 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Nuisance-Label Supervision: Robustness Improvement by Free Labels
Oct 14, 2021
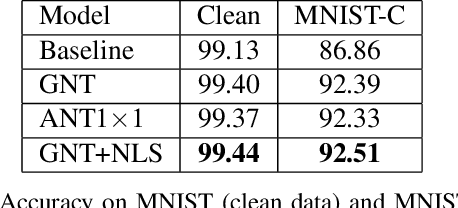
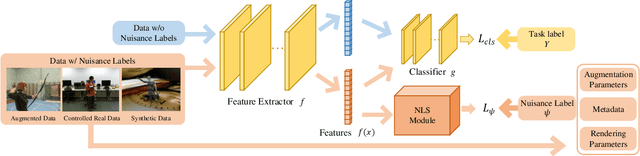

In this paper, we present a Nuisance-label Supervision (NLS) module, which can make models more robust to nuisance factor variations. Nuisance factors are those irrelevant to a task, and an ideal model should be invariant to them. For example, an activity recognition model should perform consistently regardless of the change of clothes and background. But our experiments show existing models are far from this capability. So we explicitly supervise a model with nuisance labels to make extracted features less dependent on nuisance factors. Although the values of nuisance factors are rarely annotated, we demonstrate that besides existing annotations, nuisance labels can be acquired freely from data augmentation and synthetic data. Experiments show consistent improvement in robustness towards image corruption and appearance change in action recognition.
Unsupervised Image-to-Image Translation Using Domain-Specific Variational Information Bound
Nov 29, 2018
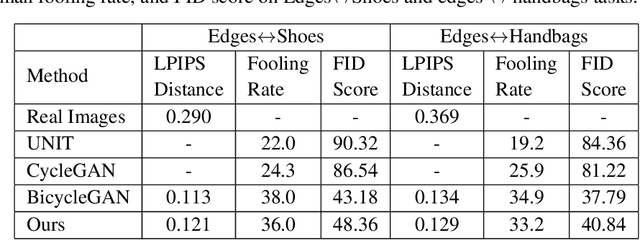
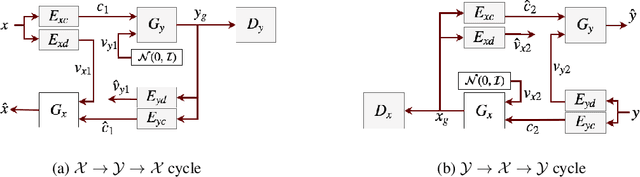
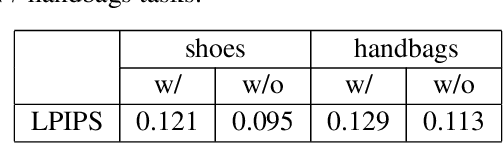
Unsupervised image-to-image translation is a class of computer vision problems which aims at modeling conditional distribution of images in the target domain, given a set of unpaired images in the source and target domains. An image in the source domain might have multiple representations in the target domain. Therefore, ambiguity in modeling of the conditional distribution arises, specially when the images in the source and target domains come from different modalities. Current approaches mostly rely on simplifying assumptions to map both domains into a shared-latent space. Consequently, they are only able to model the domain-invariant information between the two modalities. These approaches usually fail to model domain-specific information which has no representation in the target domain. In this work, we propose an unsupervised image-to-image translation framework which maximizes a domain-specific variational information bound and learns the target domain-invariant representation of the two domain. The proposed framework makes it possible to map a single source image into multiple images in the target domain, utilizing several target domain-specific codes sampled randomly from the prior distribution, or extracted from reference images.
Real-time division-of-focal-plane polarization imaging system with progressive networks
Oct 26, 2021Division-of-focal-plane (DoFP) polarization imaging technical recently has been applied in many fields. However, the images captured by such sensors cannot be used directly because they suffer from instantaneous field-of-view errors and low resolution problem. This paper builds a fast DoFP demosaicing system with proposed progressive polarization demosaicing convolutional neural network (PPDN), which is specifically designed for edge-side GPU devices like Navidia Jetson TX2. The proposed network consists of two parts: reconstruction stage and refining stage. The former recovers four polarization channels from a single DoFP image. The latter fine-tune the four channels to obtain more accurate polarization information. PPDN can be implemented in another version: PPDN-L (large), for the platforms of high computing resources. Experiments show that PPDN can compete with the best existing methods with fewer parameters and faster inference speed and meet the real-time demands of imaging system.
