 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Long-Short Temporal Contrastive Learning of Video Transformers
Jun 17, 2021
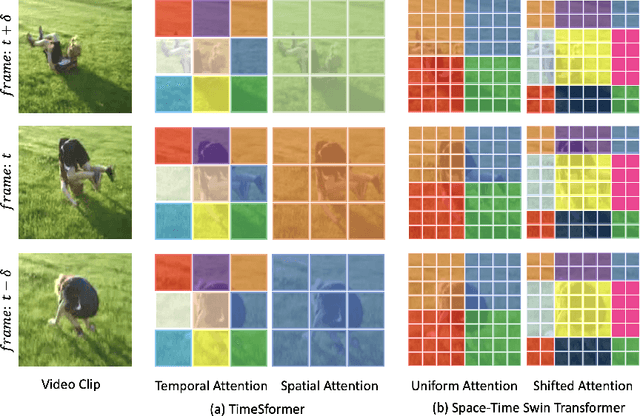

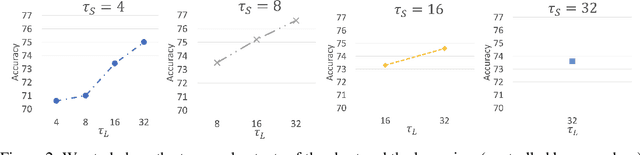
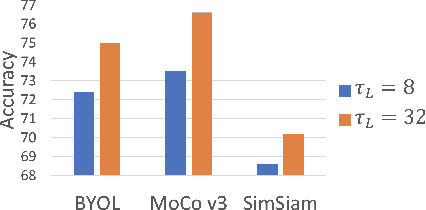
Video transformers have recently emerged as a competitive alternative to 3D CNNs for video understanding. However, due to their large number of parameters and reduced inductive biases, these models require supervised pretraining on large-scale image datasets to achieve top performance. In this paper, we empirically demonstrate that self-supervised pretraining of video transformers on video-only datasets can lead to action recognition results that are on par or better than those obtained with supervised pretraining on large-scale image datasets, even massive ones such as ImageNet-21K. Since transformer-based models are effective at capturing dependencies over extended temporal spans, we propose a simple learning procedure that forces the model to match a long-term view to a short-term view of the same video. Our approach, named Long-Short Temporal Contrastive Learning (LSTCL), enables video transformers to learn an effective clip-level representation by predicting temporal context captured from a longer temporal extent. To demonstrate the generality of our findings, we implement and validate our approach under three different self-supervised contrastive learning frameworks (MoCo v3, BYOL, SimSiam) using two distinct video-transformer architectures, including an improved variant of the Swin Transformer augmented with space-time attention. We conduct a thorough ablation study and show that LSTCL achieves competitive performance on multiple video benchmarks and represents a convincing alternative to supervised image-based pretraining.
SingleGAN: Image-to-Image Translation by a Single-Generator Network using Multiple Generative Adversarial Learning
Oct 11, 2018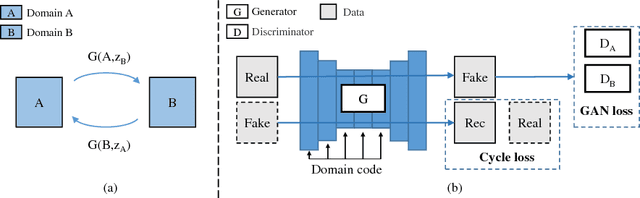
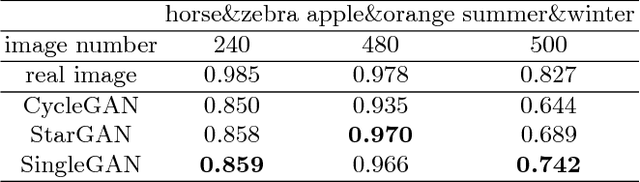
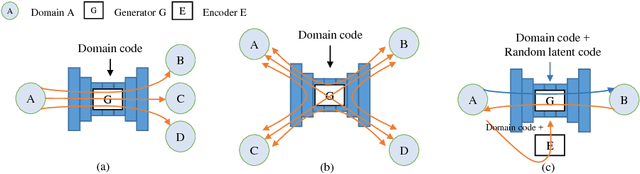
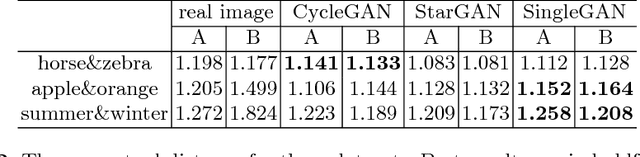
