IS can be intractable when considering more realistic and complex backgrounds such as medical images. Modern reinforcement learning methods, successfully applied to obtain optimal policy for a variety of tasks, do not require complete knowledge of the background generating functions and can be potentially applied to anatomical backgrounds. An important first step is to validate the optimality of the reinforcement learning method. In this study, we investigate the ability of a reinforcement learning method that employs Q-network to approximate the IS. We demonstrate that the search strategy corresponding to the Q-network is consistent with the IS search strategy. The findings show the potential of the reinforcement learning with Q-network approach to estimate optimal eye movement planning with real anatomical backgrounds.
FoveaTer: Foveated Transformer for Image Classification
May 29, 2021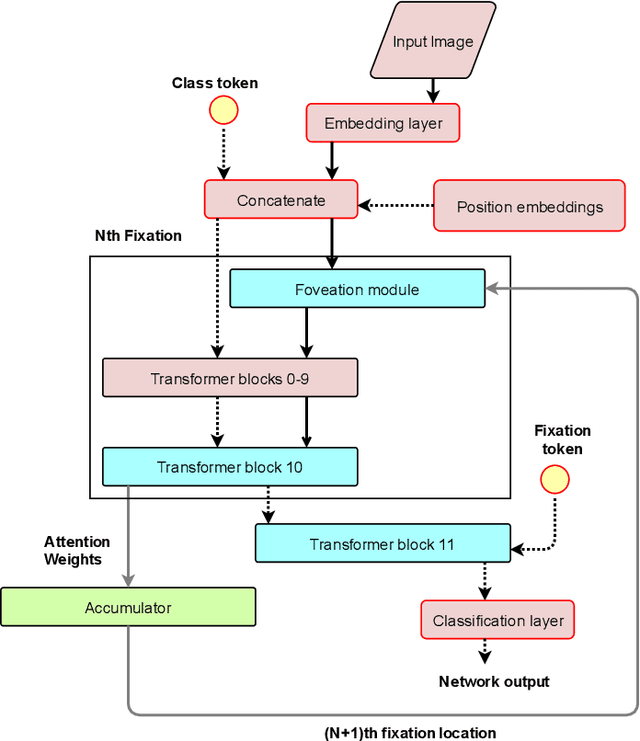
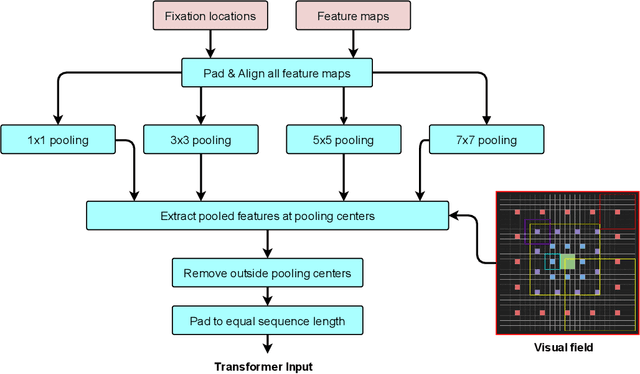
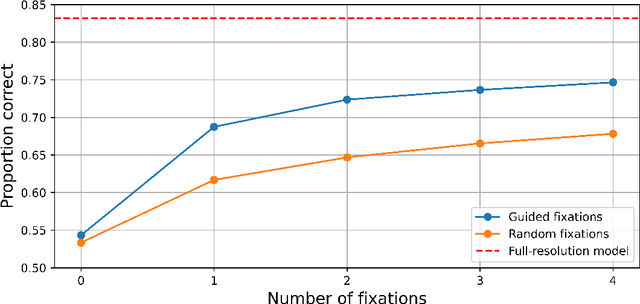
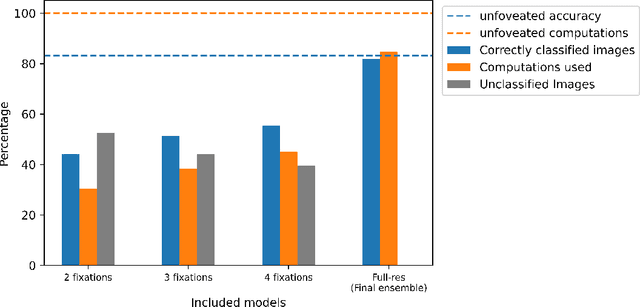
Many animals and humans process the visual field with a varying spatial resolution (foveated vision) and use peripheral processing to make eye movements and point the fovea to acquire high-resolution information about objects of interest. This architecture results in computationally efficient rapid scene exploration. Recent progress in vision Transformers has brought about new alternatives to the traditionally convolution-reliant computer vision systems. However, these models do not explicitly model the foveated properties of the visual system nor the interaction between eye movements and the classification task. We propose foveated Transformer (FoveaTer) model, which uses pooling regions and saccadic movements to perform object classification tasks using a vision Transformer architecture. Our proposed model pools the image features using squared pooling regions, an approximation to the biologically-inspired foveated architecture, and uses the pooled features as an input to a Transformer Network. It decides on the following fixation location based on the attention assigned by the Transformer to various locations from previous and present fixations. The model uses a confidence threshold to stop scene exploration, allowing to dynamically allocate more fixation/computational resources to more challenging images. We construct an ensemble model using our proposed model and unfoveated model, achieving an accuracy 1.36% below the unfoveated model with 22% computational savings. Finally, we demonstrate our model's robustness against adversarial attacks, where it outperforms the unfoveated model.