Unified Multi-scale Feature Abstraction for Medical Image Segmentation
Oct 24, 2019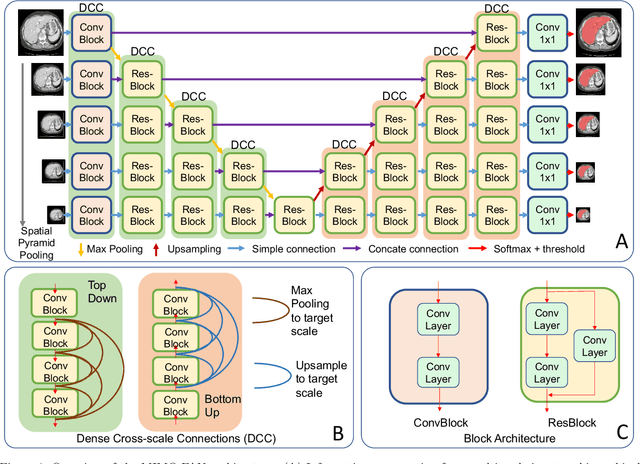
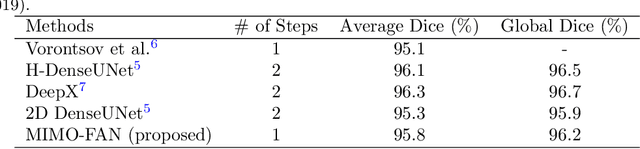
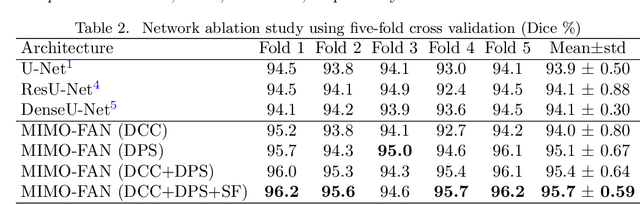
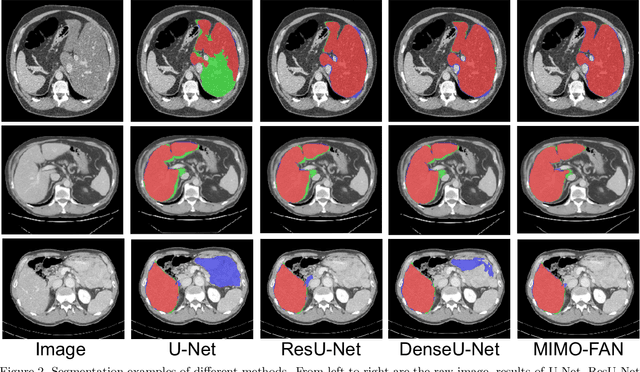
Automatic medical image segmentation, an essential component of medical image analysis, plays an importantrole in computer-aided diagnosis. For example, locating and segmenting the liver can be very helpful in livercancer diagnosis and treatment. The state-of-the-art models in medical image segmentation are variants ofthe encoder-decoder architecture such as fully convolutional network (FCN) and U-Net.1A major focus ofthe FCN based segmentation methods has been on network structure engineering by incorporating the latestCNN structures such as ResNet2and DenseNet.3In addition to exploring new network structures for efficientlyabstracting high level features, incorporating structures for multi-scale image feature extraction in FCN hashelped to improve performance in segmentation tasks. In this paper, we design a new multi-scale networkarchitecture, which takes multi-scale inputs with dedicated convolutional paths to efficiently combine featuresfrom different scales to better utilize the hierarchical information.
