 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Aesthetic Photo Collage with Deep Reinforcement Learning
Oct 19, 2021
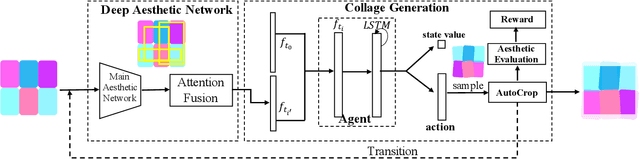



Photo collage aims to automatically arrange multiple photos on a given canvas with high aesthetic quality. Existing methods are based mainly on handcrafted feature optimization, which cannot adequately capture high-level human aesthetic senses. Deep learning provides a promising way, but owing to the complexity of collage and lack of training data, a solution has yet to be found. In this paper, we propose a novel pipeline for automatic generation of aspect ratio specified collage and the reinforcement learning technique is introduced in collage for the first time. Inspired by manual collages, we model the collage generation as sequential decision process to adjust spatial positions, orientation angles, placement order and the global layout. To instruct the agent to improve both the overall layout and local details, the reward function is specially designed for collage, considering subjective and objective factors. To overcome the lack of training data, we pretrain our deep aesthetic network on a large scale image aesthetic dataset (CPC) for general aesthetic feature extraction and propose an attention fusion module for structural collage feature representation. We test our model against competing methods on two movie datasets and our results outperform others in aesthetic quality evaluation. Further user study is also conducted to demonstrate the effectiveness.
Dynamic Inference with Neural Interpreters
Oct 12, 2021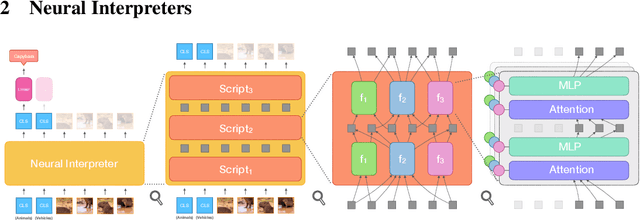
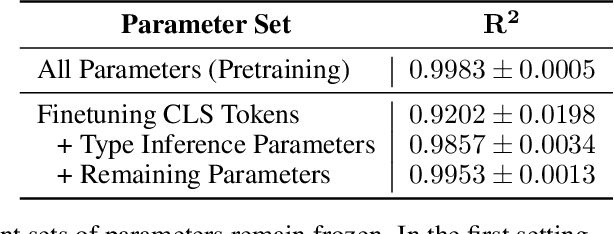
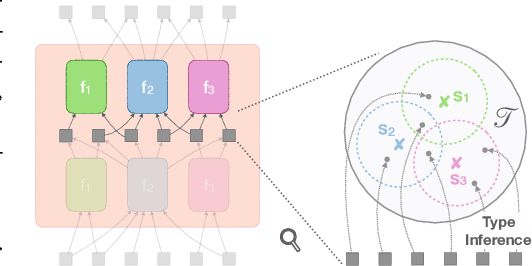
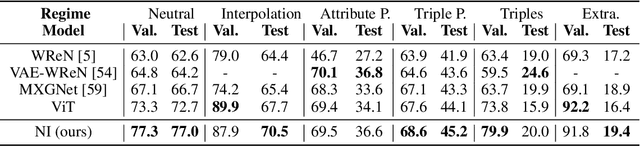
Modern neural network architectures can leverage large amounts of data to generalize well within the training distribution. However, they are less capable of systematic generalization to data drawn from unseen but related distributions, a feat that is hypothesized to require compositional reasoning and reuse of knowledge. In this work, we present Neural Interpreters, an architecture that factorizes inference in a self-attention network as a system of modules, which we call \emph{functions}. Inputs to the model are routed through a sequence of functions in a way that is end-to-end learned. The proposed architecture can flexibly compose computation along width and depth, and lends itself well to capacity extension after training. To demonstrate the versatility of Neural Interpreters, we evaluate it in two distinct settings: image classification and visual abstract reasoning on Raven Progressive Matrices. In the former, we show that Neural Interpreters perform on par with the vision transformer using fewer parameters, while being transferrable to a new task in a sample efficient manner. In the latter, we find that Neural Interpreters are competitive with respect to the state-of-the-art in terms of systematic generalization
