 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Difficulty Curriculum for Generative Adversarial Networks (CuGAN)
Oct 20, 2019
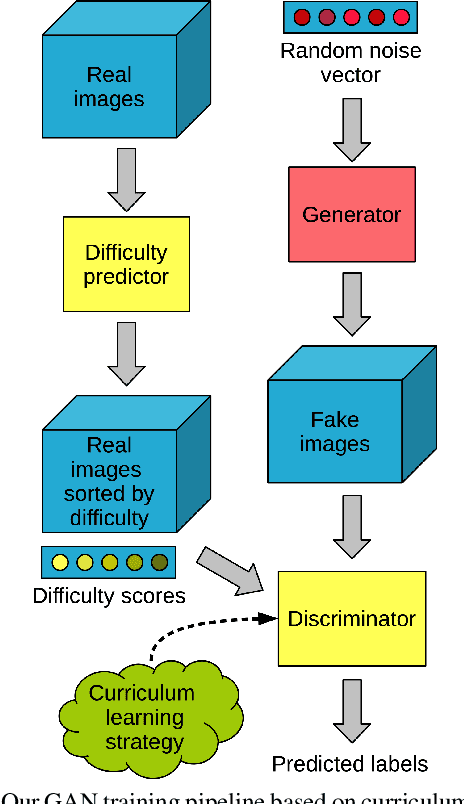


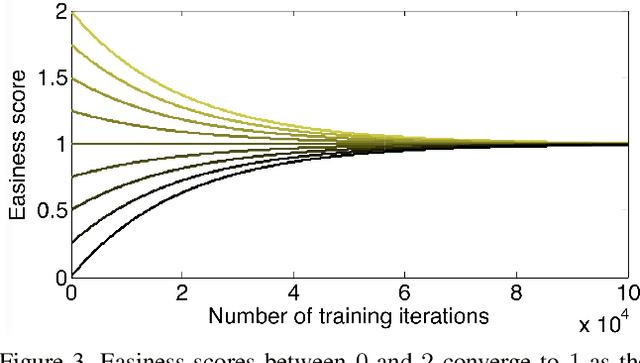
Despite the significant advances in recent years, Generative Adversarial Networks (GANs) are still notoriously hard to train. In this paper, we propose three novel curriculum learning strategies for training GANs. All strategies are first based on ranking the training images by their difficulty scores, which are estimated by a state-of-the-art image difficulty predictor. Our first strategy is to divide images into gradually more difficult batches. Our second strategy introduces a novel curriculum loss function for the discriminator that takes into account the difficulty scores of the real images. Our third strategy is based on sampling from an evolving distribution, which favors the easier images during the initial training stages and gradually converges to a uniform distribution, in which samples are equally likely, regardless of difficulty. We compare our curriculum learning strategies with the classic training procedure on two tasks: image generation and image translation. Our experiments indicate that all strategies provide faster convergence and superior results. For example, our best curriculum learning strategy applied on spectrally normalized GANs (SNGANs) fooled human annotators in thinking that generated CIFAR-like images are real in 25.0% of the presented cases, while the SNGANs trained using the classic procedure fooled the annotators in only 18.4% cases. Similarly, in image translation, the human annotators preferred the images produced by the Cycle-consistent GAN (CycleGAN) trained using curriculum learning in 40.5% cases and those produced by CycleGAN based on classic training in only 19.8% cases, $39.7\%$ cases being labeled as ties.
