 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Training Variational Networks with Multi-Domain Simulations: Speed-of-Sound Image Reconstruction
Jun 25, 2020
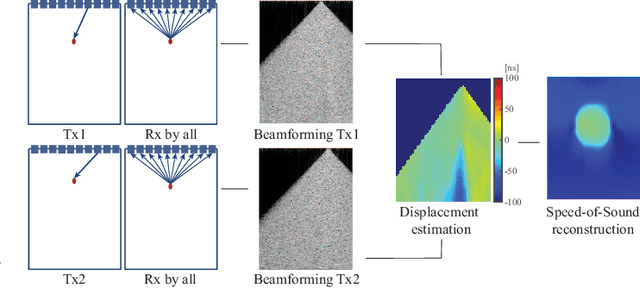
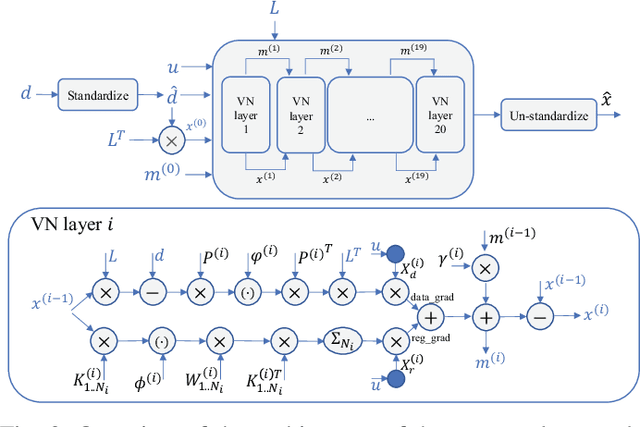
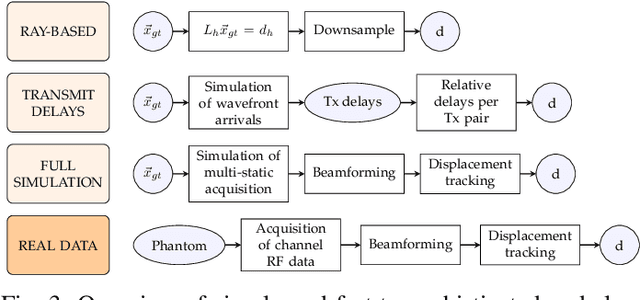
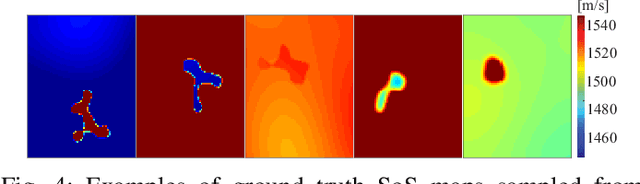
Speed-of-sound has been shown as a potential biomarker for breast cancer imaging, successfully differentiating malignant tumors from benign ones. Speed-of-sound images can be reconstructed from time-of-flight measurements from ultrasound images acquired using conventional handheld ultrasound transducers. Variational Networks (VN) have recently been shown to be a potential learning-based approach for optimizing inverse problems in image reconstruction. Despite earlier promising results, these methods however do not generalize well from simulated to acquired data, due to the domain shift. In this work, we present for the first time a VN solution for a pulse-echo SoS image reconstruction problem using diverging waves with conventional transducers and single-sided tissue access. This is made possible by incorporating simulations with varying complexity into training. We use loop unrolling of gradient descent with momentum, with an exponentially weighted loss of outputs at each unrolled iteration in order to regularize training. We learn norms as activation functions regularized to have smooth forms for robustness to input distribution variations. We evaluate reconstruction quality on ray-based and full-wave simulations as well as on tissue-mimicking phantom data, in comparison to a classical iterative (L-BFGS) optimization of this image reconstruction problem. We show that the proposed regularization techniques combined with multi-source domain training yield substantial improvements in the domain adaptation capabilities of VN, reducing median RMSE by 54% on a wave-based simulation dataset compared to the baseline VN. We also show that on data acquired from a tissue-mimicking breast phantom the proposed VN provides improved reconstruction in 12 milliseconds.
