 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image contrast enhancement using fuzzy logic
Sep 12, 2018
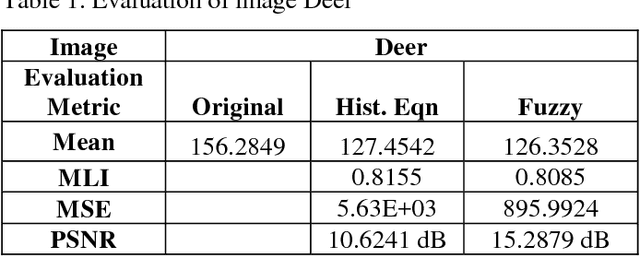

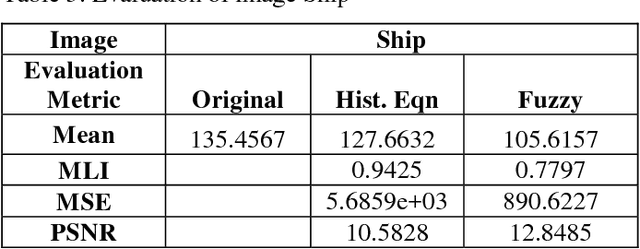
Image enhancement is a method of improving the quality of an image and contrast is a major aspect. Traditional methods of contrast enhancement like histogram equalization results in over/under enhancement of the image especially a lower resolution one. This paper aims at developing a new Fuzzy Inference System to enhance the contrast of the low resolution images overcoming the shortcomings of the traditional methods. Results obtained using both the approaches are compared.
A Fusion-Denoising Attack on InstaHide with Data Augmentation
May 17, 2021


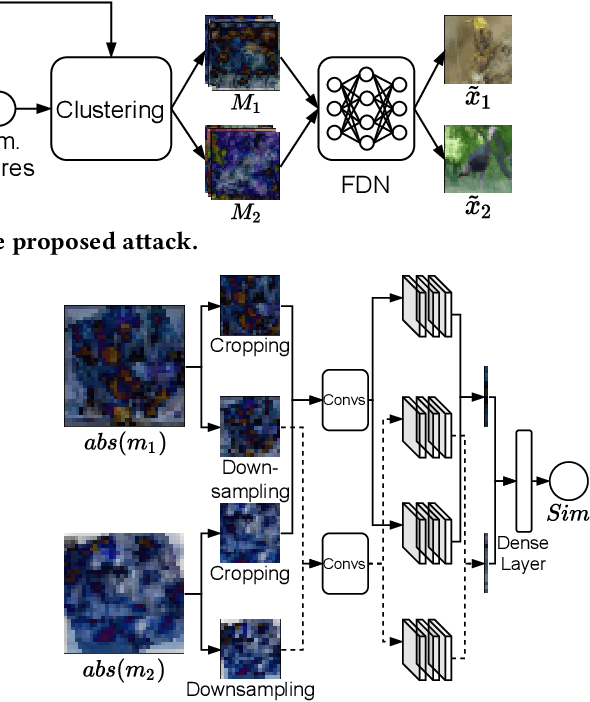
InstaHide is a state-of-the-art mechanism for protecting private training images in collaborative learning. It works by mixing multiple private images and modifying them in such a way that their visual features are no longer distinguishable to the naked eye, without significantly degrading the accuracy of training. In recent work, however, Carlini et al. show that it is possible to reconstruct private images from the encrypted dataset generated by InstaHide, by exploiting the correlations among the encrypted images. Nevertheless, Carlini et al.'s attack relies on the assumption that each private image is used without modification when mixing up with other private images. As a consequence, it could be easily defeated by incorporating data augmentation into InstaHide. This leads to a natural question: is InstaHide with data augmentation secure? This paper provides a negative answer to the above question, by present an attack for recovering private images from the outputs of InstaHide even when data augmentation is present. The basic idea of our attack is to use a comparative network to identify encrypted images that are likely to correspond to the same private image, and then employ a fusion-denoising network for restoring the private image from the encrypted ones, taking into account the effects of data augmentation. Extensive experiments demonstrate the effectiveness of the proposed attack in comparison to Carlini et al.'s attack.