Alpha Matte Generation from Single Input for Portrait Matting
Jun 14, 2021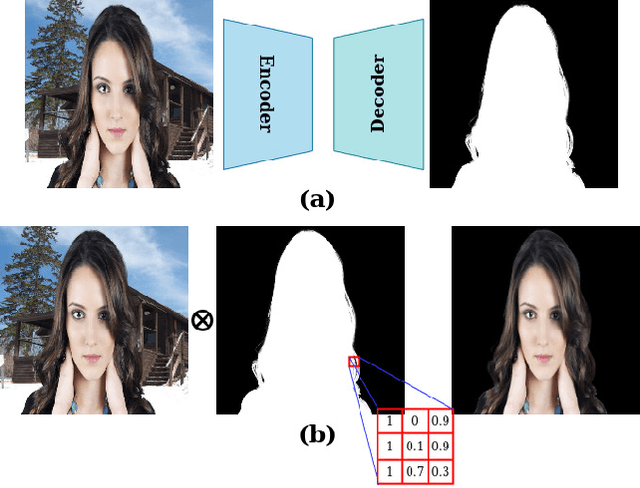
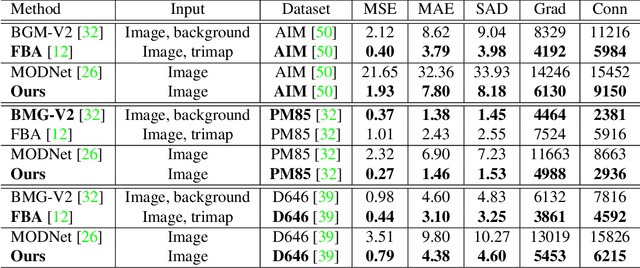
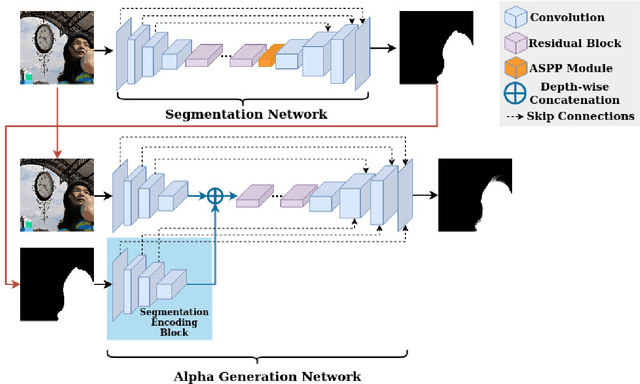
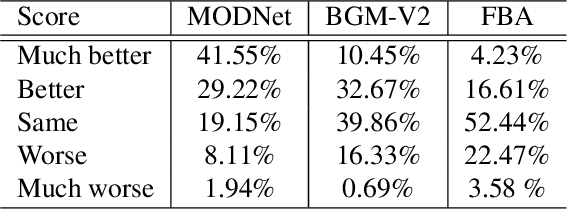
Portrait matting is an important research problem with a wide range of applications, such as video conference app, image/video editing, and post-production. The goal is to predict an alpha matte that identifies the effect of each pixel on the foreground subject. Traditional approaches and most of the existing works utilized an additional input, e.g., trimap, background image, to predict alpha matte. However, providing additional input is not always practical. Besides, models are too sensitive to these additional inputs. In this paper, we introduce an additional input-free approach to perform portrait matting using Generative Adversarial Nets (GANs). We divide the main task into two subtasks. For this, we propose a segmentation network for the person segmentation and the alpha generation network for alpha matte prediction. While the segmentation network takes an input image and produces a coarse segmentation map, the alpha generation network utilizes the same input image as well as a coarse segmentation map that is produced by the segmentation network to predict the alpha matte. Besides, we present a segmentation encoding block to downsample the coarse segmentation map and provide feature representation to the residual block. Furthermore, we propose border loss to penalize only the borders of the subject separately which is more likely to be challenging and we also adapt perceptual loss for portrait matting. To train the proposed system, we combine two different popular training datasets to improve the amount of data as well as diversity to address domain shift problems in the inference time. We tested our model on three different benchmark datasets, namely Adobe Image Matting dataset, Portrait Matting dataset, and Distinctions dataset. The proposed method outperformed the MODNet method that also takes a single input.
