 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Out-of-domain Generalization from a Single Source: A Uncertainty Quantification Approach
Aug 05, 2021
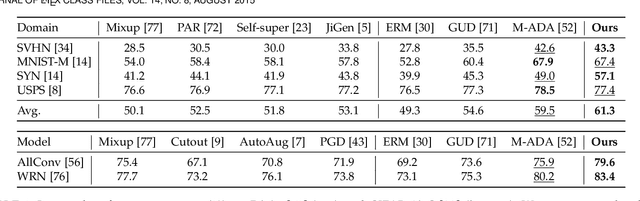
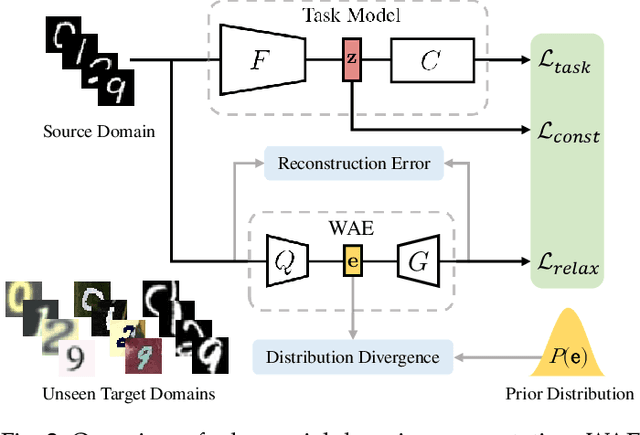
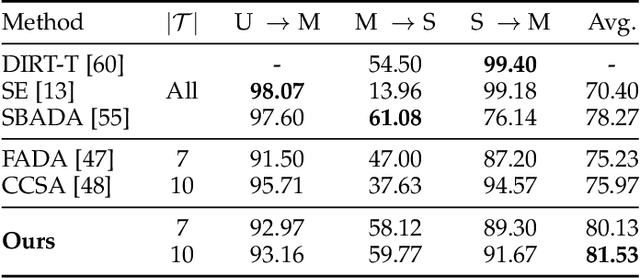
We study a worst-case scenario in generalization: Out-of-domain generalization from a single source. The goal is to learn a robust model from a single source and expect it to generalize over many unknown distributions. This challenging problem has been seldom investigated while existing solutions suffer from various limitations such as the ignorance of uncertainty assessment and label augmentation. In this paper, we propose uncertainty-guided domain generalization to tackle the aforementioned limitations. The key idea is to augment the source capacity in both feature and label spaces, while the augmentation is guided by uncertainty assessment. To the best of our knowledge, this is the first work to (1) quantify the generalization uncertainty from a single source and (2) leverage it to guide both feature and label augmentation for robust generalization. The model training and deployment are effectively organized in a Bayesian meta-learning framework. We conduct extensive comparisons and ablation study to validate our approach. The results prove our superior performance in a wide scope of tasks including image classification, semantic segmentation, text classification, and speech recognition.
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
May 05, 2021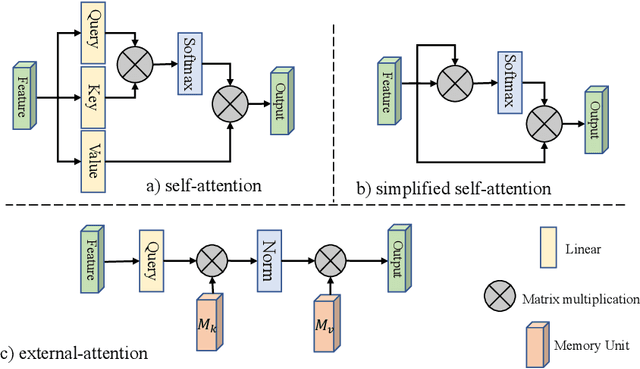
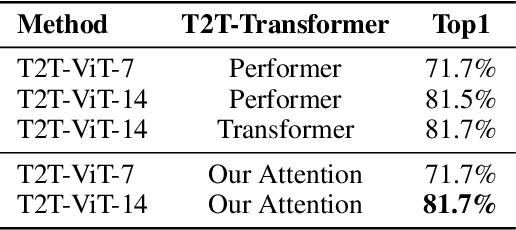

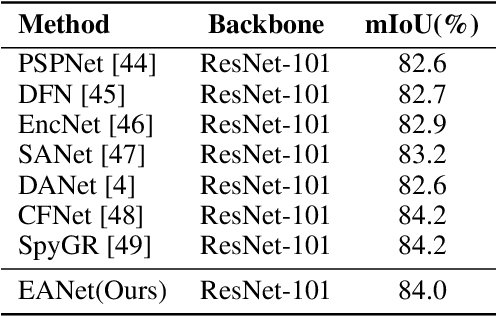
Attention mechanisms, especially self-attention, play an increasingly important role in deep feature representation in visual tasks. Self-attention updates the feature at each position by computing a weighted sum of features using pair-wise affinities across all positions to capture long-range dependency within a single sample. However, self-attention has a quadratic complexity and ignores potential correlation between different samples. This paper proposes a novel attention mechanism which we call external attention, based on two external, small, learnable, and shared memories, which can be implemented easily by simply using two cascaded linear layers and two normalization layers; it conveniently replaces self-attention in existing popular architectures. External attention has linear complexity and implicitly considers the correlations between all samples. Extensive experiments on image classification, semantic segmentation, image generation, point cloud classification and point cloud segmentation tasks reveal that our method provides comparable or superior performance to the self-attention mechanism and some of its variants, with much lower computational and memory costs.