Billion-Scale Pretraining with Vision Transformers for Multi-Task Visual Representations
Aug 12, 2021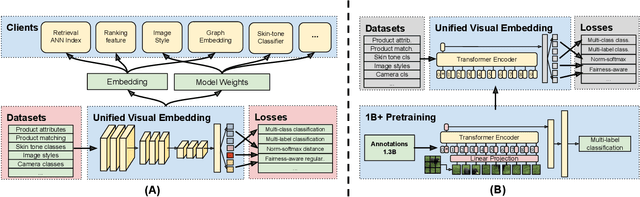
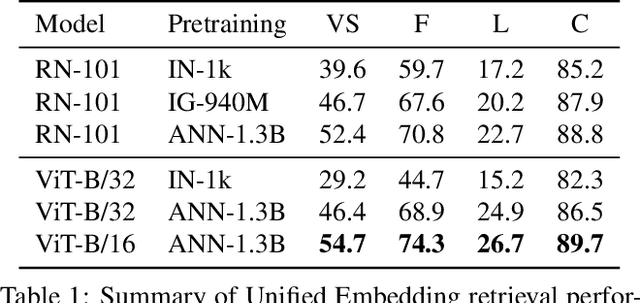

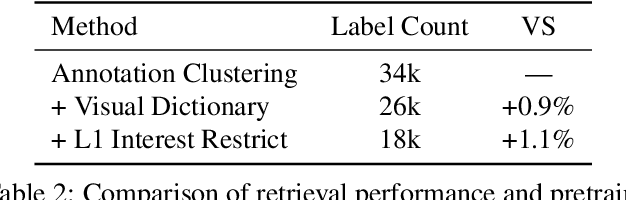
Large-scale pretraining of visual representations has led to state-of-the-art performance on a range of benchmark computer vision tasks, yet the benefits of these techniques at extreme scale in complex production systems has been relatively unexplored. We consider the case of a popular visual discovery product, where these representations are trained with multi-task learning, from use-case specific visual understanding (e.g. skin tone classification) to general representation learning for all visual content (e.g. embeddings for retrieval). In this work, we describe how we (1) generate a dataset with over a billion images via large weakly-supervised pretraining to improve the performance of these visual representations, and (2) leverage Transformers to replace the traditional convolutional backbone, with insights into both system and performance improvements, especially at 1B+ image scale. To support this backbone model, we detail a systematic approach to deriving weakly-supervised image annotations from heterogenous text signals, demonstrating the benefits of clustering techniques to handle the long-tail distribution of image labels. Through a comprehensive study of offline and online evaluation, we show that large-scale Transformer-based pretraining provides significant benefits to industry computer vision applications. The model is deployed in a production visual shopping system, with 36% improvement in top-1 relevance and 23% improvement in click-through volume. We conduct extensive experiments to better understand the empirical relationships between Transformer-based architectures, dataset scale, and the performance of production vision systems.
Manifold-based Test Generation for Image Classifiers
Feb 15, 2020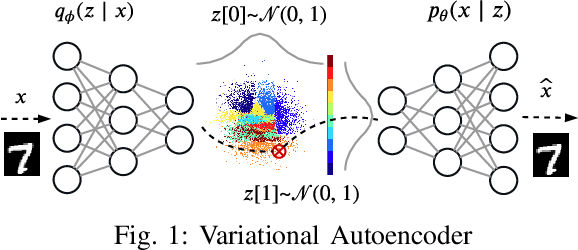
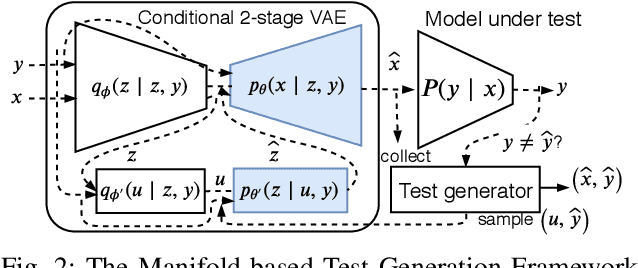


Neural networks used for image classification tasks in critical applications must be tested with sufficient realistic data to assure their correctness. To effectively test an image classification neural network, one must obtain realistic test data adequate enough to inspire confidence that differences between the implicit requirements and the learned model would be exposed. This raises two challenges: first, an adequate subset of the data points must be carefully chosen to inspire confidence, and second, the implicit requirements must be meaningfully extrapolated to data points beyond those in the explicit training set. This paper proposes a novel framework to address these challenges. Our approach is based on the premise that patterns in a large input data space can be effectively captured in a smaller manifold space, from which similar yet novel test cases---both the input and the label---can be sampled and generated. A variant of Conditional Variational Autoencoder (CVAE) is used for capturing this manifold with a generative function, and a search technique is applied on this manifold space to efficiently find fault-revealing inputs. Experiments show that this approach enables generation of thousands of realistic yet fault-revealing test cases efficiently even for well-trained models.
