 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom the Inside Out: Progressive Distribution Refinement for Confidence Calibration
Mar 17, 2026Leveraging the model's internal information as the self-reward signal in Reinforcement Learning (RL) has received extensive attention due to its label-free nature. While prior works have made significant progress in applying the Test-Time Scaling (TTS) strategies to RL, the discrepancy in internal information between test and training remains inadequately addressed. Moreover, Test-Time Training based on voting-based TTS strategies often suffers from reward hacking problems. To address these issues, we propose DistriTTRL, which leverages the distribution prior of the model's confidence during RL to progressively optimize the reward signal, rather than relying solely on single-query rollouts. Additionally, we mitigate the phenomenon of consistent reward hacking caused by the voting-based TTS strategies through diversity-targeted penalties. Benefiting from this training mechanism where model capability and self-reward signals complement each other, and the mitigation of reward hacking, DistriTTRL has achieved significant performance improvements across multiple models and benchmarks.
Believe Your Model: Distribution-Guided Confidence Calibration
Mar 04, 2026Large Reasoning Models have demonstrated remarkable performance with the advancement of test-time scaling techniques, which enhances prediction accuracy by generating multiple candidate responses and selecting the most reliable answer. While prior work has analyzed that internal model signals like confidence scores can partly indicate response correctness and exhibit a distributional correlation with accuracy, such distributional information has not been fully utilized to guide answer selection. Motivated by this, we propose DistriVoting, which incorporates distributional priors as another signal alongside confidence during voting. Specifically, our method (1) first decomposes the mixed confidence distribution into positive and negative components using Gaussian Mixture Models, (2) then applies a reject filter based on positive/negative samples from them to mitigate overlap between the two distributions. Besides, to further alleviate the overlap from the perspective of distribution itself, we propose SelfStepConf, which uses step-level confidence to dynamically adjust inference process, increasing the separation between the two distributions to improve the reliability of confidences in voting. Experiments across 16 models and 5 benchmarks demonstrate that our method significantly outperforms state-of-the-art approaches.
Semantic Bridging Domains: Pseudo-Source as Test-Time Connector
Mar 04, 2026Distribution shifts between training and testing data are a critical bottleneck limiting the practical utility of models, especially in real-world test-time scenarios. To adapt models when the source domain is unknown and the target domain is unlabeled, previous works constructed pseudo-source domains via data generation and translation, then aligned the target domain with them. However, significant discrepancies exist between the pseudo-source and the original source domain, leading to potential divergence when correcting the target directly. From this perspective, we propose a Stepwise Semantic Alignment (SSA) method, viewing the pseudo-source as a semantic bridge connecting the source and target, rather than a direct substitute for the source. Specifically, we leverage easily accessible universal semantics to rectify the semantic features of the pseudo-source, and then align the target domain using the corrected pseudo-source semantics. Additionally, we introduce a Hierarchical Feature Aggregation (HFA) module and a Confidence-Aware Complementary Learning (CACL) strategy to enhance the semantic quality of the SSA process in the absence of source and ground truth of target domains. We evaluated our approach on tasks like semantic segmentation and image classification, achieving a 5.2% performance boost on GTA2Cityscapes over the state-of-the-art.
Similarity and Dissimilarity Guided Co-association Matrix Construction for Ensemble Clustering
Nov 01, 2024



Ensemble clustering aggregates multiple weak clusterings to achieve a more accurate and robust consensus result. The Co-Association matrix (CA matrix) based method is the mainstream ensemble clustering approach that constructs the similarity relationships between sample pairs according the weak clustering partitions to generate the final clustering result. However, the existing methods neglect that the quality of cluster is related to its size, i.e., a cluster with smaller size tends to higher accuracy. Moreover, they also do not consider the valuable dissimilarity information in the base clusterings which can reflect the varying importance of sample pairs that are completely disconnected. To this end, we propose the Similarity and Dissimilarity Guided Co-association matrix (SDGCA) to achieve ensemble clustering. First, we introduce normalized ensemble entropy to estimate the quality of each cluster, and construct a similarity matrix based on this estimation. Then, we employ the random walk to explore high-order proximity of base clusterings to construct a dissimilarity matrix. Finally, the adversarial relationship between the similarity matrix and the dissimilarity matrix is utilized to construct a promoted CA matrix for ensemble clustering. We compared our method with 13 state-of-the-art methods across 12 datasets, and the results demonstrated the superiority clustering ability and robustness of the proposed approach. The code is available at https://github.com/xuz2019/SDGCA.
MM-Point: Multi-View Information-Enhanced Multi-Modal Self-Supervised 3D Point Cloud Understanding
Feb 25, 2024



In perception, multiple sensory information is integrated to map visual information from 2D views onto 3D objects, which is beneficial for understanding in 3D environments. But in terms of a single 2D view rendered from different angles, only limited partial information can be provided.The richness and value of Multi-view 2D information can provide superior self-supervised signals for 3D objects. In this paper, we propose a novel self-supervised point cloud representation learning method, MM-Point, which is driven by intra-modal and inter-modal similarity objectives. The core of MM-Point lies in the Multi-modal interaction and transmission between 3D objects and multiple 2D views at the same time. In order to more effectively simultaneously perform the consistent cross-modal objective of 2D multi-view information based on contrastive learning, we further propose Multi-MLP and Multi-level Augmentation strategies. Through carefully designed transformation strategies, we further learn Multi-level invariance in 2D Multi-views. MM-Point demonstrates state-of-the-art (SOTA) performance in various downstream tasks. For instance, it achieves a peak accuracy of 92.4% on the synthetic dataset ModelNet40, and a top accuracy of 87.8% on the real-world dataset ScanObjectNN, comparable to fully supervised methods. Additionally, we demonstrate its effectiveness in tasks such as few-shot classification, 3D part segmentation and 3D semantic segmentation.
Towards Stable Co-saliency Detection and Object Co-segmentation
Oct 02, 2022