Feature Forwarding for Efficient Single Image Dehazing
May 03, 2019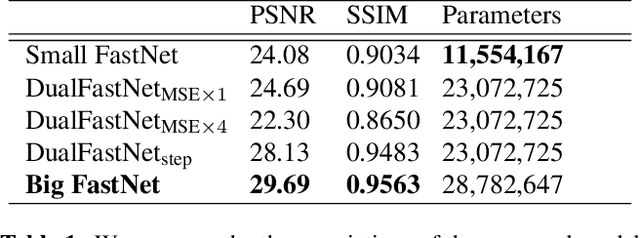
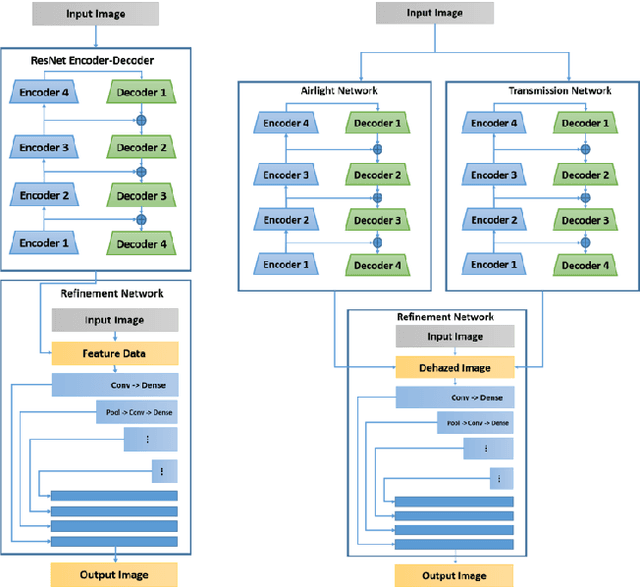
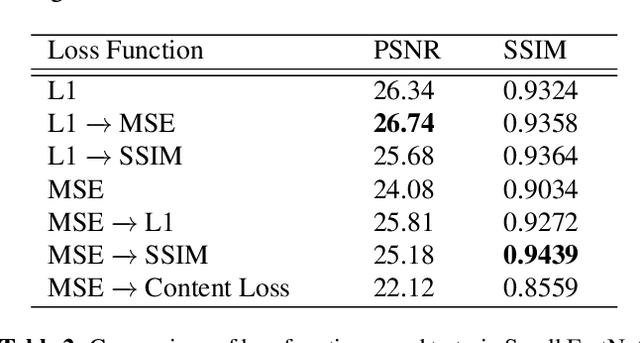
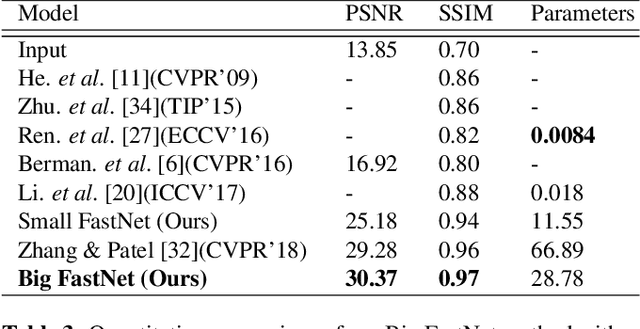
Haze degrades content and obscures information of images, which can negatively impact vision-based decision-making in real-time systems. In this paper, we propose an efficient fully convolutional neural network (CNN) image dehazing method designed to run on edge graphical processing units (GPUs). We utilize three variants of our architecture to explore the dependency of dehazed image quality on parameter count and model design. The first two variants presented, a small and big version, make use of a single efficient encoder-decoder convolutional feature extractor. The final variant utilizes a pair of encoder-decoders for atmospheric light and transmission map estimation. Each variant ends with an image refinement pyramid pooling network to form the final dehazed image. For the big variant of the single-encoder network, we demonstrate state-of-the-art performance on the NYU Depth dataset. For the small variant, we maintain competitive performance on the super-resolution O/I-HAZE datasets without the need for image cropping. Finally, we examine some challenges presented by the Dense-Haze dataset when leveraging CNN architectures for dehazing of dense haze imagery and examine the impact of loss function selection on image quality. Benchmarks are included to show the feasibility of introducing this approach into real-time systems.