Improving Dietary Assessment Via Integrated Hierarchy Food Classification
Sep 06, 2021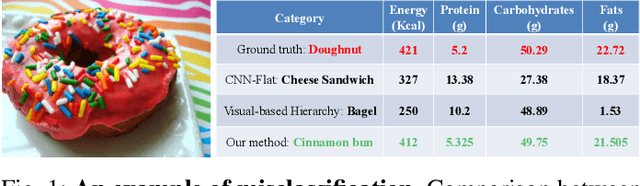
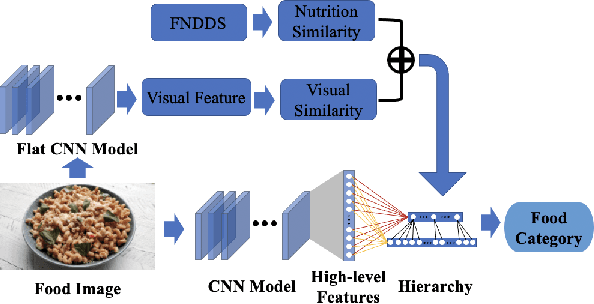
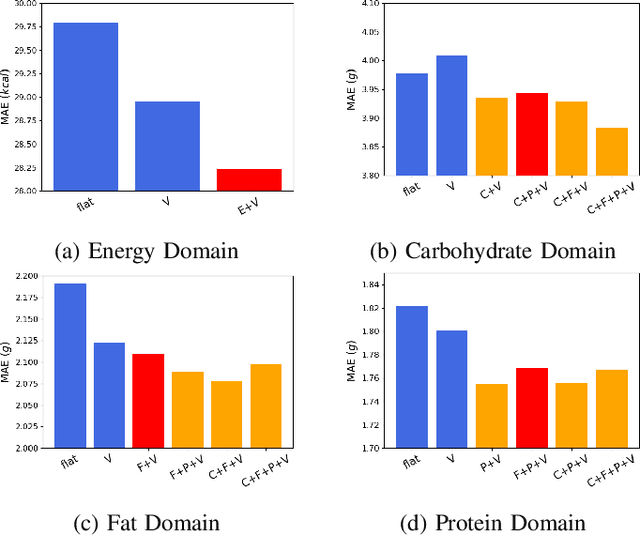

Image-based dietary assessment refers to the process of determining what someone eats and how much energy and nutrients are consumed from visual data. Food classification is the first and most crucial step. Existing methods focus on improving accuracy measured by the rate of correct classification based on visual information alone, which is very challenging due to the high complexity and inter-class similarity of foods. Further, accuracy in food classification is conceptual as description of a food can always be improved. In this work, we introduce a new food classification framework to improve the quality of predictions by integrating the information from multiple domains while maintaining the classification accuracy. We apply a multi-task network based on a hierarchical structure that uses both visual and nutrition domain specific information to cluster similar foods. Our method is validated on the modified VIPER-FoodNet (VFN) food image dataset by including associated energy and nutrient information. We achieve comparable classification accuracy with existing methods that use visual information only, but with less error in terms of energy and nutrient values for the wrong predictions.
Multi-Task Neural Processes
Dec 02, 2021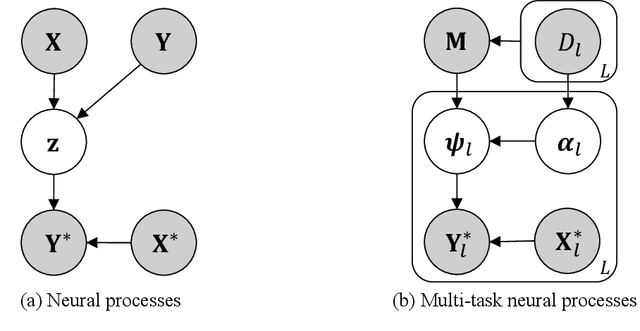
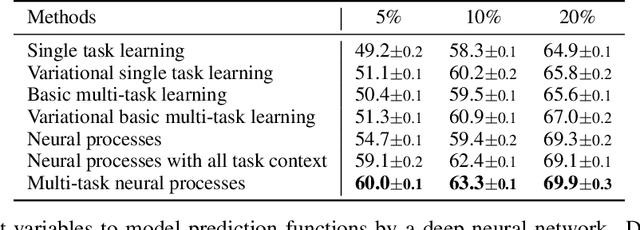
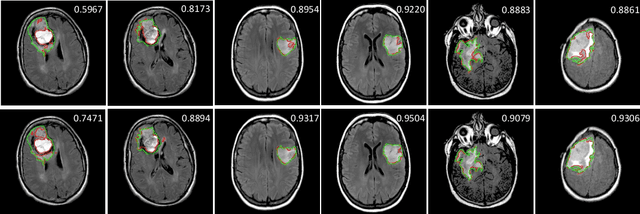
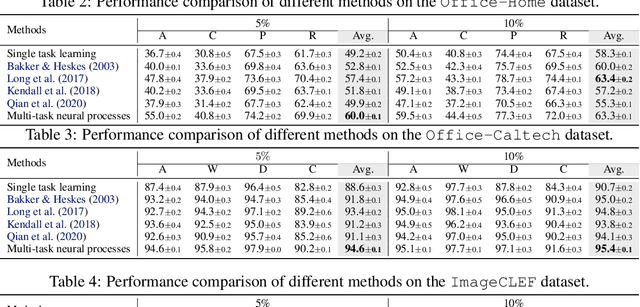
