 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High Fidelity Deep Learning-based MRI Reconstruction with Instance-wise Discriminative Feature Matching Loss
Aug 27, 2021
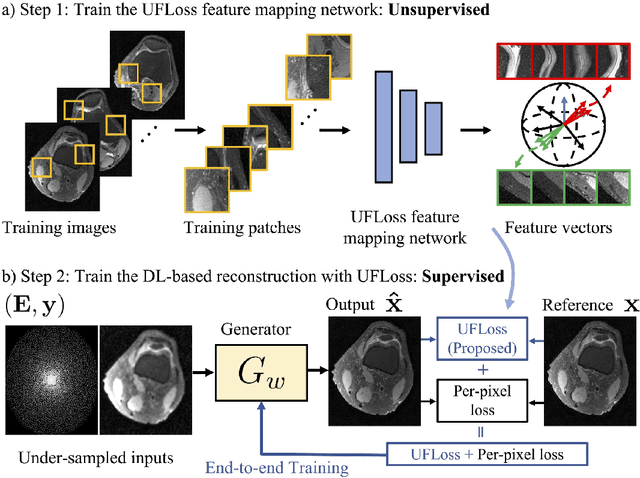
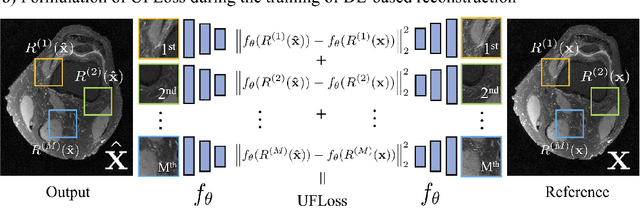
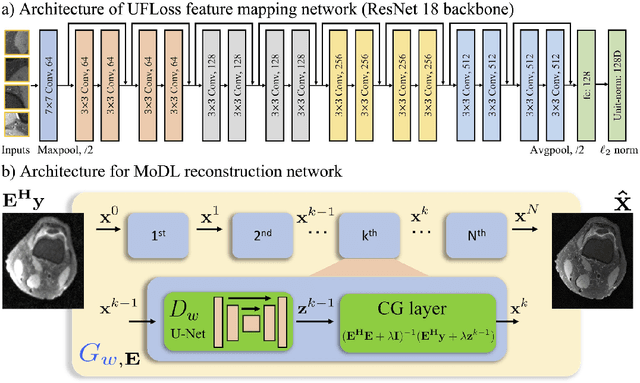
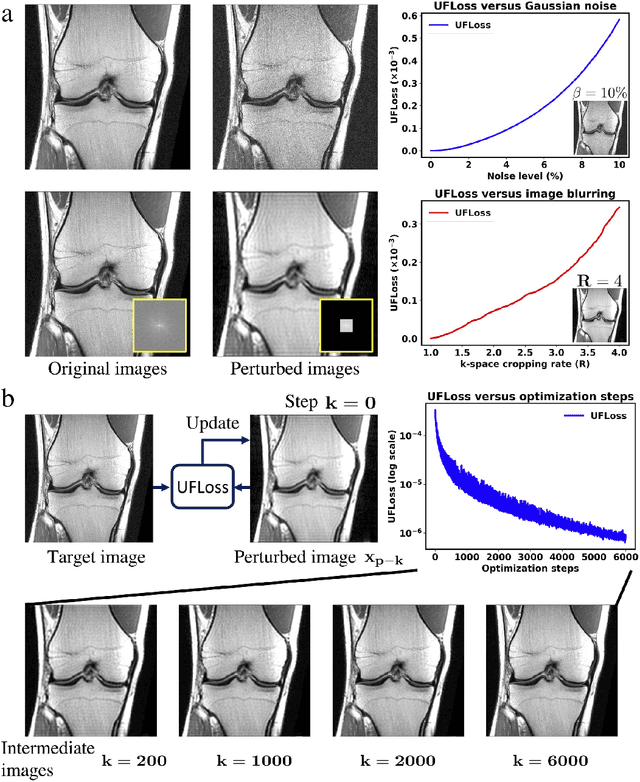
Purpose: To improve reconstruction fidelity of fine structures and textures in deep learning (DL) based reconstructions. Methods: A novel patch-based Unsupervised Feature Loss (UFLoss) is proposed and incorporated into the training of DL-based reconstruction frameworks in order to preserve perceptual similarity and high-order statistics. The UFLoss provides instance-level discrimination by mapping similar instances to similar low-dimensional feature vectors and is trained without any human annotation. By adding an additional loss function on the low-dimensional feature space during training, the reconstruction frameworks from under-sampled or corrupted data can reproduce more realistic images that are closer to the original with finer textures, sharper edges, and improved overall image quality. The performance of the proposed UFLoss is demonstrated on unrolled networks for accelerated 2D and 3D knee MRI reconstruction with retrospective under-sampling. Quantitative metrics including NRMSE, SSIM, and our proposed UFLoss were used to evaluate the performance of the proposed method and compare it with others. Results: In-vivo experiments indicate that adding the UFLoss encourages sharper edges and more faithful contrasts compared to traditional and learning-based methods with pure l2 loss. More detailed textures can be seen in both 2D and 3D knee MR images. Quantitative results indicate that reconstruction with UFLoss can provide comparable NRMSE and a higher SSIM while achieving a much lower UFLoss value. Conclusion: We present UFLoss, a patch-based unsupervised learned feature loss, which allows the training of DL-based reconstruction to obtain more detailed texture, finer features, and sharper edges with higher overall image quality under DL-based reconstruction frameworks.