Pivotal Tuning for Latent-based Editing of Real Images
Jun 10, 2021
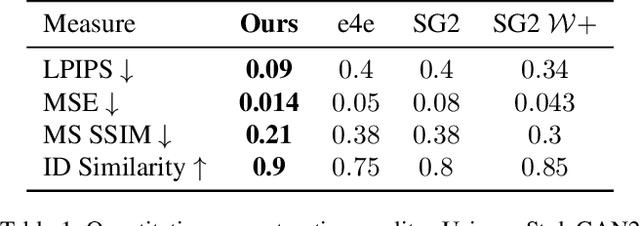
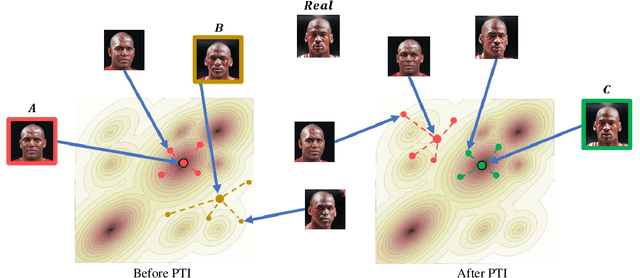
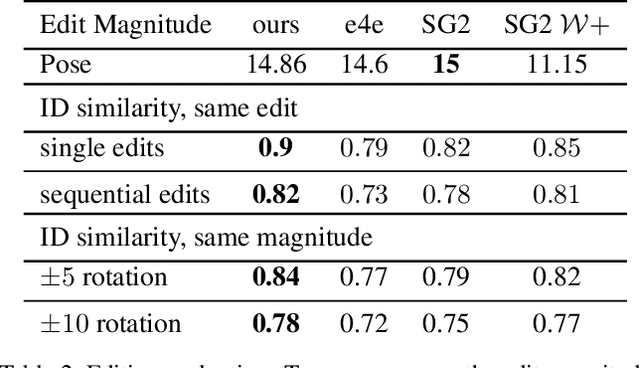
Recently, a surge of advanced facial editing techniques have been proposed that leverage the generative power of a pre-trained StyleGAN. To successfully edit an image this way, one must first project (or invert) the image into the pre-trained generator's domain. As it turns out, however, StyleGAN's latent space induces an inherent tradeoff between distortion and editability, i.e. between maintaining the original appearance and convincingly altering some of its attributes. Practically, this means it is still challenging to apply ID-preserving facial latent-space editing to faces which are out of the generator's domain. In this paper, we present an approach to bridge this gap. Our technique slightly alters the generator, so that an out-of-domain image is faithfully mapped into an in-domain latent code. The key idea is pivotal tuning - a brief training process that preserves the editing quality of an in-domain latent region, while changing its portrayed identity and appearance. In Pivotal Tuning Inversion (PTI), an initial inverted latent code serves as a pivot, around which the generator is fined-tuned. At the same time, a regularization term keeps nearby identities intact, to locally contain the effect. This surgical training process ends up altering appearance features that represent mostly identity, without affecting editing capabilities. We validate our technique through inversion and editing metrics, and show preferable scores to state-of-the-art methods. We further qualitatively demonstrate our technique by applying advanced edits (such as pose, age, or expression) to numerous images of well-known and recognizable identities. Finally, we demonstrate resilience to harder cases, including heavy make-up, elaborate hairstyles and/or headwear, which otherwise could not have been successfully inverted and edited by state-of-the-art methods.