Neural processes have recently emerged as a class of powerful neural latent variable models that combine the strengths of neural networks and stochastic processes. As they can encode contextual data in the network's function space, they offer a new way to model task relatedness in multi-task learning. To study its potential, we develop multi-task neural processes, a new variant of neural processes for multi-task learning. In particular, we propose to explore transferable knowledge from related tasks in the function space to provide inductive bias for improving each individual task. To do so, we derive the function priors in a hierarchical Bayesian inference framework, which enables each task to incorporate the shared knowledge provided by related tasks into its context of the prediction function. Our multi-task neural processes methodologically expand the scope of vanilla neural processes and provide a new way of exploring task relatedness in function spaces for multi-task learning. The proposed multi-task neural processes are capable of learning multiple tasks with limited labeled data and in the presence of domain shift. We perform extensive experimental evaluations on several benchmarks for the multi-task regression and classification tasks. The results demonstrate the effectiveness of multi-task neural processes in transferring useful knowledge among tasks for multi-task learning and superior performance in multi-task classification and brain image segmentation.
Automatic 3D Ultrasound Segmentation of Uterus Using Deep Learning
Sep 20, 2021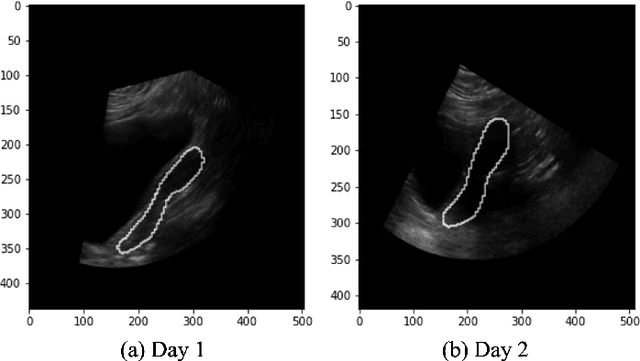
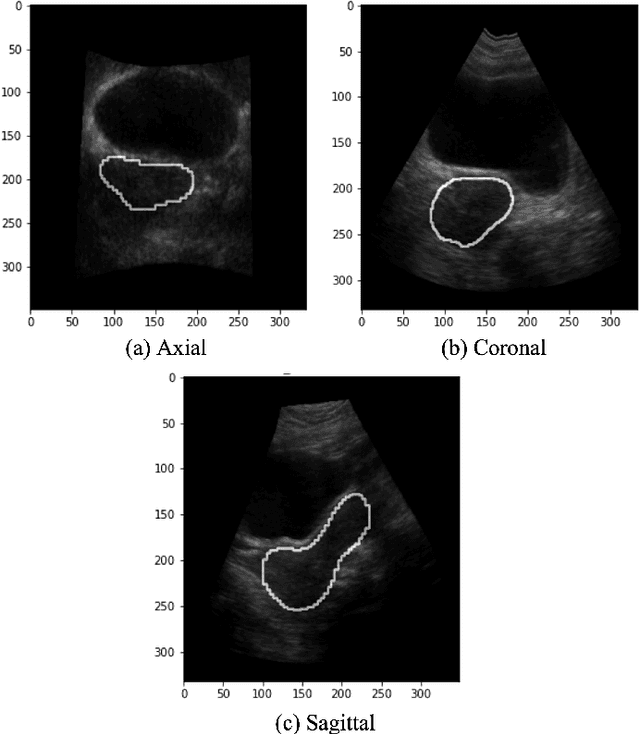
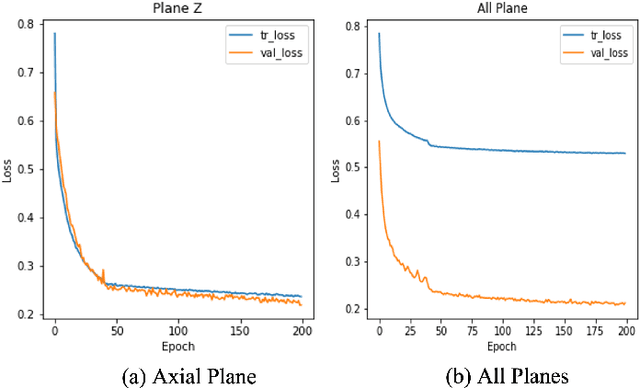
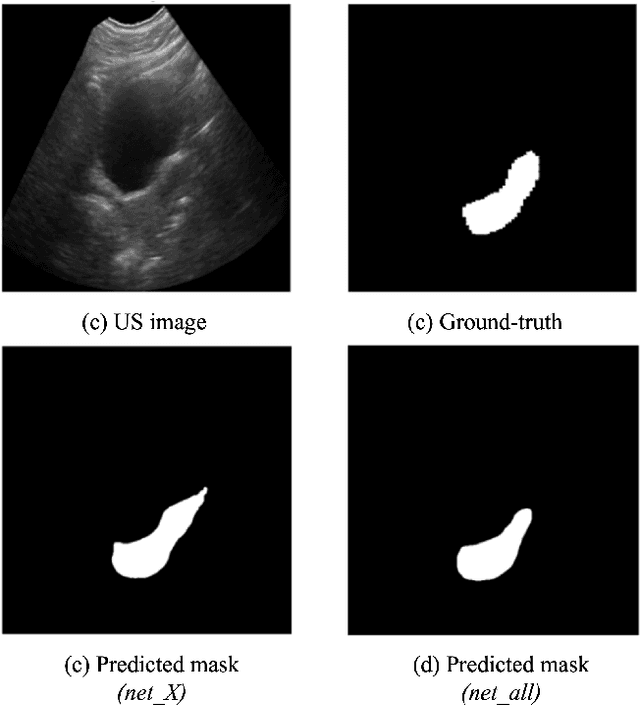
On-line segmentation of the uterus can aid effective image-based guidance for precise delivery of dose to the target tissue (the uterocervix) during cervix cancer radiotherapy. 