Reliable and Trustworthy Machine Learning for Health Using Dataset Shift Detection
Oct 26, 2021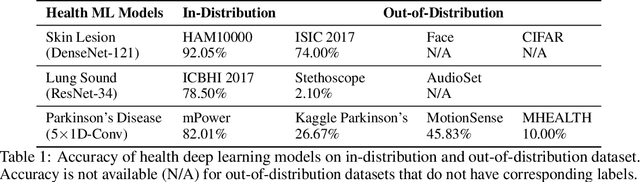
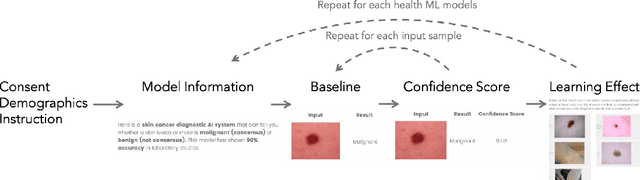
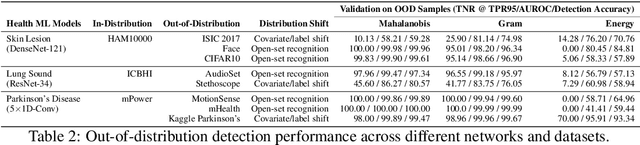

Unpredictable ML model behavior on unseen data, especially in the health domain, raises serious concerns about its safety as repercussions for mistakes can be fatal. In this paper, we explore the feasibility of using state-of-the-art out-of-distribution detectors for reliable and trustworthy diagnostic predictions. We select publicly available deep learning models relating to various health conditions (e.g., skin cancer, lung sound, and Parkinson's disease) using various input data types (e.g., image, audio, and motion data). We demonstrate that these models show unreasonable predictions on out-of-distribution datasets. We show that Mahalanobis distance- and Gram matrices-based out-of-distribution detection methods are able to detect out-of-distribution data with high accuracy for the health models that operate on different modalities. We then translate the out-of-distribution score into a human interpretable CONFIDENCE SCORE to investigate its effect on the users' interaction with health ML applications. Our user study shows that the \textsc{confidence score} helped the participants only trust the results with a high score to make a medical decision and disregard results with a low score. Through this work, we demonstrate that dataset shift is a critical piece of information for high-stake ML applications, such as medical diagnosis and healthcare, to provide reliable and trustworthy predictions to the users.