Image translation is a burgeoning field in computer vision where the goal is to learn the mapping between an input image and an output image. However, most recent methods require multiple generators for modeling different domain mappings, which are inefficient and ineffective on some multi-domain image translation tasks. In this paper, we propose a novel method, SingleGAN, to perform multi-domain image-to-image translations with a single generator. We introduce the domain code to explicitly control the different generative tasks and integrate multiple optimization goals to ensure the translation. Experimental results on several unpaired datasets show superior performance of our model in translation between two domains. Besides, we explore variants of SingleGAN for different tasks, including one-to-many domain translation, many-to-many domain translation and one-to-one domain translation with multimodality. The extended experiments show the universality and extensibility of our model.
Dense Contrastive Visual-Linguistic Pretraining
Sep 24, 2021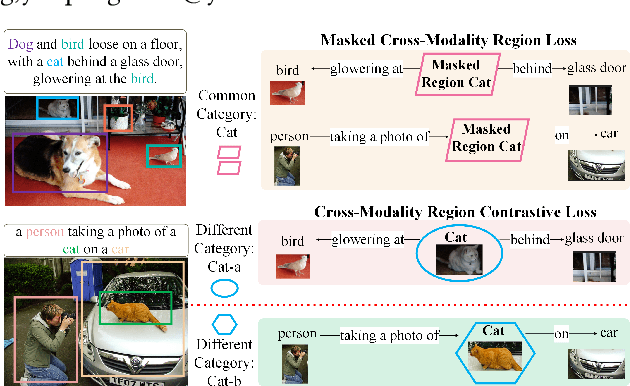

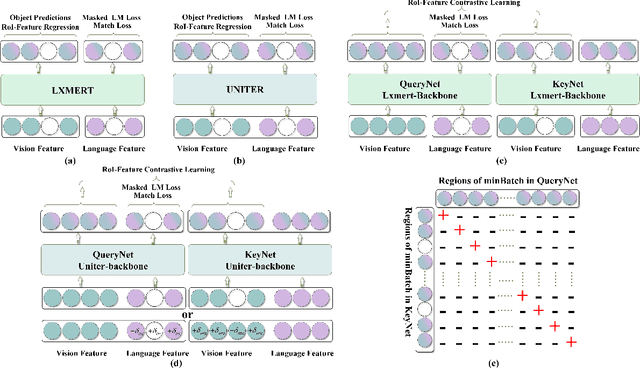
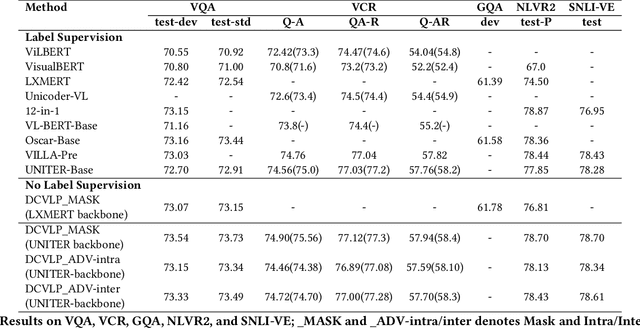
Inspired by the success of BERT, several multimodal representation learning approaches have been proposed that jointly represent image and text. These approaches achieve superior performance by capturing high-level semantic information from large-scale multimodal pretraining. In particular, LXMERT and UNITER adopt visual region feature regression and label classification as pretext tasks. However, they tend to suffer from the problems of noisy labels and sparse semantic annotations, based on the visual features having been pretrained on a crowdsourced dataset with limited and inconsistent semantic labeling. To overcome these issues, we propose unbiased Dense Contrastive Visual-Linguistic Pretraining (DCVLP), which replaces the region regression and classification with cross-modality region contrastive learning that requires no annotations. Two data augmentation strategies (Mask Perturbation and Intra-/Inter-Adversarial Perturbation) are developed to improve the quality of negative samples used in contrastive learning. Overall, DCVLP allows cross-modality dense region contrastive learning in a self-supervised setting independent of any object annotations. We compare our method against prior visual-linguistic pretraining frameworks to validate the superiority of dense contrastive learning on multimodal representation learning.