3D ultrasound (US) can be used to image the uterus, however, finding the position of uterine boundary in US images is a challenging task due to large daily positional and shape changes in the uterus, large variation in bladder filling, and the limitations of 3D US images such as low resolution in the elevational direction and imaging aberrations. Previous studies on uterus segmentation mainly focused on developing semi-automatic algorithms where require manual initialization to be done by an expert clinician. Due to limited studies on the automatic 3D uterus segmentation, the aim of the current study was to overcome the need for manual initialization in the semi-automatic algorithms using the recent deep learning-based algorithms. Therefore, we developed 2D UNet-based networks that are trained based on two scenarios. In the first scenario, we trained 3 different networks on each plane (i.e., sagittal, coronal, axial) individually. In the second scenario, our proposed network was trained using all the planes of each 3D volume. Our proposed schematic can overcome the initial manual selection of previous semi-automatic algorithm.
Multi-focus Image Fusion Based on Similarity Characteristics
Dec 17, 2019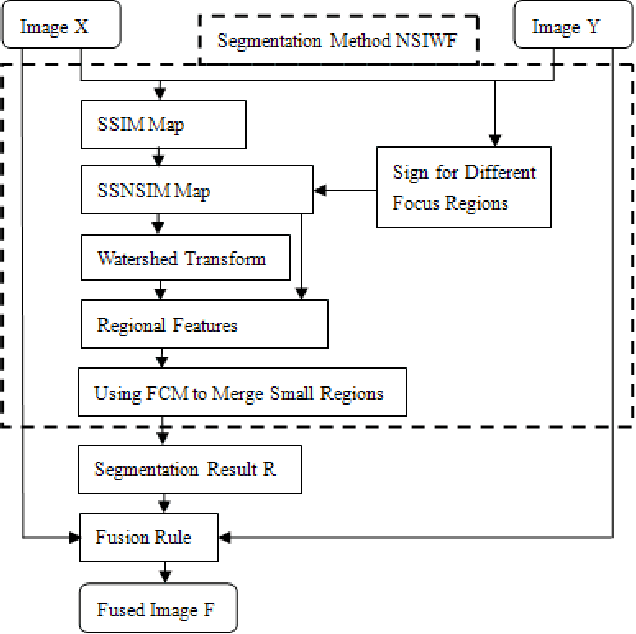
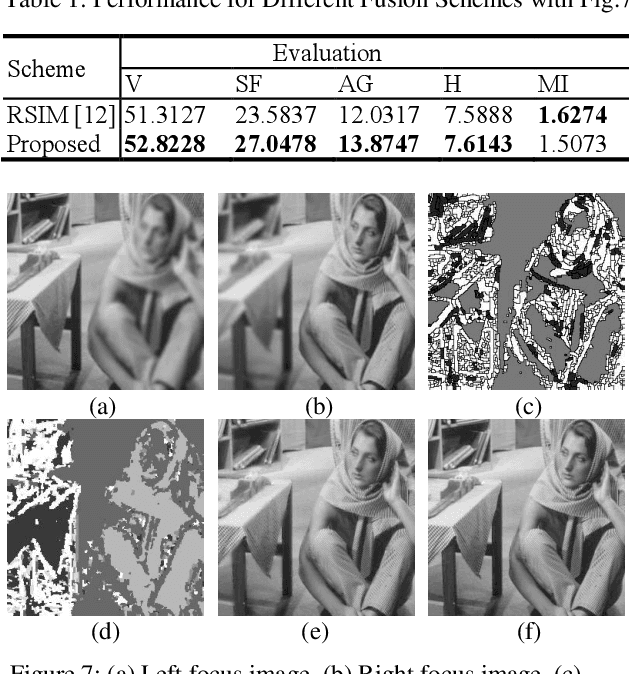
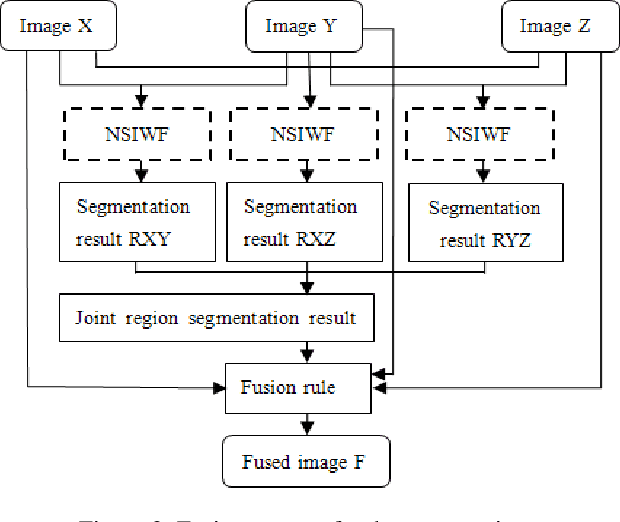
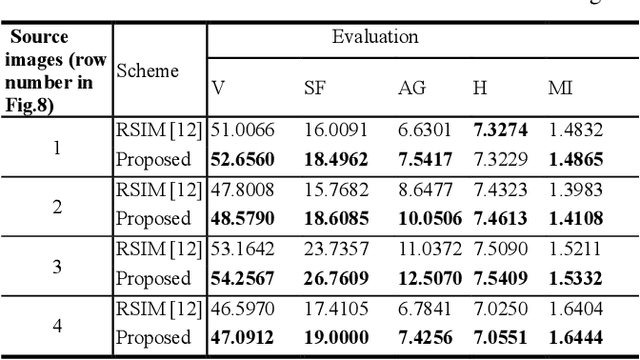
A novel multi-focus image fusion algorithm performed in spatial domain based on similarity characteristics is proposed incorporating with region segmentation. In this paper, a new similarity measure is developed based on the structural similarity (SSIM) index, which is more suitable for multi-focus image segmentation. Firstly, the SSNSIM map is calculated between two input images. Then we segment the SSNSIM map using watershed method, and merge the small homogeneous regions with fuzzy c-means clustering algorithm (FCM). For three source images, a joint region segmentation method based on segmentation of two images is used to obtain