Data-Efficient Language-Supervised Zero-Shot Learning with Self-Distillation
Apr 18, 2021
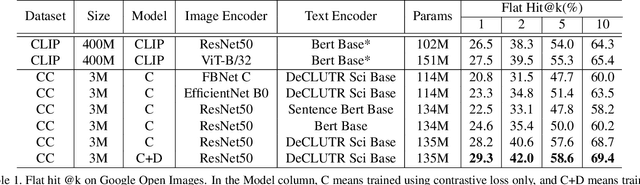
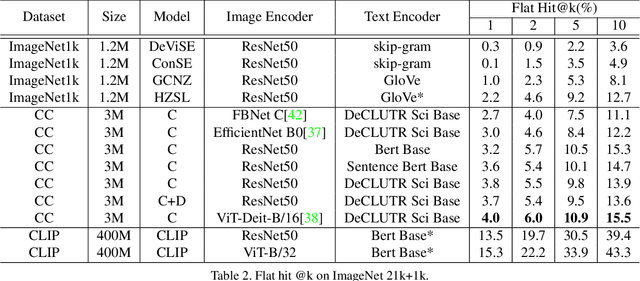
Traditional computer vision models are trained to predict a fixed set of predefined categories. Recently, natural language has been shown to be a broader and richer source of supervision that provides finer descriptions to visual concepts than supervised "gold" labels. Previous works, such as CLIP, use a simple pretraining task of predicting the pairings between images and text captions. CLIP, however, is data hungry and requires more than 400M image text pairs for training. We propose a data-efficient contrastive distillation method that uses soft labels to learn from noisy image-text pairs. Our model transfers knowledge from pretrained image and sentence encoders and achieves strong performance with only 3M image text pairs, 133x smaller than CLIP. Our method exceeds the previous SoTA of general zero-shot learning on ImageNet 21k+1k by 73% relatively with a ResNet50 image encoder and DeCLUTR text encoder. We also beat CLIP by 10.5% relatively on zero-shot evaluation on Google Open Images (19,958 classes).
Identity and Attribute Preserving Thumbnail Upscaling
May 30, 2021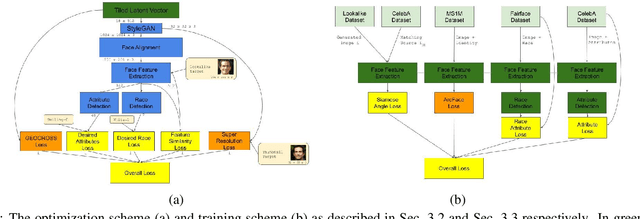
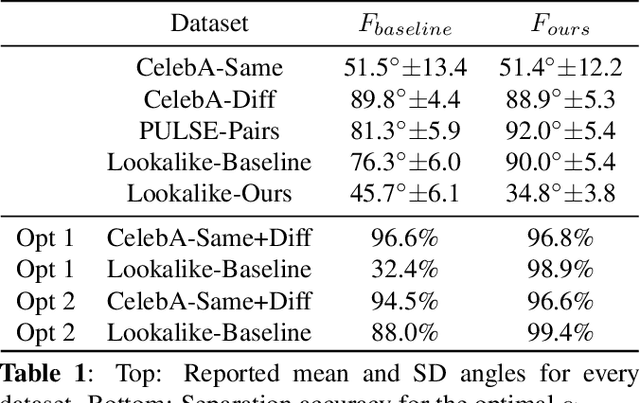


We consider the task of upscaling a low resolution thumbnail image of a person, to a higher resolution image, which preserves the person's identity and other attributes. Since the thumbnail image is of low resolution, many higher resolution versions exist. Previous approaches produce solutions where the person's identity is not preserved, or biased solutions, such as predominantly Caucasian faces. We address the existing ambiguity by first augmenting the feature extractor to better capture facial identity, facial attributes (such as smiling or not) and race, and second, use this feature extractor to generate high-resolution images which are identity preserving as well as conditioned on race and facial attributes. Our results indicate an improvement in face similarity recognition and lookalike generation as well as in the ability to generate higher resolution images which preserve an input thumbnail identity and whose race and attributes are maintained.
