 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Danish Fungi 2020 -- Not Just Another Image Recognition Dataset
Mar 22, 2021

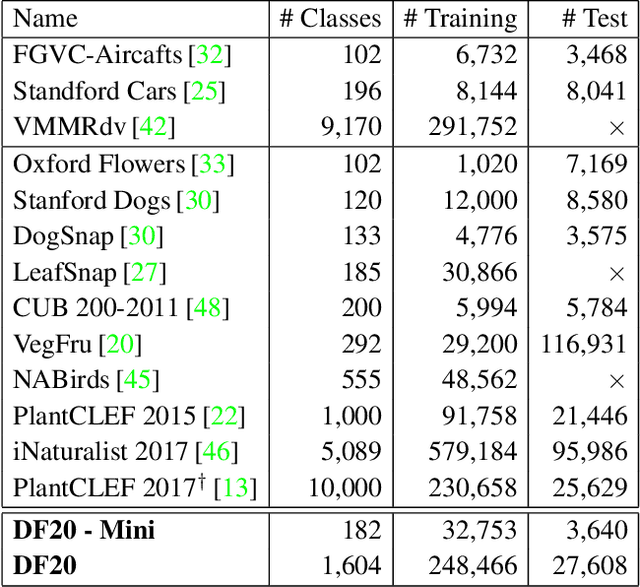
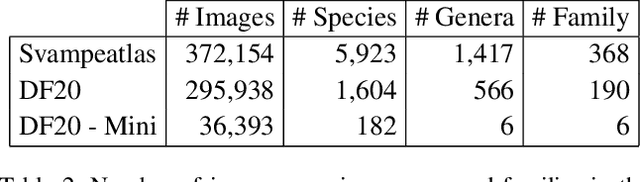
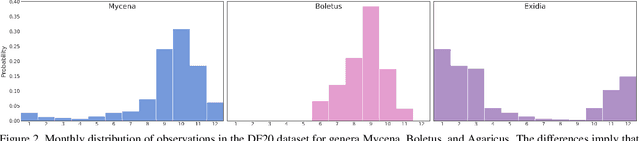
We introduce a novel fine-grained dataset and benchmark, the Danish Fungi 2020 (DF20). The dataset, constructed from observations submitted to the Danish Fungal Atlas, is unique in its taxonomy-accurate class labels, small number of errors, highly unbalanced long-tailed class distribution, rich observation metadata, and well-defined class hierarchy. DF20 has zero overlap with ImageNet, allowing unbiased comparison of models fine-tuned from publicly available ImageNet checkpoints. The proposed evaluation protocol enables testing the ability to improve classification using metadata -- e.g. precise geographic location, habitat, and substrate, facilitates classifier calibration testing, and finally allows to study the impact of the device settings on the classification performance. Experiments using Convolutional Neural Networks (CNN) and the recent Vision Transformers (ViT) show that DF20 presents a challenging task. Interestingly, ViT achieves results superior to CNN baselines with 81.25% accuracy, reducing the CNN error by 13%. A baseline procedure for including metadata into the decision process improves the classification accuracy by more than 3.5 percentage points, reducing the error rate by 20%. The source code for all methods and experiments is available at https://sites.google.com/view/danish-fungi-dataset.