In this paper, we present a novel model for simultaneous stable co-saliency detection (CoSOD) and object co-segmentation (CoSEG). To detect co-saliency (segmentation) accurately, the core problem is to well model inter-image relations between an image group. Some methods design sophisticated modules, such as recurrent neural network (RNN), to address this problem. However, order-sensitive problem is the major drawback of RNN, which heavily affects the stability of proposed CoSOD (CoSEG) model. In this paper, inspired by RNN-based model, we first propose a multi-path stable recurrent unit (MSRU), containing dummy orders mechanisms (DOM) and recurrent unit (RU). Our proposed MSRU not only helps CoSOD (CoSEG) model captures robust inter-image relations, but also reduces order-sensitivity, resulting in a more stable inference and training process. { Moreover, we design a cross-order contrastive loss (COCL) that can further address order-sensitive problem by pulling close the feature embedding generated from different input orders.} We validate our model on five widely used CoSOD datasets (CoCA, CoSOD3k, Cosal2015, iCoseg and MSRC), and three widely used datasets (Internet, iCoseg and PASCAL-VOC) for object co-segmentation, the performance demonstrates the superiority of the proposed approach as compared to the state-of-the-art (SOTA) methods.
Disentangled High Quality Salient Object Detection
Sep 02, 2021
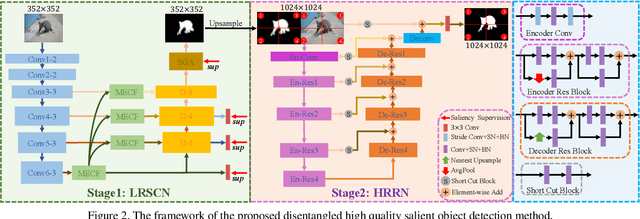
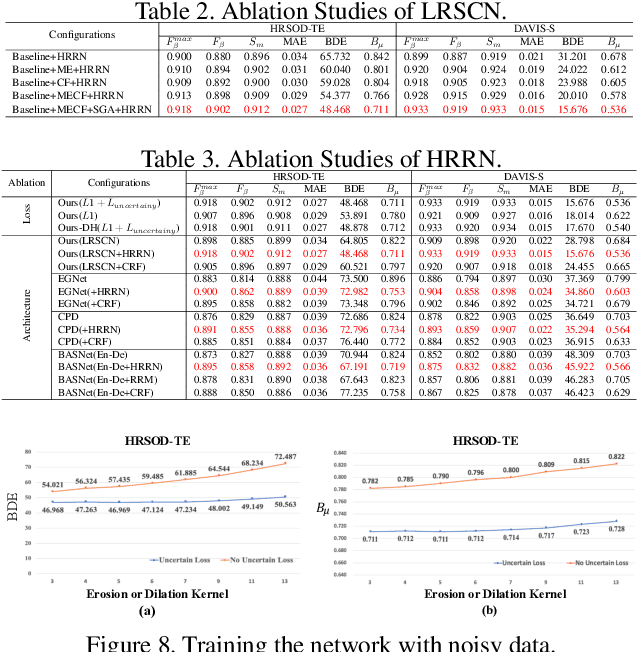
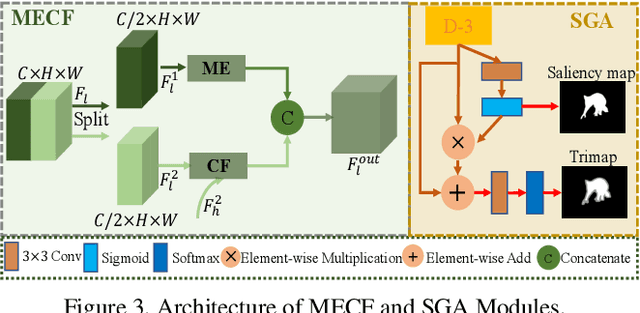
Aiming at discovering and locating most distinctive objects from visual scenes, salient object detection (SOD) plays an essential role in various computer vision systems. Coming to the era of high resolution, SOD methods are facing new challenges. The major limitation of previous methods is that they try to identify the salient regions and estimate the accurate objects boundaries simultaneously with a single regression task at low-resolution. This practice ignores the inherent difference between the two difficult problems, resulting in poor detection quality. In this paper, we propose a novel deep learning framework for high-resolution SOD task, which disentangles the task into a low-resolution saliency classification network (LRSCN) and a high-resolution refinement network (HRRN). As a pixel-wise classification task, LRSCN is designed to capture sufficient semantics at low-resolution to identify the definite salient, background and uncertain image regions. HRRN is a regression task, which aims at accurately refining the saliency value of pixels in the uncertain region to preserve a clear object boundary at high-resolution with limited GPU memory. It is worth noting that by introducing uncertainty into the training process, our HRRN can well address the high-resolution refinement task without using any high-resolution training data. Extensive experiments on high-resolution saliency datasets as well as some widely used saliency benchmarks show that the proposed method achieves superior performance compared to the state-of-the-art methods.