Detection of Illicit Drug Trafficking Events on Instagram: A Deep Multimodal Multilabel Learning Approach
Aug 19, 2021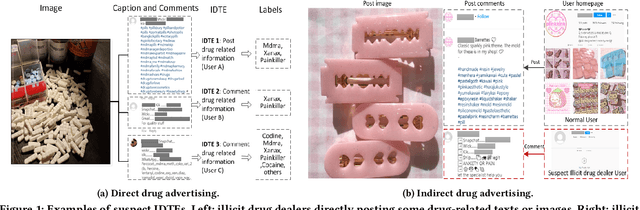
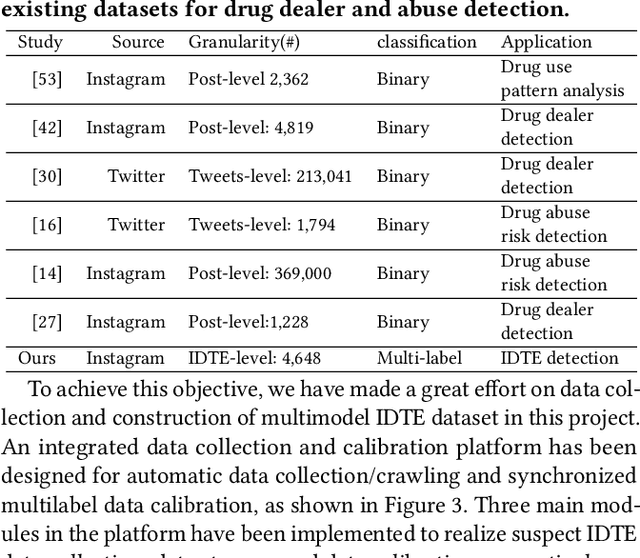
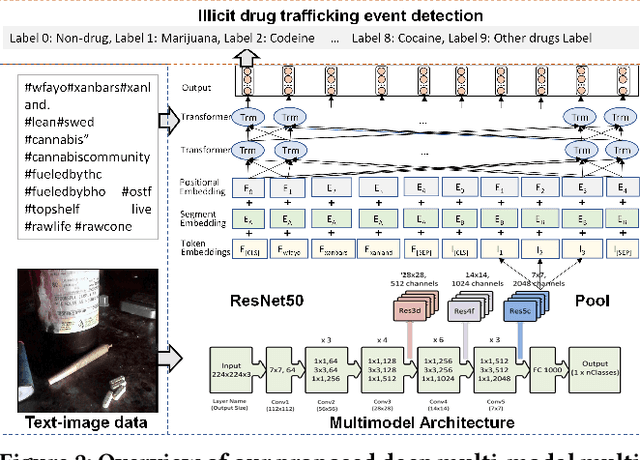
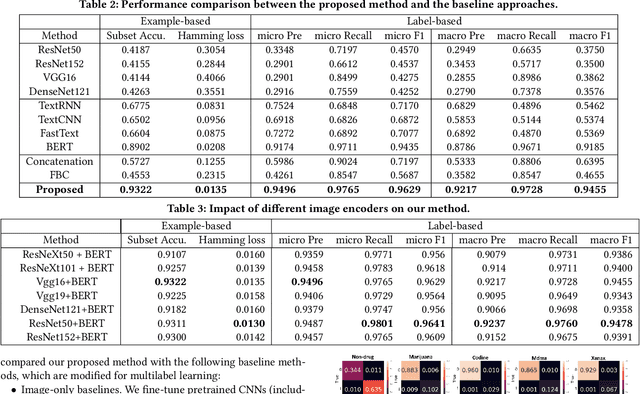
Social media such as Instagram and Twitter have become important platforms for marketing and selling illicit drugs. Detection of online illicit drug trafficking has become critical to combat the online trade of illicit drugs. However, the legal status often varies spatially and temporally; even for the same drug, federal and state legislation can have different regulations about its legality. Meanwhile, more drug trafficking events are disguised as a novel form of advertising commenting leading to information heterogeneity. Accordingly, accurate detection of illicit drug trafficking events (IDTEs) from social media has become even more challenging. In this work, we conduct the first systematic study on fine-grained detection of IDTEs on Instagram. We propose to take a deep multimodal multilabel learning (DMML) approach to detect IDTEs and demonstrate its effectiveness on a newly constructed dataset called multimodal IDTE(MM-IDTE). Specifically, our model takes text and image data as the input and combines multimodal information to predict multiple labels of illicit drugs. Inspired by the success of BERT, we have developed a self-supervised multimodal bidirectional transformer by jointly fine-tuning pretrained text and image encoders. We have constructed a large-scale dataset MM-IDTE with manually annotated multiple drug labels to support fine-grained detection of illicit drugs. Extensive experimental results on the MM-IDTE dataset show that the proposed DMML methodology can accurately detect IDTEs even in the presence of special characters and style changes attempting to evade detection.