Towards Accurate Camera Geopositioning by Image Matching
Mar 13, 2019In this work, we present a camera geopositioning system based on matching a query image against a database with panoramic images. For matching, our system uses memory vectors aggregated from global image descriptors based on convolutional features to facilitate fast searching in the database. To speed up searching, a clustering algorithm is used to balance geographical positioning and computation time. We refine the obtained position from the query image using a new outlier removal algorithm. The matching of the query image is obtained with a recall@5 larger than 90% for panorama-to-panorama matching. We cluster available panoramas from geographically adjacent locations into a single compact representation and observe computational gains of approximately 50% at the cost of only a small (approximately 3%) recall loss. Finally, we present a coordinate estimation algorithm that reduces the median geopositioning error by up to 20%.
Genetic Programming and Gradient Descent: A Memetic Approach to Binary Image Classification
Sep 28, 2019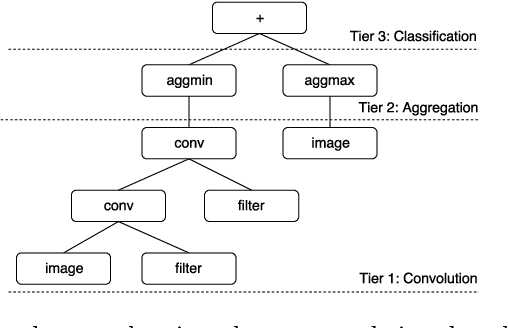
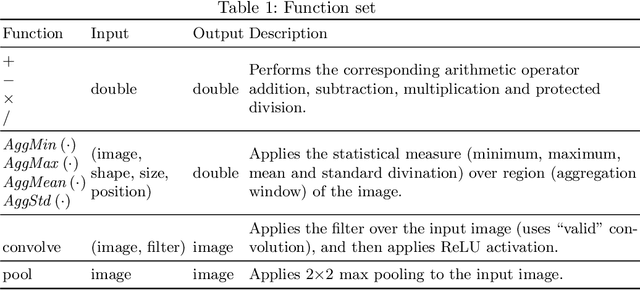
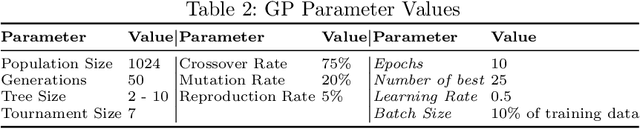
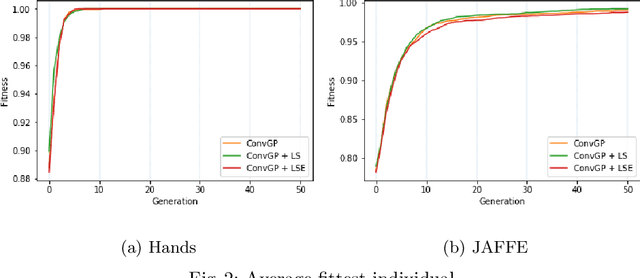
Image classification is an essential task in computer vision, which aims to categorise a set of images into different groups based on some visual criteria. Existing methods, such as convolutional neural networks, have been successfully utilised to perform image classification. However, such methods often require human intervention to design a model. Furthermore, such models are difficult to interpret and it is challenging to analyse the patterns of different classes. This paper presents a hybrid (memetic) approach combining genetic programming (GP) and Gradient-based optimisation for image classification to overcome the limitations mentioned. The performance of the proposed method is compared to a baseline version (without local search) on four binary classification image datasets to provide an insight into the usefulness of local search mechanisms for enhancing the performance of GP.