Informative Class Activation Maps
Jun 19, 2021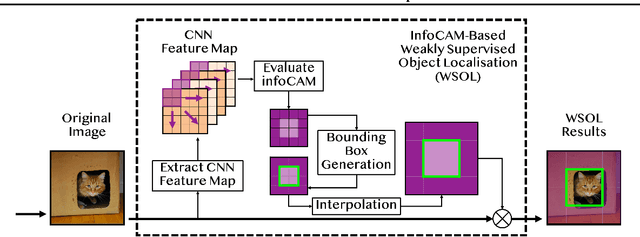
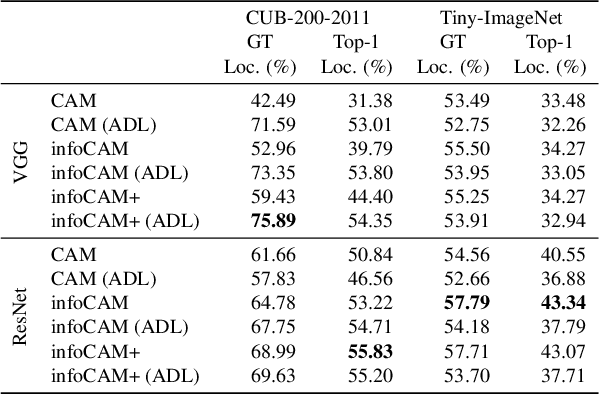

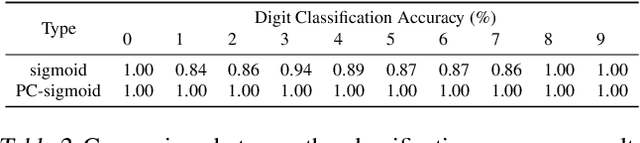
We study how to evaluate the quantitative information content of a region within an image for a particular label. To this end, we bridge class activation maps with information theory. We develop an informative class activation map (infoCAM). Given a classification task, infoCAM depict how to accumulate information of partial regions to that of the entire image toward a label. Thus, we can utilise infoCAM to locate the most informative features for a label. When applied to an image classification task, infoCAM performs better than the traditional classification map in the weakly supervised object localisation task. We achieve state-of-the-art results on Tiny-ImageNet.