the final segmentation result. Finally, the corresponding segmented regions of the source images are fused according to their average gradient. The performance of the image fusion method is evaluated by several criteria including spatial frequency, average gradient, entropy, edge retention etc. The evaluation results indicate that the proposed method is effective and has good visual perception.
Multi-modal AsynDGAN: Learn From Distributed Medical Image Data without Sharing Private Information
Dec 15, 2020As deep learning technologies advance, increasingly more data is necessary to generate general and robust models for various tasks. In the medical domain, however, large-scale and multi-parties data training and analyses are infeasible due to the privacy and data security concerns. In this paper, we propose an extendable and elastic learning framework to preserve privacy and security while enabling collaborative learning with efficient communication. The proposed framework is named distributed Asynchronized Discriminator Generative Adversarial Networks (AsynDGAN), which consists of a centralized generator and multiple distributed discriminators. The advantages of our proposed framework are five-fold: 1) the central generator could learn the real data distribution from multiple datasets implicitly without sharing the image data; 2) the framework is applicable for single-modality or multi-modality data; 3) the learned generator can be used to synthesize samples for down-stream learning tasks to achieve close-to-real performance as using actual samples collected from multiple data centers; 4) the synthetic samples can also be used to augment data or complete missing modalities for one single data center; 5) the learning process is more efficient and requires lower bandwidth than other distributed deep learning methods.