3D CNN with Localized Residual Connections for Hyperspectral Image Classification
Dec 06, 2019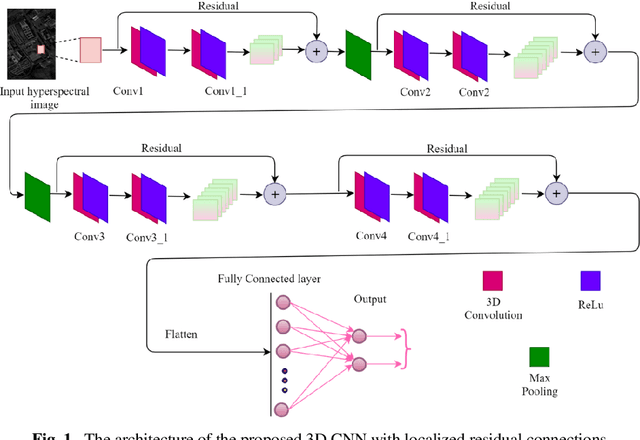
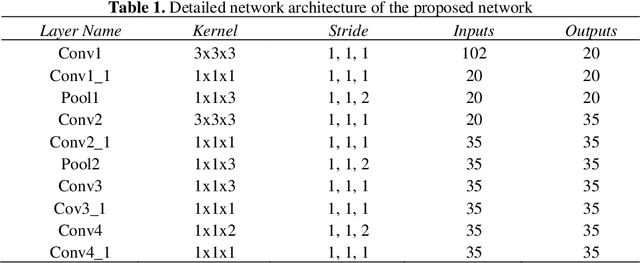
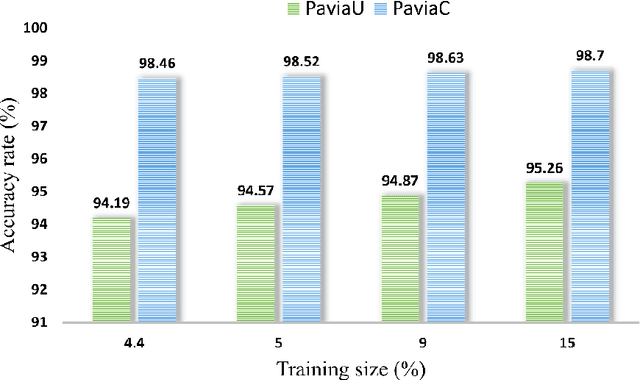

In this paper we propose a novel 3D CNN network with localized residual connections for hyperspectral image classification. Our work chalks a comparative study with the existing methods employed for abstracting deeper features and propose a model which incorporates residual features from multiple stages in the network. The proposed architecture processes individual spatiospectral feature rich cubes from hyperspectral images through 3D convolutional layers. The residual connections result in improved performance due to assimilation of both low-level and high-level features. We conduct experiments over Pavia University and Pavia Center dataset for performance analysis. We compare our method with two recent state-of-the-art methods for hyperspectral image classification method. The proposed network outperforms the existing approaches by a good margin.