A framework for quantitative analysis of Computed Tomography images of viral pneumonitis: radiomic features in COVID and non-COVID patients
Sep 28, 2021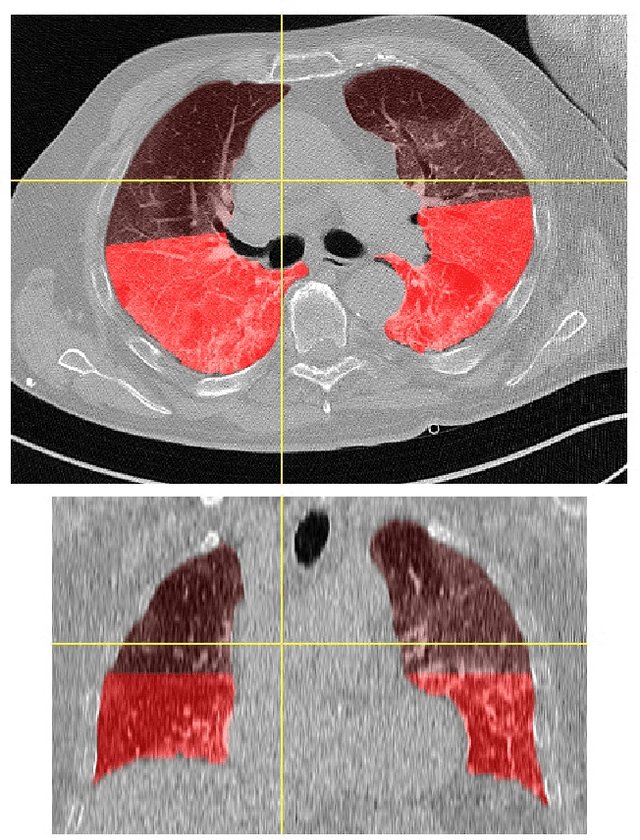
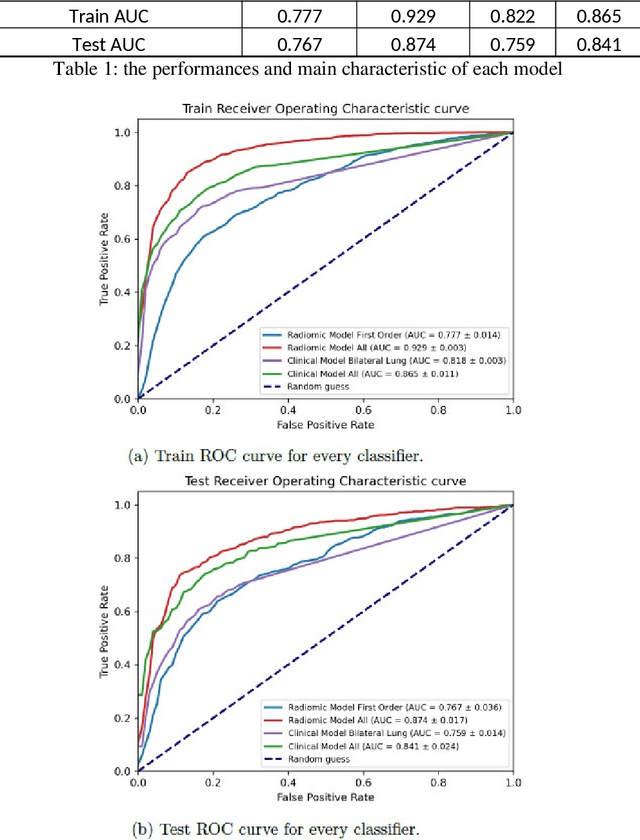
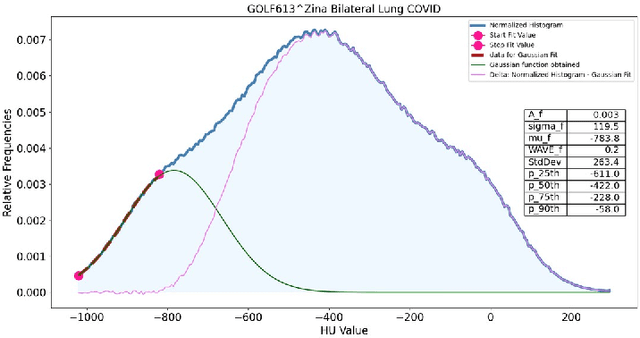
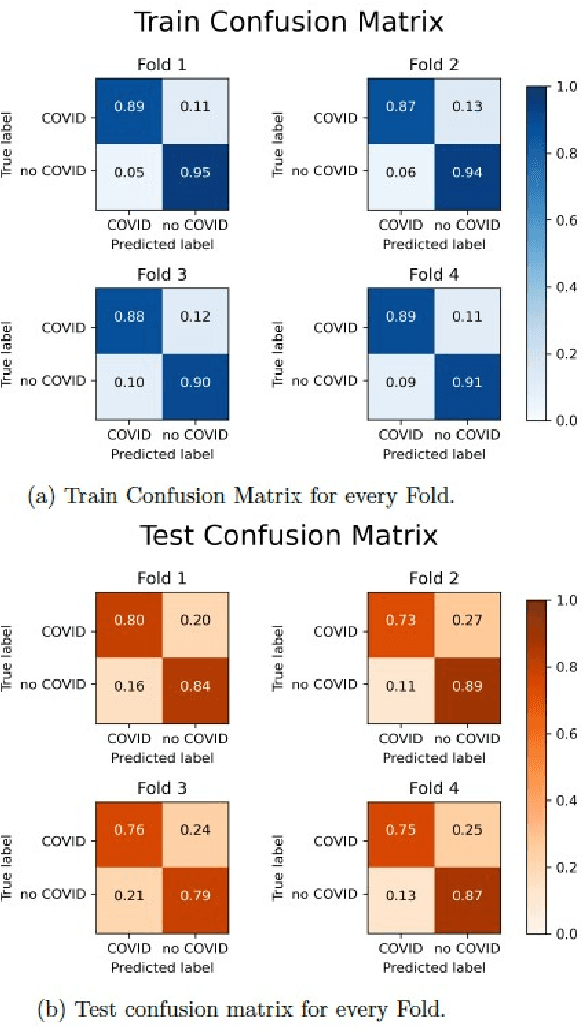
Purpose: to optimize a pipeline of clinical data gathering and CT images processing implemented during the COVID-19 pandemic crisis and to develop artificial intelligence model for different of viral pneumonia. Methods: 1028 chest CT image of patients with positive swab were segmented automatically for lung extraction. A Gaussian model developed in Python language was applied to calculate quantitative metrics (QM) describing well-aerated and ill portions of the lungs from the histogram distribution of lung CT numbers in both lungs of each image and in four geometrical subdivision. Furthermore, radiomic features (RF) of first and second order were extracted from bilateral lungs using PyRadiomic tools. QM and RF were used to develop 4 different Multi-Layer Perceptron (MLP) classifier to discriminate images of patients with COVID (n=646) and non-COVID (n=382) viral pneumonia. Results: The Gaussian model applied to lung CT histogram correctly described healthy parenchyma 94% of the patients. The resulting accuracy of the models for COVID diagnosis were in the range 0.76-0.87, as the integral of the receiver operating curve. The best diagnostic performances were associated