TEAM-Net: Multi-modal Learning for Video Action Recognition with Partial Decoding
Oct 17, 2021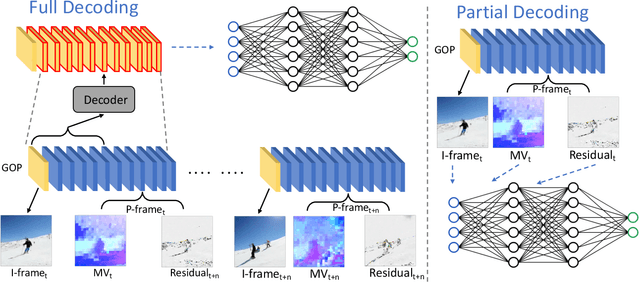


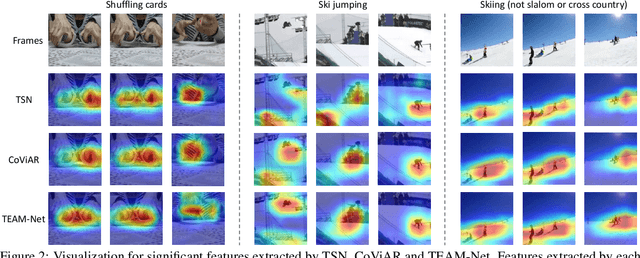
Most of existing video action recognition models ingest raw RGB frames. However, the raw video stream requires enormous storage and contains significant temporal redundancy. Video compression (e.g., H.264, MPEG-4) reduces superfluous information by representing the raw video stream using the concept of Group of Pictures (GOP). Each GOP is composed of the first I-frame (aka RGB image) followed by a number of P-frames, represented by motion vectors and residuals, which can be regarded and used as pre-extracted features. In this work, we 1) introduce sampling the input for the network from partially decoded videos based on the GOP-level, and 2) propose a plug-and-play mulTi-modal lEArning Module (TEAM) for training the network using information from I-frames and P-frames in an end-to-end manner. We demonstrate the superior performance of TEAM-Net compared to the baseline using RGB only. TEAM-Net also achieves the state-of-the-art performance in the area of video action recognition with partial decoding. Code is provided at https://github.com/villawang/TEAM-Net.
LIFE: Lighting Invariant Flow Estimation
Apr 19, 2021

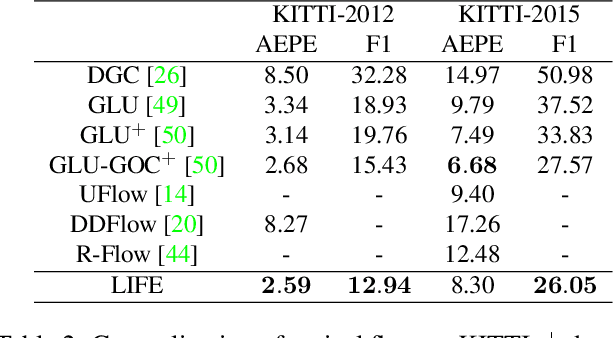
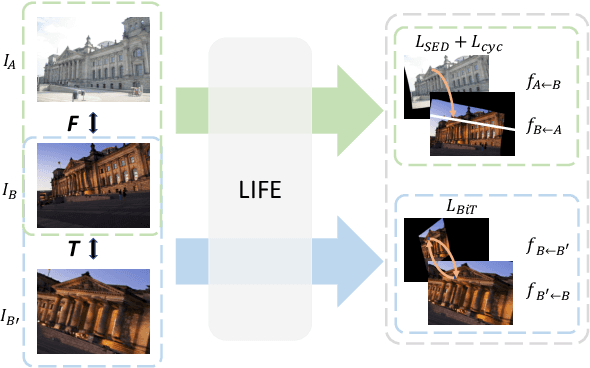
We tackle the problem of estimating flow between two images with large lighting variations. Recent learning-based flow estimation frameworks have shown remarkable performance on image pairs with small displacement and constant illuminations, but cannot work well on cases with large viewpoint change and lighting variations because of the lack of pixel-wise flow annotations for such cases. We observe that via the Structure-from-Motion (SfM) techniques, one can easily estimate relative camera poses between image pairs with large viewpoint change and lighting variations. We propose a novel weakly supervised framework LIFE to train a neural network for estimating accurate lighting-invariant flows between image pairs. Sparse correspondences are conventionally established via feature matching with descriptors encoding local image contents. However, local image contents are inevitably ambiguous and error-prone during the cross-image feature matching process, which hinders downstream tasks. We propose to guide feature matching with the flows predicted by LIFE, which addresses the ambiguous matching by utilizing abundant context information in the image pairs. We show that LIFE outperforms previous flow learning frameworks by large margins in challenging scenarios, consistently improves feature matching, and benefits downstream tasks.