Blur-Attention: A boosting mechanism for non-uniform blurred image restoration
Aug 19, 2020
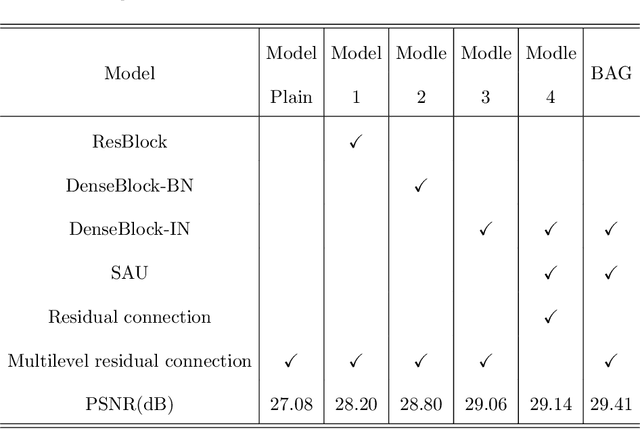
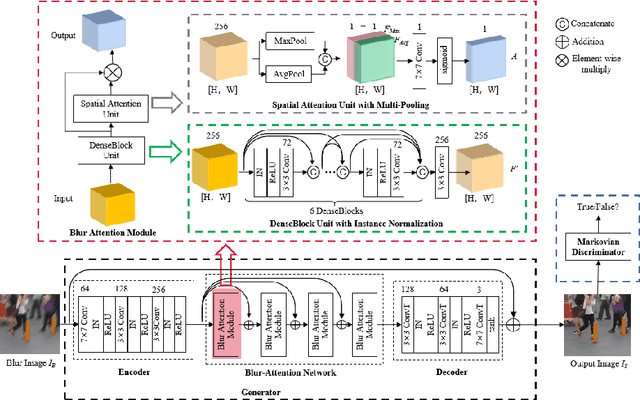
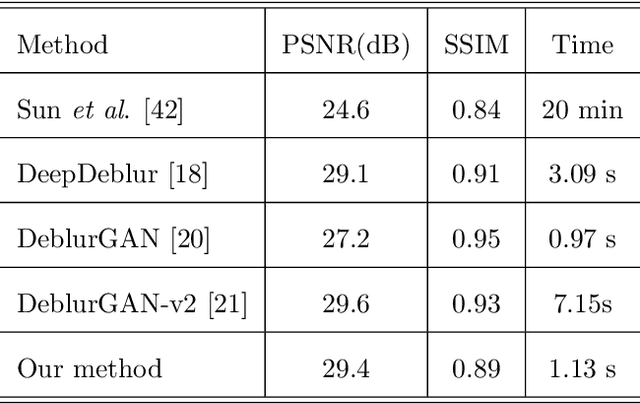
Dynamic scene deblurring is a challenging problem in computer vision. It is difficult to accurately estimate the spatially varying blur kernel by traditional methods. Data-driven-based methods usually employ kernel-free end-to-end mapping schemes, which are apt to overlook the kernel estimation. To address this issue, we propose a blur-attention module to dynamically capture the spatially varying features of non-uniform blurred images. The module consists of a DenseBlock unit and a spatial attention unit with multi-pooling feature fusion, which can effectively extract complex spatially varying blur features. We design a multi-level residual connection structure to connect multiple blur-attention modules to form a blur-attention network. By introducing the blur-attention network into a conditional generation adversarial framework, we propose an end-to-end blind motion deblurring method, namely Blur-Attention-GAN (BAG), for a single image. Our method can adaptively select the weights of the extracted features according to the spatially varying blur features, and dynamically restore the images. Experimental results show that the deblurring capability of our method achieved outstanding objective performance in terms of PSNR, SSIM, and subjective visual quality. Furthermore, by visualizing the features extracted by the blur-attention module, comprehensive discussions are provided on its effectiveness.
