 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent SHAP: Toward Practical Human-Interpretable Explanations
Nov 27, 2022



Model agnostic feature attribution algorithms (such as SHAP and LIME) are ubiquitous techniques for explaining the decisions of complex classification models, such as deep neural networks. However, since complex classification models produce superior performance when trained on low-level (or encoded) features, in many cases, the explanations generated by these algorithms are neither interpretable nor usable by humans. Methods proposed in recent studies that support the generation of human-interpretable explanations are impractical, because they require a fully invertible transformation function that maps the model's input features to the human-interpretable features. In this work, we introduce Latent SHAP, a black-box feature attribution framework that provides human-interpretable explanations, without the requirement for a fully invertible transformation function. We demonstrate Latent SHAP's effectiveness using (1) a controlled experiment where invertible transformation functions are available, which enables robust quantitative evaluation of our method, and (2) celebrity attractiveness classification (using the CelebA dataset) where invertible transformation functions are not available, which enables thorough qualitative evaluation of our method.
On Brightness Agnostic Adversarial Examples Against Face Recognition Systems
Sep 29, 2021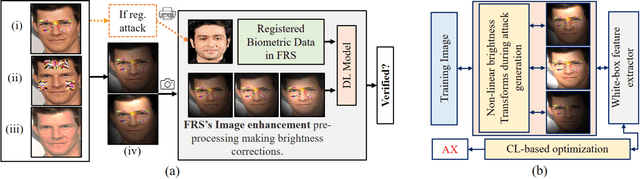
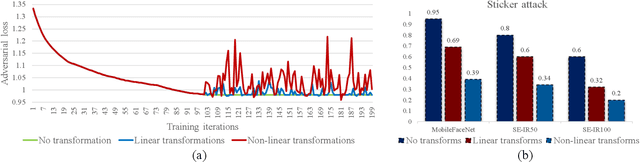
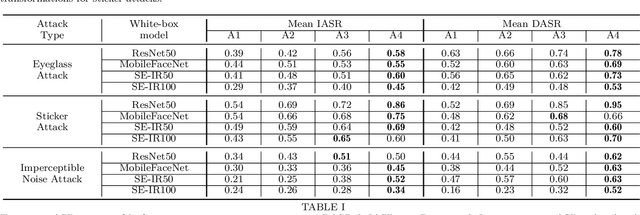
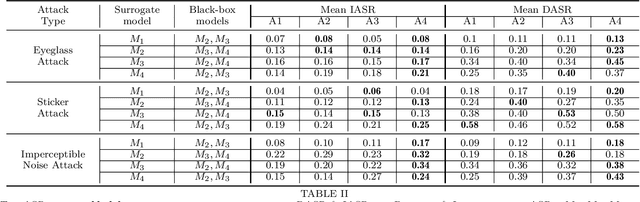
This paper introduces a novel adversarial example generation method against face recognition systems (FRSs). An adversarial example (AX) is an image with deliberately crafted noise to cause incorrect predictions by a target system. The AXs generated from our method remain robust under real-world brightness changes. Our method performs non-linear brightness transformations while leveraging the concept of curriculum learning during the attack generation procedure. We demonstrate that our method outperforms conventional techniques from comprehensive experimental investigations in the digital and physical world. Furthermore, this method enables practical risk assessment of FRSs against brightness agnostic AXs.