Learning Landmarks from Unaligned Data using Image Translation
Jul 03, 2019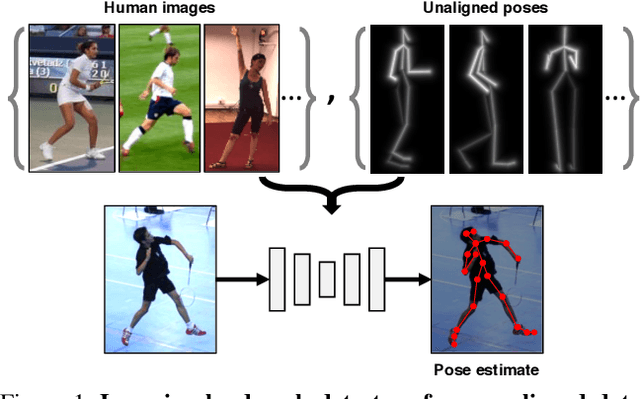
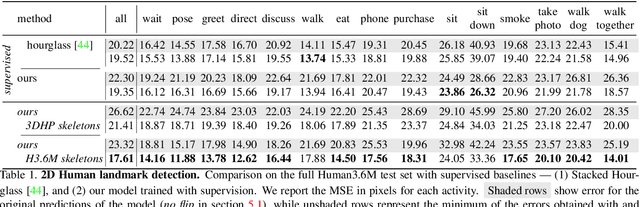

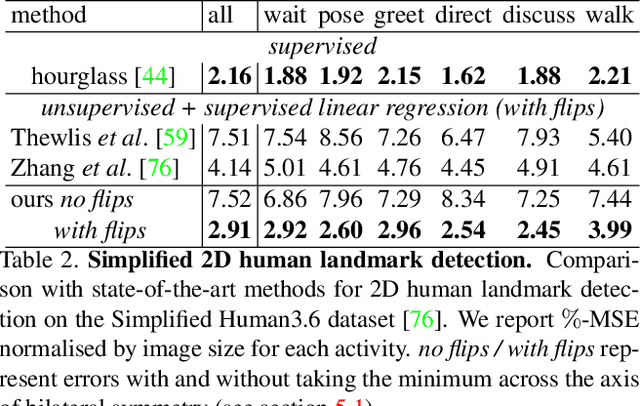
We introduce a method for learning landmark detectors from unlabelled video frames and unpaired labels. This allows us to learn a detector from a large collection of raw videos given only a few example annotations harvested from existing data or motion capture. We achieve this by formulating the landmark detection task as one of image translation, learning to map an image of the object to an image of its landmarks, represented as a skeleton. The advantage is that this translation problem can then be tackled by CycleGAN. However, we show that a naive application of CycleGAN confounds appearance and pose information, with suboptimal keypoint detection performance. We solve this problem by introducing an analytical and differentiable renderer for the skeleton image so that no appearance information can be leaked in the skeleton. Then, since cycle consistency requires to reconstruct the input image from the skeleton, we supply the appearance information thus removed by conditioning the generator with a second image of the same object (e.g. another frame from a video). Furthermore, while CycleGAN uses two cycle consistency constraints, we show that the second one is detrimental in this application and we discard it, significantly simplifying the model. We show that these modifications improve the quality of the learned detector leading to state-of-the-art unsupervised landmark detection performance in a number of challenging human pose and facial landmark detection benchmarks.