UIBert: Learning Generic Multimodal Representations for UI Understanding
Jul 29, 2021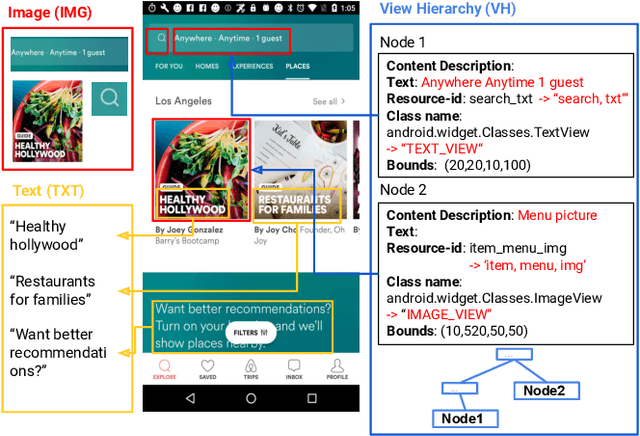
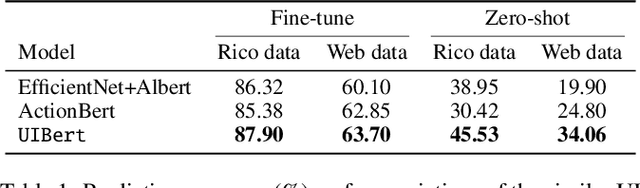
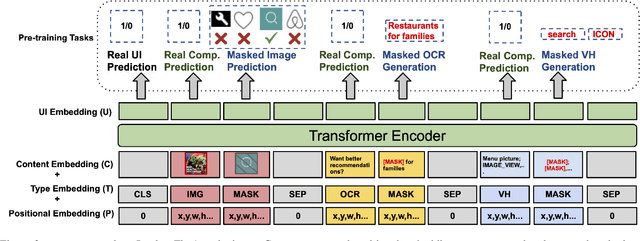
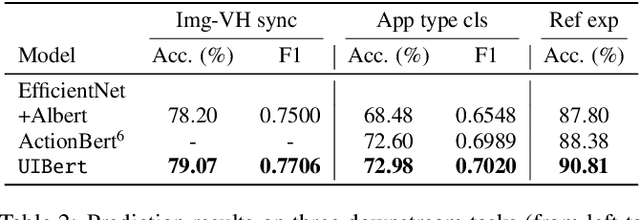
To improve the accessibility of smart devices and to simplify their usage, building models which understand user interfaces (UIs) and assist users to complete their tasks is critical. However, unique challenges are proposed by UI-specific characteristics, such as how to effectively leverage multimodal UI features that involve image, text, and structural metadata and how to achieve good performance when high-quality labeled data is unavailable. To address such challenges we introduce UIBert, a transformer-based joint image-text model trained through novel pre-training tasks on large-scale unlabeled UI data to learn generic feature representations for a UI and its components. Our key intuition is that the heterogeneous features in a UI are self-aligned, i.e., the image and text features of UI components, are predictive of each other. We propose five pretraining tasks utilizing this self-alignment among different features of a UI component and across various components in the same UI. We evaluate our method on nine real-world downstream UI tasks where UIBert outperforms strong multimodal baselines by up to 9.26% accuracy.