Mixed-Supervised Dual-Network for Medical Image Segmentation
Aug 26, 2019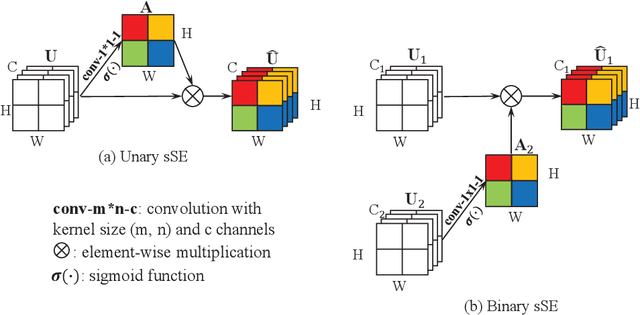
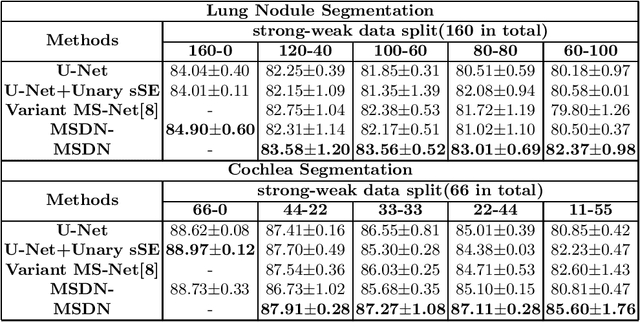
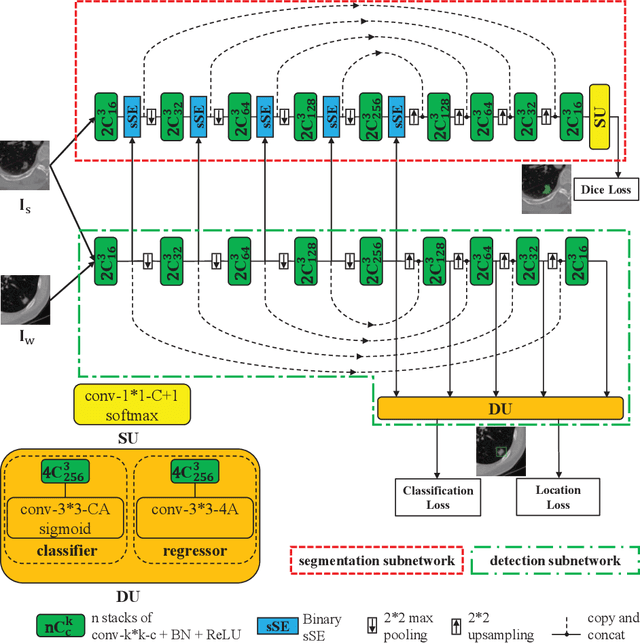
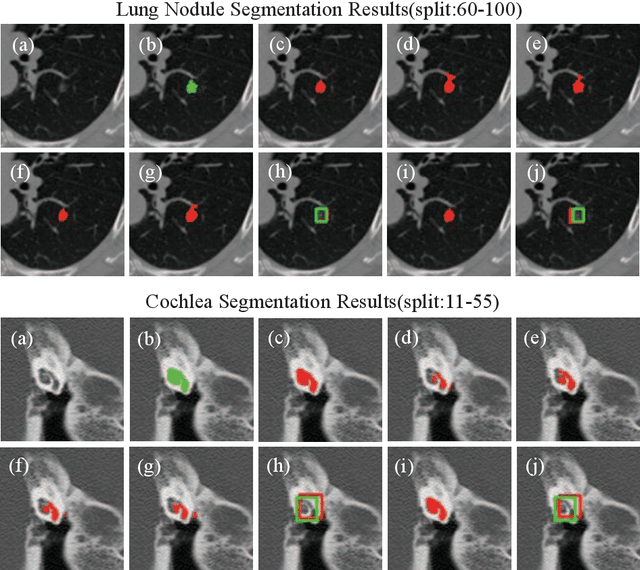
Deep learning based medical image segmentation models usually require large datasets with high-quality dense segmentations to train, which are very time-consuming and expensive to prepare. One way to tackle this challenge is by using the mixed-supervised learning framework, in which only a part of data is densely annotated with segmentation label and the rest is weakly labeled with bounding boxes. The model is trained jointly in a multi-task learning setting. In this paper, we propose Mixed-Supervised Dual-Network (MSDN), a novel architecture which consists of two separate networks for the detection and segmentation tasks respectively, and a series of connection modules between the layers of the two networks. These connection modules are used to transfer useful information from the auxiliary detection task to help the segmentation task. We propose to use a recent technique called "Squeeze and Excitation" in the connection module to boost the transfer. We conduct experiments on two medical image segmentation datasets. The proposed MSDN model outperforms multiple baselines.
Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging
May 28, 2021
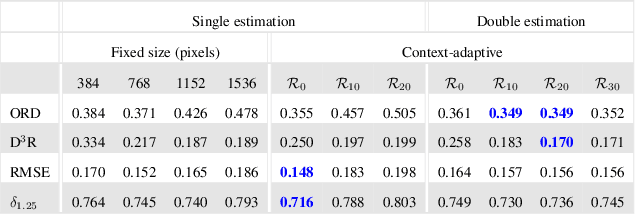


Neural networks have shown great abilities in estimating depth from a single image. However, the inferred depth maps are well below one-megapixel resolution and often lack fine-grained details, which limits their practicality. Our method builds on our analysis on how the input resolution and the scene structure affects depth estimation performance. We demonstrate that there is a trade-off between a consistent scene structure and the high-frequency details, and merge low- and high-resolution estimations to take advantage of this duality using a simple depth merging network. We present a double estimation method that improves the whole-image depth estimation and a patch selection method that adds local details to the final result. We demonstrate that by merging estimations at different resolutions with changing context, we can generate multi-megapixel depth maps with a high level of detail using a pre-trained model.
* For more details visit http://yaksoy.github.io/highresdepth/
A Topological Solution of Entanglement for Complex-shaped Parts in Robotic Bin-picking
Jun 02, 2021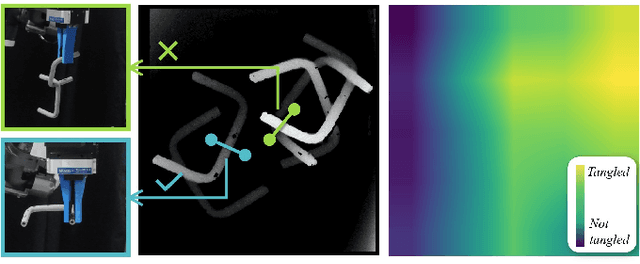


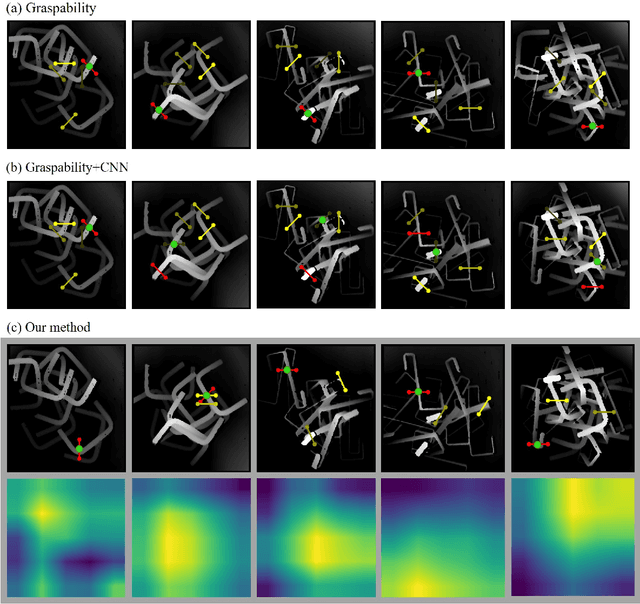
This paper addresses the problem of picking up only one object at a time avoiding any entanglement in bin-picking. To cope with a difficult case where the complex-shaped objects are heavily entangled together, we propose a topology-based method that can generate non-tangle grasp positions on a single depth image. The core technique is entanglement map, which is a feature map to measure the entanglement possibilities obtained from the input image. We use the entanglement map to select probable regions containing graspable objects. The optimum grasping pose is detected from the selected regions considering the collision between robot hand and objects. Experimental results show that our analytic method provides a more comprehensive and intuitive observation of entanglement and exceeds previous learning-based work in success rates. Especially, our topology-based method does not rely on any object models or time-consuming training process, so that it can be easily adapted to more complex bin-picking scenes.