Approximate Query Matching for Image Retrieval
Mar 14, 2018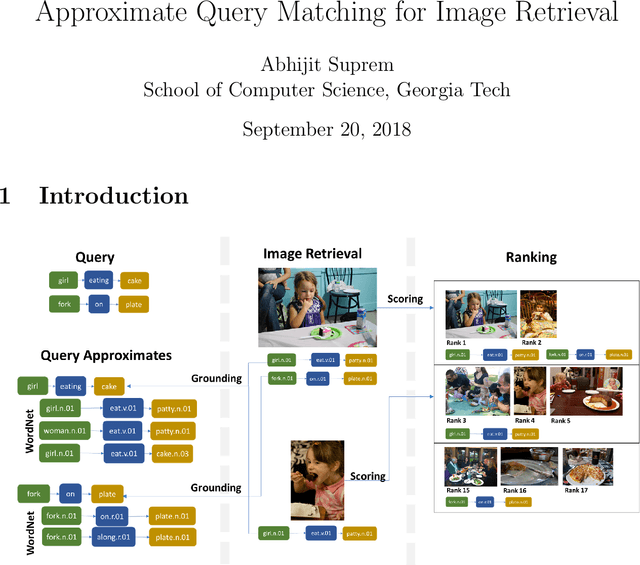
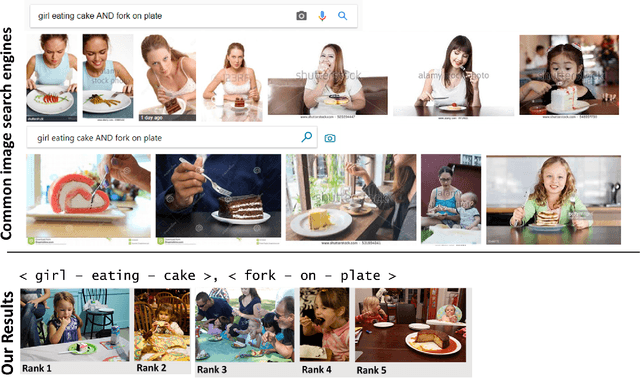
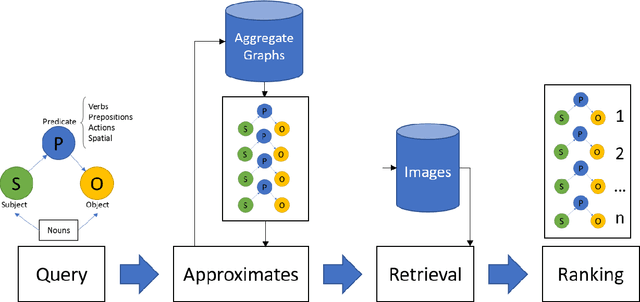
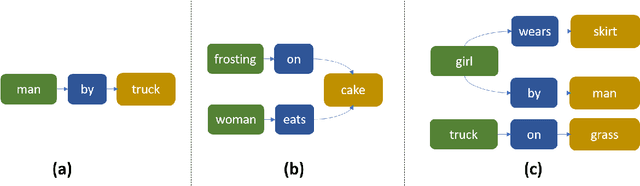
Traditional image recognition involves identifying the key object in a portrait-type image with a single object focus (ILSVRC, AlexNet, and VGG). More recent approaches consider dense image recognition - segmenting an image with appropriate bounding boxes and performing image recognition within these bounding boxes (Semantic segmentation). The Visual Genome dataset [5] is an attempt to bridge these various approaches to a cohesive dataset for each subtask - bounding box generation, image recognition, captioning, and a new operation: scene graph generation. Our focus is on using such scene graphs to perform graph search on image databases to holistically retrieve images based on a search criteria. We develop a method to store scene graphs and metadata in graph databases (using Neo4J) and to perform fast approximate retrieval of images based on a graph search query. We process more complex queries than single object search, e.g. "girl eating cake" retrieves images that contain the specified relation as well as variations.