Improving the Harmony of the Composite Image by Spatial-Separated Attention Module
Jul 15, 2019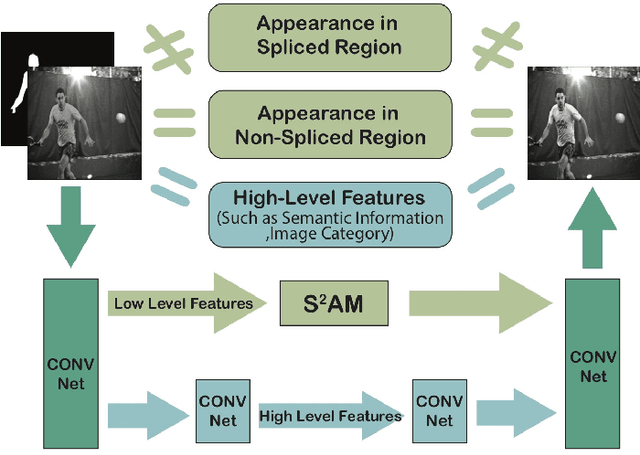
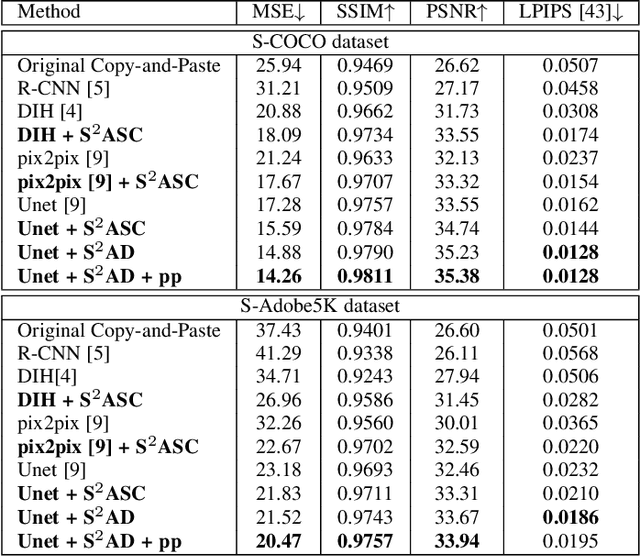
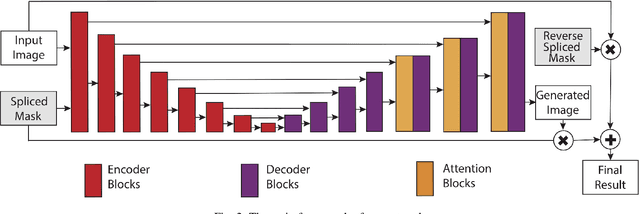
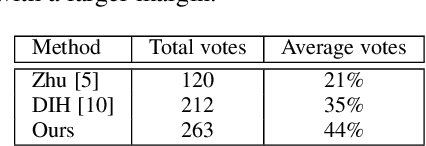
Image composition is one of the most important applications in image processing. However, the inharmonious appearance between the spliced region and background degrade the quality of the image. Thus, we address the problem of Image Harmonization: Given a spliced image and the mask of the spliced region, we try to harmonize the "style'' of the pasted region with the background (non-spliced region). Previous approaches have been focusing on learning directly by the neural network. In this work, we start from an empirical observation: the differences can only be found in the spliced region between the spliced image and the harmonized result while they share the same semantic information and the appearance in the non-spliced region. Thus, in order to learn the feature map in the masked region and the others individually, we propose a novel attention module named Spatial-Separated Attention Module (S2AM). Furthermore, we design a novel image harmonization framework by inserting the S2AM in the coarser low-level features of the Unet structure in two different ways. Besides image harmonization, we make a big step for harmonizing the composite image without the specific mask under previous observation. The experiments show that the proposed S2AM performs better than other state-of-the-art attention modules in our task. Moreover, we demonstrate the advantages of our model against other state-of-the-art image harmonization methods via criteria from multiple points of view. Code is available at https://github.com/vinthony/s2am
Generative Image Translation for Data Augmentation in Colorectal Histopathology Images
Oct 13, 2019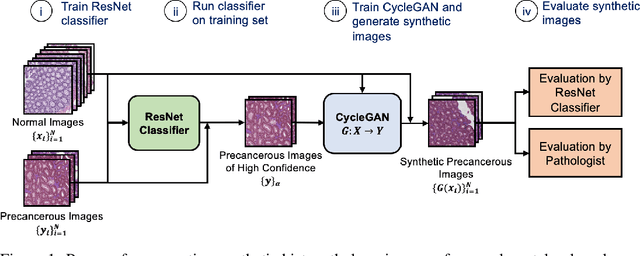
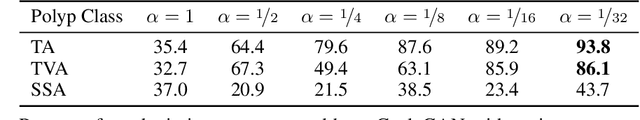
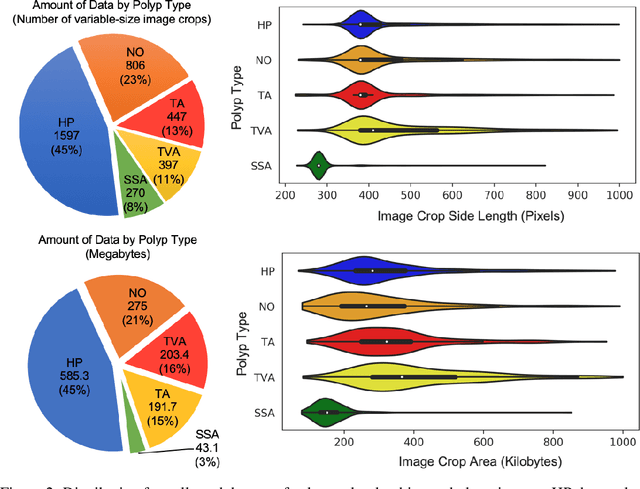
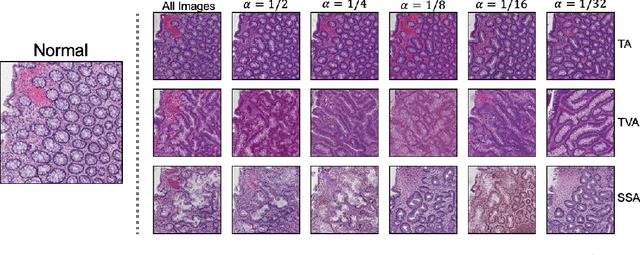