VITAL: A Visual Interpretation on Text with Adversarial Learning for Image Labeling
Jul 26, 2019
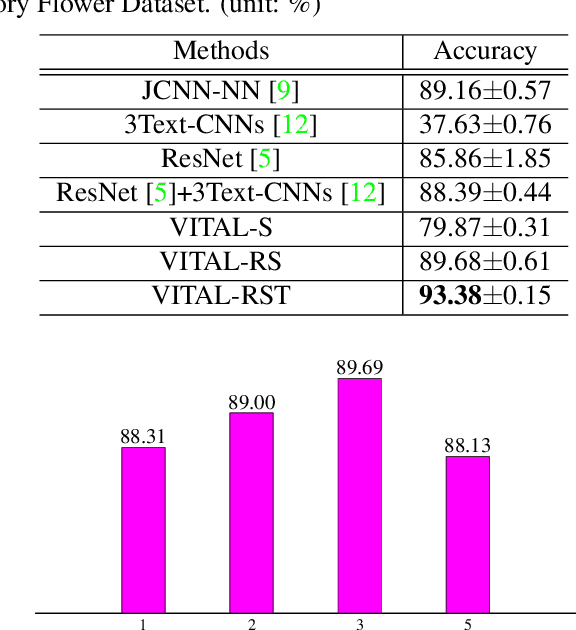
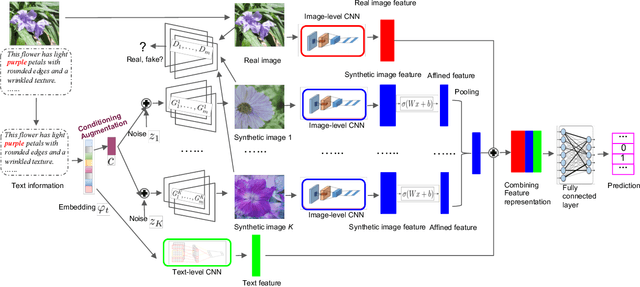
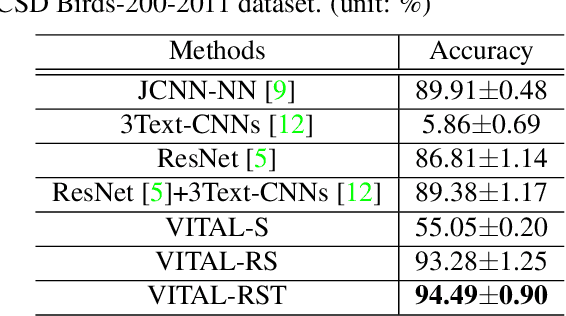
In this paper, we propose a novel way to interpret text information by extracting visual feature presentation from multiple high-resolution and photo-realistic synthetic images generated by Text-to-image Generative Adversarial Network (GAN) to improve the performance of image labeling. Firstly, we design a stacked Generative Multi-Adversarial Network (GMAN), StackGMAN++, a modified version of the current state-of-the-art Text-to-image GAN, StackGAN++, to generate multiple synthetic images with various prior noises conditioned on a text. And then we extract deep visual features from the generated synthetic images to explore the underlying visual concepts for text. Finally, we combine image-level visual feature, text-level feature and visual features based on synthetic images together to predict labels for images. We conduct experiments on two benchmark datasets and the experimental results clearly demonstrate the efficacy of our proposed approach.