to the model based on RF of first and second order, with 21 relevant features after LASSO regression and an accuracy of 0.81$\pm$0.02 after 4-fold cross validation Conclusions: Despite these results were obtained with CT images from a single center, a platform for extracting useful quantitative metrics from CT images was developed and optimized. Four artificial intelligence-based models for classifying patients with COVID and non-COVID viral pneumonia were developed and compared showing overall good diagnostic performances
On Brightness Agnostic Adversarial Examples Against Face Recognition Systems
Sep 29, 2021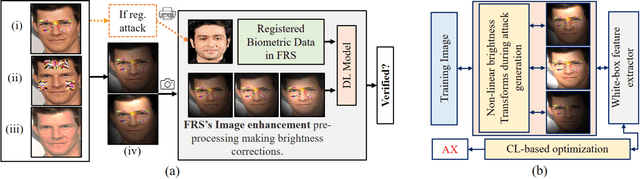
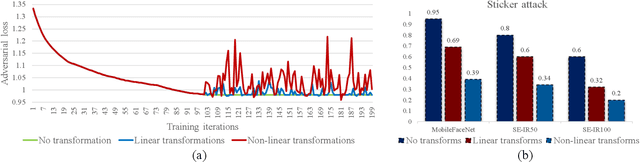
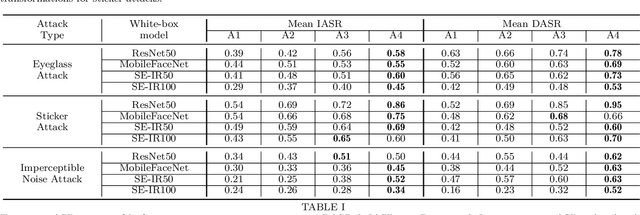
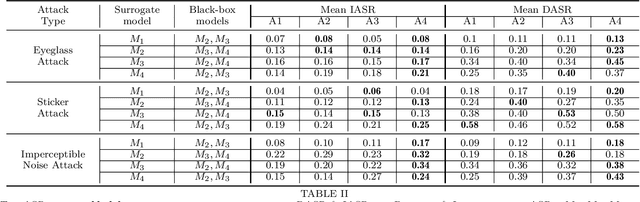
This paper introduces a novel adversarial example generation method against face recognition systems (FRSs). An adversarial example (AX) is an image with deliberately crafted noise to cause incorrect predictions by a target system. The AXs generated from our method remain robust under real-world brightness changes. Our method performs non-linear brightness transformations while leveraging the concept of curriculum learning during the attack generation procedure. We demonstrate that our method outperforms conventional techniques from comprehensive experimental investigations in the digital and physical world. Furthermore, this method enables practical risk assessment of FRSs against brightness agnostic AXs.