Adversarial Image Registration with Application for MR and TRUS Image Fusion
Oct 01, 2018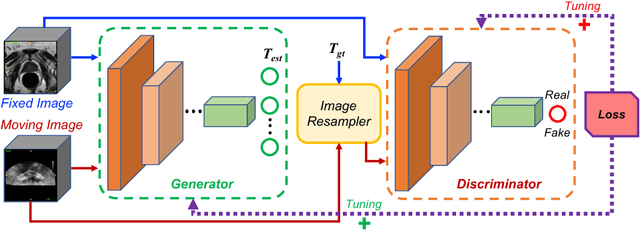
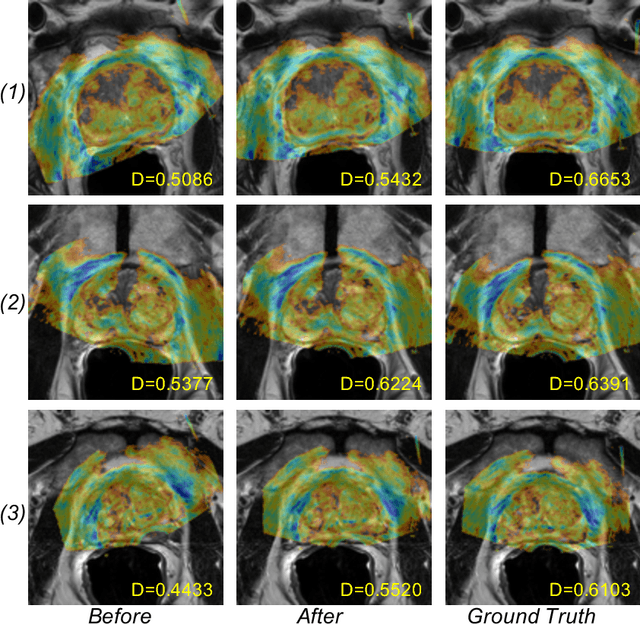
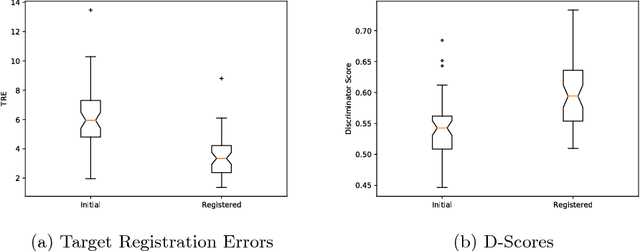
Robust and accurate alignment of multimodal medical images is a very challenging task, which however is very useful for many clinical applications. For example, magnetic resonance (MR) and transrectal ultrasound (TRUS) image registration is a critical component in MR-TRUS fusion guided prostate interventions. However, due to the huge difference between the image appearances and the large variation in image correspondence, MR-TRUS image registration is a very challenging problem. In this paper, an adversarial image registration (AIR) framework is proposed. By training two deep neural networks simultaneously, one being a generator and the other being a discriminator, we can obtain not only a network for image registration, but also a metric network which can help evaluate the quality of image registration. The developed AIR-net is then evaluated using clinical datasets acquired through image-fusion guided prostate biopsy procedures and promising results are demonstrated.
Deep Learning-Based Carotid Artery Vessel Wall Segmentation in Black-Blood MRI Using Anatomical Priors
Dec 02, 2021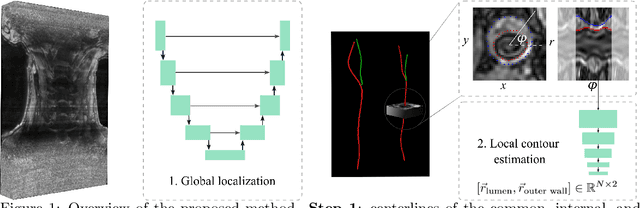
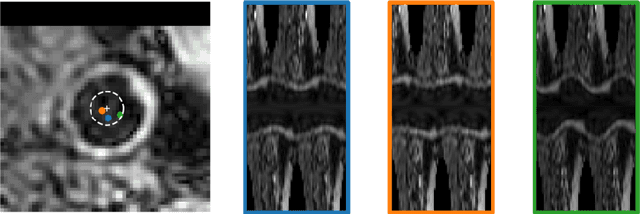
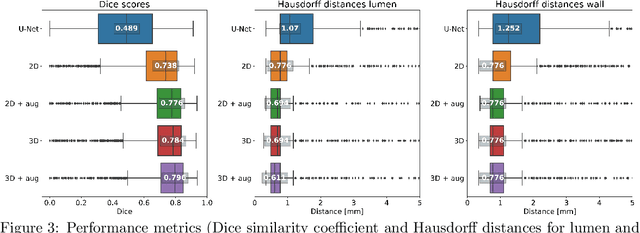
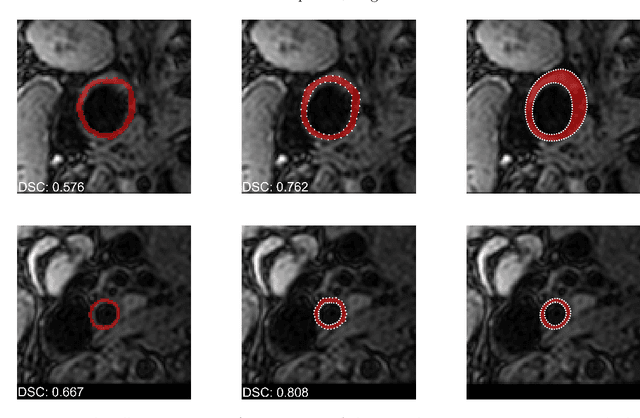
Carotid artery vessel wall thickness measurement is an essential step in the monitoring of patients with atherosclerosis. This requires accurate segmentation of the vessel wall, i.e., the region between an artery's lumen and outer wall, in black-blood magnetic resonance (MR) images. Commonly used convolutional neural networks (CNNs) for semantic segmentation are suboptimal for this task as their use does not guarantee a contiguous ring-shaped segmentation. Instead, in this work, we cast vessel wall segmentation as a multi-task regression problem in a polar coordinate system. For each carotid artery in each axial image slice, we aim to simultaneously find two non-intersecting nested contours that together delineate the vessel wall. CNNs applied to this problem enable an inductive bias that guarantees ring-shaped vessel walls. Moreover, we identify a problem-specific training data augmentation technique that substantially affects segmentation performance. We apply our method to segmentation of the internal and external carotid artery wall, and achieve top-ranking quantitative results in a public challenge, i.e., a median Dice similarity coefficient of 0.813 for the vessel wall and median Hausdorff distances of 0.552 mm and 0.776 mm for lumen and outer wall, respectively. Moreover, we show how the method improves over a conventional semantic segmentation approach. These results show that it is feasible to automatically obtain anatomically plausible segmentations of the carotid vessel wall with high accuracy.