Deep Visual Reasoning: Learning to Predict Action Sequences for Task and Motion Planning from an Initial Scene Image
Jun 09, 2020
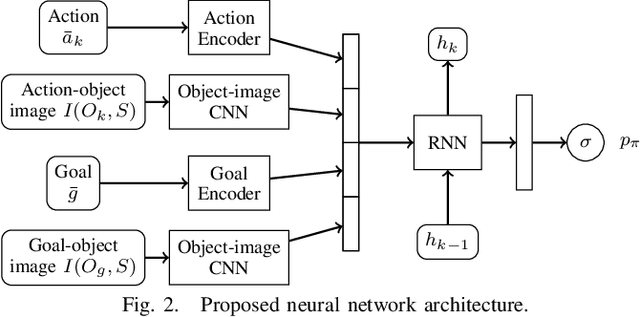
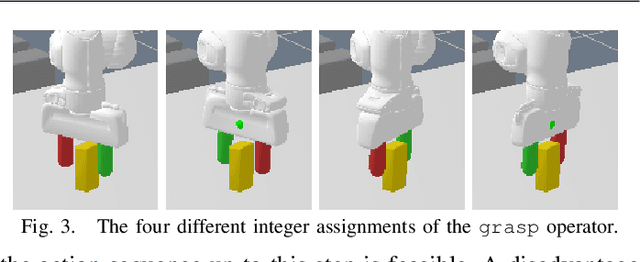
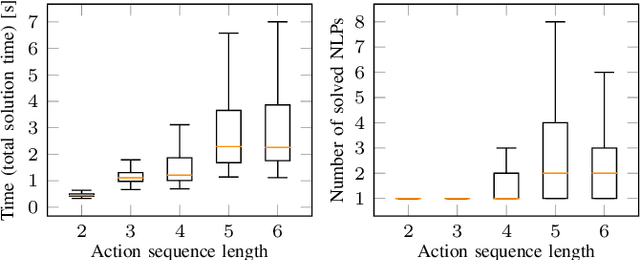
In this paper, we propose a deep convolutional recurrent neural network that predicts action sequences for task and motion planning (TAMP) from an initial scene image. Typical TAMP problems are formalized by combining reasoning on a symbolic, discrete level (e.g. first-order logic) with continuous motion planning such as nonlinear trajectory optimization. Due to the great combinatorial complexity of possible discrete action sequences, a large number of optimization/motion planning problems have to be solved to find a solution, which limits the scalability of these approaches. To circumvent this combinatorial complexity, we develop a neural network which, based on an initial image of the scene, directly predicts promising discrete action sequences such that ideally only one motion planning problem has to be solved to find a solution to the overall TAMP problem. A key aspect is that our method generalizes to scenes with many and varying number of objects, although being trained on only two objects at a time. This is possible by encoding the objects of the scene in images as input to the neural network, instead of a fixed feature vector. Results show runtime improvements of several magnitudes. Video: https://youtu.be/i8yyEbbvoEk
Slot Based Image Augmentation System for Object Detection
Jul 19, 2019
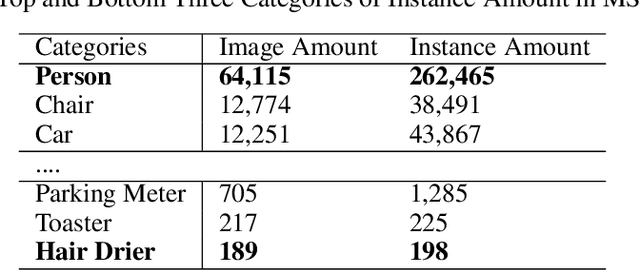
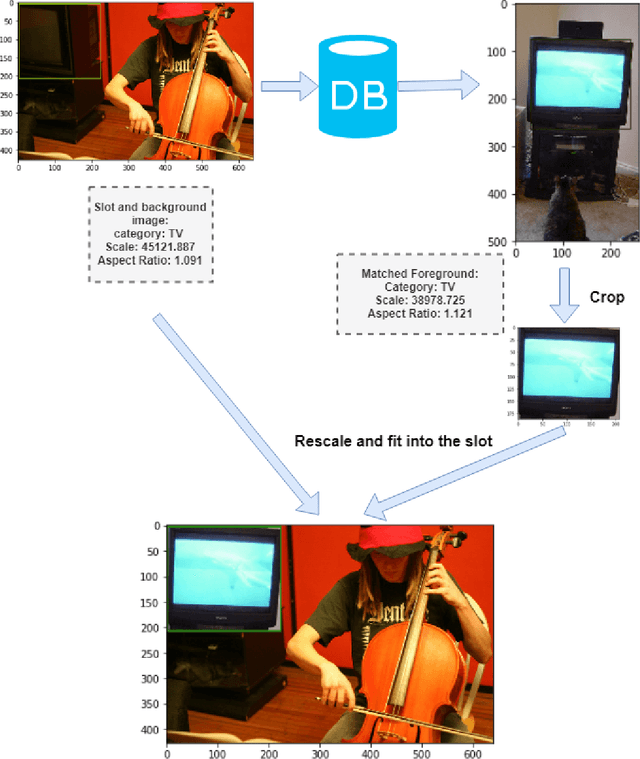