Generating Thermal Image Data Samples using 3D Facial Modelling Techniques and Deep Learning Methodologies
May 07, 2020



Methods for generating synthetic data have become of increasing importance to build large datasets required for Convolution Neural Networks (CNN) based deep learning techniques for a wide range of computer vision applications. In this work, we extend existing methodologies to show how 2D thermal facial data can be mapped to provide 3D facial models. For the proposed research work we have used tufts datasets for generating 3D varying face poses by using a single frontal face pose. The system works by refining the existing image quality by performing fusion based image preprocessing operations. The refined outputs have better contrast adjustments, decreased noise level and higher exposedness of the dark regions. It makes the facial landmarks and temperature patterns on the human face more discernible and visible when compared to original raw data. Different image quality metrics are used to compare the refined version of images with original images. In the next phase of the proposed study, the refined version of images is used to create 3D facial geometry structures by using Convolution Neural Networks (CNN). The generated outputs are then imported in blender software to finally extract the 3D thermal facial outputs of both males and females. The same technique is also used on our thermal face data acquired using prototype thermal camera (developed under Heliaus EU project) in an indoor lab environment which is then used for generating synthetic 3D face data along with varying yaw face angles and lastly facial depth map is generated.
Improving Calibration and Out-of-Distribution Detection in Medical Image Segmentation with Convolutional Neural Networks
Apr 12, 2020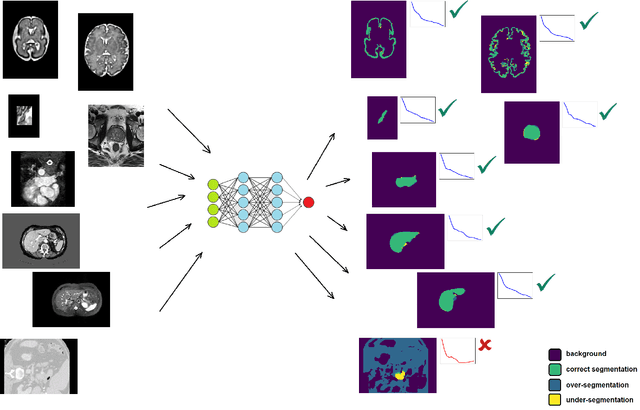
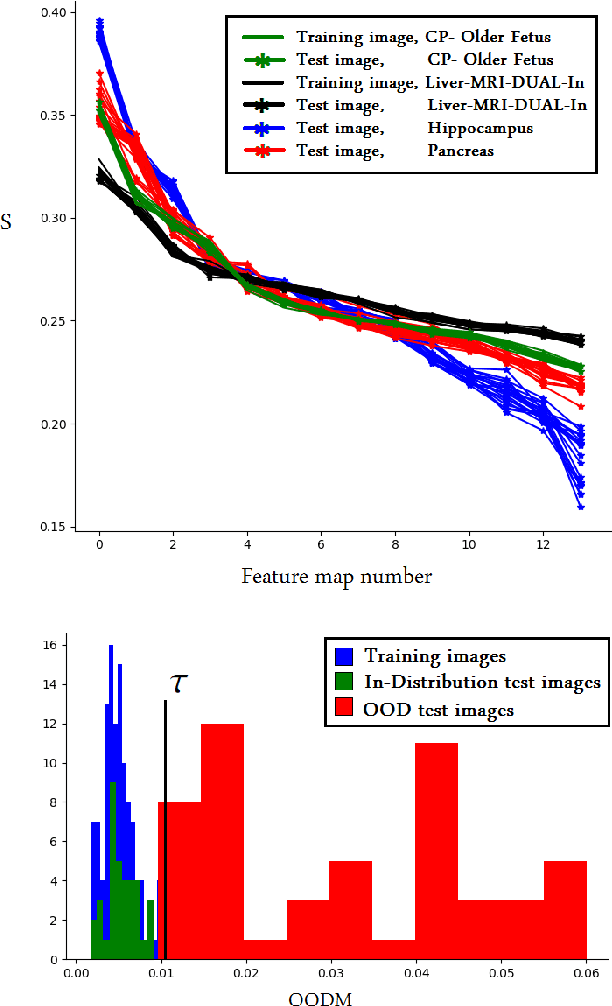
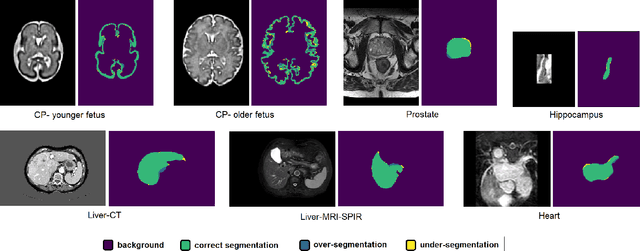
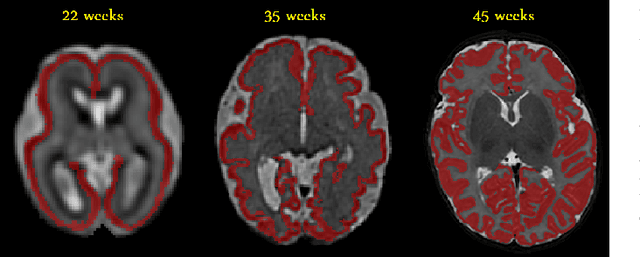
Convolutional Neural Networks (CNNs) are powerful medical image segmentation models. In this study, we address some of the main unresolved issues regarding these models. Specifically, training of these models on small medical image datasets is still challenging, with many studies promoting techniques such as transfer learning. Moreover, these models are infamous for producing over-confident predictions and for failing silently when presented with out-of-distribution (OOD) data at test time. In this paper, we advocate for training on heterogeneous data, i.e., training a single model