Image Denoising by Gaussian Patch Mixture Model and Low Rank Patches
Nov 20, 2020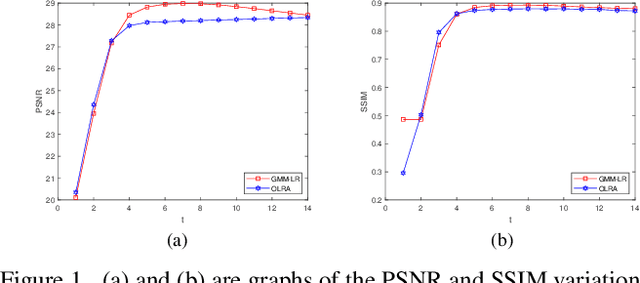

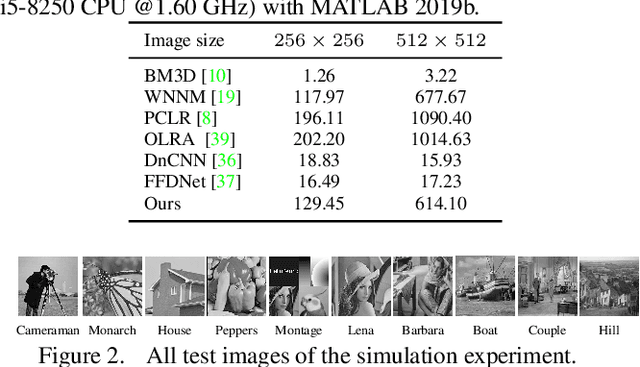
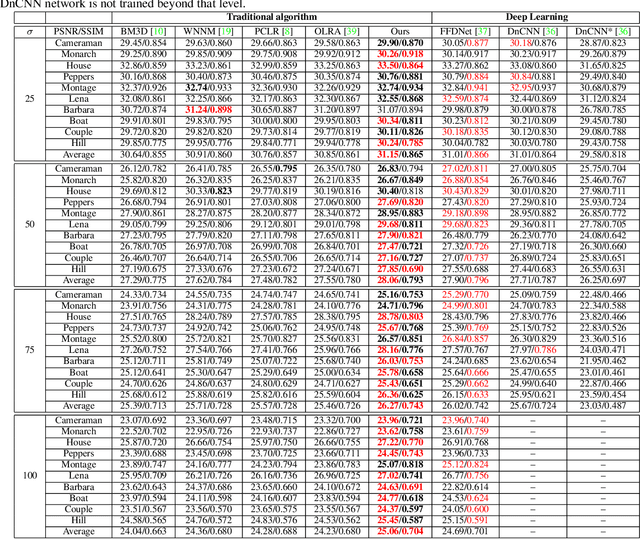
Non-local self-similarity based low rank algorithms are the state-of-the-art methods for image denoising. In this paper, a new method is proposed by solving two issues: how to improve similar patches matching accuracy and build an appropriate low rank matrix approximation model for Gaussian noise. For the first issue, similar patches can be found locally or globally. Local patch matching is to find similar patches in a large neighborhood which can alleviate noise effect, but the number of patches may be insufficient. Global patch matching is to determine enough similar patches but the error rate of patch matching may be higher. Based on this, we first use local patch matching method to reduce noise and then use Gaussian patch mixture model to achieve global patch matching. The second issue is that there is no low rank matrix approximation model to adapt to Gaussian noise. We build a new model according to the characteristics of Gaussian noise, then prove that there is a globally optimal solution of the model. By solving the two issues, experimental results are reported to show that the proposed approach outperforms the state-of-the-art denoising methods includes several deep learning ones in both PSNR / SSIM values and visual quality.