Mask-aware IoU for Anchor Assignment in Real-time Instance Segmentation
Oct 19, 2021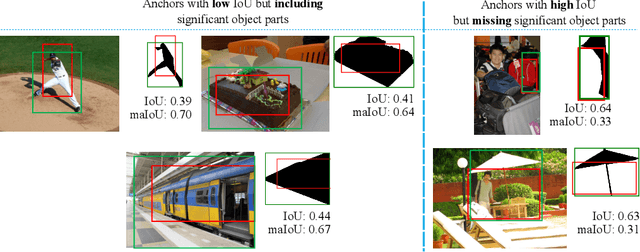
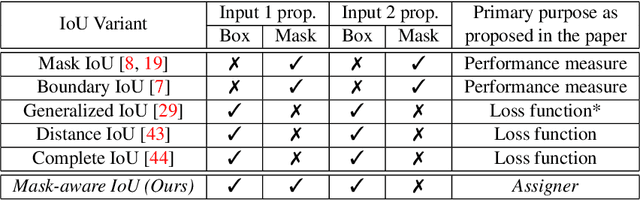
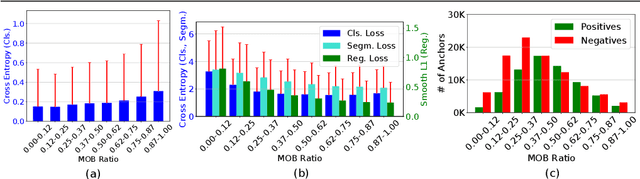
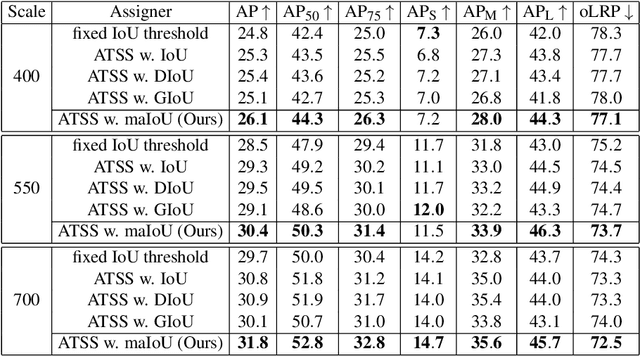
This paper presents Mask-aware Intersection-over-Union (maIoU) for assigning anchor boxes as positives and negatives during training of instance segmentation methods. Unlike conventional IoU or its variants, which only considers the proximity of two boxes; maIoU consistently measures the proximity of an anchor box with not only a ground truth box but also its associated ground truth mask. Thus, additionally considering the mask, which, in fact, represents the shape of the object, maIoU enables a more accurate supervision during training. We present the effectiveness of maIoU on a state-of-the-art (SOTA) assigner, ATSS, by replacing IoU operation by our maIoU and training YOLACT, a SOTA real-time instance segmentation method. Using ATSS with maIoU consistently outperforms (i) ATSS with IoU by $\sim 1$ mask AP, (ii) baseline YOLACT with fixed IoU threshold assigner by $\sim 2$ mask AP over different image sizes and (iii) decreases the inference time by $25 \%$ owing to using less anchors. Then, exploiting this efficiency, we devise maYOLACT, a faster and $+6$ AP more accurate detector than YOLACT. Our best model achieves $37.7$ mask AP at $25$ fps on COCO test-dev establishing a new state-of-the-art for real-time instance segmentation. Code is available at https://github.com/kemaloksuz/Mask-aware-IoU
Measurement of Hybrid Rocket Solid Fuel Regression Rate for a Slab Burner using Deep Learning
Aug 25, 2021
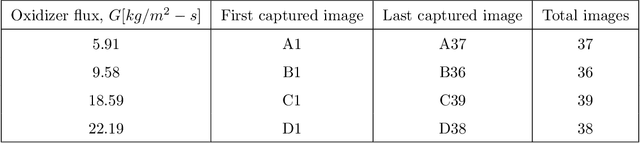

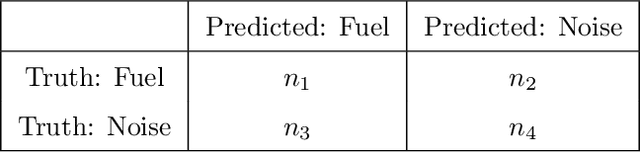