Comparing Visual Reasoning in Humans and AI
Apr 29, 2021
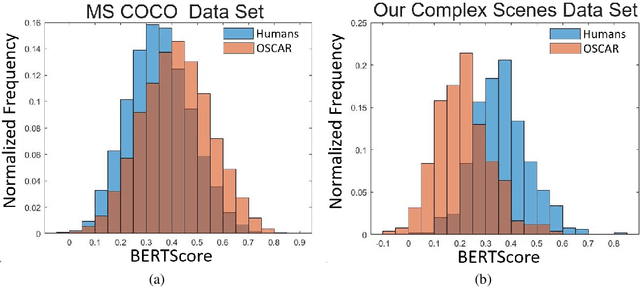

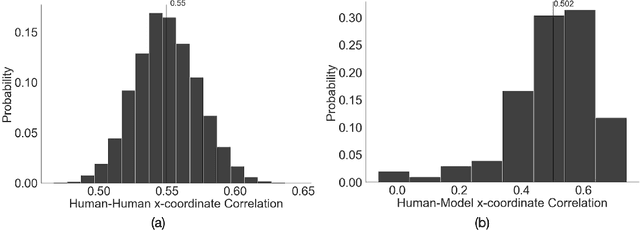
Recent advances in natural language processing and computer vision have led to AI models that interpret simple scenes at human levels. Yet, we do not have a complete understanding of how humans and AI models differ in their interpretation of more complex scenes. We created a dataset of complex scenes that contained human behaviors and social interactions. AI and humans had to describe the scenes with a sentence. We used a quantitative metric of similarity between scene descriptions of the AI/human and ground truth of five other human descriptions of each scene. Results show that the machine/human agreement scene descriptions are much lower than human/human agreement for our complex scenes. Using an experimental manipulation that occludes different spatial regions of the scenes, we assessed how machines and humans vary in utilizing regions of images to understand the scenes. Together, our results are a first step toward understanding how machines fall short of human visual reasoning with complex scenes depicting human behaviors.
Gaze Perception in Humans and CNN-Based Model
Apr 17, 2021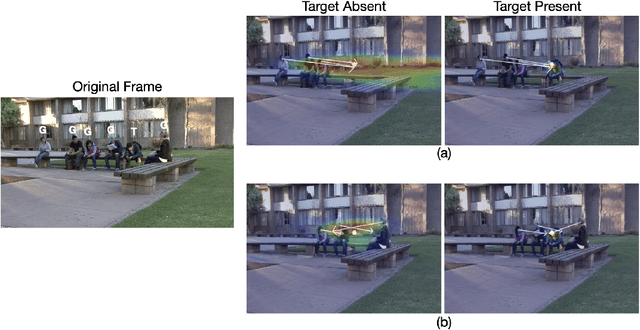
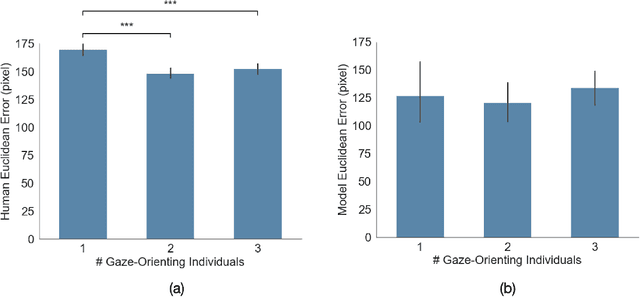
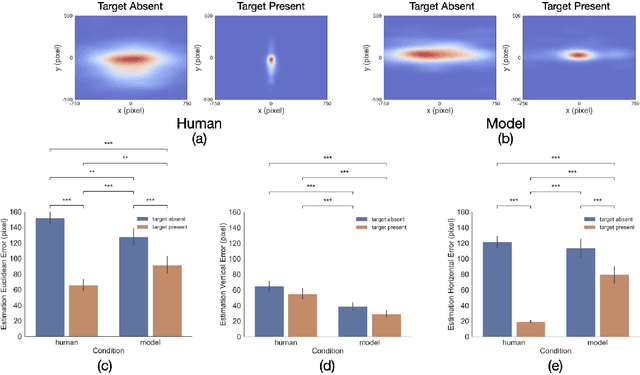
Making accurate inferences about other individuals' locus of attention is essential for human social interactions and will be important for AI to effectively interact with humans. In this study, we compare how a CNN (convolutional neural network) based model of gaze and humans infer the locus of attention in images of real-world scenes with a number of individuals looking at a common location. We show that compared to the model, humans' estimates of the locus of attention are more influenced by the context of the scene, such as the presence of the attended target and the number of individuals in the image.