FedIPR: Ownership Verification for Federated Deep Neural Network Models
Sep 27, 2021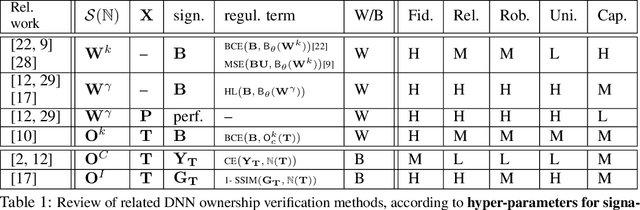
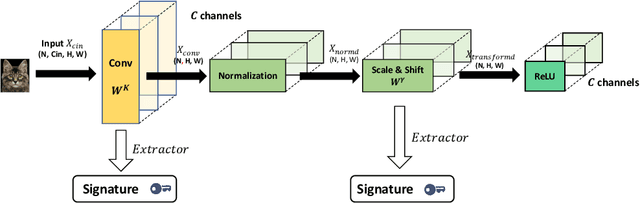
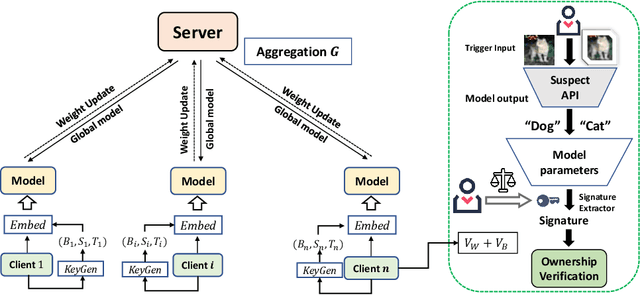
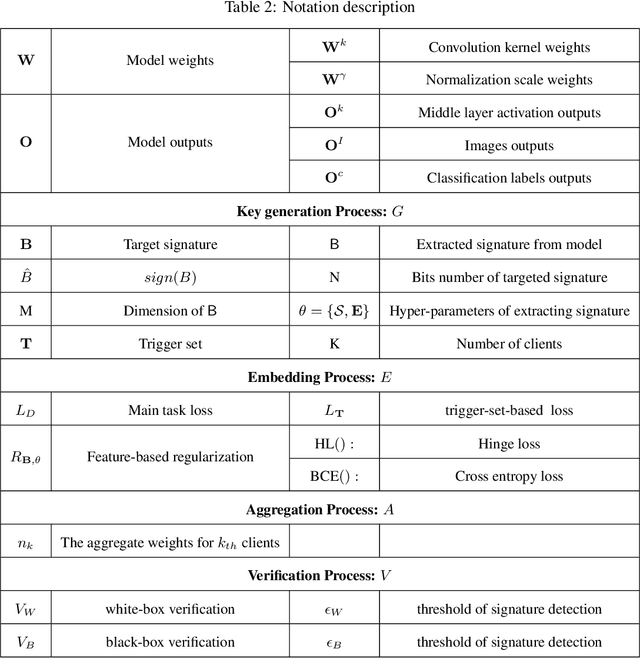
Federated learning models must be protected against plagiarism since these models are built upon valuable training data owned by multiple institutions or people.This paper illustrates a novel federated deep neural network (FedDNN) ownership verification scheme that allows ownership signatures to be embedded and verified to claim legitimate intellectual property rights (IPR) of FedDNN models, in case that models are illegally copied, re-distributed or misused. The effectiveness of embedded ownership signatures is theoretically justified by proved condition sunder which signatures can be embedded and detected by multiple clients with-out disclosing private signatures. Extensive experimental results on CIFAR10,CIFAR100 image datasets demonstrate that varying bit-lengths signatures can be embedded and reliably detected without affecting models classification performances. Signatures are also robust against removal attacks including fine-tuning and pruning.