Variational Diffusion Models
Jul 12, 2021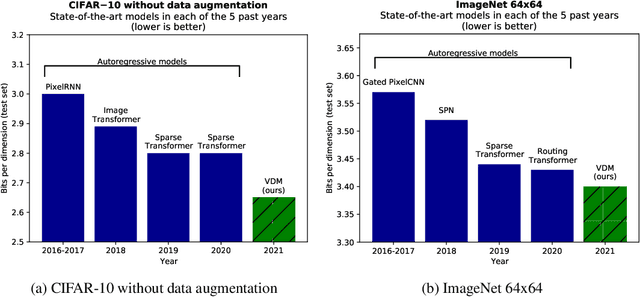
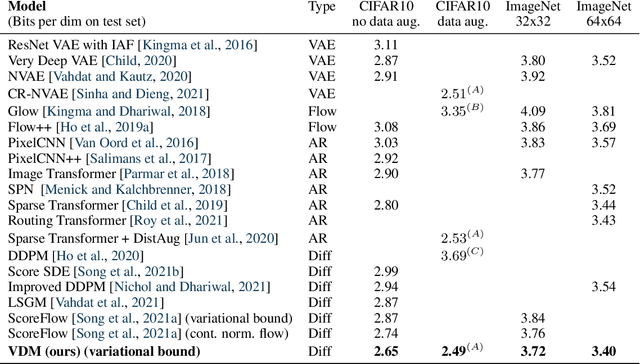

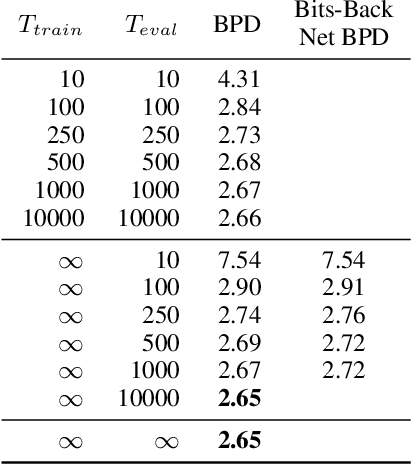
Diffusion-based generative models have demonstrated a capacity for perceptually impressive synthesis, but can they also be great likelihood-based models? We answer this in the affirmative, and introduce a family of diffusion-based generative models that obtain state-of-the-art likelihoods on standard image density estimation benchmarks. Unlike other diffusion-based models, our method allows for efficient optimization of the noise schedule jointly with the rest of the model. We show that the variational lower bound (VLB) simplifies to a remarkably short expression in terms of the signal-to-noise ratio of the diffused data, thereby improving our theoretical understanding of this model class. Using this insight, we prove an equivalence between several models proposed in the literature. In addition, we show that the continuous-time VLB is invariant to the noise schedule, except for the signal-to-noise ratio at its endpoints. This enables us to learn a noise schedule that minimizes the variance of the resulting VLB estimator, leading to faster optimization. Combining these advances with architectural improvements, we obtain state-of-the-art likelihoods on image density estimation benchmarks, outperforming autoregressive models that have dominated these benchmarks for many years, with often significantly faster optimization. In addition, we show how to turn the model into a bits-back compression scheme, and demonstrate lossless compression rates close to the theoretical optimum.
Data Augmentation and CNN Classification For Automatic COVID-19 Diagnosis From CT-Scan Images On Small Dataset
Aug 16, 2021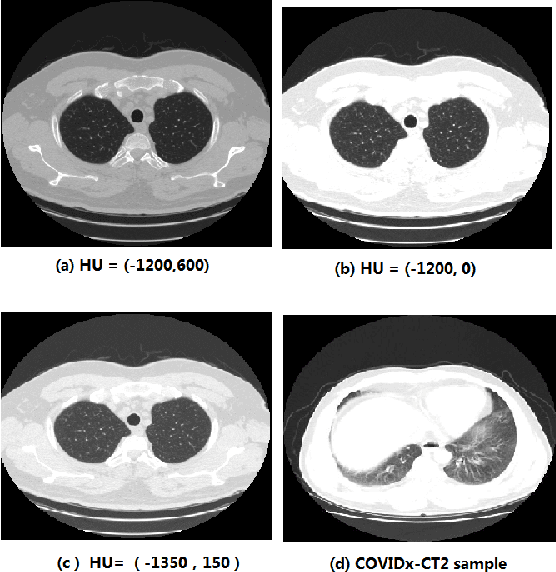
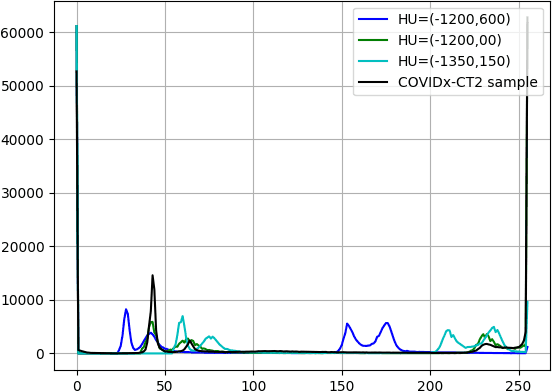
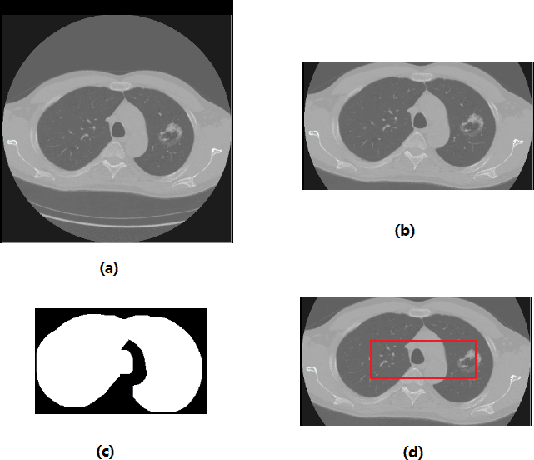
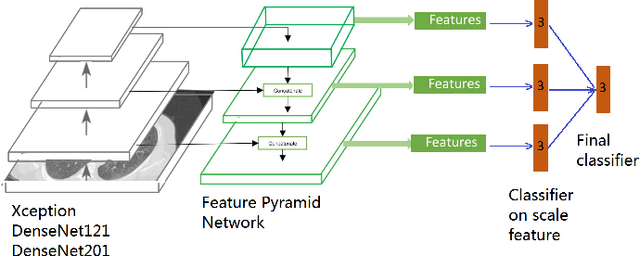