REO-Relevance, Extraness, Omission: A Fine-grained Evaluation for Image Captioning
Sep 05, 2019
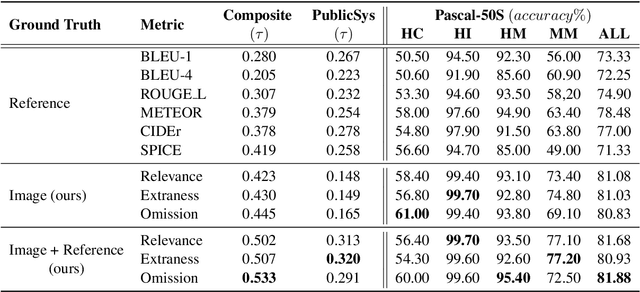
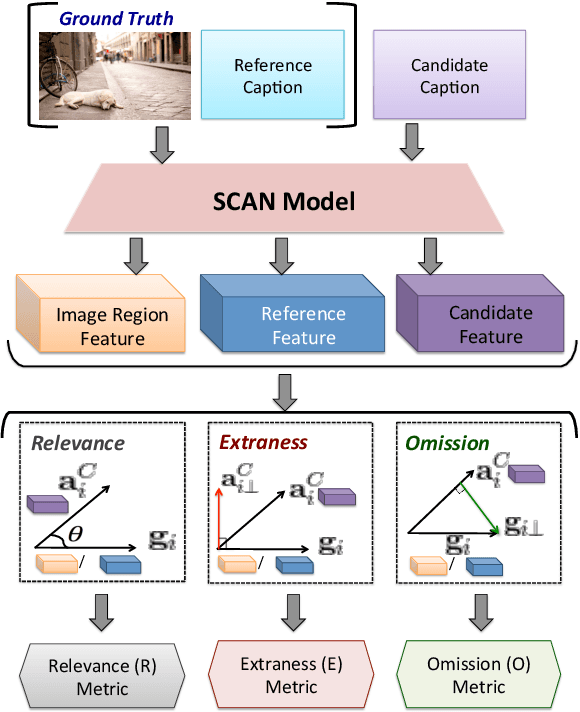

Popular metrics used for evaluating image captioning systems, such as BLEU and CIDEr, provide a single score to gauge the system's overall effectiveness. This score is often not informative enough to indicate what specific errors are made by a given system. In this study, we present a fine-grained evaluation method REO for automatically measuring the performance of image captioning systems. REO assesses the quality of captions from three perspectives: 1) Relevance to the ground truth, 2) Extraness of the content that is irrelevant to the ground truth, and 3) Omission of the elements in the images and human references. Experiments on three benchmark datasets demonstrate that our method achieves a higher consistency with human judgments and provides more intuitive evaluation results than alternative metrics.
CIAN: Cross-Image Affinity Net for Weakly Supervised Semantic Segmentation
Nov 27, 2018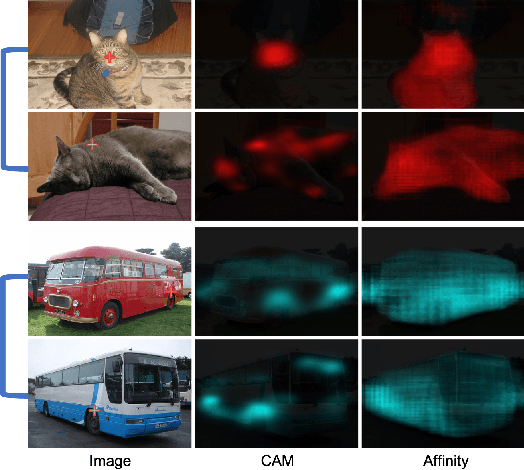
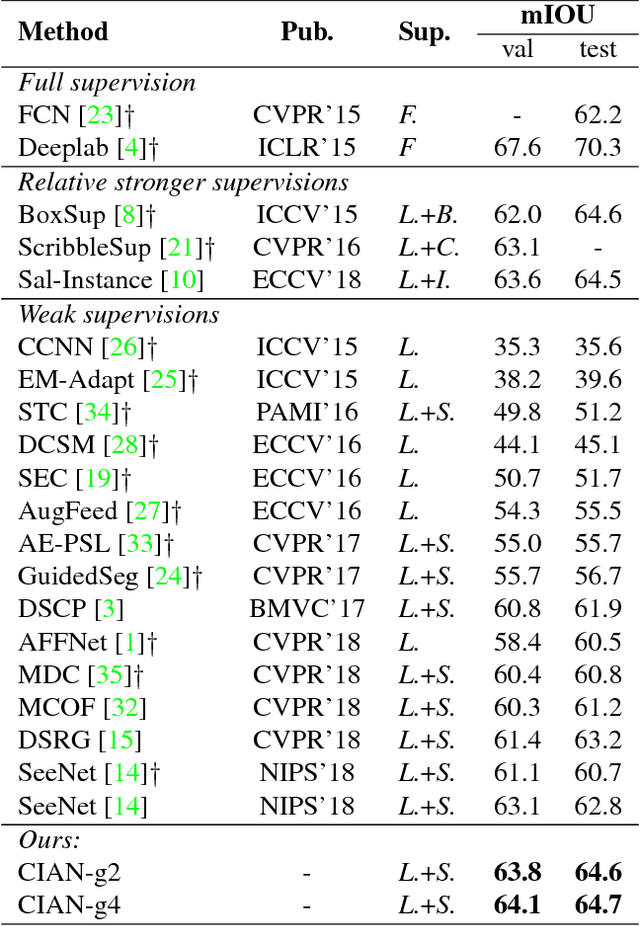
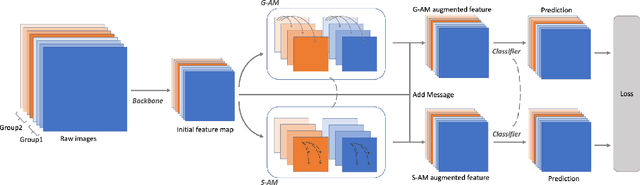
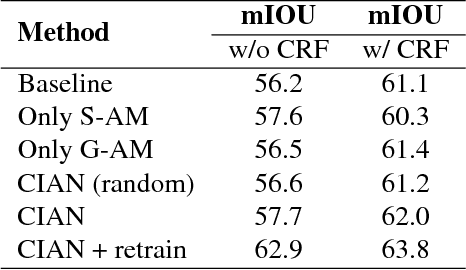
Weakly supervised semantic segmentation based on image-level labels aims for alleviating the data scarcity problem by training with coarse labels. State-of-the-art methods rely on image-level labels to generate proxy segmentation masks, then train the segmentation network on these masks with various constraints. These methods consider each image independently and lack the exploration of cross-image relationships. We argue the cross-image relationship is vital to weakly supervised learning. We propose an end-to-end affinity module for explicitly modeling the