* Accepted at BIOSIG 2021 conference
Detecting Backdoor in Deep Neural Networks via Intentional Adversarial Perturbations
May 29, 2021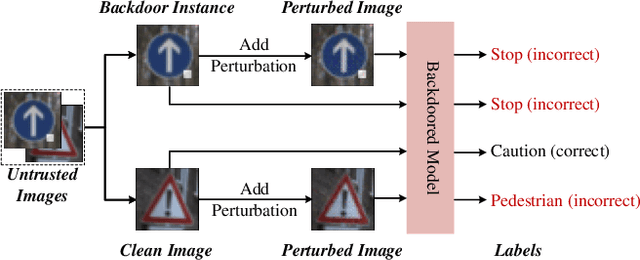
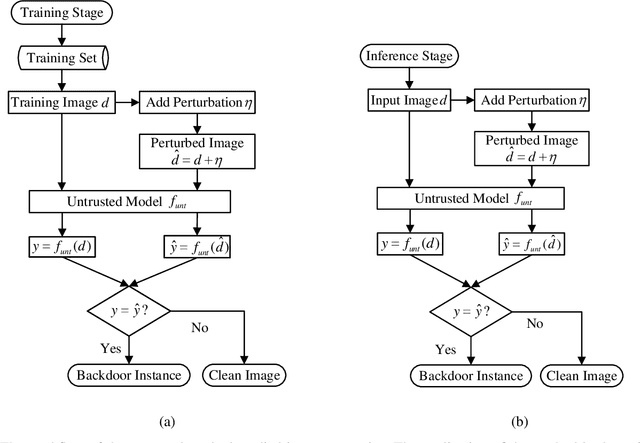


Recent researches show that deep learning model is susceptible to backdoor attacks where the backdoor embedded in the model will be triggered when a backdoor instance arrives. In this paper, a novel backdoor detection method based on adversarial examples is proposed. The proposed method leverages intentional adversarial perturbations to detect whether the image contains a trigger, which can be applied in two scenarios (sanitize the training set in training stage and detect the backdoor instances in inference stage). Specifically, given an untrusted image, the adversarial perturbation is added to the input image intentionally, if the prediction of model on the perturbed image is consistent with that on the unperturbed image, the input image will be considered as a backdoor instance. The proposed adversarial perturbation based method requires low computational resources and maintains the visual quality of the images. Experimental results show that, the proposed defense method reduces the backdoor attack success rates from 99.47%, 99.77% and 97.89% to 0.37%, 0.24% and 0.09% on Fashion-MNIST, CIFAR-10 and GTSRB datasets, respectively. Besides, the proposed method maintains the visual quality of the image as the added perturbation is very small. In addition, for attacks under different settings (trigger transparency, trigger size and trigger pattern), the false acceptance rates of the proposed method are as low as 1.2%, 0.3% and 0.04% on Fashion-MNIST, CIFAR-10 and GTSRB datasets, respectively, which demonstrates that the proposed method can achieve high defense performance against backdoor attacks under different attack settings.