This study presents an imaging-based deep learning tool to measure the fuel regression rate in a 2D slab burner experiment for hybrid rocket fuels. The slab burner experiment is designed to verify mechanistic models of reacting boundary layer combustion in hybrid rockets by the measurement of fuel regression rates. A DSLR camera with a high intensity flash is used to capture images throughout the burn and the images are then used to find the fuel boundary to calculate the regression rate. A U-net convolutional neural network architecture is explored to segment the fuel from the experimental images. A Monte-Carlo Dropout process is used to quantify the regression rate uncertainty produced from the network. The U-net computed regression rates are compared with values from other techniques from literature and show error less than 10%. An oxidizer flux dependency study is performed and shows the U-net predictions of regression rates are accurate and independent of the oxidizer flux, when the images in the training set are not over-saturated. Training with monochrome images is explored and is not successful at predicting the fuel regression rate from images with high noise. The network is superior at filtering out noise introduced by soot, pitting, and wax deposition on the chamber glass as well as the flame when compared to traditional image processing techniques, such as threshold binary conversion and spatial filtering. U-net consistently provides low error image segmentations to allow accurate computation of the regression rate of the fuel.
A self-adapting super-resolution structures framework for automatic design of GAN
Jun 10, 2021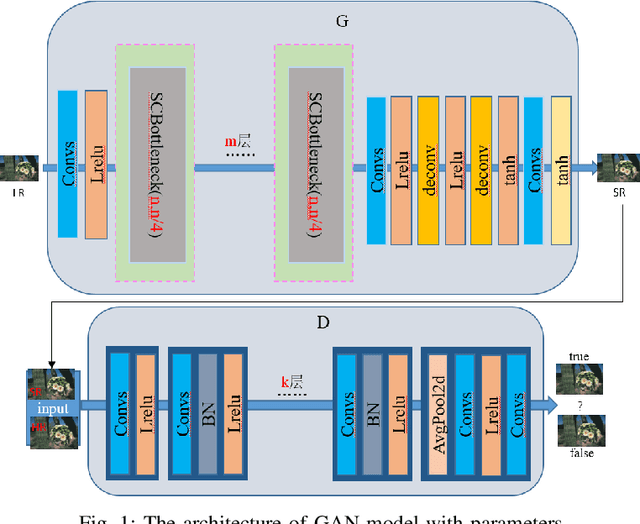
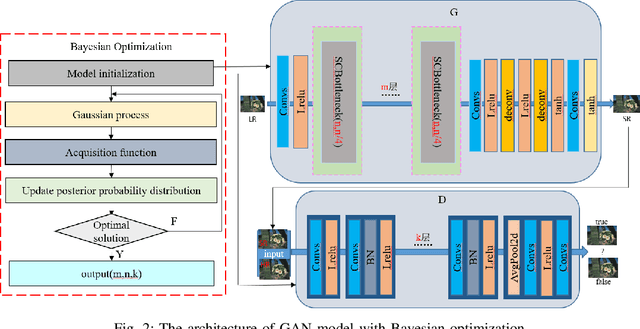
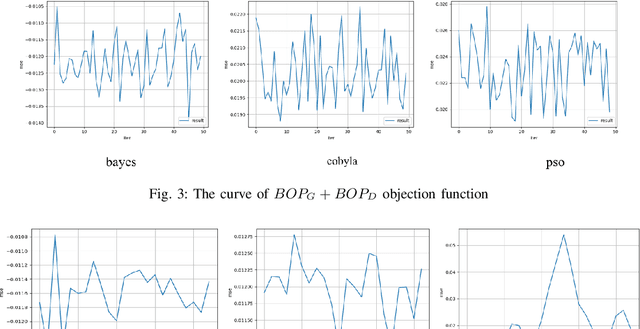
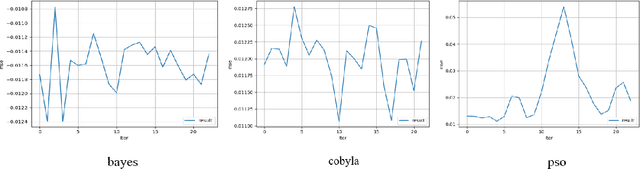
With the development of deep learning, the single super-resolution image reconstruction network models are becoming more and more complex. Small changes in hyperparameters of the models have a greater impact on model performance. In the existing works, experts have gradually explored a set of optimal model parameters based on empirical values or performing brute-force search. In this paper, we introduce a new