relationship among a group of images. By means of this, one image can benefit from the complementary information from other images, and the supervision guidance can be shared in the group. The proposed method improves over the baseline with a large margin. Our method achieves 64.1\% mIOU score on Pascal VOC 2012 validation set, and 64.7\% mIOU score on test set, which is a new state-of-the-art by only using image-level labels, demonstrating the effectiveness of the method.
Disentangled High Quality Salient Object Detection
Sep 02, 2021
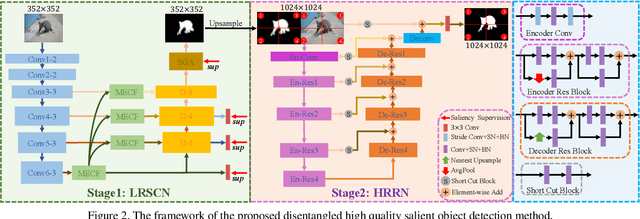
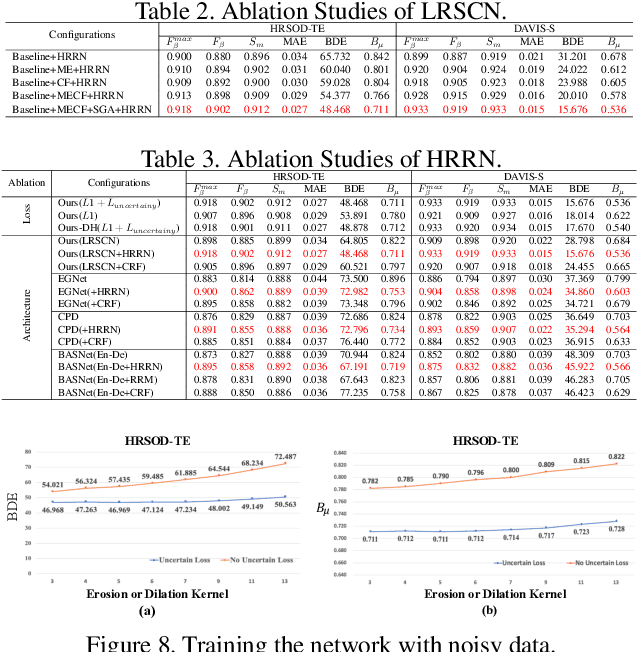
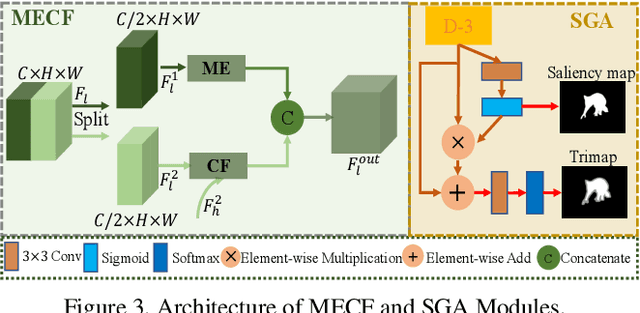
Aiming at discovering and locating most distinctive objects from visual scenes, salient object detection (SOD) plays an essential role in various computer vision systems. Coming to the era of high resolution, SOD methods are facing new challenges. The major limitation of previous methods is that they try to identify the salient regions and estimate the accurate objects boundaries simultaneously with a single regression task at low-resolution. This practice ignores the inherent difference between the two difficult problems, resulting in poor detection quality. In this paper, we propose a novel deep learning framework for high-resolution SOD task, which disentangles the task into a low-resolution saliency classification network (LRSCN) and a high-resolution refinement network (HRRN). As a pixel-wise classification task, LRSCN is designed to capture sufficient semantics at low-resolution to identify the definite salient, background and uncertain image regions. HRRN is a regression task, which aims at accurately refining the saliency value of pixels in the uncertain region to preserve a clear object boundary at high-resolution with limited