Language-based Video Editing via Multi-Modal Multi-Level Transformer
Apr 02, 2021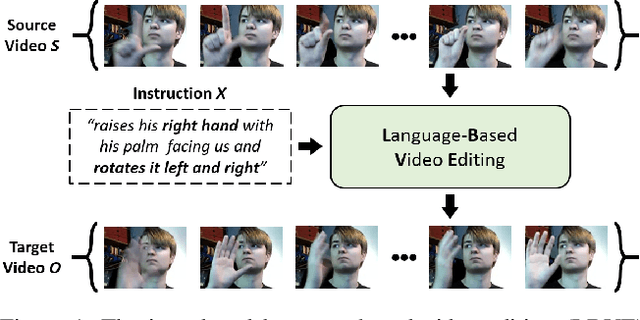
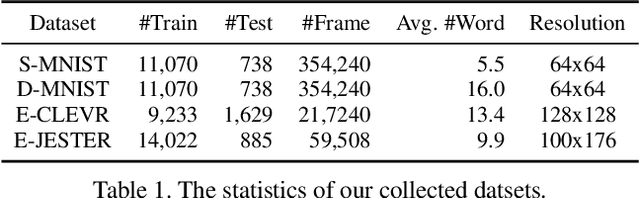
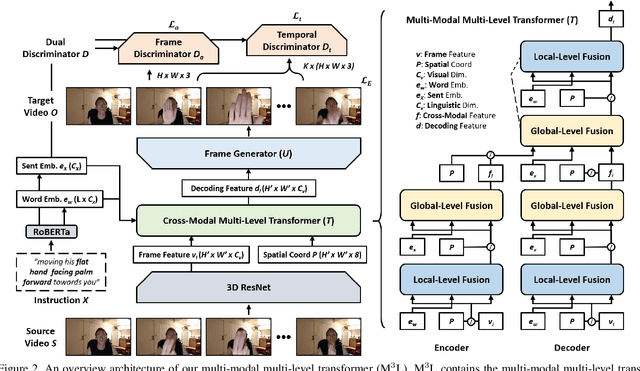

Video editing tools are widely used nowadays for digital design. Although the demand for these tools is high, the prior knowledge required makes it difficult for novices to get started. Systems that could follow natural language instructions to perform automatic editing would significantly improve accessibility. This paper introduces the language-based video editing (LBVE) task, which allows the model to edit, guided by text instruction, a source video into a target video. LBVE contains two features: 1) the scenario of the source video is preserved instead of generating a completely different video; 2) the semantic is presented differently in the target video, and all changes are controlled by the given instruction. We propose a Multi-Modal Multi-Level Transformer (M$^3$L-Transformer) to carry out LBVE. The M$^3$L-Transformer dynamically learns the correspondence between video perception and language semantic at different levels, which benefits both the video understanding and video frame synthesis. We build three new datasets for evaluation, including two diagnostic and one from natural videos with human-labeled text. Extensive experimental results show that M$^3$L-Transformer is effective for video editing and that LBVE can lead to a new field toward vision-and-language research.
Medical Image Quality Metrics for Foveated Model Observers
Feb 09, 2021
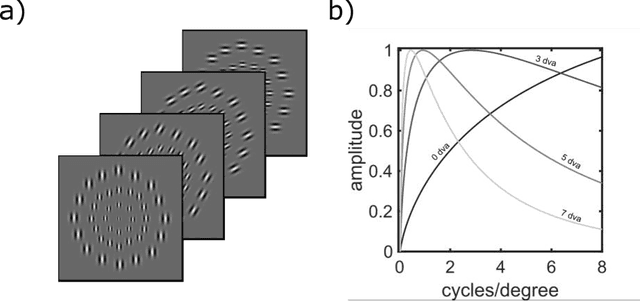

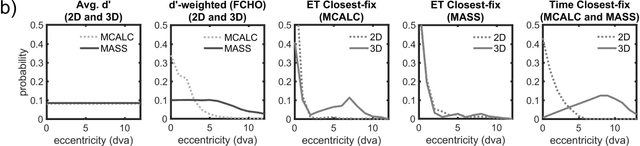
A recently proposed model observer mimics the foveated nature of the human visual system by processing the entire image with varying spatial detail, executing eye movements and scrolling through slices. The model can predict how human search performance changes with signal type and modality (2D vs. 3D), yet its implementation is computationally expensive and time-consuming. Here, we evaluate various image quality metrics using extensions of the classic index of detectability expressions and assess foveated model observers for location-known exactly tasks. We evaluated foveated extensions of a Channelized Hotelling and Non-prewhitening model with an eye filter. The proposed methods involve calculating a model index of detectability (d') for each retinal eccentricity and combining these with a weighting function into a single detectability metric. We assessed different versions of the weighting function that varied in the required measurements of the human observers' search (no measurements, eye movement patterns, and size of the image and median search times). We show that the index of detectability across eccentricities weighted using the eye movement patterns of observers best predicted human performance in 2D vs. 3D search performance for a small microcalcification-like signal and a larger mass-like. The metric with weighting function based on median search times was the second best at predicting human results. The findings provide a set of model observer tools to evaluate image quality in the early stages of imaging system evaluation or design without implementing the more computationally complex foveated search model.