We present an image translation approach to generate augmented data for mitigating data imbalances in a dataset of histopathology images of colorectal polyps, adenomatous tumors that can lead to colorectal cancer if left untreated. By applying cycle-consistent generative adversarial networks (CycleGANs) to a source domain of normal colonic mucosa images, we generate synthetic colorectal polyp images that belong to diagnostically less common polyp classes. Generated images maintain the general structure of their source image but exhibit adenomatous features that can be enhanced with our proposed filtration module, called Path-Rank-Filter. We evaluate the quality of generated images through Turing tests with four gastrointestinal pathologists, finding that at least two of the four pathologists could not identify generated images at a statistically significant level. Finally, we demonstrate that using CycleGAN-generated images to augment training data improves the AUC of a convolutional neural network for detecting sessile serrated adenomas by over 10%, suggesting that our approach might warrant further research for other histopathology image classification tasks.
NestFuse: An Infrared and Visible Image Fusion Architecture based on Nest Connection and Spatial/Channel Attention Models
Jul 01, 2020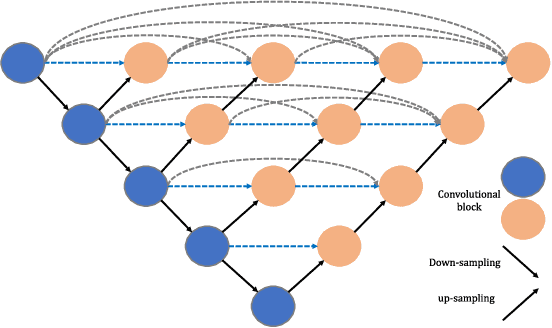



In this paper we propose a novel method for infrared and visible image fusion where we develop nest connection-based network and spatial/channel attention models. The nest connection-based network can preserve significant amounts of information from input data in a multi-scale perspective. The approach comprises three key elements: encoder, fusion strategy and decoder respectively. In our proposed fusion strategy, spatial attention models and channel attention models are developed that describe the importance of each spatial position and of each channel with deep features. Firstly, the source images are fed into the encoder to extract multi-scale deep features. The novel fusion strategy is then developed to fuse these features for each scale. Finally, the fused image is reconstructed by the nest connection-based decoder. Experiments are performed on publicly available datasets. These exhibit that our proposed approach has better fusion performance than other state-of-the-art methods. This claim is justified through both subjective and objective evaluation. The code of our fusion method is available at https://github.com/hli1221/imagefusion-nestfuse