* Accepted at BIOSIG 2021 conference
Dodging Attack Using Carefully Crafted Natural Makeup
Sep 14, 2021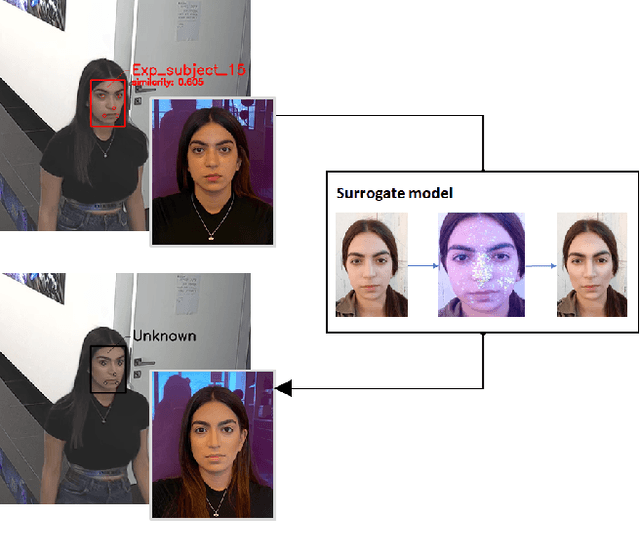

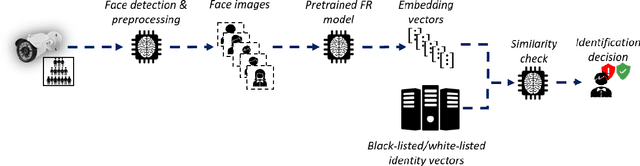
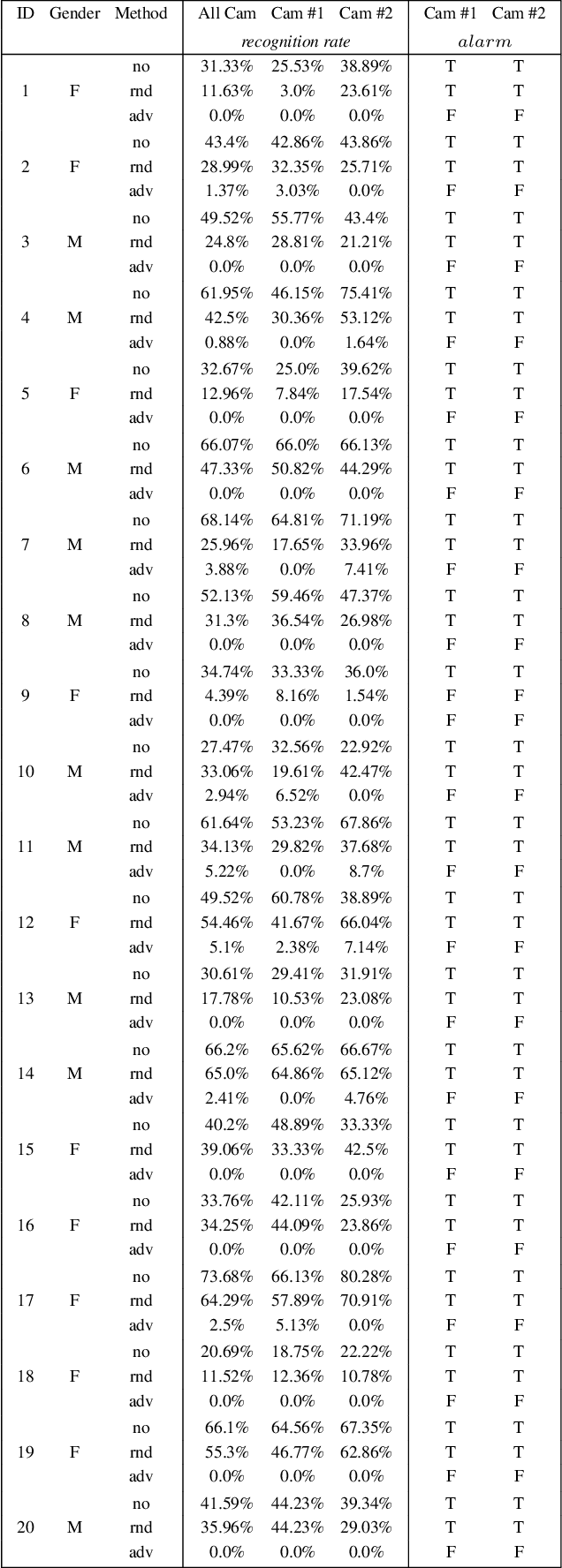
Deep learning face recognition models are used by state-of-the-art surveillance systems to identify individuals passing through public areas (e.g., airports). Previous studies have demonstrated the use of adversarial machine learning (AML) attacks to successfully evade identification by such systems, both in the digital and physical domains. Attacks in the physical domain, however, require significant manipulation to the human participant's face, which can raise suspicion by human observers (e.g. airport security officers). In this study, we present a novel black-box AML attack which carefully crafts natural makeup, which, when applied on a human participant, prevents the participant from being identified by facial recognition models. We evaluated our proposed attack against the ArcFace face recognition model, with 20 participants in a real-world setup that includes two cameras, different shooting angles, and different lighting conditions. The evaluation results show that in the digital domain, the face recognition system was unable to identify all of the participants, while in the physical domain, the face recognition system was able to identify the participants in only 1.22% of the frames (compared to 47.57% without makeup and 33.73% with random natural makeup), which is below a reasonable threshold of a realistic operational environment.