super-resolution image reconstruction generative adversarial network framework, and a Bayesian optimization method used to optimizing the hyperparameters of the generator and discriminator. The generator is made by self-calibrated convolution, and discriminator is made by convolution lays. We have defined the hyperparameters such as the number of network layers and the number of neurons. Our method adopts Bayesian optimization as a optimization policy of GAN in our model. Not only can find the optimal hyperparameter solution automatically, but also can construct a super-resolution image reconstruction network, reducing the manual workload. Experiments show that Bayesian optimization can search the optimal solution earlier than the other two optimization algorithms.
Comparing object recognition in humans and deep convolutional neural networks -- An eye tracking study
Jul 30, 2021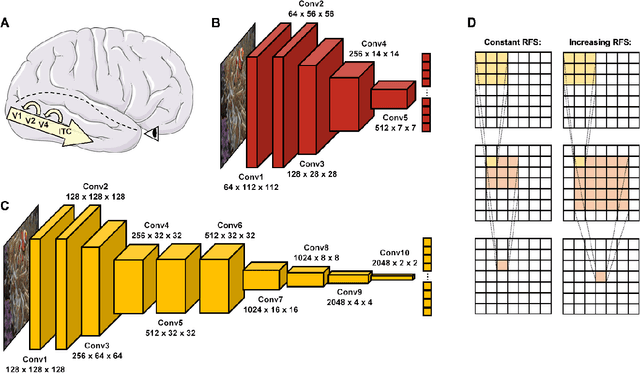
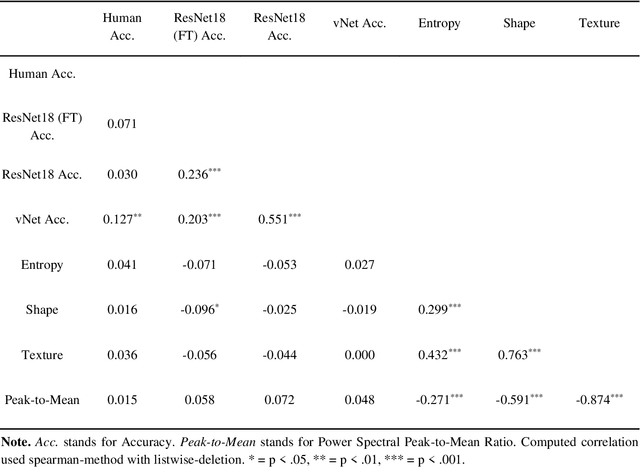
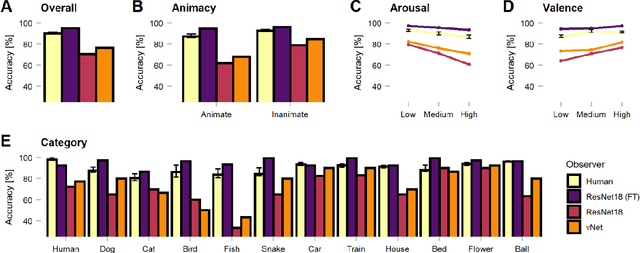
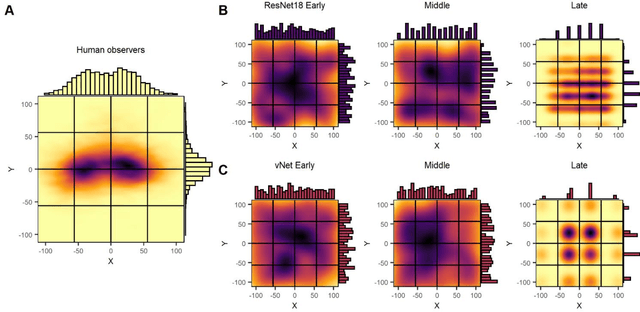
Deep convolutional neural networks (DCNNs) and the ventral visual pathway share vast architectural and functional similarities in visual challenges such as object recognition. Recent insights have demonstrated that both hierarchical cascades can be compared in terms of both exerted behavior and underlying activation. However, these approaches ignore key differences in spatial priorities of information processing. In this proof-of-concept study, we demonstrate a comparison of human observers (N = 45) and three feedforward DCNNs through eye tracking and saliency maps. The results reveal fundamentally different resolutions in both visualization methods that need to be considered for an insightful comparison. Moreover, we provide evidence that a DCNN with biologically plausible receptive field sizes called vNet reveals higher agreement with human viewing behavior as contrasted with a standard ResNet architecture. We find that image-specific