GPU memory. It is worth noting that by introducing uncertainty into the training process, our HRRN can well address the high-resolution refinement task without using any high-resolution training data. Extensive experiments on high-resolution saliency datasets as well as some widely used saliency benchmarks show that the proposed method achieves superior performance compared to the state-of-the-art methods.
Roughness Index and Roughness Distance for Benchmarking Medical Segmentation
Mar 23, 2021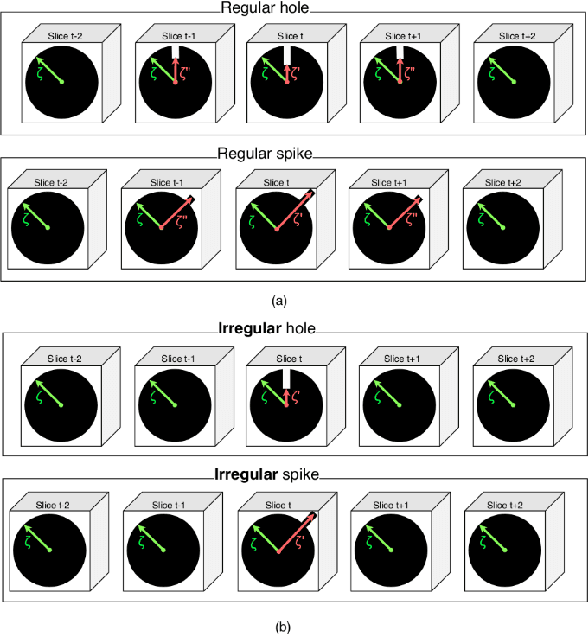
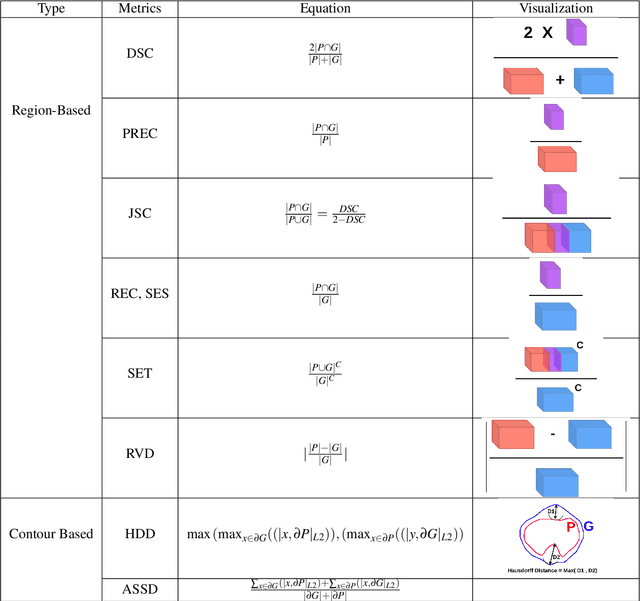
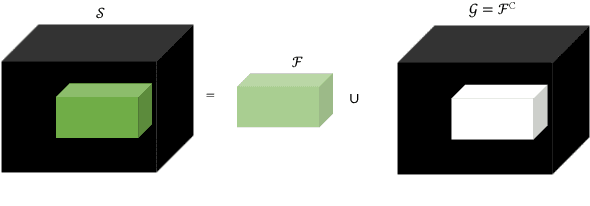

Medical image segmentation is one of the most challenging tasks in medical image analysis and has been widely developed for many clinical applications. Most of the existing metrics have been first designed for natural images and then extended to medical images. While object surface plays an important role in medical segmentation and quantitative analysis i.e. analyze brain tumor surface, measure gray matter volume, most of the existing metrics are limited when it comes to analyzing the object surface, especially to tell about surface smoothness or roughness of a given volumetric object or to analyze the topological errors. In this paper, we first analysis both pros and cons of all existing medical image segmentation metrics, specially on volumetric data. We then propose an appropriate roughness index and roughness distance for medical image segmentation analysis and evaluation. Our proposed method addresses two kinds of segmentation errors, i.e. (i)topological errors on boundary/surface and (ii)irregularities on the boundary/surface. The contribution of this work is four-fold: (i) detect irregular spikes/holes on a surface, (ii) propose roughness index to measure surface roughness