Robust Pose Transfer with Dynamic Details using Neural Video Rendering
Jul 14, 2021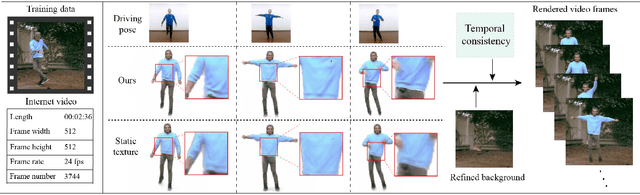
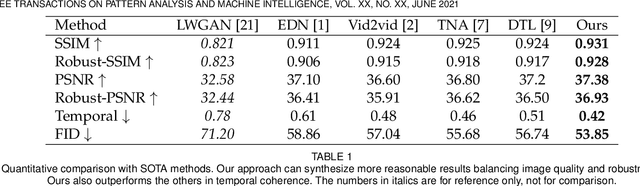
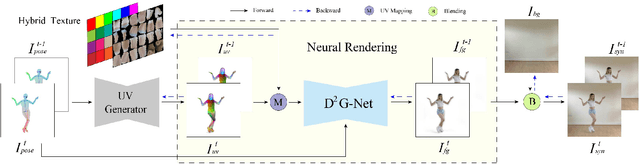
Pose transfer of human videos aims to generate a high fidelity video of a target person imitating actions of a source person. A few studies have made great progress either through image translation with deep latent features or neural rendering with explicit 3D features. However, both of them rely on large amounts of training data to generate realistic results, and the performance degrades on more accessible internet videos due to insufficient training frames. In this paper, we demonstrate that the dynamic details can be preserved even trained from short monocular videos. Overall, we propose a neural video rendering framework coupled with an image-translation-based dynamic details generation network (D2G-Net), which fully utilizes both the stability of explicit 3D features and the capacity of learning components. To be specific, a novel texture representation is presented to encode both the static and pose-varying appearance characteristics, which is then mapped to the image space and rendered as a detail-rich frame in the neural rendering stage. Moreover, we introduce a concise temporal loss in the training stage to suppress the detail flickering that is made more visible due to high-quality dynamic details generated by our method. Through extensive comparisons, we demonstrate that our neural human video renderer is capable of achieving both clearer dynamic details and more robust performance even on accessible short videos with only 2k - 4k frames.
Efficient remedies for outlier detection with variational autoencoders
Aug 19, 2021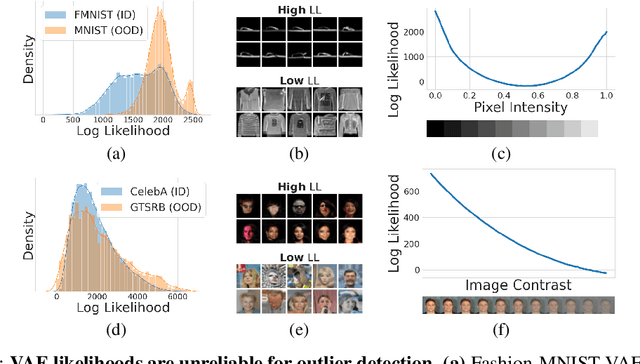

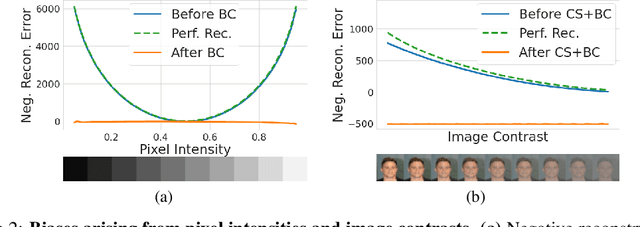
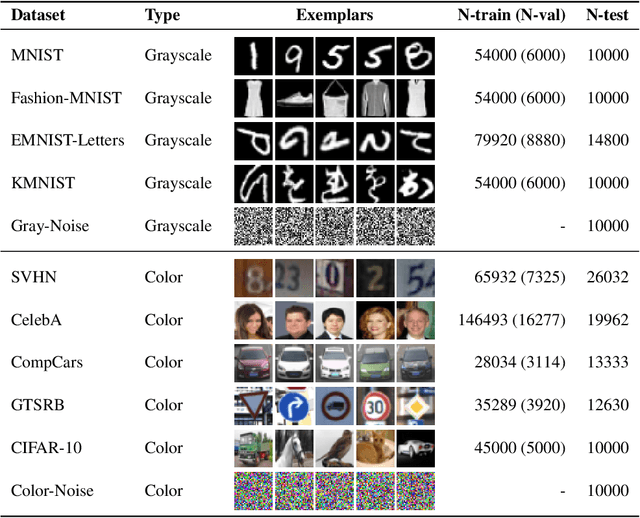
Deep networks often make confident, yet incorrect, predictions when tested with outlier data that is far removed from their training distributions. Likelihoods computed by deep generative models are a candidate metric for outlier detection with unlabeled data. Yet, previous studies have shown that such likelihoods are unreliable and can be easily biased by simple transformations to input data. Here, we examine outlier detection with variational autoencoders (VAEs), among the simplest class of deep generative models. First, we show that a theoretically-grounded correction readily ameliorates a key bias with VAE likelihood estimates. The bias correction is model-free, sample-specific, and accurately computed with the Bernoulli and continuous Bernoulli visible distributions. Second, we show that a well-known preprocessing technique, contrast normalization, extends the effectiveness of bias correction to natural image datasets. Third, we show that the variance of the likelihoods computed over an ensemble of VAEs also enables robust outlier detection. We perform a comprehensive evaluation of our remedies with nine (grayscale and natural) image datasets, and demonstrate significant advantages, in terms of both speed and accuracy, over four other state-of-the-art methods. Our lightweight remedies are biologically inspired and may serve to achieve efficient outlier detection with many types of deep generative models.