on several different datasets, spanning several different organs of interest and different imaging modalities. We show that not only a single CNN learns to automatically recognize the context and accurately segment the organ of interest in each context, but also that such a joint model often has more accurate and better-calibrated predictions than dedicated models trained separately on each dataset. We also show that training on heterogeneous data can outperform transfer learning. For detecting OOD data, we propose a method based on spectral analysis of CNN feature maps. We show that different datasets, representing different imaging modalities and/or different organs of interest, have distinct spectral signatures, which can be used to identify whether or not a test image is similar to the images used to train a model. We show that this approach is far more accurate than OOD detection based on prediction uncertainty. The methods proposed in this paper contribute significantly to improving the accuracy and reliability of CNN-based medical image segmentation models.
Design Strategy Network: A deep hierarchical framework to represent generative design strategies in complex action spaces
Oct 07, 2021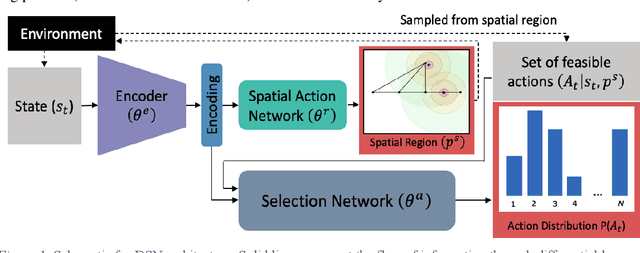
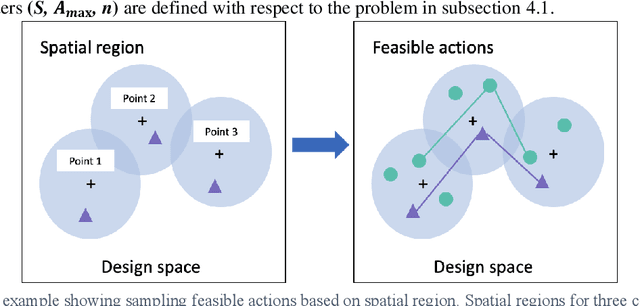

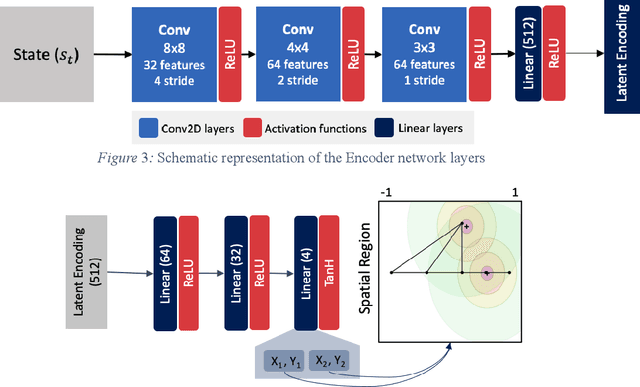
Generative design problems often encompass complex action spaces that may be divergent over time, contain state-dependent constraints, or involve hybrid (discrete and continuous) domains. To address those challenges, this work introduces Design Strategy Network (DSN), a data-driven deep hierarchical framework that can learn strategies over these arbitrary complex action spaces. The hierarchical architecture decomposes every action decision into first predicting a preferred spatial region in the design space and then outputting a probability distribution over a set of possible actions from that region. This framework comprises a convolutional encoder to work with image-based design state representations, a multi-layer perceptron to predict a spatial region, and a weight-sharing network to generate a probability distribution over unordered set-based inputs of feasible actions. Applied to a truss design study, the framework learns to predict the actions of human designers in the study, capturing their truss generation strategies in the process. Results show that DSNs significantly outperform non-hierarchical methods of policy representation, demonstrating their superiority in complex action space problems.