We present an automatic COVID1-19 diagnosis framework from lung CT images. The focus is on signal processing and classification on small datasets with efforts putting into exploring data preparation and augmentation to improve the generalization capability of the 2D CNN classification models. We propose a unique and effective data augmentation method using multiple Hounsfield Unit (HU) normalization windows. In addition, the original slice image is cropped to exclude background, and a filter is applied to filter out closed-lung images. For the classification network, we choose to use 2D Densenet and Xception with the feature pyramid network (FPN). To further improve the classification accuracy, an ensemble of multiple CNN models and HU windows is used. On the training/validation dataset, we achieve a patient classification accuracy of 93.39%.
Geometric Image Synthesis
Sep 12, 2018
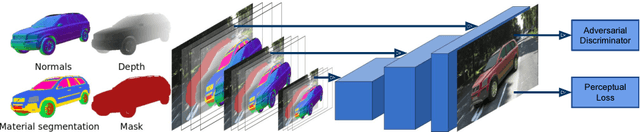

The task of generating natural images from 3D scenes has been a long standing goal in computer graphics. On the other hand, recent developments in deep neural networks allow for trainable models that can produce natural-looking images with little or no knowledge about the scene structure. While the generated images often consist of realistic looking local patterns, the overall structure of the generated images is often inconsistent. In this work we propose a trainable, geometry-aware image generation method that leverages various types of scene information, including geometry and segmentation, to create realistic looking natural images that match the desired scene structure. Our geometrically-consistent image synthesis method is a deep neural network, called Geometry to Image Synthesis (GIS) framework, which retains the advantages of a trainable method, e.g., differentiability and adaptiveness, but, at the same time, makes a step towards the generalizability, control and quality output of modern graphics rendering engines. We utilize the GIS framework to insert vehicles in outdoor driving scenes, as well as to generate novel views of objects from the Linemod dataset. We qualitatively show that our network is able to generalize beyond the training set to novel scene geometries, object shapes and segmentations. Furthermore, we quantitatively show that the GIS framework can be used to synthesize large amounts of training data which proves beneficial for training instance segmentation models.