Object Detection has been a significant topic in computer vision. As the continuous development of Deep Learning, many advanced academic and industrial outcomes are established on localising and classifying the target objects, such as instance segmentation, video tracking and robotic vision. As the core concept of Deep Learning, Deep Neural Networks (DNNs) and associated training are highly integrated with task-driven modelling, having great effects on accurate detection. The main focus of improving detection performance is proposing DNNs with extra layers and novel topological connections to extract the desired features from input data. However, training these models can be computationally expensive and laborious progress as the complicated model architecture and enormous parameters. Besides, the dataset is another reason causing this issue and low detection accuracy, because of insufficient data samples or difficult instances. To address these training difficulties, this thesis presents two different approaches to improve the detection performance in the relatively light-weight way. As the intrinsic feature of data-driven in deep learning, the first approach is "slot-based image augmentation" to enrich the dataset with extra foreground and background combinations. Instead of the commonly used image flipping method, the proposed system achieved similar mAP improvement with less extra images which decrease training time. This proposed augmentation system has extra flexibility adapting to various scenarios and the performance-driven analysis provides an alternative aspect of conducting image augmentation
LEA-Net: Layer-wise External Attention Network for Efficient Color Anomaly Detection
Sep 12, 2021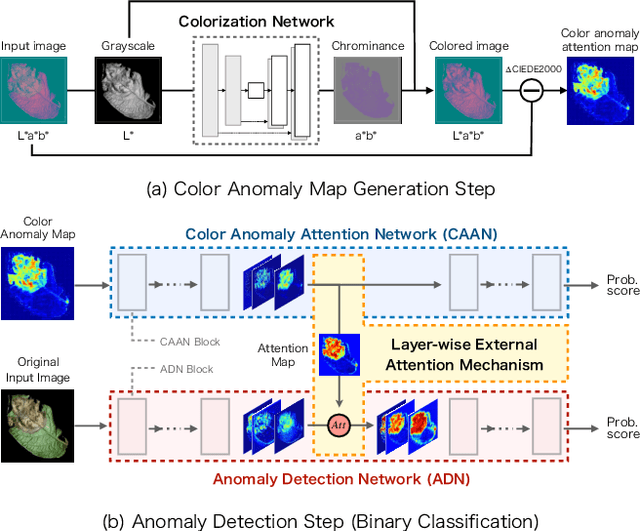
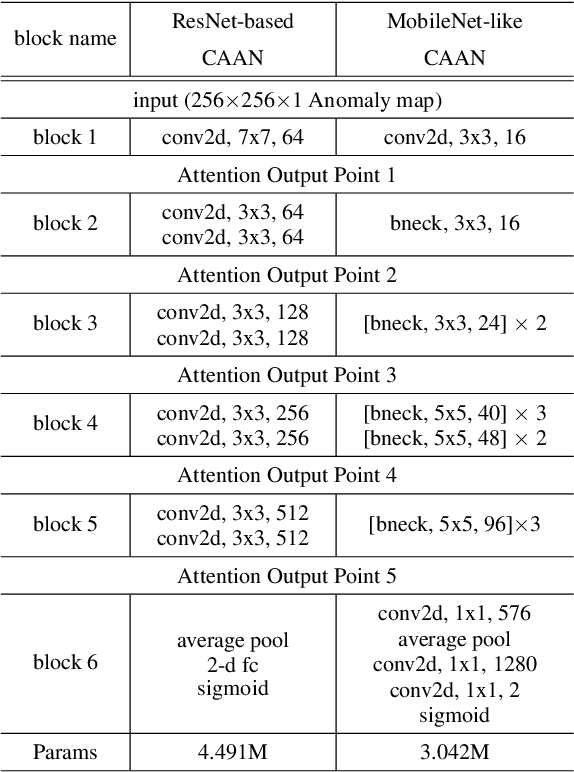
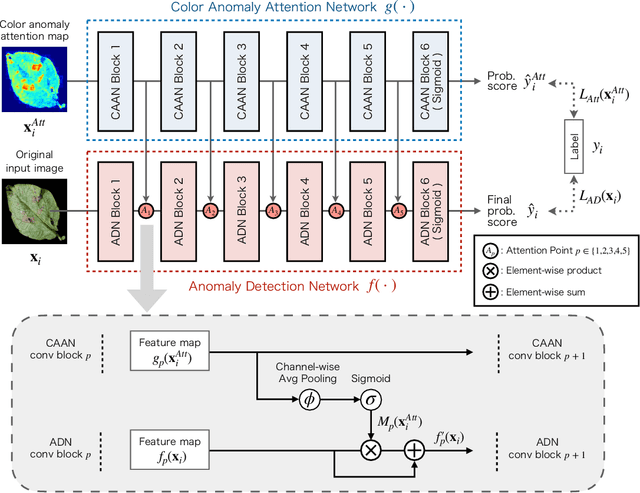
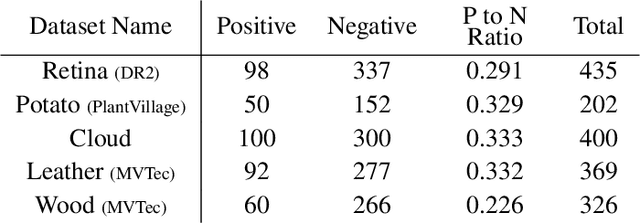
The utilization of prior knowledge about anomalies is an essential issue for anomaly detections. Recently, the visual attention mechanism has become a promising way to improve the performance of CNNs for some computer vision tasks. In this paper, we propose a novel model called Layer-wise External Attention Network (LEA-Net) for efficient image anomaly detection. The core idea relies on the integration of unsupervised and supervised anomaly detectors via the visual attention mechanism. Our strategy is as follows: (i) Prior knowledge about anomalies is represented as the anomaly map generated by unsupervised learning of normal instances, (ii) The anomaly map is translated to an attention map by the external network, (iii) The attention map is then incorporated into intermediate layers of the anomaly detection network. Notably, this layer-wise external attention can be applied to any CNN model in an end-to-end training manner. For a pilot study, we validate LEA-Net on color anomaly detection tasks. Through extensive experiments on PlantVillage, MVTec AD, and Cloud datasets, we demonstrate that the proposed layer-wise visual attention mechanism consistently boosts anomaly detection performances of an existing CNN model, even on imbalanced datasets. Moreover, we show that our attention mechanism successfully boosts the performance of several CNN models.