* Published in Journal of Mechanical Design
Attacks on Image Encryption Schemes for Privacy-Preserving Deep Neural Networks
Apr 29, 2020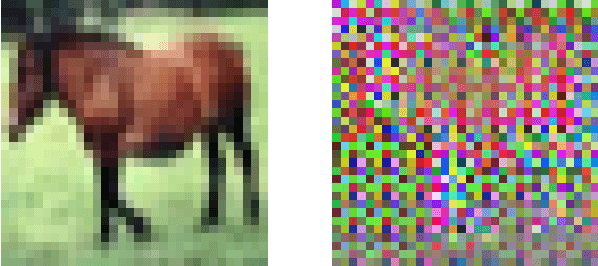

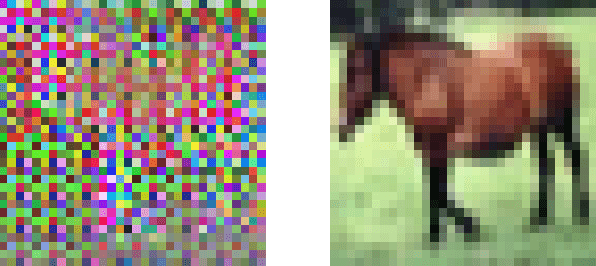

Privacy preserving machine learning is an active area of research usually relying on techniques such as homomorphic encryption or secure multiparty computation. Recent novel encryption techniques for performing machine learning using deep neural nets on images have recently been proposed by Tanaka and Sirichotedumrong, Kinoshita, and Kiya. We present new chosen-plaintext and ciphertext-only attacks against both of these proposed image encryption schemes and demonstrate the attacks' effectiveness on several examples.
Exemplar Guided Face Image Super-Resolution without Facial Landmarks
Jun 17, 2019
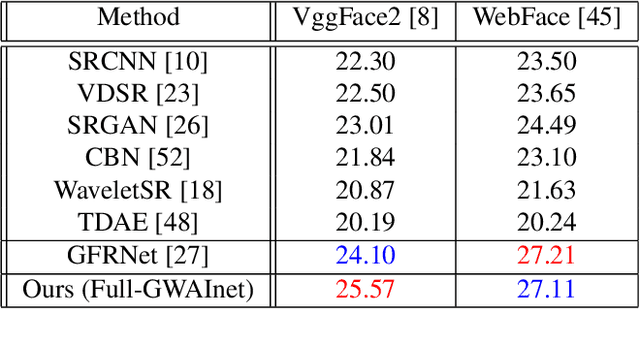
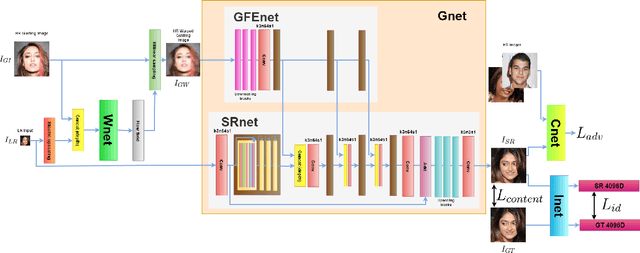
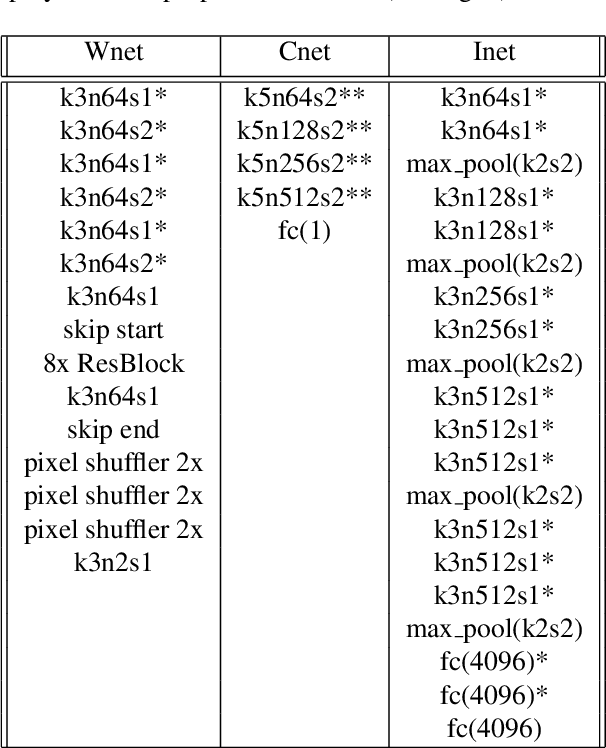
Nowadays, due to the ubiquitous visual media there are vast amounts of already available high-resolution (HR) face images. Therefore, for super-resolving a given very low-resolution (LR) face image of a person it is very likely to find another HR face image of the same person which can be used to guide the process. In this paper, we propose a convolutional neural network (CNN)-based solution, namely GWAInet, which applies super-resolution (SR) by a factor 8x on face images guided by another unconstrained HR face image of the same person with possible differences in age, expression, pose or size. GWAInet is trained in an adversarial generative manner to produce the desired high quality perceptual image results. The utilization of the HR guiding image is realized via the use of a warper subnetwork that aligns its contents to the input image and the use of a feature fusion chain for the extracted features from the warped guiding image and the input image. In training, the identity loss further helps in preserving the identity related features by minimizing the distance between the embedding vectors of SR and HR ground truth images. Contrary to the current state-of-the-art in face super-resolution, our method does not require facial landmark points for its training, which helps its robustness and allows it to produce fine details also for the surrounding face region in a uniform manner. Our method GWAInet produces photo-realistic images in upscaling factor 8x and outperforms state-of-the-art in quantitative terms and perceptual quality.