Statistical Loss and Analysis for Deep Learning in Hyperspectral Image Classification
Dec 28, 2019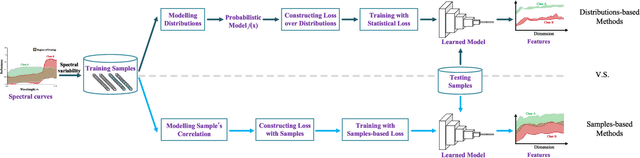
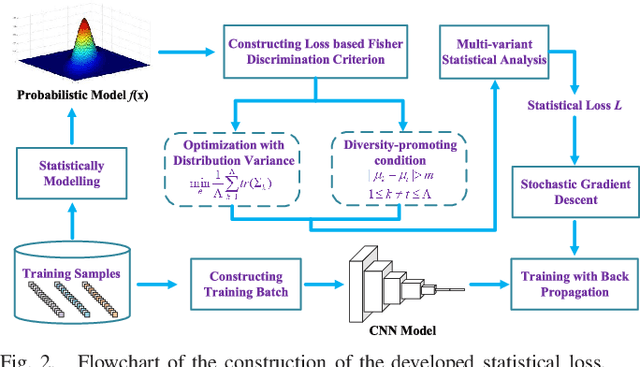

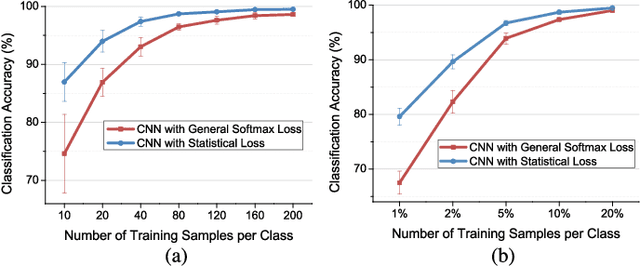
Nowadays, deep learning methods, especially the convolutional neural networks (CNNs), have shown impressive performance on extracting abstract and high-level features from the hyperspectral image. However, general training process of CNNs mainly considers the pixel-wise information or the samples' correlation to formulate the penalization while ignores the statistical properties especially the spectral variability of each class in the hyperspectral image. These samples-based penalizations would lead to the uncertainty of the training process due to the imbalanced and limited number of training samples. To overcome this problem, this work characterizes each class from the hyperspectral image as a statistical distribution and further develops a novel statistical loss with the distributions, not directly with samples for deep learning. Based on the Fisher discrimination criterion, the loss penalizes the sample variance of each class distribution to decrease the intra-class variance of the training samples. Moreover, an additional diversity-promoting condition is added to enlarge the inter-class variance between different class distributions and this could better discriminate samples from different classes in hyperspectral image. Finally, the statistical estimation form of the statistical loss is developed with the training samples through multi-variant statistical analysis. Experiments over the real-world hyperspectral images show the effectiveness of the developed statistical loss for deep learning.