PerspectiveNet: 3D Object Detection from a Single RGB Image via Perspective Points
Dec 16, 2019
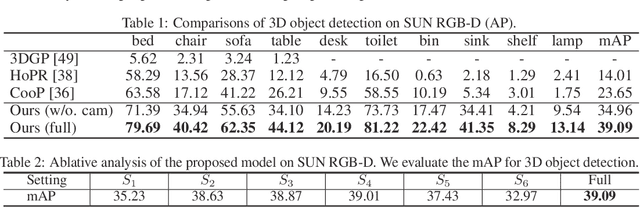
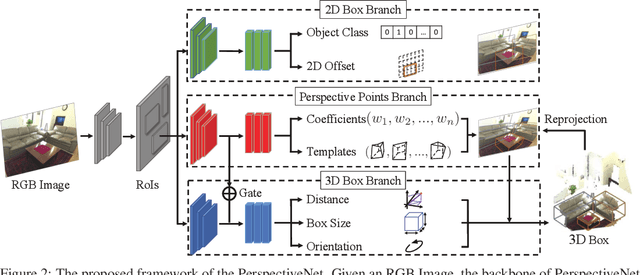
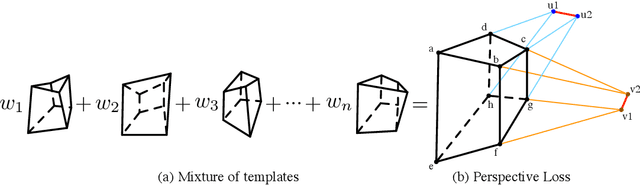
Detecting 3D objects from a single RGB image is intrinsically ambiguous, thus requiring appropriate prior knowledge and intermediate representations as constraints to reduce the uncertainties and improve the consistencies between the 2D image plane and the 3D world coordinate. To address this challenge, we propose to adopt perspective points as a new intermediate representation for 3D object detection, defined as the 2D projections of local Manhattan 3D keypoints to locate an object; these perspective points satisfy geometric constraints imposed by the perspective projection. We further devise PerspectiveNet, an end-to-end trainable model that simultaneously detects the 2D bounding box, 2D perspective points, and 3D object bounding box for each object from a single RGB image. PerspectiveNet yields three unique advantages: (i) 3D object bounding boxes are estimated based on perspective points, bridging the gap between 2D and 3D bounding boxes without the need of category-specific 3D shape priors. (ii) It predicts the perspective points by a template-based method, and a perspective loss is formulated to maintain the perspective constraints. (iii) It maintains the consistency between the 2D perspective points and 3D bounding boxes via a differentiable projective function. Experiments on SUN RGB-D dataset show that the proposed method significantly outperforms existing RGB-based approaches for 3D object detection.
Geometric Image Correspondence Verification by Dense Pixel Matching
Apr 15, 2019
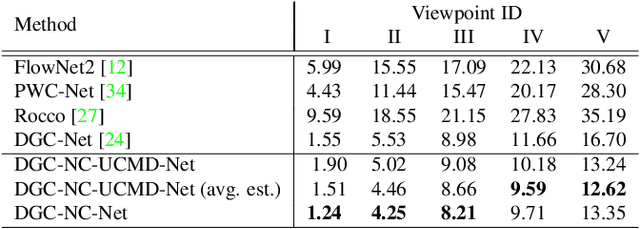
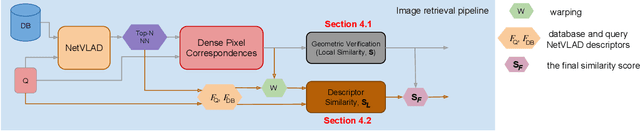
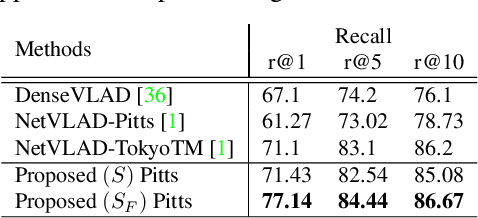
This paper addresses the problem of determining dense pixel correspondences between two images and its application to geometric correspondence verification in image retrieval. The main contribution is a geometric correspondence verification approach for re-ranking a shortlist of retrieved database images based on their dense pair-wise matching with the query image at a pixel level. We determine a set of cyclically consistent dense pixel matches between the pair of images and evaluate local similarity of matched pixels using neural network based image descriptors. Final re-ranking is based on a novel similarity function, which fuses the local similarity metric with a global similarity metric and a geometric consistency measure computed for the matched pixels. For dense matching our approach utilizes a modified version of a recently proposed dense geometric correspondence network (DGC-Net), which we also improve by optimizing the architecture. The proposed model and similarity metric compare favourably to the state-of-the-art image retrieval methods. In addition, we apply our method to the problem of long-term visual localization demonstrating promising results and generalization across datasets.