Faces in the Wild: Efficient Gender Recognition in Surveillance Conditions
Jul 14, 2021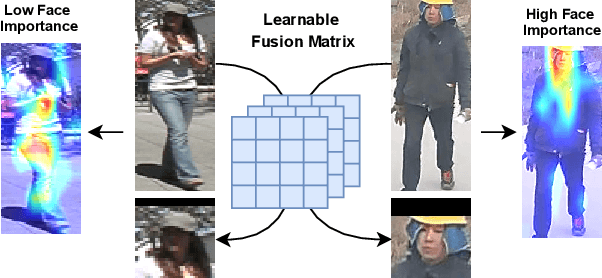
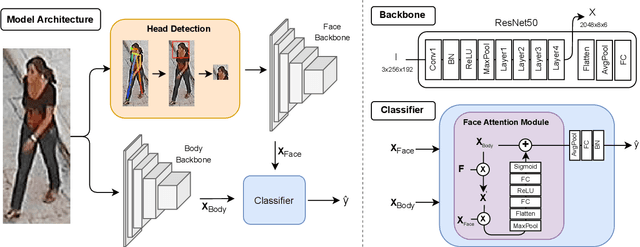


Soft biometrics inference in surveillance scenarios is a topic of interest for various applications, particularly in security-related areas. However, soft biometric analysis is not extensively reported in wild conditions. In particular, previous works on gender recognition report their results in face datasets, with relatively good image quality and frontal poses. Given the uncertainty of the availability of the facial region in wild conditions, we consider that these methods are not adequate for surveillance settings. To overcome these limitations, we: 1) present frontal and wild face versions of three well-known surveillance datasets; and 2) propose a model that effectively and dynamically combines facial and body information, which makes it suitable for gender recognition in wild conditions. The frontal and wild face datasets derive from widely used Pedestrian Attribute Recognition (PAR) sets (PETA, PA-100K, and RAP), using a pose-based approach to filter the frontal samples and facial regions. This approach retrieves the facial region of images with varying image/subject conditions, where the state-of-the-art face detectors often fail. Our model combines facial and body information through a learnable fusion matrix and a channel-attention sub-network, focusing on the most influential body parts according to the specific image/subject features. We compare it with five PAR methods, consistently obtaining state-of-the-art results on gender recognition, and reducing the prediction errors by up to 24% in frontal samples. The announced PAR datasets versions and model serve as the basis for wild soft biometrics classification and are available in https://github.com/Tiago-Roxo.