of a given object, (iii) propose a roughness distance to measure the distance of two boundaries/surfaces by utilizing the proposed roughness index and (iv) suggest an algorithm which helps to remove the irregular spikes/holes to smooth the surface. Our proposed roughness index and roughness distance are built upon the solid surface roughness parameter which has been successfully developed in the civil engineering.
Learning to Observe: Approximating Human Perceptual Thresholds for Detection of Suprathreshold Image Transformations
Dec 13, 2019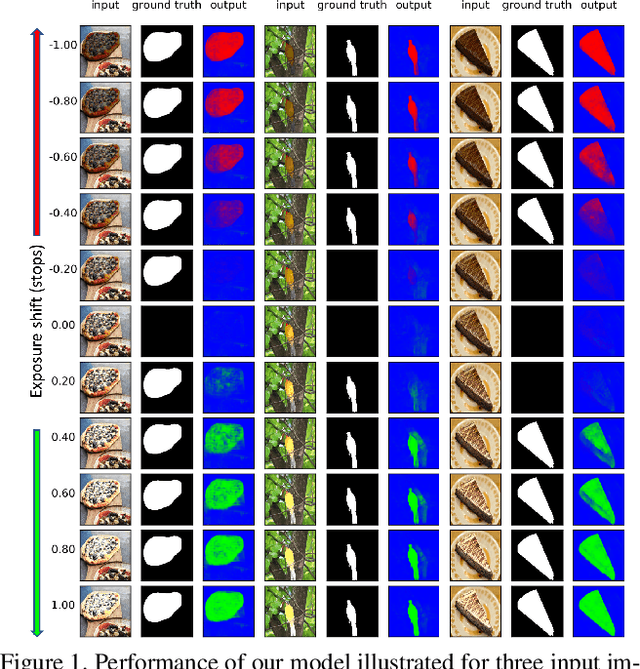
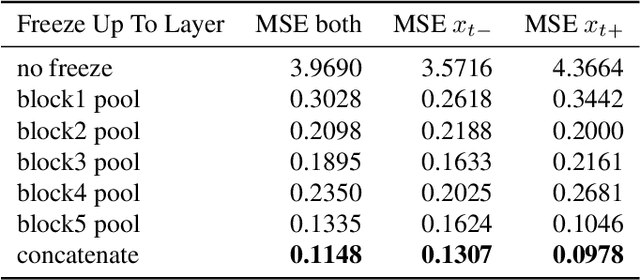
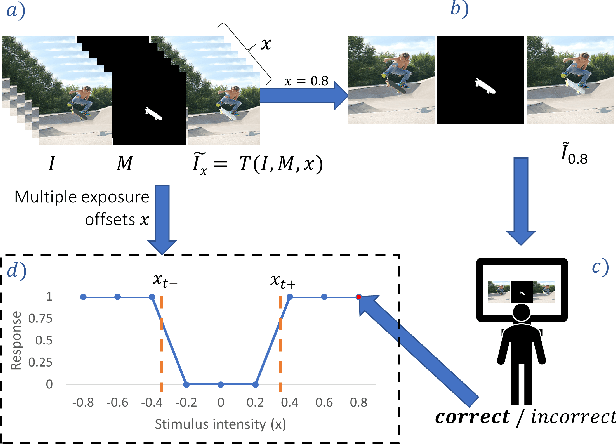
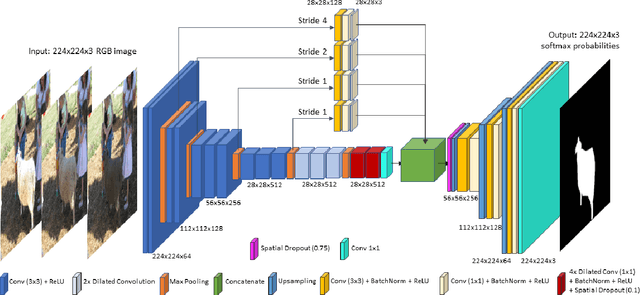
Many tasks in computer vision are often calibrated and evaluated relative to human perception. In this paper, we propose to directly approximate the perceptual function performed by human observers completing a visual detection task. Specifically, we present a novel methodology for learning to detect image transformations visible to human observers through approximating perceptual thresholds. To do this, we carry out a subjective two-alternative forced-choice study to estimate perceptual thresholds of human observers detecting local exposure shifts in images. We then leverage transformation equivariant representation learning to overcome issues of limited perceptual data. This representation is then used to train a dense convolutional classifier capable of detecting local suprathreshold exposure shifts - a distortion common to image composites. In this context, our model is able to approximate perceptual thresholds with an average error of 0.1148 exposure stops between empirical and predicted thresholds. It can also be trained to detect a range of different pixel-wise transformation.
ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias
Jun 07, 2021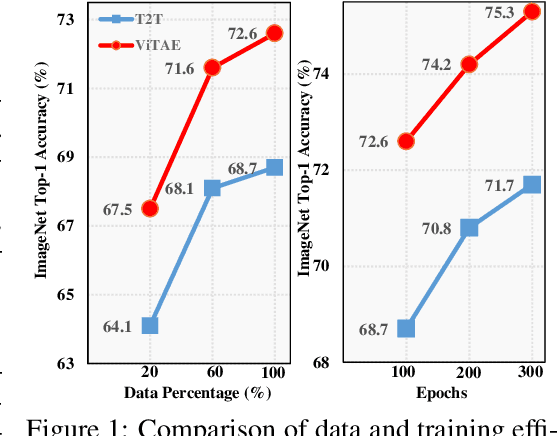

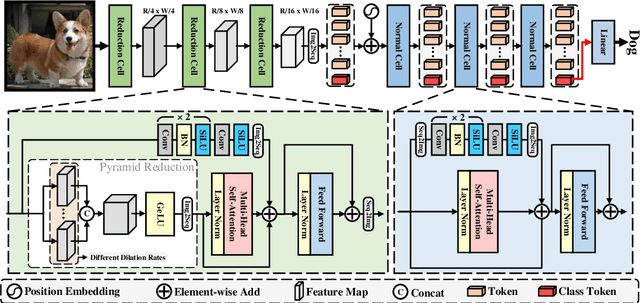
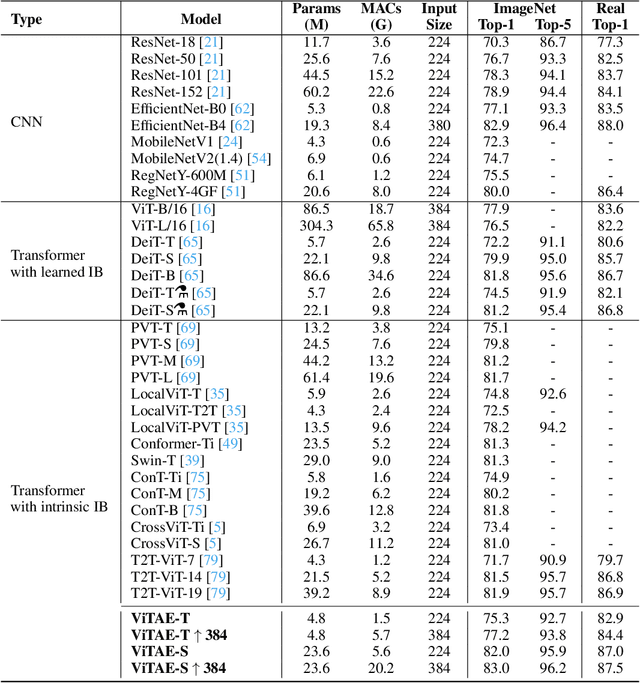
Transformers have shown great potential in various computer vision tasks owing to their strong capability in modeling long-range dependency using the self-attention mechanism. Nevertheless, vision transformers treat an image as 1D sequence of visual tokens, lacking an intrinsic inductive bias (IB) in modeling local visual structures and dealing with scale variance. Alternatively, they require large-scale training data and longer training schedules to learn the IB implicitly. In this paper, we propose a novel Vision Transformer Advanced by Exploring intrinsic IB from convolutions, \ie, ViTAE. Technically, ViTAE has several spatial pyramid reduction modules to downsample and embed the input image into tokens with rich multi-scale context by using multiple convolutions with different dilation rates. In this way, it acquires an intrinsic scale invariance IB and is able to learn robust feature representation for objects at various scales. Moreover, in each transformer layer, ViTAE has a convolution block in parallel to the multi-head self-attention module, whose features are fused and fed into the feed-forward network. Consequently, it has the intrinsic locality IB and is able to learn local features and global dependencies collaboratively. Experiments on ImageNet as well as downstream tasks prove the superiority of ViTAE over the baseline transformer and concurrent works. Source code and pretrained models will be available at GitHub.