False Negative Reduction in Video Instance Segmentation using Uncertainty Estimates
Jun 28, 2021

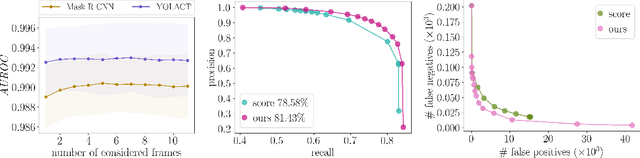
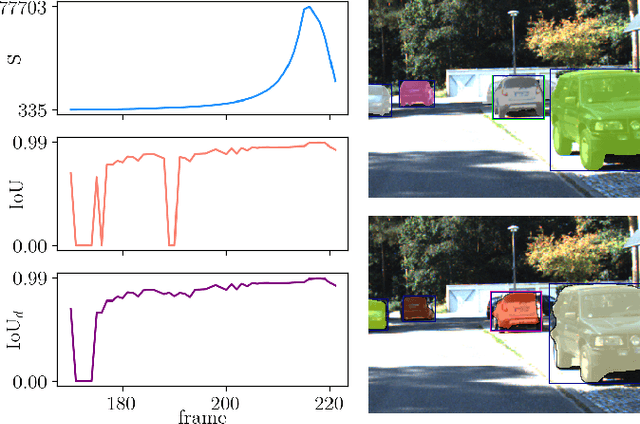
Instance segmentation of images is an important tool for automated scene understanding. Neural networks are usually trained to optimize their overall performance in terms of accuracy. Meanwhile, in applications such as automated driving, an overlooked pedestrian seems more harmful than a falsely detected one. In this work, we present a false negative detection method for image sequences based on inconsistencies in time series of tracked instances given the availability of image sequences in online applications. As the number of instances can be greatly increased by this algorithm, we apply a false positive pruning using uncertainty estimates aggregated over instances. To this end, instance-wise metrics are constructed which characterize uncertainty and geometry of a given instance or are predicated on depth estimation. The proposed method serves as a post-processing step applicable to any neural network that can also be trained on single frames only. In our tests, we obtain an improved trade-off between false negative and false positive instances by our fused detection approach in comparison to the use of an ordinary score value provided by the instance segmentation network during inference.
Integrated Construction of Multimodal Atlases with Structural Connectomes in the Space of Riemannian Metrics
Sep 20, 2021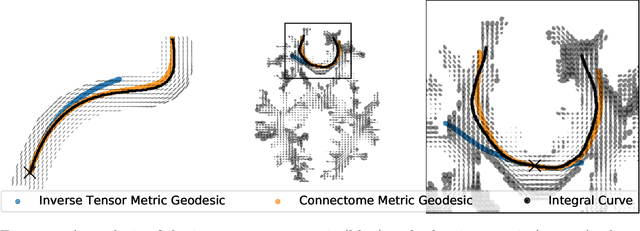

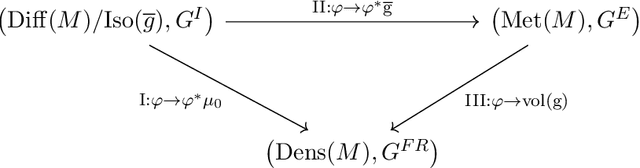
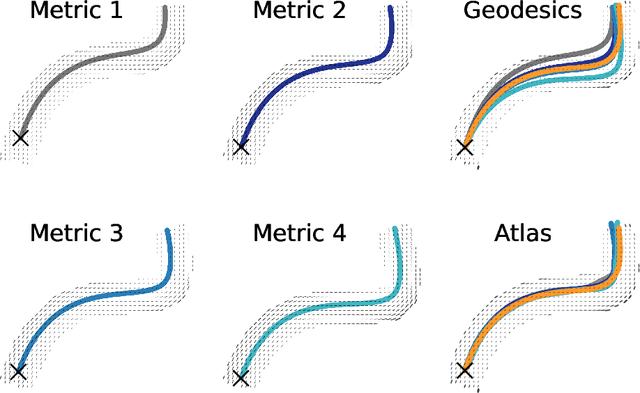
The structural network of the brain, or structural connectome, can be represented by fiber bundles generated by a variety of tractography methods. While such methods give qualitative insights into brain structure, there is controversy over whether they can provide quantitative information, especially at the population level. In order to enable population-level statistical analysis of the structural connectome, we propose representing a connectome as a Riemannian metric, which is a point on an infinite-dimensional manifold. We equip this manifold with the Ebin metric, a natural metric structure for this space, to get a Riemannian manifold along with its associated geometric properties. We then use this Riemannian framework to apply object-oriented statistical analysis to define an atlas as the Fr\'echet mean of a population of Riemannian metrics. This formulation ties into the existing framework for diffeomorphic construction of image atlases, allowing us to construct a multimodal atlas by simultaneously integrating complementary white matter structure details from DWMRI and cortical details from T1-weighted MRI. We illustrate our framework with 2D data examples of connectome registration and atlas formation. Finally, we build an example 3D multimodal atlas using T1 images and connectomes derived from diffusion tensors estimated from a subset of subjects from the Human Connectome Project.