factors such as category, animacy, arousal, and valence have a direct link to the agreement of spatial object recognition priorities in humans and DCNNs, while other measures such as difficulty and general image properties do not. With this approach, we try to open up new perspectives at the intersection of biological and computer vision research.
STRESS: Super-Resolution for Dynamic Fetal MRI using Self-Supervised Learning
Jun 30, 2021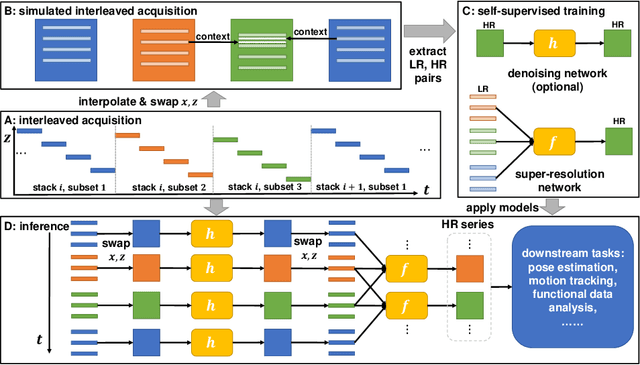
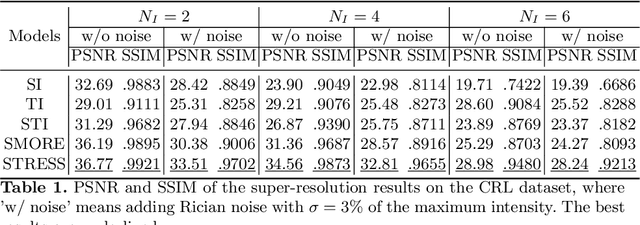
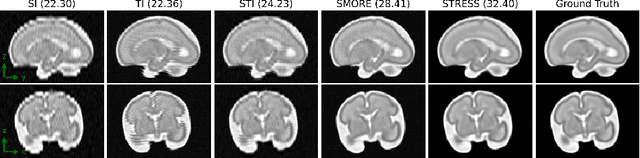

Fetal motion is unpredictable and rapid on the scale of conventional MR scan times. Therefore, dynamic fetal MRI, which aims at capturing fetal motion and dynamics of fetal function, is limited to fast imaging techniques with compromises in image quality and resolution. Super-resolution for dynamic fetal MRI is still a challenge, especially when multi-oriented stacks of image slices for oversampling are not available and high temporal resolution for recording the dynamics of the fetus or placenta is desired. Further, fetal motion makes it difficult to acquire high-resolution images for supervised learning methods. To address this problem, in this work, we propose STRESS (Spatio-Temporal Resolution Enhancement with Simulated Scans), a self-supervised super-resolution framework for dynamic fetal MRI with interleaved slice acquisitions. Our proposed method simulates an interleaved slice acquisition along the high-resolution axis on the originally acquired data to generate pairs of low- and high-resolution images. Then, it trains a super-resolution network by exploiting both spatial and temporal correlations in the MR time series, which is used to enhance the resolution of the original data. Evaluations on both simulated and in utero data show that our proposed method outperforms other self-supervised super-resolution methods and improves image quality, which is beneficial to other downstream tasks and evaluations.