Towards Cross-modality Medical Image Segmentation with Online Mutual Knowledge Distillation
Oct 04, 2020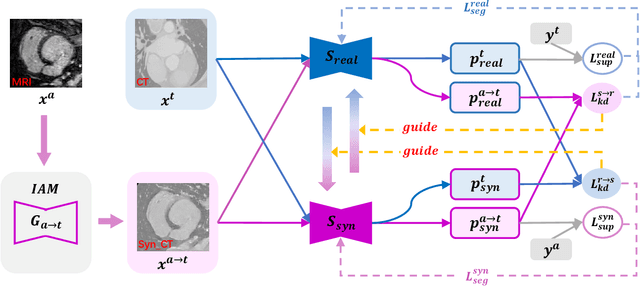
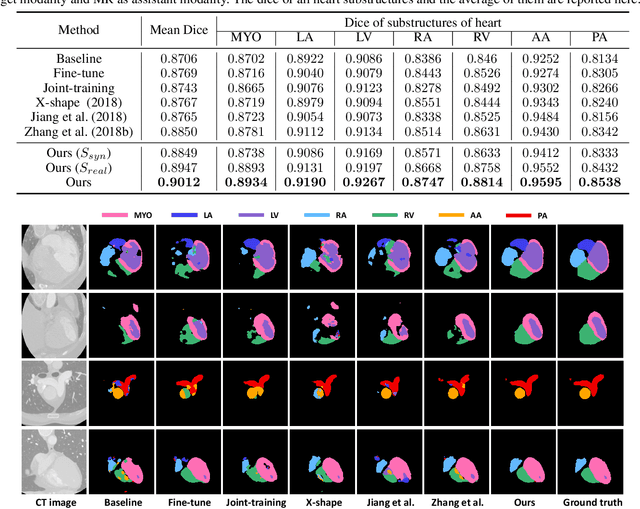
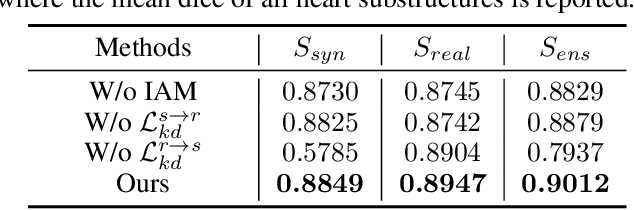
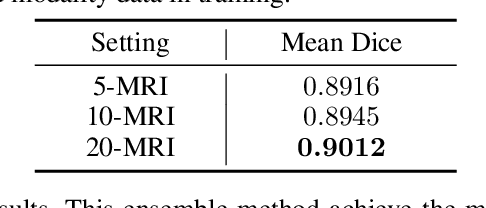
The success of deep convolutional neural networks is partially attributed to the massive amount of annotated training data. However, in practice, medical data annotations are usually expensive and time-consuming to be obtained. Considering multi-modality data with the same anatomic structures are widely available in clinic routine, in this paper, we aim to exploit the prior knowledge (e.g., shape priors) learned from one modality (aka., assistant modality) to improve the segmentation performance on another modality (aka., target modality) to make up annotation scarcity. To alleviate the learning difficulties caused by modality-specific appearance discrepancy, we first present an Image Alignment Module (IAM) to narrow the appearance gap between assistant and target modality data.We then propose a novel Mutual Knowledge Distillation (MKD) scheme to thoroughly exploit the modality-shared knowledge to facilitate the target-modality segmentation. To be specific, we formulate our framework as an integration of two individual segmentors. Each segmentor not only explicitly extracts one modality knowledge from corresponding annotations, but also implicitly explores another modality knowledge from its counterpart in mutual-guided manner. The ensemble of two segmentors would further integrate the knowledge from both modalities and generate reliable segmentation results on target modality. Experimental results on the public multi-class cardiac segmentation data, i.e., MMWHS 2017, show that our method achieves large improvements on CT segmentation by utilizing additional MRI data and outperforms other state-of-the-art multi-modality learning methods.