Knowledge Distillation Using Hierarchical Self-Supervision Augmented Distribution
Sep 07, 2021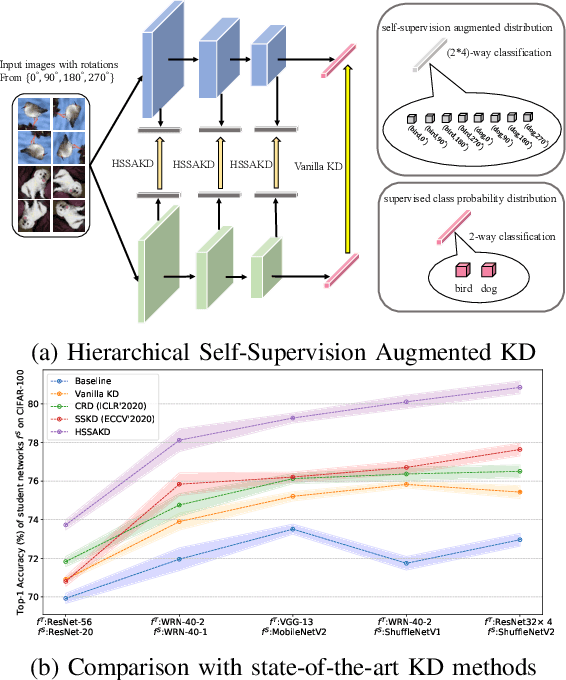
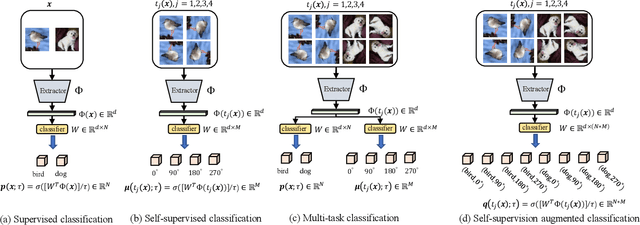
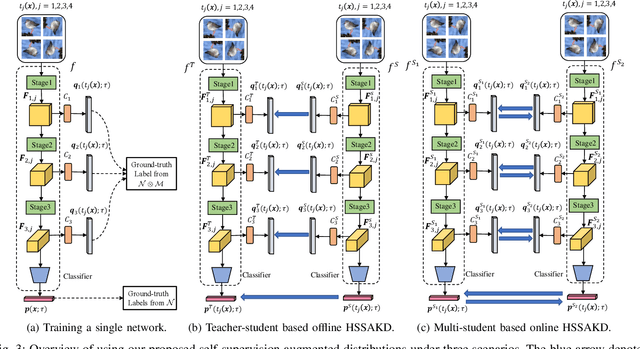

Knowledge distillation (KD) is an effective framework that aims to transfer meaningful information from a large teacher to a smaller student. Generally, KD often involves how to define and transfer knowledge. Previous KD methods often focus on mining various forms of knowledge, for example, feature maps and refined information. However, the knowledge is derived from the primary supervised task and thus is highly task-specific. Motivated by the recent success of self-supervised representation learning, we propose an auxiliary self-supervision augmented task to guide networks to learn more meaningful features. Therefore, we can derive soft self-supervision augmented distributions as richer dark knowledge from this task for KD. Unlike previous knowledge, this distribution encodes joint knowledge from supervised and self-supervised feature learning. Beyond knowledge exploration, another crucial aspect is how to learn and distill our proposed knowledge effectively. To fully take advantage of hierarchical feature maps, we propose to append several auxiliary branches at various hidden layers. Each auxiliary branch is guided to learn self-supervision augmented task and distill this distribution from teacher to student. Thus we call our KD method as Hierarchical Self-Supervision Augmented Knowledge Distillation (HSSAKD). Experiments on standard image classification show that both offline and online HSSAKD achieves state-of-the-art performance in the field of KD. Further transfer experiments on object detection further verify that HSSAKD can guide the network to learn better features, which can be attributed to learn and distill an auxiliary self-supervision augmented task effectively.