Single pixel structured imaging through fog
Mar 23, 2021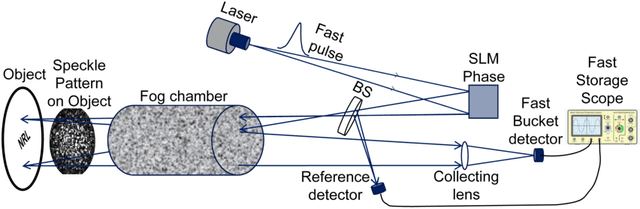
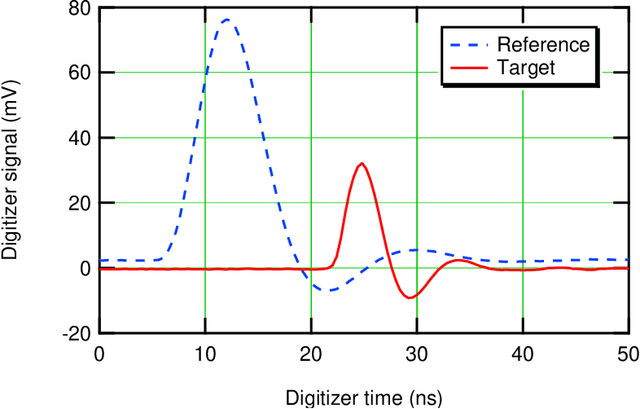

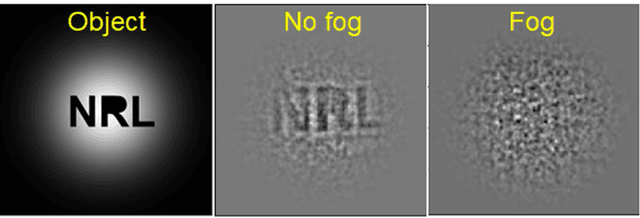
We describe the application of structured imaging with a single pixel camera to imaging through fog. We demonstrate the use of a high-pass filter on the detected bucket signals to suppress the effects of temporal variations of fog density and enable an effective reconstruction of the image. A quantitative analysis and comparison of several high-pass filters are demonstrated for the application. Both computational ghost imaging and compressive sensing techniques were used for image reconstruction and compressive sensing was observed to give a higher reconstructed image quality.