A Framework for Evaluating the Cybersecurity Risk of Real World, Machine Learning Production Systems
Jul 05, 2021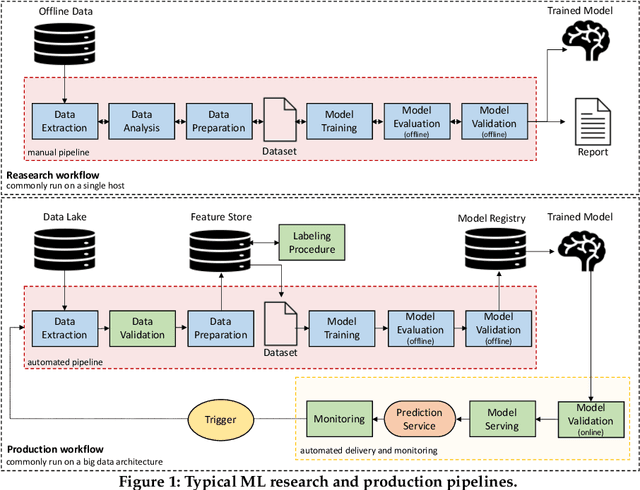

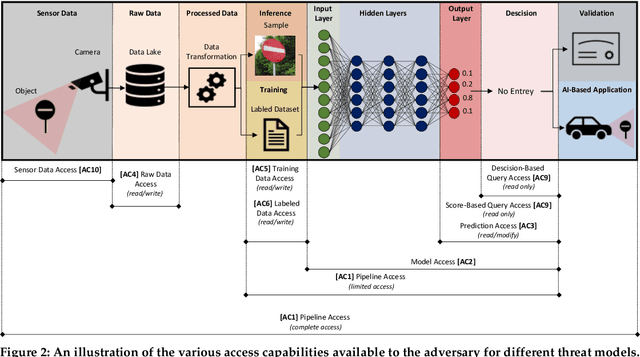
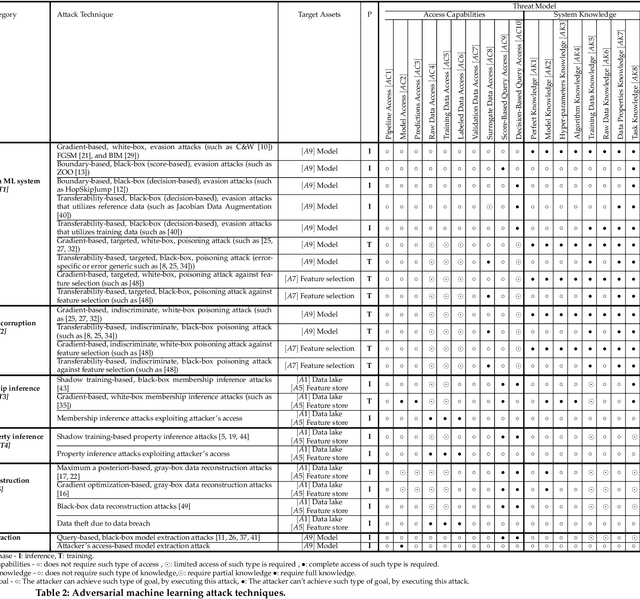
Although cyberattacks on machine learning (ML) production systems can be destructive, many industry practitioners are ill equipped, lacking tactical and strategic tools that would allow them to analyze, detect, protect against, and respond to cyberattacks targeting their ML-based systems. In this paper, we take a significant step toward securing ML production systems by integrating these systems and their vulnerabilities into cybersecurity risk assessment frameworks. Specifically, we performed a comprehensive threat analysis of ML production systems and developed an extension to the MulVAL attack graph generation and analysis framework to incorporate cyberattacks on ML production systems. Using the proposed extension, security practitioners can apply attack graph analysis methods in environments that include ML components, thus providing security experts with a practical tool for evaluating the impact and quantifying the risk of a cyberattack targeting an ML production system.