 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxial-Centric Cross-Plane Attention for 3D Medical Image Classification
Feb 25, 2026Clinicians commonly interpret three-dimensional (3D) medical images, such as computed tomography (CT) scans, using multiple anatomical planes rather than as a single volumetric representation. In this multi-planar approach, the axial plane typically serves as the primary acquisition and diagnostic reference, while the coronal and sagittal planes provide complementary spatial information to increase diagnostic confidence. However, many existing 3D deep learning methods either process volumetric data holistically or assign equal importance to all planes, failing to reflect the axial-centric clinical interpretation workflow. To address this gap, we propose an axial-centric cross-plane attention architecture for 3D medical image classification that captures the inherent asymmetric dependencies between different anatomical planes. Our architecture incorporates MedDINOv3, a medical vision foundation model pretrained via self-supervised learning on large-scale axial CT images, as a frozen feature extractor for the axial, coronal, and sagittal planes. RICA blocks and intra-plane transformer encoders capture plane-specific positional and contextual information within each anatomical plane, while axial-centric cross-plane transformer encoders condition axial features on complementary information from auxiliary planes. Experimental results on six datasets from the MedMNIST3D benchmark demonstrate that the proposed architecture consistently outperforms existing 3D and multi-plane models in terms of accuracy and AUC. Ablation studies further confirm the importance of axial-centric query-key-value allocation and directional cross-plane fusion. These results highlight the importance of aligning architectural design with clinical interpretation workflows for robust and data-efficient 3D medical image analysis.
RICAU-Net: Residual-block Inspired Coordinate Attention U-Net for Segmentation of Small and Sparse Calcium Lesions in Cardiac CT
Sep 11, 2024



The Agatston score, which is the sum of the calcification in the four main coronary arteries, has been widely used in the diagnosis of coronary artery disease (CAD). However, many studies have emphasized the importance of the vessel-specific Agatston score, as calcification in a specific vessel is significantly correlated with the occurrence of coronary heart disease (CHD). In this paper, we propose the Residual-block Inspired Coordinate Attention U-Net (RICAU-Net), which incorporates coordinate attention in two distinct manners and a customized combo loss function for lesion-specific coronary artery calcium (CAC) segmentation. This approach aims to tackle the high class-imbalance issue associated with small and sparse lesions, particularly for CAC in the left main coronary artery (LM) which is generally small and the scarcest in the dataset due to its anatomical structure. The proposed method was compared with six different methods using Dice score, precision, and recall. Our approach achieved the highest per-lesion Dice scores for all four lesions, especially for CAC in LM compared to other methods. The ablation studies demonstrated the significance of positional information from the coordinate attention and the customized loss function in segmenting small and sparse lesions with a high class-imbalance problem.
Modality Bank: Learn multi-modality images across data centers without sharing medical data
Jan 22, 2022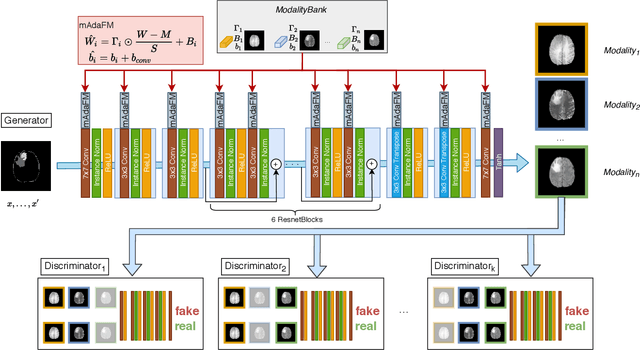
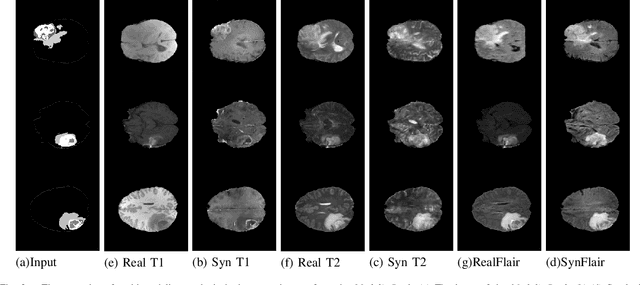
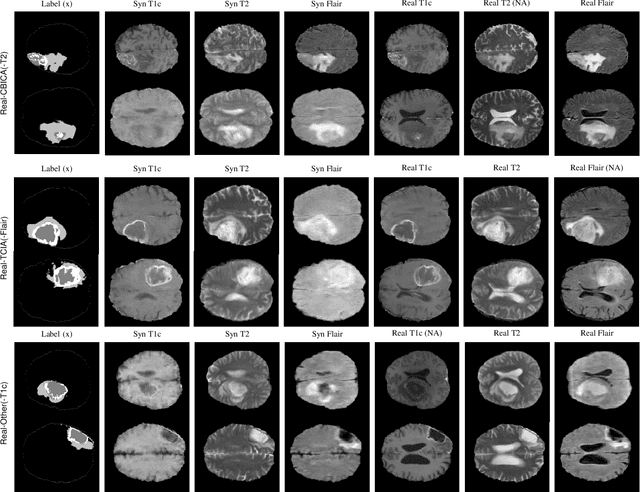
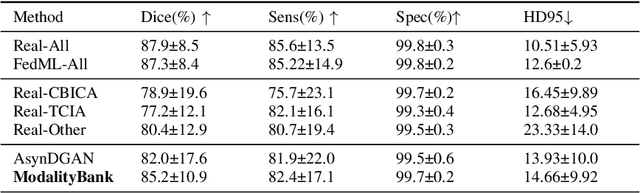
Multi-modality images have been widely used and provide comprehensive information for medical image analysis. However, acquiring all modalities among all institutes is costly and often impossible in clinical settings. To leverage more comprehensive multi-modality information, we propose a privacy secured decentralized multi-modality adaptive learning architecture named ModalityBank. Our method could learn a set of effective domain-specific modulation parameters plugged into a common domain-agnostic network. We demonstrate by switching different sets of configurations, the generator could output high-quality images for a specific modality. Our method could also complete the missing modalities across all data centers, thus could be used for modality completion purposes. The downstream task trained from the synthesized multi-modality samples could achieve higher performance than learning from one real data center and achieve close-to-real performance compare with all real images.
Multi-modal AsynDGAN: Learn From Distributed Medical Image Data without Sharing Private Information
Dec 15, 2020As deep learning technologies advance, increasingly more data is necessary to generate general and robust models for various tasks. In the medical domain, however, large-scale and multi-parties data training and analyses are infeasible due to the privacy and data security concerns. In this paper, we propose an extendable and elastic learning framework to preserve privacy and security while enabling collaborative learning with efficient communication. The proposed framework is named distributed Asynchronized Discriminator Generative Adversarial Networks (AsynDGAN), which consists of a centralized generator and multiple distributed discriminators. The advantages of our proposed framework are five-fold: 1) the central generator could learn the real data distribution from multiple datasets implicitly without sharing the image data; 2) the framework is applicable for single-modality or multi-modality data; 3) the learned generator can be used to synthesize samples for down-stream learning tasks to achieve close-to-real performance as using actual samples collected from multiple data centers; 4) the synthetic samples can also be used to augment data or complete missing modalities for one single data center; 5) the learning process is more efficient and requires lower bandwidth than other distributed deep learning methods.