Partial success in closing the gap between human and machine vision
Jun 14, 2021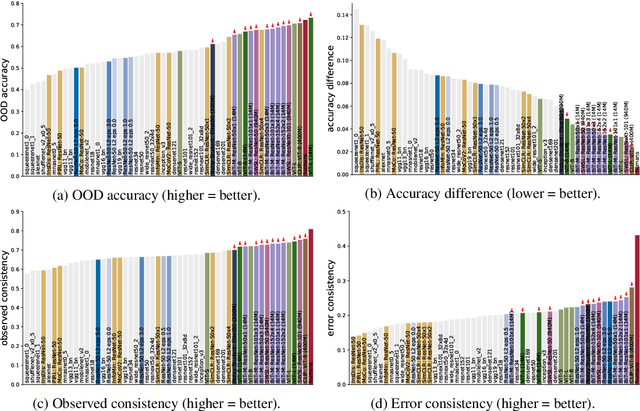

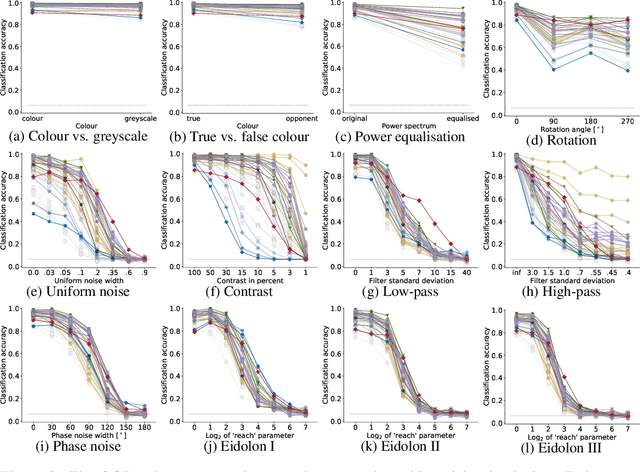
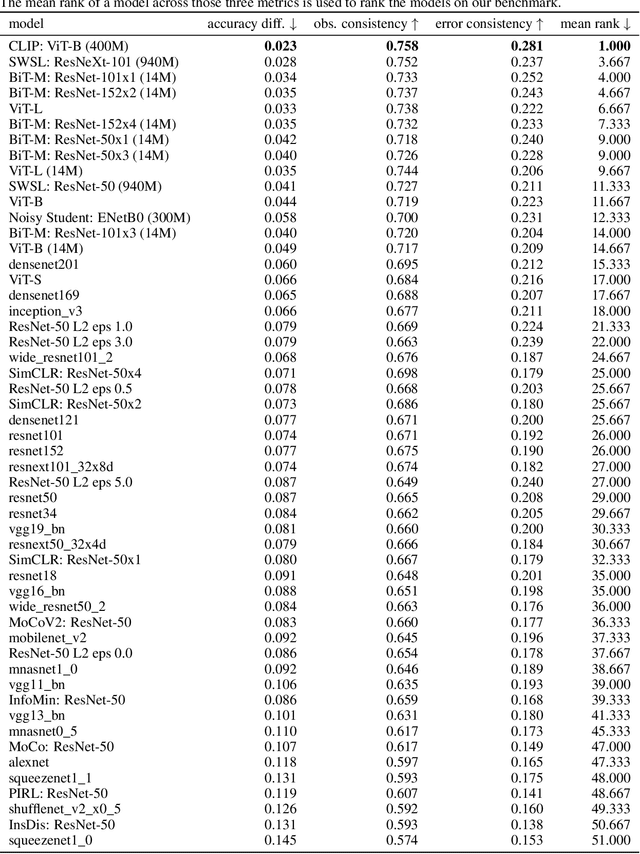
A few years ago, the first CNN surpassed human performance on ImageNet. However, it soon became clear that machines lack robustness on more challenging test cases, a major obstacle towards deploying machines "in the wild" and towards obtaining better computational models of human visual perception. Here we ask: Are we making progress in closing the gap between human and machine vision? To answer this question, we tested human observers on a broad range of out-of-distribution (OOD) datasets, adding the "missing human baseline" by recording 85,120 psychophysical trials across 90 participants. We then investigated a range of promising machine learning developments that crucially deviate from standard supervised CNNs along three axes: objective function (self-supervised, adversarially trained, CLIP language-image training), architecture (e.g. vision transformers), and dataset size (ranging from 1M to 1B). Our findings are threefold. (1.) The longstanding robustness gap between humans and CNNs is closing, with the best models now matching or exceeding human performance on most OOD datasets. (2.) There is still a substantial image-level consistency gap, meaning that humans make different errors than models. In contrast, most models systematically agree in their categorisation errors, even substantially different ones like contrastive self-supervised vs. standard supervised models. (3.) In many cases, human-to-model consistency improves when training dataset size is increased by one to three orders of magnitude. Our results give reason for cautious optimism: While there is still much room for improvement, the behavioural difference between human and machine vision is narrowing. In order to measure future progress, 17 OOD datasets with image-level human behavioural data are provided as a benchmark here: https://github.com/bethgelab/model-vs-human/