* Accepted by AAAI 2020
Learn like a Pathologist: Curriculum Learning by Annotator Agreement for Histopathology Image Classification
Sep 29, 2020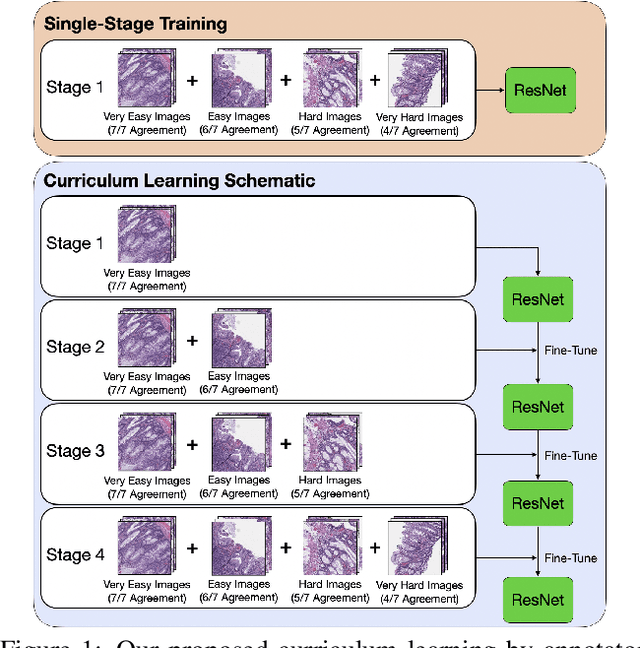
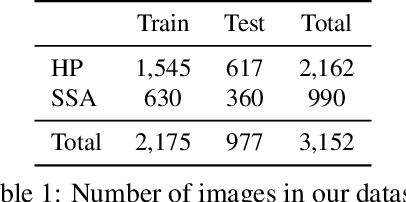
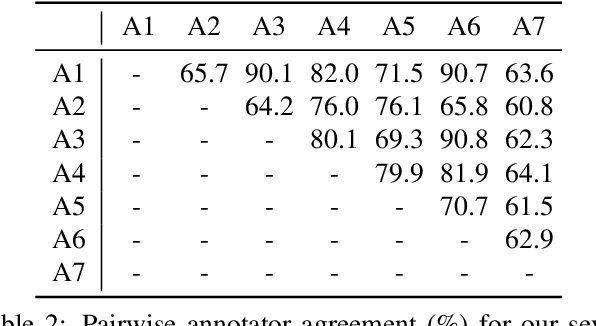
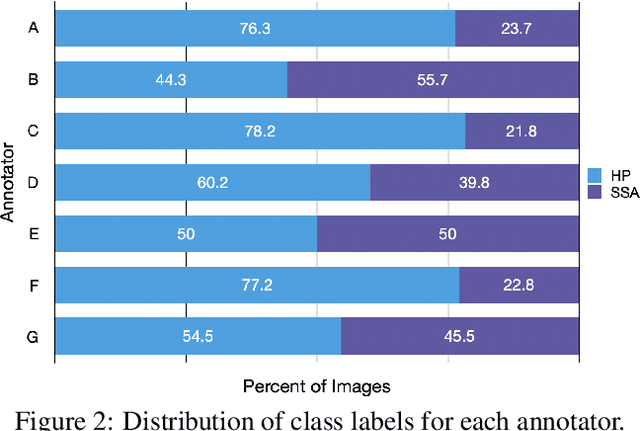
Applying curriculum learning requires both a range of difficulty in data and a method for determining the difficulty of examples. In many tasks, however, satisfying these requirements can be a formidable challenge. In this paper, we contend that histopathology image classification is a compelling use case for curriculum learning. Based on the nature of histopathology images, a range of difficulty inherently exists among examples, and, since medical datasets are often labeled by multiple annotators, annotator agreement can be used as a natural proxy for the difficulty of a given example. Hence, we propose a simple curriculum learning method that trains on progressively-harder images as determined by annotator agreement. We evaluate our hypothesis on the challenging and clinically-important task of colorectal polyp classification. Whereas vanilla training achieves an AUC of 83.7% for this task, a model trained with our proposed curriculum learning approach achieves an AUC of 88.2%, an improvement of 4.5%. Our work aims to inspire researchers to think more creatively and rigorously when choosing contexts for applying curriculum learning.